



There’s a sea of web scraping tools to choose from. Each has its (somewhat) unique set of features, programming languages, and pricing models, making it easy to get confused. So, how do you ensure you choose the right web scraping solution that fits your data extraction needs?
In this web scraping guide, we’ll show you ten key factors to consider when selecting the ideal web scraping tools. We’ll look at attributes such as the web scraper features, project scope and scalability, and pricing structure—helping you make an informed decision.
Two Types of Web Scraping Tools
Before we discuss the different factors of the best web scraping solution, let’s clarify what will be covered here. Basically, there are two different types of web scraper:
- Off-the-shelf tools
These are usually subscription-based and “cloud-run.” These done-for-you tools take care of the entire data extraction process (so you have to let go of control) and only require minimal input, like the target website and elements to scrape. - Web scraping APIs
These are usually subscription-based web scrapers. Instead of taking complete control, these web scraping APIs are designed to automatically handle web scraping complexities like proxy rotation, CAPTCHAs, etc. These tools are integrated into your scripts, giving you control over how data is filtered, extracted, and formatted.
There are also data collection tools built to solve a specific problem, like proxy providers, but these, in our opinion, are not scraping solutions but services you can use to build your own tools.
Note: You don’t want to go on this road for many reasons, but the final decision is yours. Still, check our in-house vs. out-house breakdown before committing to fully custom-made.
Now that we have a common language let’s dive into the 10 factors to consider for your scraping solution.
10 Things to Consider When Selecting the Ideal Web Scraping Tool
1. In-house Expertise
The first question you need to ask yourself is how tech-savvy your team is in web scraping and building a web scraper. This will heavily influence what tools you’ll be able to use and to what degree.
Every tool can be grouped into one of these:
- On one end, you’ll find off-the-shelf tools that automate the entire process without any input, so you won’t need any technical knowledge to use them.
- In the middle, we can find scraping APIs that take care of many of the most complex technical problems but still require some programming knowledge to build the scripts.
- While at the other end of the spectrum are scraping services like proxy providers and CAPTCHA handlers, which help you with certain aspects of your project, the rest is up to you. This means you will require a high level of programming skills to use.
Note: We’re just mentioning these last ones because they are part of the spectrum we’re talking about. For example, a done-for-you tool will be better for you if your team is primarily non-technical professionals like marketing folks or business analysts without programming skills.
Your team will just need to think about the data they need and target sites and learn how to use the software’s interface (learn more about the fundamental aspects of web scraping). Of course, these are usually more expensive and aren’t as customizable as other solutions; a worthwhile trade-off to make when you consider that:
- You require no technical knowledge
- Engineer costs and time are cut down
- You won’t have to worry about maintenance
- No need to constantly monitor the infrastructure
On the contrary, if your team has a mid-to-high-level programming skill level, a web scraping API will save you money and give you more control over your data. These tools are usually easy to integrate and take care of many complexities automatically (so you won’t need to configure anything).
2. Tech Stack and Internal Processes
Now that you know which type of data collection solution you’ll need, it’s time to think about integrating the web scraping tool into your tech stack.
With the web scraping APIs, start by thinking about what technologies you’re using. If you need to change your infrastructure or learn a new technology to make it work, it will add unnecessary pressure to the process. Instead, look for a solution that works right away.
With off-the-shelf solutions, on the other hand, have a particular way of doing things. For example, they have a specific way to take data out of them and available integrations. The solution you choose must be easy to connect to the rest of your processes and tools.
Always check if the tool can connect to your custom dashboards and integrate with the third-party tools you’re currently using. Otherwise, you’ll have to hire technical professionals to build these integrations.
At that point, it’s better to use a web scraping API.
3. Data Scraping Frequency
Ask yourself how many times you’ll need to run your web scraper and how often. Handling a one-time job is different from creating a monitoring system. The scraping frequency will affect many other factors, like scraping speed and price.
