



How do you avoid being blocked when web scraping? If your web scraping bots keep getting detected and blocked, you may miss some important elements in your data extraction process.
In this basic web scraping guide, we’ll show you 10 best practices used by our web scraping experts to ensure seamless data extraction, including strategies to overcome even the most stringent anti-bot measures and a robust web scraping solution.
How Website Detects and Blocks Your Web Scraper Bot
Before we go straight to the web scraping tips, first, you need to understand what common anti-bot measures you likely face when scraping web data.
Generally speaking, websites protect their data from getting extracted by using a variety of methods, including:
- IP address detection
- HTTP request header checking
- CAPTCHAs
- JavaScript checks
Now, when building a large-scale web scraper, you’ll want to pay special attention to bypass this anti-bot system. Following the 10 web scraping tips below will help you get a successful web scraping. However, there’s an easier way to guarantee a 99.9% data-extracting success rate by adopting a web scraping tool like ScraperAPI.
ScraperAPI empowers you to collect data from any public website. It will take care of the proxies, browsers, and CAPTCHA handling for you. You can even set the web scraping project to run on a schedule using ScraperAPI’s DataPipeline solution or get the data in JSON format directly using ScraperAPI’s special APIs for Google, Amazon, and Walmart. If you’re interested in giving it a try, sign up here for a 7-day free trial (5,000 API credits).
10 Web Scraping Best Practices to Avoid Getting Blocked or Blacklisted
Here are some useful web scraping tips that will help you extract web data without getting blocked or blacklisted.

1. IP Rotation
The number one way sites detect web scrapers is by examining their IP address and tracking how it’s behaving.
If the server finds a pattern, strange behaviors, or an impossible request frequency (to name a few) for a real user, the server can block the IP address from accessing the site again.
To avoid sending all of your requests through the same IP address, you can use an IP rotation service like ScraperAPI or other proxy services in order to route your requests through a proxy pool to hide your real IP address while scraping the site. This will allow you to scrape the majority of websites without issue.
However, not all proxies are made equal. For sites using more advanced proxy anti-scraping mechanisms, you may need to try using residential proxies.
if you are not familiar with what this means, you can check out our article on the different types of proxies to learn the difference.
Ultimately, using IP rotation, your scraper can make requests appear to be from different users and mimic the normal behavior of online traffic.
When using ScraperAPI, our smart IP rotation system will use years of statistical analysis and machine learning to rotate your proxies as needed, from a pool of data center, residential, and mobile proxies to ensure a 99.99% success rate.
Try it free for 7 days with 5,000 API credits.
2. Set a Real User-Agent
User Agents are a special type of HTTP header that will tell the website you are visiting the exact browser you are using.
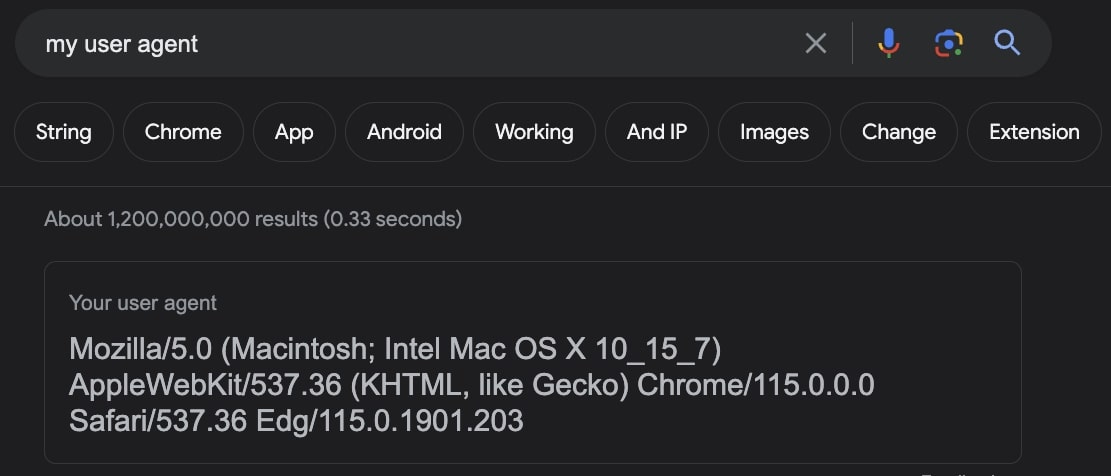
Some websites will examine User-Agents and block requests from User Agents that don’t belong to a major browser, and because most web scrapers don’t bother setting the User-Agent, they become easy to detect.
Don’t be one of these developers!
Remember to set a popular User Agent for your web crawler (here’s a list of popular User-Agents you can use).
