What is Snscrape?
Snscrape is an open-source library that allows you to scrape users, user profiles, hashtags, searches, tweets (single or surrounding thread), list posts, and trends without (almost) any rate limits without going through Twitter API.
To get the most out of this tutorial, follow along and let’s get coding!
Getting the Project Ready
To start the project, let’s open a new directory on VScode (or your favorite IDE) and open a terminal. From there, just install Snscrape using pip:
</p>
<pre>pip install snscrape</pre>
<p>It’ll automatically download all the necessary files – but for it to work, you’ll need to have Python 3.8 or higher installed. To verify your Python version, use the command python –version on your terminal.
Note:If you don’t have it already, also install Pandas using pip install pandas. We’ll use it to visualize the scraped data and export everything to a CSV file.
Next, create a new file called tweet-scraper.py and import the dependencies at the top:
</p>
<pre>import snscrape.modules.twitter as sntwitter
import pandas as pd</pre>
<p>And now we’re ready to start scraping the data!
Understanding the Structure of the Response
Just like websites, we need to understand the structure of the Twitter data Snscrape provides, so we can pick and choose the bits of data we’re actually interested in.
Let’s say that we want to know what people are talking about around web scraping. To make it happen, we’ll need to send a query to Twitter through Snscrape’s Twitter module like this:
</p>
<pre>query = "web scraping"
for tweet in sntwitter.TwitterSearchScraper(query).get_items():
print(vars(tweet))
break</pre>
<p>The .TwitterSearchScraper() method is basically like using Twitter’s search bar on the website. We’re passing it a query (in our case, web scraping) and getting the items resulting from the search.
More Snscrape Methods
Here’s a list of all other methods you can use to query Twitter using the sntwitter module:
- TwitterSearchScraper
- TwitterUserScraper
- TwitterProfileScraper
- TwitterHashtagScraper
- TwitterTweetScraperMode
- TwitterTweetScraper
- TwitterListPostsScraper
- TwitterTrendsScraper
While the vars() function will return all attributes of an element, in this case, tweet.
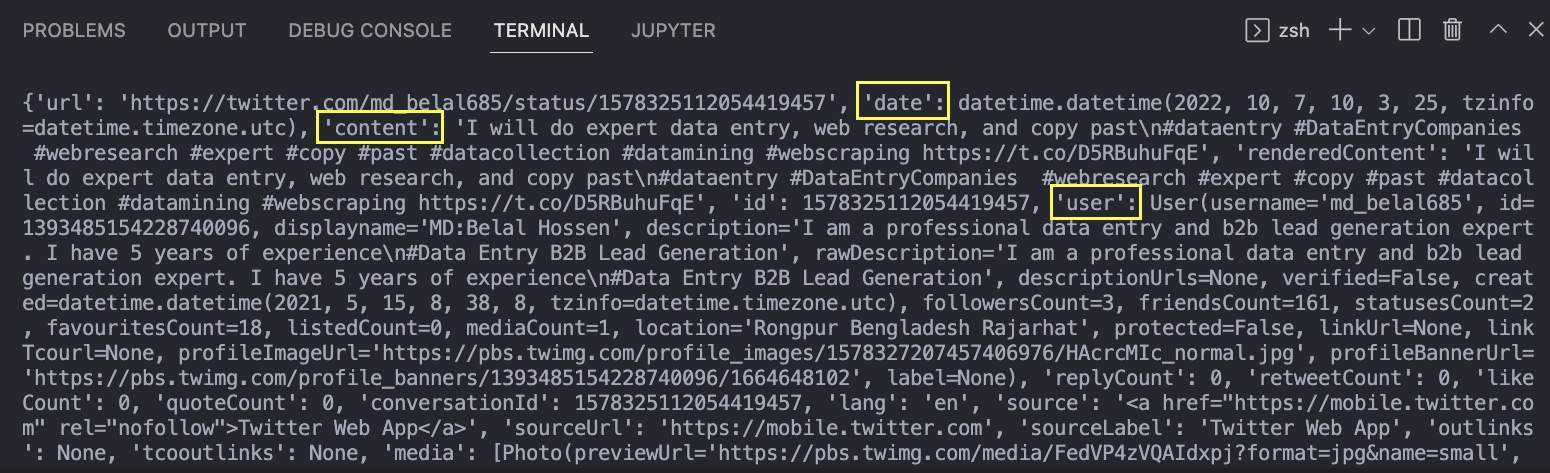
The returned JSON has all the information associated with the Tweet. In the image, we pinned the three that are most important for us: the data of the tweet, the content of the tweet (which is the tweet itself), and the user who tweeted it.