Suppose you need high-frequency scrapes (for example, every 5 – 10 minutes). In that case, you’ll want a web scraping solution with a high success rate and resilience to anti-scraping techniques but that doesn’t eat too much of your budget for every request, or you’ll risk making your project unviable.
However, one-time jobs require less focus on scalability, so going for a more expensive but faster-to-implement solution would be better than a more affordable but more tech-heavy solution.
Even with the technical knowledge, sometimes an off-the-shelf solution is a better choice if you have the budget and the tool fits your needs, as this will save you a considerable amount of work.
4. Data Extraction Scope and Scalability
Getting almost real-time data (high-frequency scrapes) from a couple of pages is not the same as getting the same data from thousands of URLs. When working with large websites, you might be more interested in the success rate (getting the data) than the speed of your solution. Meanwhile, for other projects, speed is crucial due to time constraints.

When choosing the best web scraping tool, think about the scope of your projects. For instance:
- Data volume: how much data do you need to extract?
Some tools charge based on data size (gigabytes), while others charge per request (or might have difficulty processing large amounts of data.)
Assess your needs to determine the most cost-effective solution. - Request frequency: how many requests will you send daily, weekly, and monthly?
Tools with lower success rates require more requests, potentially slowing your project. At the same time, high-volume scraping demands fast response times, while occasional scraping may tolerate slower speeds.
In terms of scalability, the web scraping tool should be able to handle an increasing number of requests and jobs without decreasing its success rate. This is because your data needs will most likely keep growing as your business grows, and you want a tool that can grow with you.
On that note, a very important factor to consider for scalability is concurrency – the ability to handle several requests simultaneously.
As your data needs keep growing, you’ll find that sending one request at a time won’t be enough to keep a smooth data stream. Instead, you’ll experience bottlenecks delaying your entire operation.
For large web scraping projects, the number of concurrent requests a tool can handle is crucial for scalability and speed. No matter how fast a tool can process a request, a tool that can successfully handle 100 to 400 concurrent requests will always be faster and more efficient.
If the tool can’t scale well, you’ll have to replace the entire infrastructure later on, which can translate into revenue loss and missing opportunities.
5. Data Control
How do you need data to be delivered to you? Do you need a specific format like JSON? Do you need this data fed to another system or stored in a database? These are essential questions to answer before committing to a solution. Especially when using a done-for-you approach.
In the case of web scraping APIs, you control how data is exported, and you’ll be the one integrating your scrapers into other systems, like databases.
However, cloud-based scraping software usually manages your data for you and allows you to download it in several formats based on your needs. Wanted or not, your data will always be stored on your provider’s server before getting into your hands.
Some vendors also provide analysis tools, which can be an advantage. Ultimately, it all comes down to how much control over the data you’re scraping, what you’re comfortable giving away, and the level of privacy you need for your project.
Related: Check out ScraperAPI’s structured data endpoints, enabling you to gather data in JSON format from Google SERPs, Amazon products, and more.
6. Website Complexity
Although the core technologies are the same (HTML, CSS, JavaScript, etc.), every website is a unique puzzle in itself, and some puzzles are just harder than others.
For example, it’s much simpler to scrape static HTML websites than scrape single-page applications (SPAs) that require a layer of rendering for your scraper to access the data.
In that sense, you’ll need to consider what websites you’ll be scraping and ensure the solution you choose can handle it correctly.
For example, ScraperAPI uses a headless browser instance to fetch the page, render it (as your regular browser would), and sends the HTML data back without you having to do more than just add a render=true parameter in your request.
Note: It’s crucial to take this rendering aspect out of your local machine, so avoid using headless browsers yourself while scraping. This is because you put your IP and API keys at risk when your headless browser fetches the resources it needs for rendering the page.
You also need to think about how changing these pages are. If a website changes its HTML structure or CSS selectors, it can easily break your scripts or scraping job (in the case of off-shelf tools).