For advanced users, you can also set your User-Agent to the Googlebot User Agent since most websites want to be listed on Google and, therefore, let Googlebot access their content.
Note: Yes, Google uses web scraping.
It’s important to remember to keep the User Agents you use relatively up to date. Every new update to Google Chrome, Safari, Firefox, etc., has a completely different user agent, so if you go years without changing the user agent on your crawlers, they will become more and more suspicious.
It may also be smart to rotate between a number of different user agents so that there isn’t a sudden spike in requests from one exact user agent to a site (this would also be fairly easy to detect).
The good news is that you don’t need to worry about this when using ScraperAPI.
3. Set Other Request Headers
Real web browsers will have a whole host of headers set, any of which can be checked by careful websites to block your web scraper.
In order to make your scraper appear to be a real browser, you can navigate to https://httpbin.org/anything, and simply copy the headers that you see there (they are the headers that your current web browser is using).
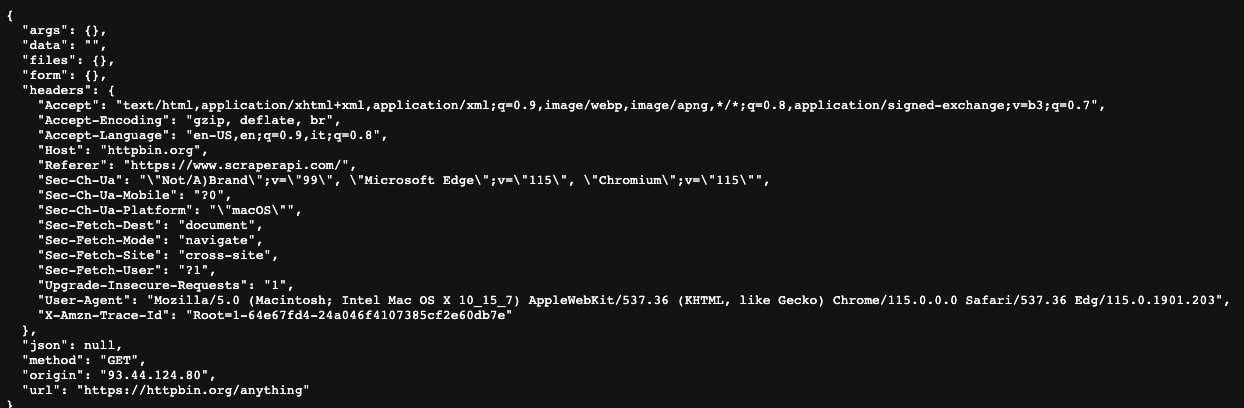
Things like “Accept”, “Accept-Encoding”, “Accept-Language”, and “Upgrade-Insecure-Requests” being set will make your requests look like they are coming from a real browser so you won’t get your web scraping blocked.
By rotating through a series of IP addresses and setting proper HTTP request headers (especially User-Agents), you should be able to avoid being detected by 99% of websites.
Here’s a complete tutorial on getting the best headers and cookies for web scraping.
4. Set Random Intervals In Between Your Website Scraping Requests
It is easy to detect a web scraper that sends exactly one request each second, 24 hours a day! No real person would ever use a website like that – plus, an obvious pattern like this is easily detectable.
Use randomized delays (anywhere between 2-10 seconds, for example) in order to build a web scraper that can avoid being blocked.
Also, remember to be polite. If you send requests too fast, you can crash the website for everyone. If you detect that your requests are getting slower and slower, you may want to send requests more slowly so you don’t overload the web server (you’ll definitely want to do this to help frameworks like Scrapy avoid being banned).
Make sure to use web scraping best practices to avoid this kind of issue.
For especially polite crawlers, you can check a site’s robots.txt (this will be located at http://example.com/robots.txt or http://www.example.com/robots.txt) to look for any line that says crawl-delay, specifying how many seconds you should wait in between requests.
 Remember, the web is for everyone!
Remember, the web is for everyone!
5. Set a Referrer
The Referer header is an HTTP request header that lets the site know what site you are arriving from.
Generally, it’s a good idea to set this so that it looks like you’re arriving from Google.
You can do this with the header:
“Referer”: “https://www.google.com/”
You can also change this up for websites in different countries. For example, if you are trying to scrape a site in the UK, you might want to use “https://www.google.co.uk/” instead of “https://www.google.com/”.
You can also look up the most common referers to any site using a tool like https://www.similarweb.com, often, this will be a social media site like Youtube.
By setting this header, you can make your request look even more authentic, as it appears to be traffic from a site that the webmaster would be expecting a lot of traffic to come from during normal usage.
The next five strategies are a little more complex to implement, but if you’re still not able to access the data, these are worth trying.
6. Use a Headless Browser
The trickiest websites to scrape may detect subtle tells like web fonts, extensions, browser cookies, and javascript execution in order to determine whether or not the request is coming from a real user.
In order to scrape these sites, you may need to deploy your own headless browser (or have ScraperAPI do it for you!).
Tools like Selenium and Puppeteer will allow you to write a program to control a real web browser that is identical to what a real user would use in order to completely avoid detection.
Image Source: Toptal
While it is quite a bit of work to make Selenium undetectable or Puppeteer undetectable, this is the most effective way to scrape websites that would otherwise be impossible.
That said, this should be the last resource, as there are many ways to bypass even dynamic content.
For example, if the website requires to execute JavaScript before injecting the content, you can use ScraperAPI to render the page before returning the resulting HTML.
Another potential solution is finding the hidden API the site is getting its data from. That’s the approach we used to collect job data from LinkedIn.
A potential scenario to go ahead and use a headless browser is when site interaction is 100% needed (like clicking on a button), and you can’t find the file from where the application is pooling the data.
7. Avoid Honeypot Traps
A lot of sites will try to detect web crawlers by putting in invisible links that only a robot would follow.
To avoid them, you need to detect whether a link has the “display: none” or “visibility: hidden” CSS property set, and if they do, avoid following that link. Otherwise, the server will be able to spot your scraper, fingerprint the properties of your requests, and block you quite easily.
Honeypots are one of the easiest ways for smart webmasters to detect crawlers, so make sure that you are performing this check on each page that you scrape.
Advanced webmasters may also just set the color to white (or to whatever color the background color of the page is), so you may want to check if the link has something like “color: #fff;” or “color: #ffffff” set, as this would make the link effectively invisible.
8. Detect Website Changes
Many websites change layouts for many reasons, and this will often cause scrapers to break.
In addition, some websites will have different layouts in unexpected places (page 1 of the search results may have a different layout than page 4). This is true even for surprisingly large companies that are less tech-savvy, e.g., large retail stores that are just making the transition to online.
You need to properly detect these changes when building your scraper and create ongoing monitoring so that you know your crawler is still working (usually, just counting the number of successful requests per crawl should do the trick).
Another easy way to set up monitoring is to write a unit test for a specific URL on the site or one URL of each type.
For example, on a reviews site, you may want to write:
- A unit test for the search results page
- A unit test for the reviews page
- A unit test for the main product page
And so on.
This way, you can check for breaking site changes using only a few requests every 24 hours or so and without having to go through a full crawl to detect errors.
9. Use a CAPTCHA Solving Service
One of the most common ways for sites to crack down on crawlers is to display a CAPTCHA.
Luckily, there are services specifically designed to get past these restrictions in an economical way, whether they are fully integrated solutions like ScraperAPI or narrow CAPTCHA solving solutions that you can integrate just for the CAPTCHA solving functionality like 2Captcha or AntiCAPTCHA.
As you can imagine, there’s no way for simple data-collecting scripts to solve them, so they are quite effective for blocking most scrapers.
Some of these CAPTCHA-solving services are fairly slow and expensive, so you may need to consider whether it is still economically viable to scrape sites that require continuous CAPTCHA-solving over time.
Note: ScraperAPI automatically handles CAPTCHAS for you without any extra cost.
10. Scrape Out of the Google Cache
As a true last resort, particularly for data that does not change too often, you may be able to scrape data out of Google’s cached copy of the website rather than the website itself.
Simply prepend “http://webcache.googleusercontent.com/search?q=cache:” to the beginning of the URL.
For example, to scrape ScraperAPI’s documentation, you could send your request to:
“http://webcache.googleusercontent.com/search?q=cache:https://www.scraperapi.com/documentation/”.
This is a good workaround for non-time-sensitive information that is on extremely hard-to-scrape sites.
While scraping out of Google’s cache can be a bit more reliable than scraping a site that is actively trying to block your scrapers, remember that this is not a foolproof solution.
Some sites like LinkedIn actively tell Google not to cache their data, and the data for unpopular sites may be fairly out of date as Google determines how often they should crawl a site based on the site’s popularity as well as how many pages exist on that site.
Bypass Web Scraping Blocks Effortlessly with ScraperAPI
Hopefully, you’ve learned a few useful tips for web scraping popular websites without being blocked, blacklisted or IP banned.
If you don’t want to implement all of these techniques from scratch or you’re working on a time-sensitive project, create a free ScraperAPI account and start collecting data in a couple of minutes.
Until next time, happy web scraping!