If you’ve worked with JSON data before, accessing the value of these fields is simple:
- tweet.date
- tweet.content
- tweet.user.username
The third is different because we don’t want the entire value of user, instead, we access the field user and then move down to the username field.
Scraping Complex Queries in Snscrape
Although there are several ways to construct your queries, the easiest way is using Twitter’s search bar to generate a query with the exact parameters we need.
First, go to Twitter and enter whatever query you like:
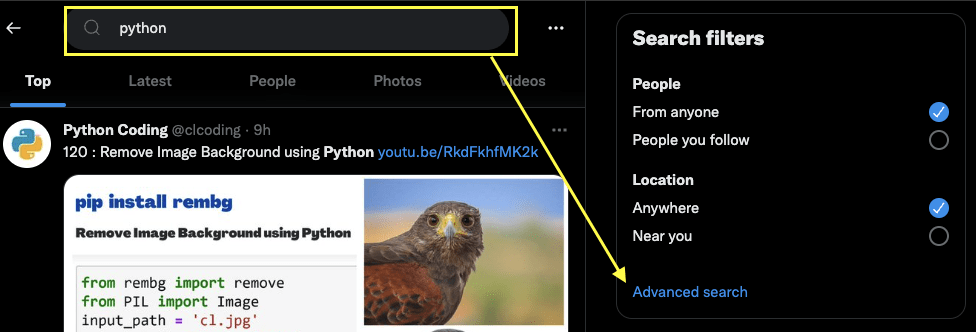
And now click on Advanced Search:
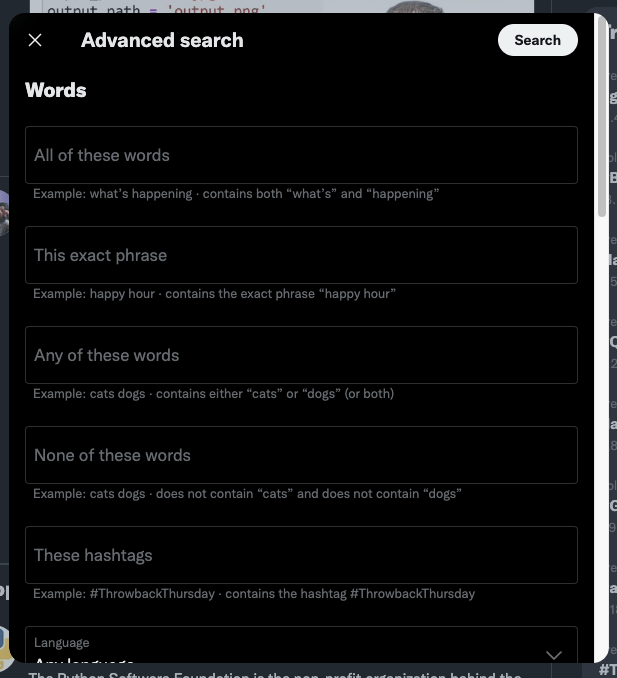
Now fill in the form with the parameter that matches your needs. For this example, we’ll use the following information:
| Field | Value |
|---|---|
| These exact words | web scraping |
| Language | English |
| From date | January 12, 2022 |
| To date | June 12, 2023 |
Note: You can also set specific accounts and filters and use less restrictive word combinations.
Once that’s ready, click the search button on the top right corner.
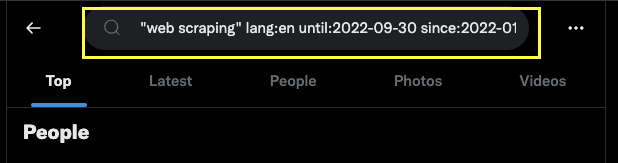
It has created a custom query we can use in our code to pass it to the TwitterSearchScraper() method.