Some solutions provide done-for-you parsers, allowing you to skip the maintenance of the scraper and collect formatted data (usually JSON) consistently without worrying about changes in the target site.
A good example is ScraperAPI’s Google SERP parser. After constructing your search query URL, ScraperAPI will return all SERP information in JSON format, saving you time and money when collecting search data.

7. IP Blocking/Anti-Scraping Resilience
One of the main reasons to use a web scraping tool is to avoid getting your bots blocked by anti-scraping mechanisms (like CAPTCHAs, Honeypot traps, Browser fingerprinting, etc.) and putting your IP at risk of bans and blocklists.
You’ll want to use a tool that:
- Counts with a healthy, ever-expanding, and well-maintained proxy pool
- Has a mix of data center, residential and mobile proxies in over 50 locations across the globe to better fit your needs – although is best if you don’t have to worry about these and the solution shuffles this for you automatically
- Uses statistical analysis and machine learning to determine the best combination of headers and IP addresses to guarantee a successful request
- Rotates IPs between every request automatically when needed
- Bypasses captchas and other bot protection mechanisms
- Use dynamic retries to ensure a successful request
ScraperAPI has all of these features and more (check our documentation here), but self-promotion aside, you’ll want to have these features at your disposal to be able to scale your data collection.
8. Geo-Targeting
Some websites serve different content based on your geographic location (e.g., eCommerce sites and search engines), while others can completely block you from accessing them. If your target websites fall into one of these two categories, then you’ll need to consider whether or not the tools you’re comparing count with the proxies you’ll need.
Let us explain it better.
When you use a proxy, your requests are not (necessarily) sent from an IP address in your country. Tools dynamically assign an IP address—in many cases, like ours, based on machine learning and statistical analysis—and the server will respond with the appropriate HTML document based on that IP geolocation.
Let’s say you send five requests to scrape the US version of an eCommerce category series. The web scraping tool will send each request with a different IP, and, for the sake of this example, imagine that it uses an IP from the US, Canada, the UK, Italy, and France.
If the server has a different version of the page for each of these countries, you’ll receive that page’s version instead of only the US version of all pages. So you’ll end up with one page in Italian, another in French, and three in English – but most likely with different content, pricing, and vocabulary. That’s what we mean by accurate data.
By using geo-targeting, you can specify from where you want your requests to be sent and get data as if a user from that country is going to the website. On the other hand, it’s very common for certain websites to block traffic from certain locations (think of international media being banned by totalitarian regimes), so changing the IP location will allow you to access these geo-blocked pages and protect your identity from being spotted.
If your project requires you to get localized data or access geo-blocked pages, geo-targeting is a must.
Note: It’s worth noting that some providers charge extra for this feature while others, like us, offer it for free. Learn more about ScraperAPI’s residential proxy and rotating proxy solutions. We offer free and paid plans.
9. Reliable Customer Support
This is more related to the provider and less about the tool itself, but more likely than not, you’ll run into challenges, and having a support team you can count on is crucial.
When considering a tool, think about the provider and their service. Some companies will help you set up your scrapers and help you optimize them where possible, while others might just answer your emails a couple of times a month.
It’s also important to understand how these providers offer their technical support. Sometimes, they just allow you to email them or submit a ticket. In other cases, providers—like us—offer a dedicated Slack support channel to respond in a more personalized and quick manner.
10. Web Scraping Pricing Structure and Transparency
Web scraping has become more difficult over the years, requiring new and better techniques to keep pipelines running. This has also made pricing web scraping solutions a bit trickier.
That being said, it’s important to understand how much you’re paying for how much data, which is not always very clear. Some tools charge by the size of the data collected (in terms of bytes, gigabytes, etc.), while others charge a subscription for a total number of API credits.
To help you understand the pricing structure of most modern web scraping tools, we wrote a web scraping pricing guide, explaining every detail and the language necessary to avoid hidden fees.