Setting a Limit to Your Scraper
There are A LOT of tweets on Twitter. There’s just a ridiculous amount of tweets being generated every day. So let’s set a limit to the number of tweets we want to scrape and break the loop once we reach it.
Setting the limit is super simple:
</p>
<pre>limit = 1000</pre>
<p>However, if we just print tweets out, it will never actually reach any limit. To make it work, we’ll need to store the tweets in a list.
</p>
<pre>tweets = []</pre>
<p>With these two elements, we can add the following logic to our for loop without issues:
</p>
<pre>for tweet in sntwitter.TwitterSearchScraper(query).get_items():
if len(tweets) == limit:
break
else:
tweets.append([tweet.date, tweet.user.username, tweet.content])</pre>
<p>Creating a Dataframe With Pandas
Just for testing, let’s change the limit to 10 and print the array to see what it returns:

A little hard to read, but you can clearly see those two usernames, the dates, and the tweets. Perfect!
Now, let’s give it a better structure before exporting the data. With Pandas, all we need to do is pass our array to the .DataFrame() method and create the columns.
</p>
<pre>df = pd.DataFrame(tweets, columns=['Date', 'User', 'Tweet'])
#print(df)
</pre>
<p>Note: These should match the data we’re scraping and the order they will be scraped.
You can print the dataframe to ensure you’re getting all the tweets specified in the limit variable, but it should work just fine.
Exporting Your Dataframe to a CSV/JSON File
How could you not love Python when it makes exporting so easy?
Let’s set the limit to 1000 and run our script!
Exporting to CSV:
</p>
<pre>df.to_csv('scraped-tweets.csv', index=False, encoding='utf-8')</pre>
<p>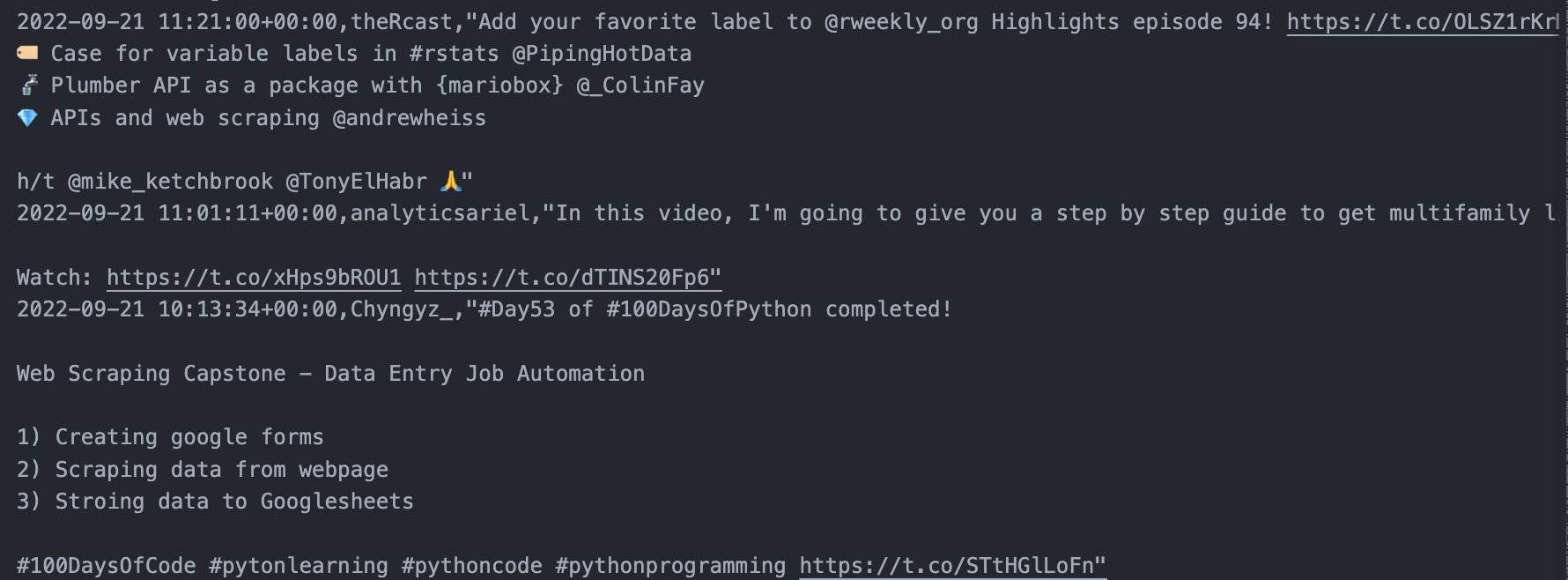
Export to JSON:
</p>
<pre>df.to_json('scraped-tweets.json', orient='records', lines=True)
</pre>
<p>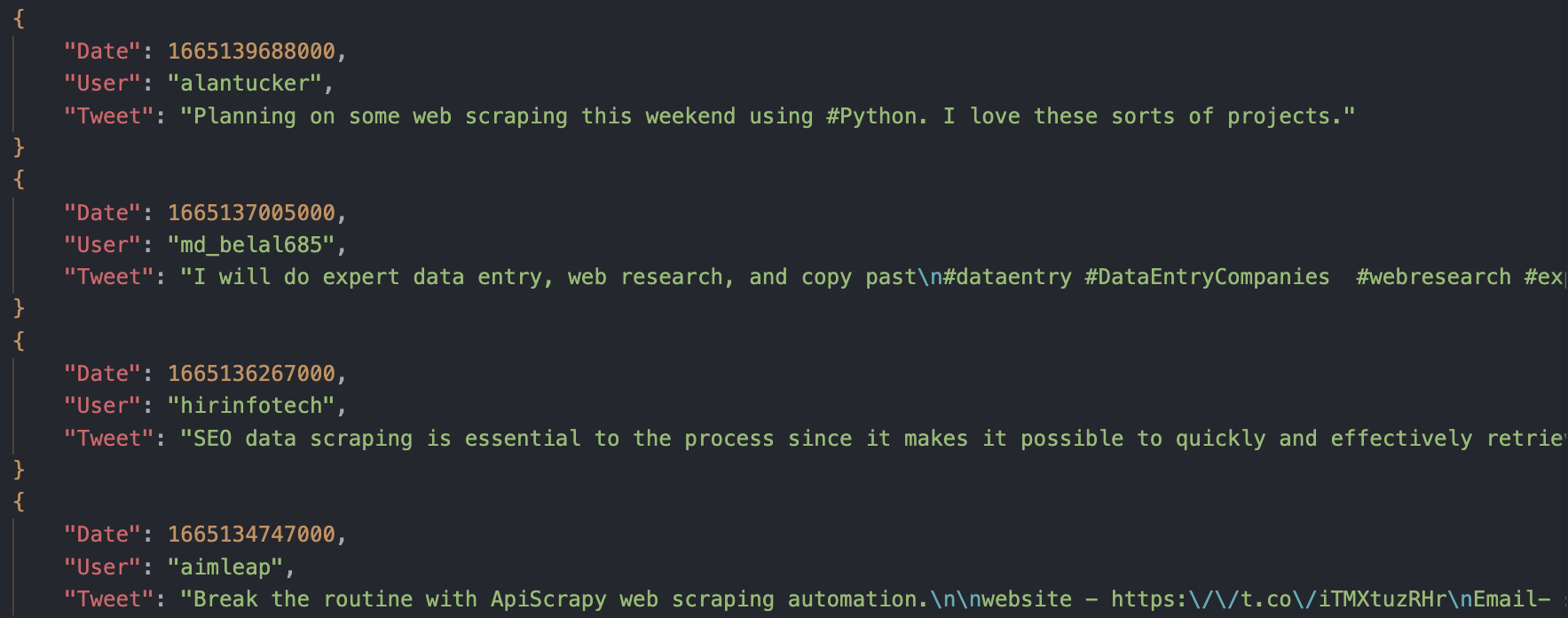
Note: Of course, the script will take longer than before to scrape all the data. So don’t worry if it takes a few minutes before it returns the tweets.
Congratulations! You just scraped 1000 Tweets from January to September 2022 in a few minutes.
You can use this method to scrape tweets from any time range and use any filter you want to make your research laser focused.
Wrapping Up
Snscrape is a useful tool for beginners and professionals to collect data with a simple to use API.
It allows you to collect all major details from tweets without having to create complicated workarounds or spending hundreds of thousands of dollars for Twitter’s API.
Until next time, happy scraping!