However, here are a few things to keep in mind:
- Check the tool’s documentation to understand how they charge for data
Some off-the-shelf solutions like Octoparse say they charge per website, but they actually use something called “workflow” (an automation task), so if you have to scrape 20 times that same website, they’ll charge you for each workflow run. - Pricing must be as transparent as possible, and every detail should be easy to find on the pricing page or in the documentation
That’s why we have a section dedicated to the cost of requests, breaking it down for each functionality. - Many scraping solutions offer similar functionality but price them differently
For example, ScraperAPI offers free geo-targeting in all its plans, while ScrapeIN charges 20 API credits.
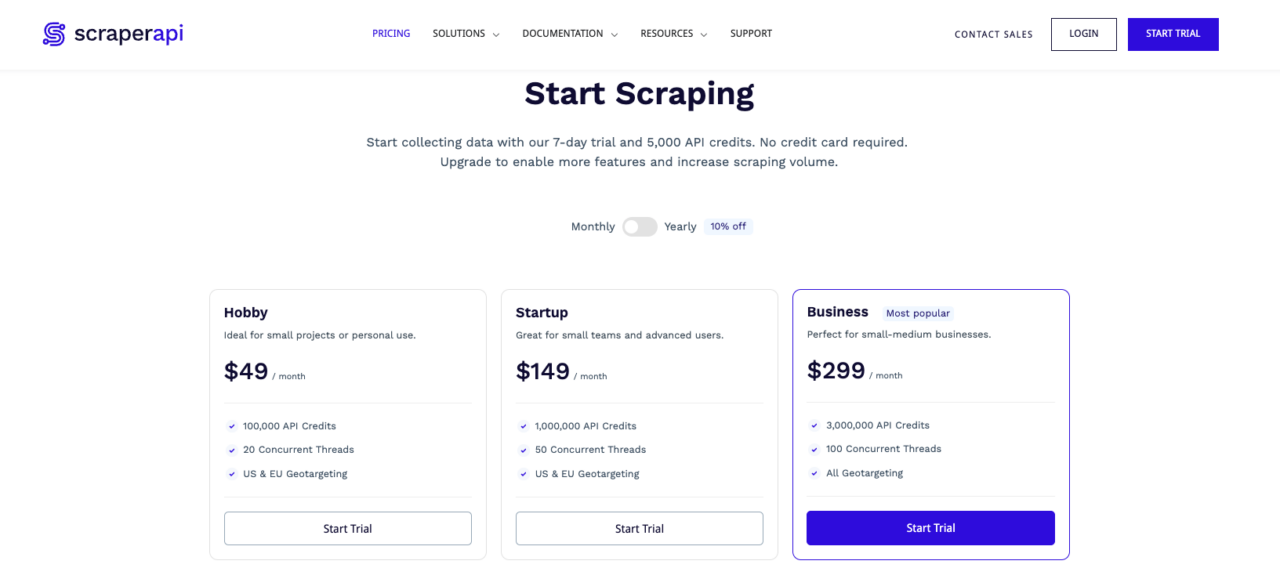
Here are the plans that are available from ScraperAPI. For the details of each plan, visit ScraperAPI’s pricing page.
ScraperAPI: The Best Data Extraction Tool For Any Web Scraping Need
We hope these ten factors empower you to make informed decisions when selecting the best web scraping tool for your data extraction projects.
If you find the decision-making process overwhelming, we recommend creating a list of your specific requirements based on the first nine factors. By evaluating these requirements against pricing, functionality, and scalability, you can identify the most suitable solution. ScraperAPI consistently excels in these areas compared to other web scraping tools.
Give ScraperAPI a try by creating a free account and enjoy 5000 free API credits with all our functionalities enabled. There’s no credit card needed, so you can see for yourself whether or not it’ll work for you.
If you have specific requirements, contact our sales team. We’ll help you make the best choice for your case.
Until next time, happy scraping!
Other web scraping guides that may interest you:





