


eBay, the third-largest e-commerce platform, boasts over a billion product listings, trailing only Amazon and Walmart. Access to fresh and reliable eBay data empowers online shops and retailers to analyze product pricing, identify trending products, understand seasonal purchasing behavior, and more. Web scraping emerges as the most effective method to collect eBay product data at scale.
In this eBay web scraping tutorial, you’ll learn how to extract valuable information (product details, prices, descriptions, etc.) from eBay using two approaches: Python and BeautifulSoup, and JavaScript. We’ll guide you through a step-by-step process, provide complete code examples, and recommend a web scraping tool to simplify the process without compromising results.
Is It Legal to Scrape eBay?
Before we dive into the eBay web scraping tutorial, let’s address a common concern: Is web scraping eBay legal?
Generally, web scraping eBay is legal as long as you avoid accessing data behind login walls or personal information without consent. However, the legality of web scraping can be complex due to conflicting interests and varying legal interpretations. To ensure ethical and legal practices, it’s essential to be mindful of the type of data you’re scraping, the extraction methods, and the intended use of the data.
In all of ScraperAPI’s web scraping guides, we focus on ethical practices to help you navigate this complex landscape. By following these guidelines, you can confidently extract valuable data from eBay without any legal repercussions.
Learn the details about the legality of scraping eBay and other websites here.
Web Scraping eBay Product Listings with Python – TL;DR
For those in a hurry, here’s the scraper we’ll build in this tutorial:
import requests
import json
from bs4 import BeautifulSoup
API_KEY = "YOUR_API_KEY"
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
payload = {"api_key": API_KEY, "url": url}
r = requests.get("https://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
result_list = []
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url["href"]
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image["src"]
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# print(result_list)
# Output the result in JSON format
output_json = json.dumps(result_list, indent=2)
# Write the JSON data to a file
with open("ebay_results.json", "w", encoding="utf-8") as json_file:
json_file.write(output_json)
print("JSON data has been written to ebay_results.json")
For this iteration, we’re sending our requests using ScraperAPI to bypass eBay’s anti-scraping mechanisms and handle the technical complexities when scaling the project.
Note: Replace API_KEY in the code with your own ScraperAPI API key.
How to Scrape eBay with Python
Python is one of the best languages for web scraping due to its user-friendliness, simple syntax, and wide range of available libraries.
To scrape eBay with Python, we will use the Requests library and BeautifulSoup for HTML parsing. Additionally, we’ll send our requests through ScraperAPI to avoid any anti-scraping measures.
What You Need to Build a Python eBay Data Extractor
This eBay web scraping tutorial is based on Python 3.10, but it should work with any Python version starting from 3.8. Ensure you have a compatible Python version installed before proceeding.
Now, let’s initiate a Python project within a virtual environment named “ebay-scraper.” Execute the following commands sequentially to set up your project structure:
mkdir ebay-scraper
cd ebay-scraper
python -m venv env
This is what each line of the commands above does for proper understanding:
- First, t creates a directory named “ebay–scrapper”
- Then, it switches your terminal to the actual directory where you are currently building
- Finally, t locally creates the Python virtual environment for the project
Enter the project folder and add a main.py file. This file would soon contain the logic to scrape eBay.
You’ll also need to install the following Python libraries:
- Requests: This library is widely regarded as the most popular HTTP client library for Python. It simplifies the process of sending HTTP requests and handling responses which will enable you to download eBay’s search result pages.
- BeautifulSoup: This is a comprehensive Python HTML and XML parsing library. It helps to navigate through the webpage’s structure and extract the necessary data.
- lxml: This library is known for its speed and feature-rich capabilities for processing XML and HTML in Python.
You can easily install these libraries together using the Python Package Installer (PIP):
pip install requests beautifulsoup4 lxml
With these prerequisites in place, you are all set to move on to the next step!
Understanding eBay Search Results Page Structure
When you search for a specific term, like “airpods pro,” eBay will show results similar to the page below:
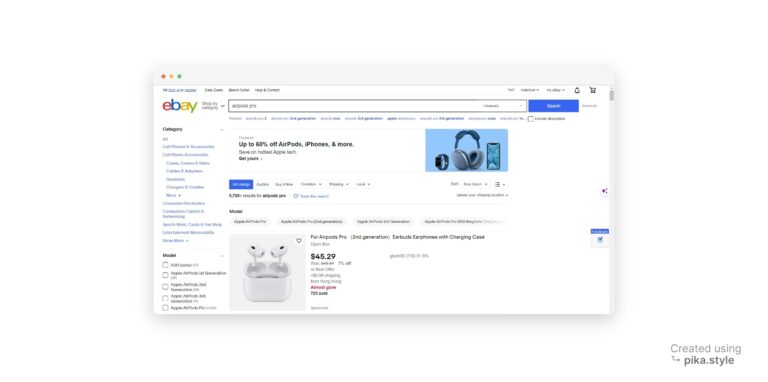
All products listed under “airpods pro” can be extracted, as well as their links, titles, prices, ratings, and images.
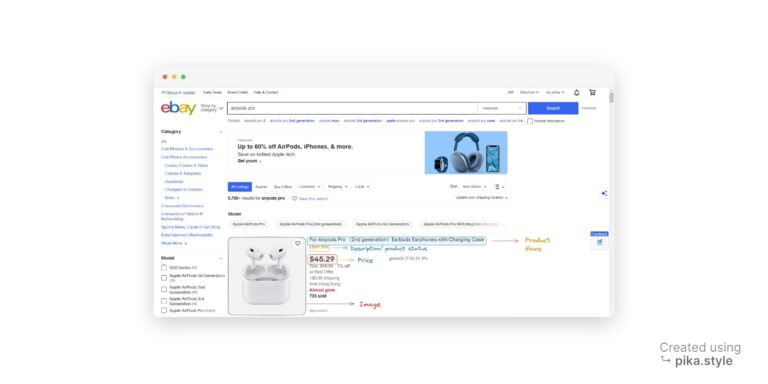
Before start writing your script, it is critical to determine what data you intend to collect. For this project, we’ll focus on extracting the following product details:
- Product Name
- Price
- Product Image
- A Brief Product Description
- The product URL
In the screenshot below, you’ll see where to find these attributes:
Now that we know what information we’re interested in and where to find it, it’s time to build our scraper.
Step 1: Setting Up Our eBay Python Web Scraping Project
Open your code editor and add the following lines of code to import our dependencies:
import requests
from bs4 import BeautifulSoup
import csv
Note: we also imported the CSV library as we want to export our data in this format.
Next, we need to set up the URL of the eBay page we want to scrape. In this example, we will be searching for “airpods pro“. Your URL should be like this:
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
Step 2: Send the Request and Parse the HTML
Now, let’s send a GET request to the eBay page and parse the HTML using BeautifulSoup.
html = requests.get(url)
print(html.text)
This code uses the requests library to send a “GET request” to our eBay search results page and retrieves the HTML content of the web page, and stores it in the html variable.
However, as soon as you run this code, you will realize that eBay has put some anti-bot measures in place.
You can bypass this anti-bot measure by sending a proper user-agent header as part of the request to mimic a web browser:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
To parse the HTML content, the code creates a BeautifulSoup object by passing html.text and the parser type (lxml) to the BeautifulSoup() function. This allows us to navigate and extract data from the HTML easily.
Step 3: Find the Product Items on the Page
We generally need to understand the HTML layout of a page to scrape the results out. This is an important and critical part of web scraping.
Nonetheless, do not fret if you are not too skillful with HTML.
We will utilize Developer Tools, a feature available in most popular web browsers, to scrape our required data.
When on the search results page, do “inspect element” and open the developer tools window. Alternatively, press “CTRL+SHIFT+I” for Windows users or “Option + ⌘ + I” on Mac

In the new window, you will find the source code of the target web page. In our case, all the products are mentioned as list elements, so we have to grab all these lists.
In order to grab an HTML element, we need to have an identifier associated with it. It can be an id of that element, any class name, or any other HTML attribute of the particular element.
In our case, we are using the class name as the identifier. All the lists have the same class name, i.e. s-item.
On further inspection, we got the class names for the product name and product price, which are “s-item__title” and “s-item__price”, respectively.
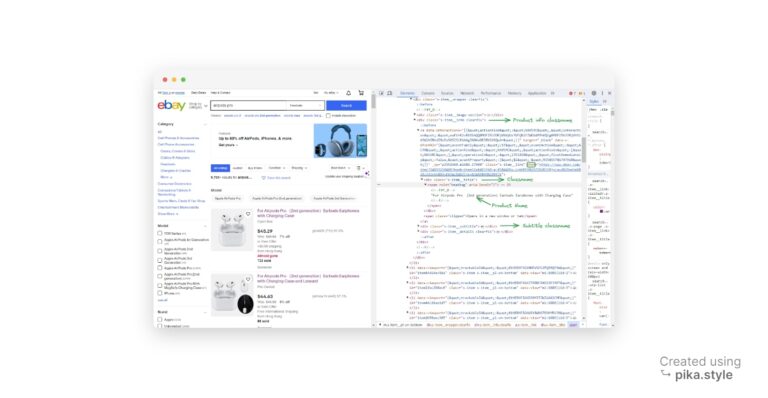
The next step is to find the product items on the page. The code uses the find_all() method of the BeautifulSoup object to find all the div elements with the class “s-item__info clearfix“.
These div elements represent the product items on the page. The program also finds the corresponding image containers using the same approach.
Add the following lines of code to your file:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
html = requests.get(url)
print(html.text)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
Step 4: Extract the Desired Information
For each product item, we will extract the title, price, product URL, product status, and image URL.
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
html = requests.get(url)
print(html.text)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
result_list = []
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url["href"]
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image["src"]
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
Inside a loop, the code extracts the title, price, product URL, product status, and image URL for each product item. It uses the find() method of the BeautifulSoup object to find specific elements within each product item div.
The extracted data is then stored in a dictionary called result_dict and appended to the result_list.
Step 5: Write the Results to a CSV File
After extracting the data, we create a CSV file called “ebay_results.csv” in write mode using the open() function.
with open("ebay_results.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["title", "price", "image_url", "status", "link"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# Write the header row
writer.writeheader()
# Write the data rows
for result in result_list:
writer.writerow(result)
It creates a DictWriter object from the CSV library to write the data to the CSV file. The “fieldnames” parameter specifies the column names in the CSV file.

We can also print the extracted data to the console.
for result in result_list:
print("Title:", result["title"])
print("Price:", result["price"])
print("Image URL:", result["image_url"])
print("Status:", result["status"])
print("Product Link:", result["link"])
print("\n")
The code above iterates over each item in the result_list and prints the corresponding values for each key. In this case: the title, price, image URL, product status, and product URL.

The Full Scraping Code of eBay Python Web Scraper
Now that we have all of the puzzle pieces in place, let’s write the complete scraping code. This code will combine all the techniques and steps we’ve discussed, enabling you to collect eBay product data in a single step.
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US, en;q=0.5",
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, "lxml")
result_list = []
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url["href"]
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image["src"]
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# Write the result_list to a CSV file
with open("ebay_results4.csv", "w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["title", "price", "image_url", "status", "link"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# Write the header row
writer.writeheader()
# Write the data rows
for result in result_list:
writer.writerow(result)
# Print the result list
for result in result_list:
print("Title:", result["title"])
print("Price:", result["price"])
print("Image URL:", result["image_url"])
print("Status:", result["status"])
print("Product Link:", result["link"])
print("\n")
Web Scraping eBay with Cheerio (JavaScript)
If you’ve been following our tutorial series, you know that we’ve gone through the basics of web scraping in JavaScript and built a more complex LinkedIn scraper using a for loop and the network tab in chrome’s DevTools.
Note: You don’t need to read those first to understand this tutorial, but it might help to get a clearer picture of our thought process.
To build on top of that, we’ll create an async function to scrape the name, price, and link of 4k TVs on eBay and then export the data into a CSV using the Object-to-CSV package.
How to Scrape eBay Listings with JavaScript (Cheerio)
Understanding eBay’s URL Structure
Let’s go to https://www.ebay.com/ and search for “4k smart tv” on the search bar to grab our initial URL.
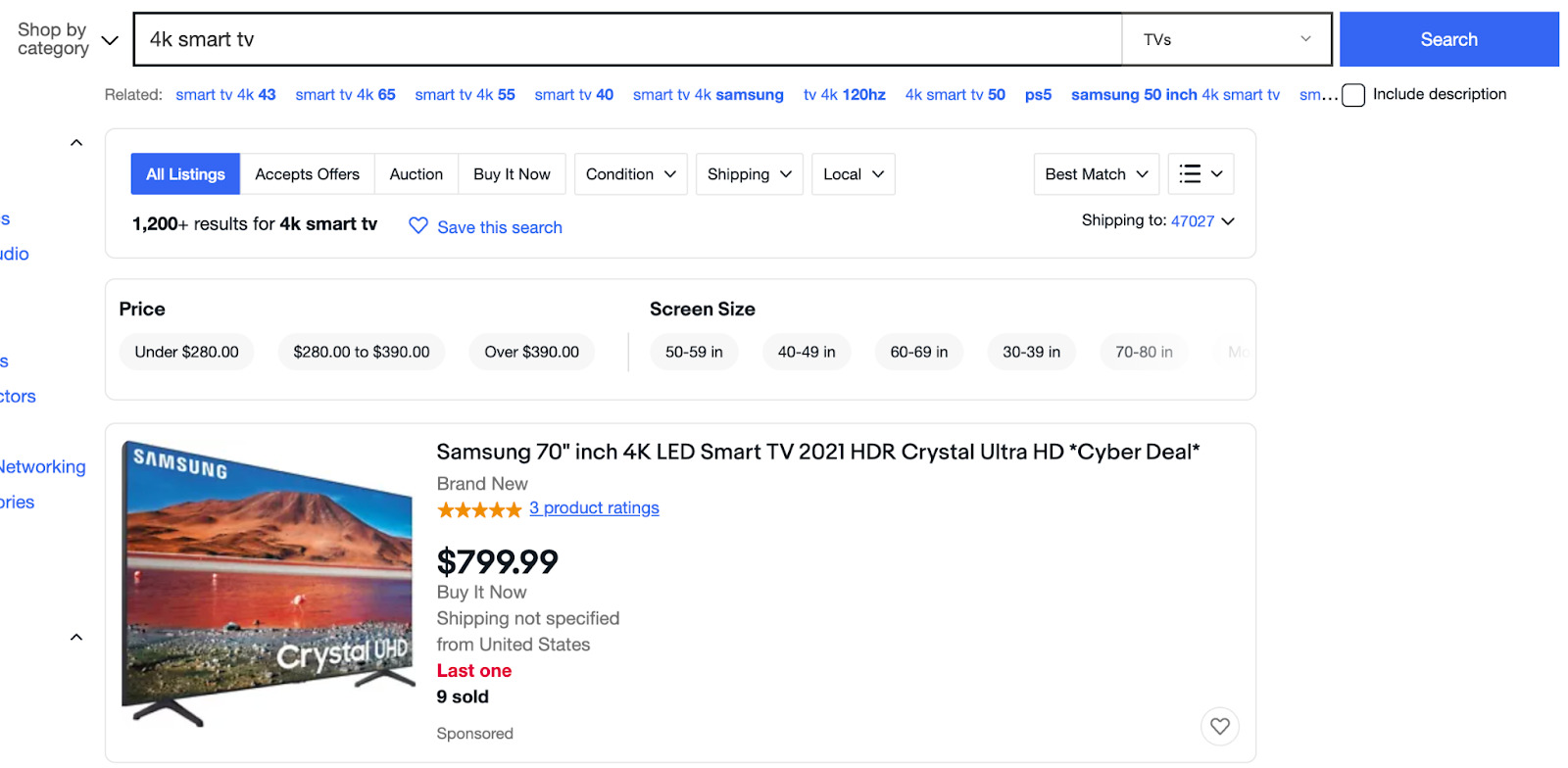
It sends us to the following URL:
https://www.ebay.com/sch/i.html?_from=R40&trksid=p2380057.m570.l1312&nkw=4k+smart+tv&sacat=0
If we were to scrape just this eBay page, we could stop at this point and start writing our code. However, we want to see how it changes when moving through the pagination to understand how we can tell our script to do the same.
At first glance, it seems like the _sacat parameter stores the page number, so if we change it, it would be enough. Because eBay uses a numbered pagination, we can just click on the “Next” button and see how the URL changes.

https://www.ebay.com/sch/i.html?_from=R40&nkw=4k+smart+tv&sacat=0&pgn=2
This is quite different from what we had before. So let’s go back and see if it returns to the previous version.
https://www.ebay.com/sch/i.html?_from=R40&nkw=4k+smart+tv&sacat=0&pgn=1
No, it uses the “new” version of the URL when we use the pagination. This is great! All we need to do is change the _pgn parameter, and it will move to the next page. We confirmed this by just changing the number in the addressed bar.
Awesome, we’ll use this new version as our base URL for the HTTP request and later on to allow us to scrape every page in the series.
Step 1: Testing for JavaScript
Now that we have a consistent URL structure to work with, we need to test the website’s source code and make sure the data we want is available in the HTML and not injected through JavaScript – which would change our whole approach.
Of course, we already told you we were using Cheerio, so you know we’re not dealing with JavaScript, but here’s how you can test this for any website in the future.
Go to the page you want to scrape, right-click and click on “View Page Source”.
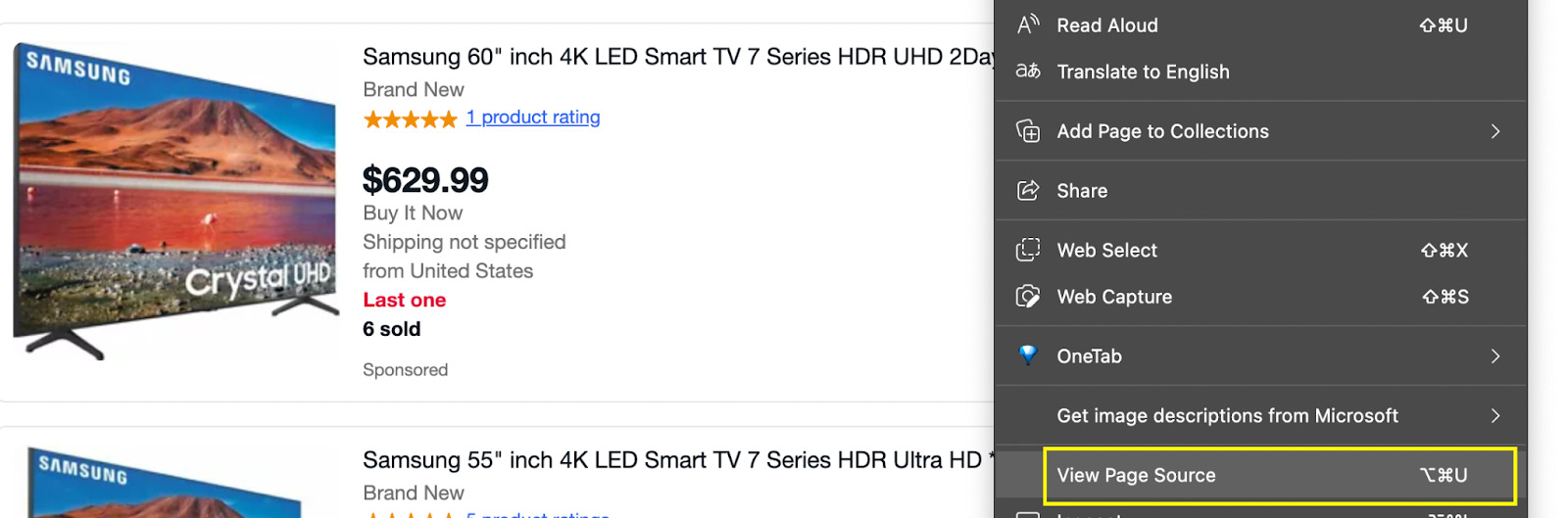
It will show you the site’s source code before any AJAX injection. We’ll copy the name and look for it in the Page Source for the test.
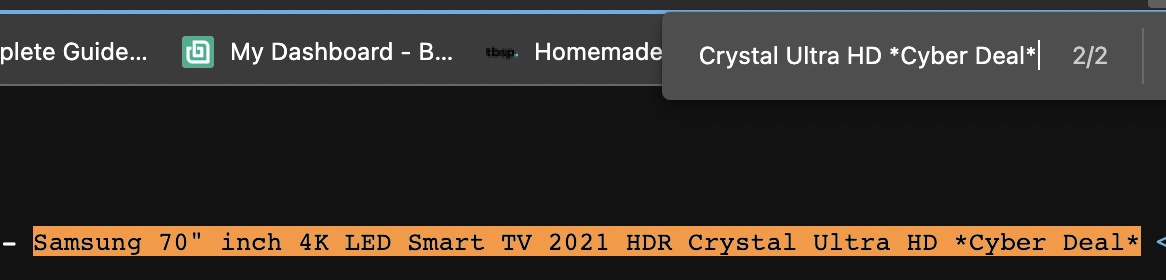
And next is the price.
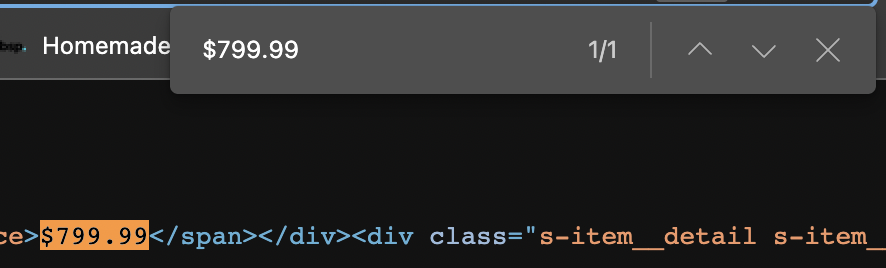
We did the same with a few other products just to be sure, and we could find the element every time.
This step will tell us if we can go ahead and access the data using Axios and Cheerio or if we’ll need to use a tool like ScraperAPI’s JavaScript rendering to load the JS or a headless browser like Puppeteer.
Step 2: Sending Our HTTP Request with Axios
The fun part begins! Let’s create a new folder for our project, open it on VScode (or your favorite editor) and start it with npm init -y to create the initial package.json file. From there, we can install Axios, a great and simple tool to send HTTP requests with Node.js, with npm install axios.
To send and test the request, let’s create a new file called index.js (original, we know), require Axios at the top, and create an async function. Inside it, we’ll send our request using Axios and store the response’s data inside a variable called html for clarity.
const axios = require('axios');
(async function () {
const response = await axios('https://www.ebay.com/sch/i.html?_from=R40&nkw=4k+smart+tv&sacat=0&pgn=1');
const html = await response.data;
})();
Because we’re using async, we now have access to the await operator which is “used to wait for a Promise,” making it a great tool for web scraping, as our code will be more resilient.
Let’s console.log() the html variable to verify that our request is working:
console.log(html)
Ah yes! A bunch of nonsense, as expected.
Step 3: Parsing the Raw HTML with Cheerio
Before extracting our elements, we need to parse the raw data we downloaded to give it a structure we can navigate. That’s where Cheerio comes in!
We’ll create a new variable and pass html to cheerio using cheerio.load():
const $ = cheerio.load(html);
From there, let’s head back to the website to find our selectors.
Note: Don’t forget to install Cheerio with npm install cheerio before using it.
Step 4: Picking the Right Selectors
The first thing we’re looking for is the element that contains all the data we’re looking for. So every product seems to be contained within a card, right?
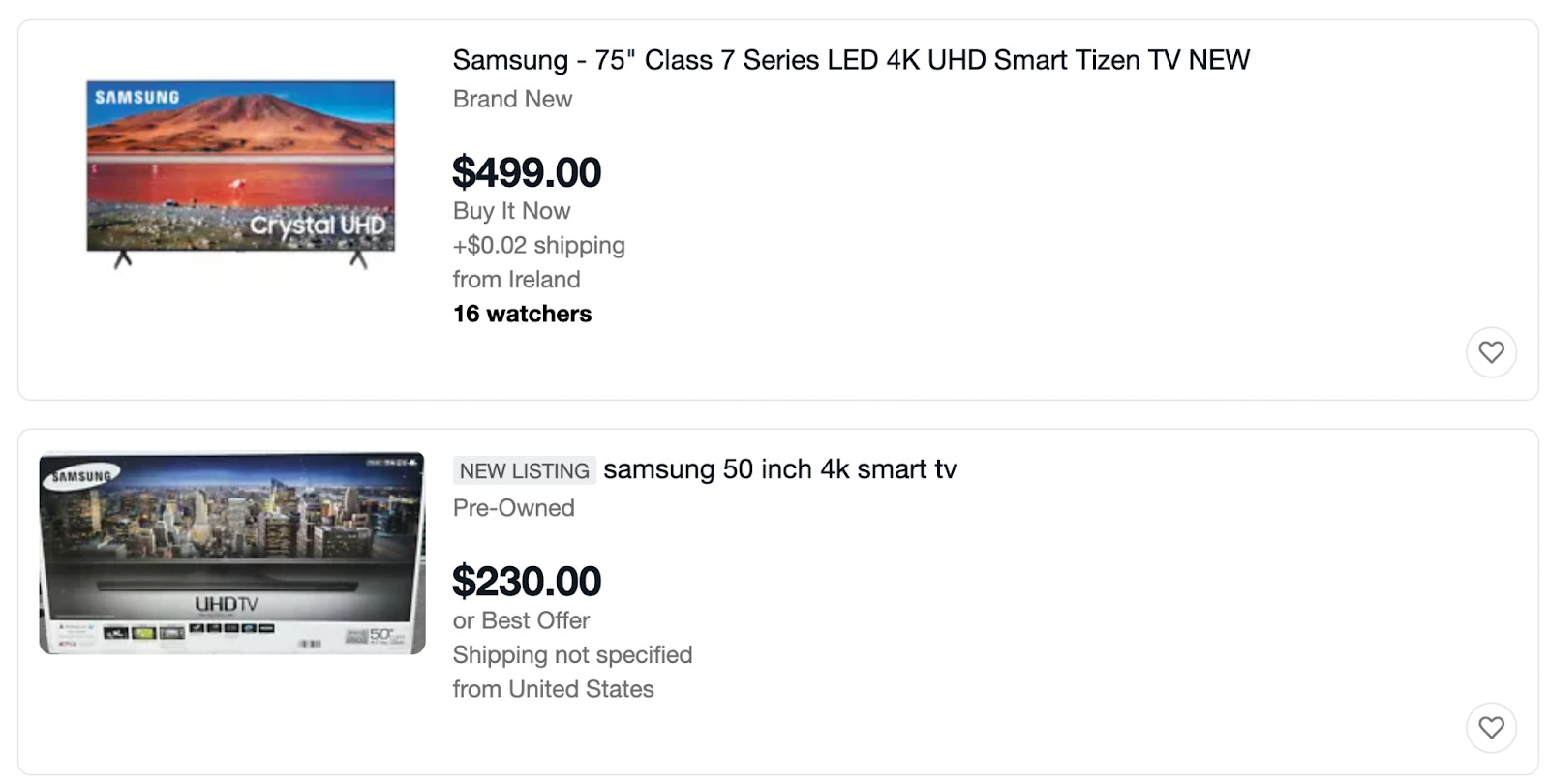
We want to grab the element that contains all cards so we can then iterate through the list and extract the information we want (name, price, and URL – to refresh your memory).
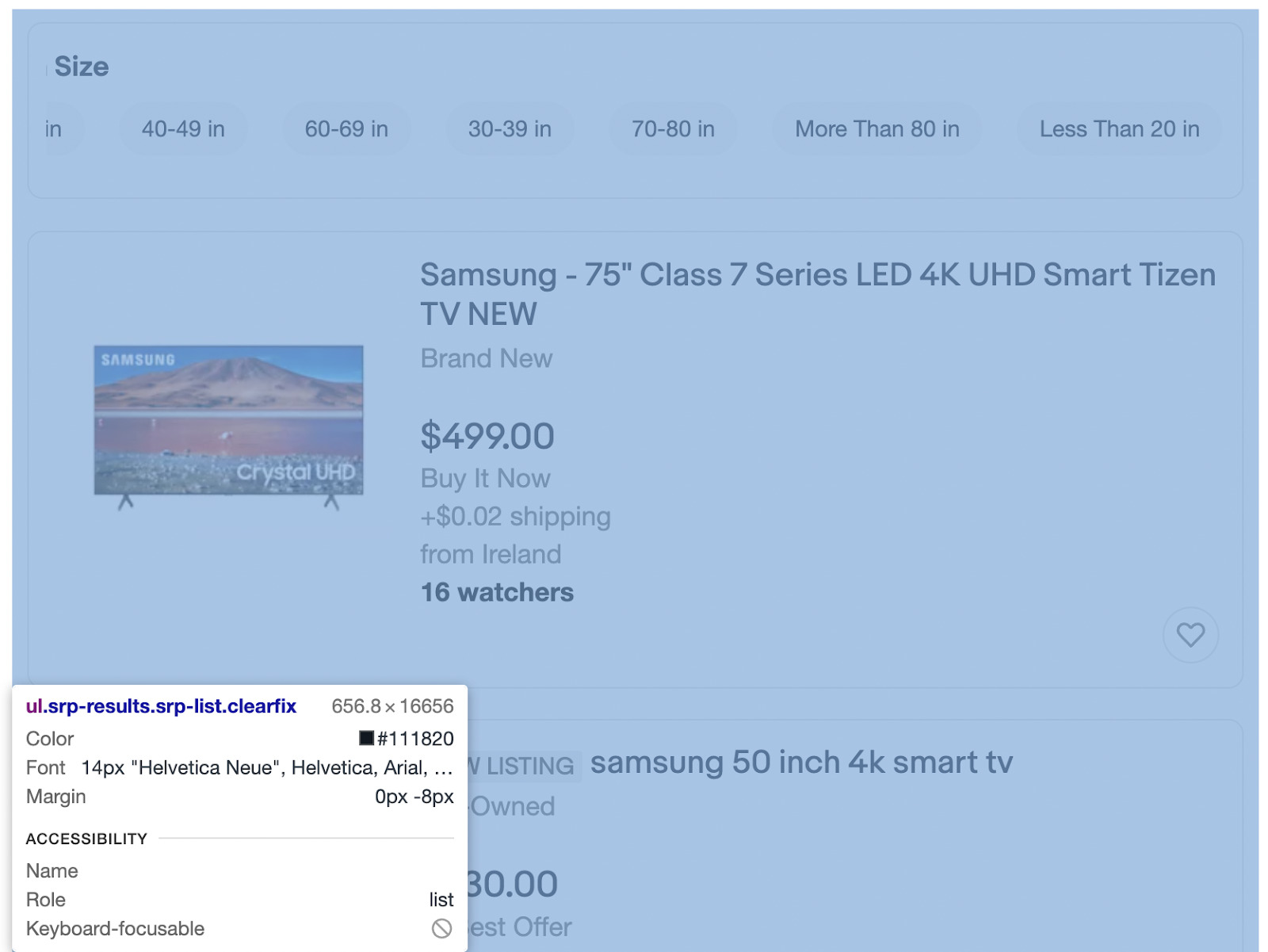
This ul element wraps all product cards, so it is a great starting point to explore the HTML structure a little bit more.
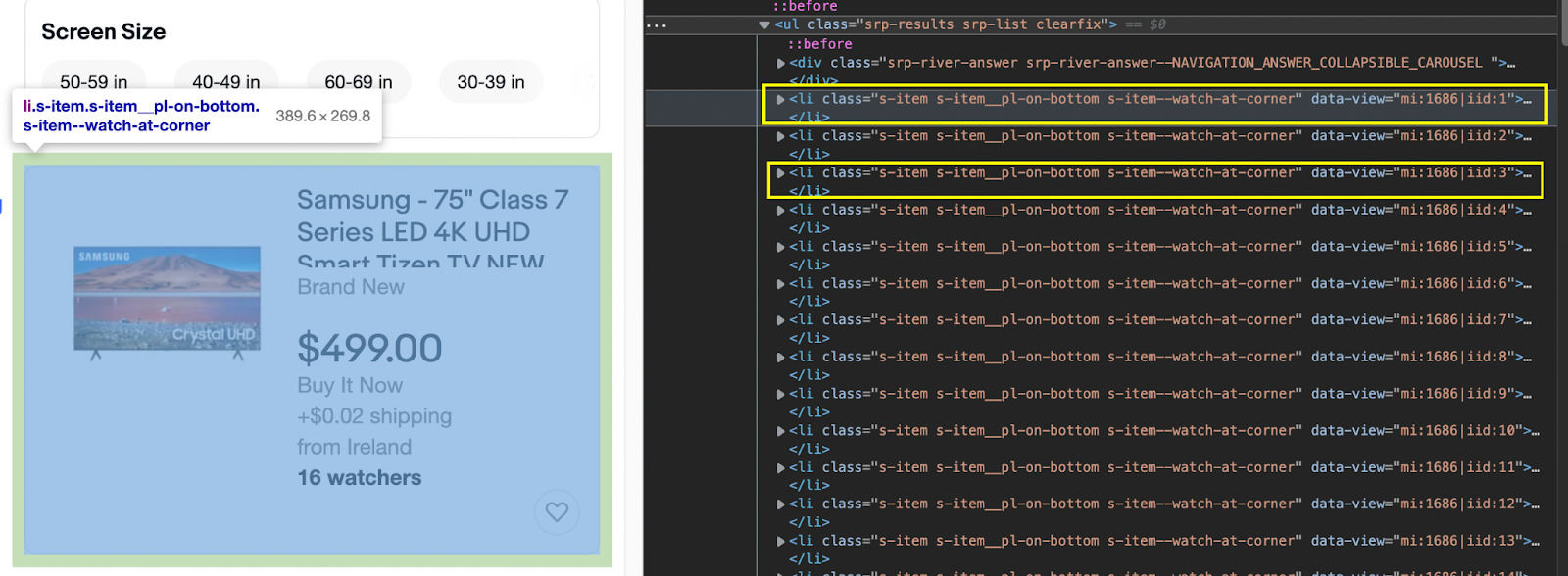
Like we thought, every product card is a li element within the ul. All we need to do is grab all the li elements and assign them to a variable, effectively creating an array we can then go through to extract the data.
For testing, let’s open the browser’s console and use the li element’s class and see what gets returned:
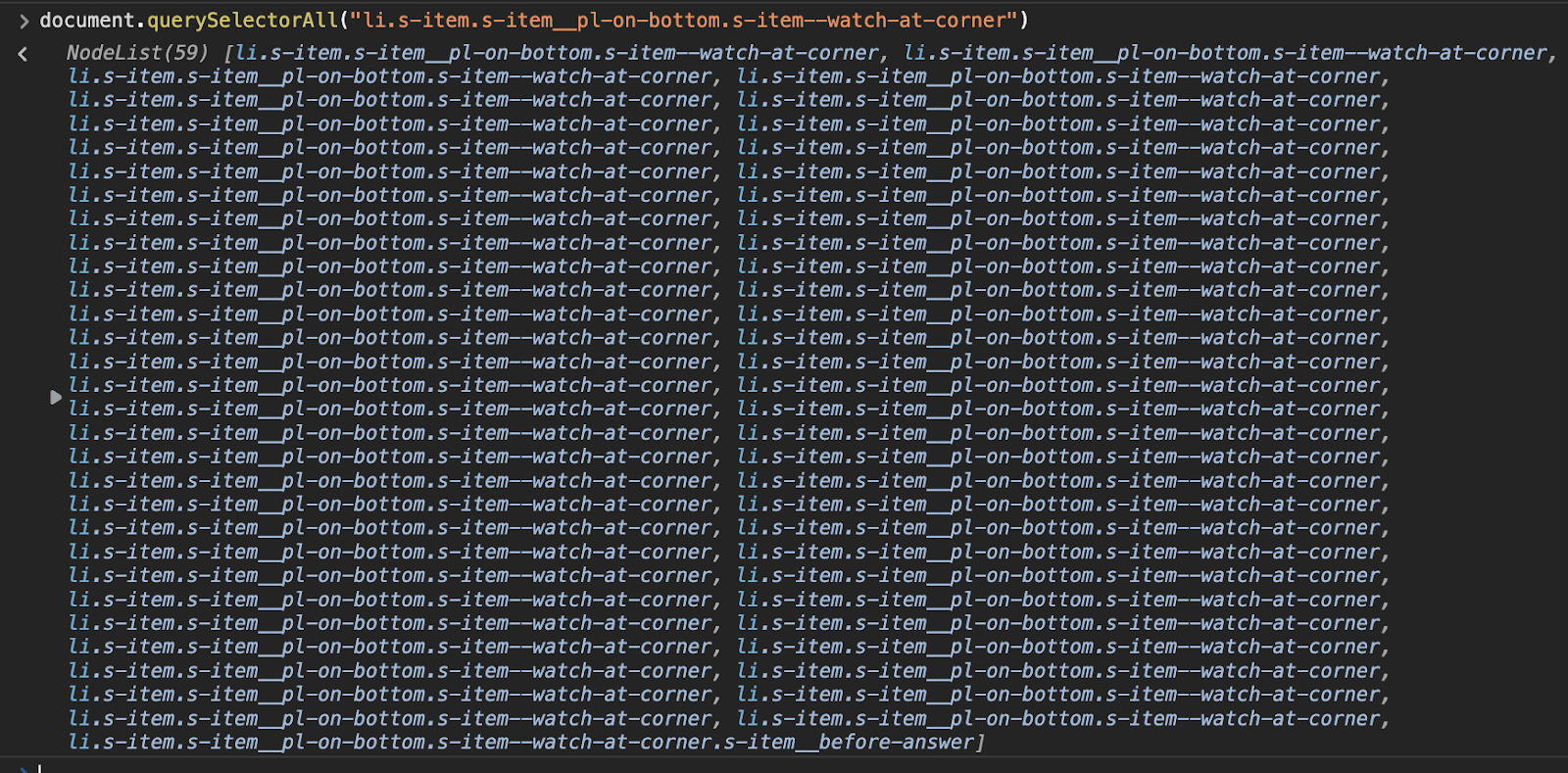
Unlike Python’s Scrapy, Cheerio doesn’t have a built-in shell for testing, but we can use the console to test the selectors without having to send a request every time. We did the same thing with the rest of the elements.
We’ll pick the only h3 tag inside of each element within the list for the name.
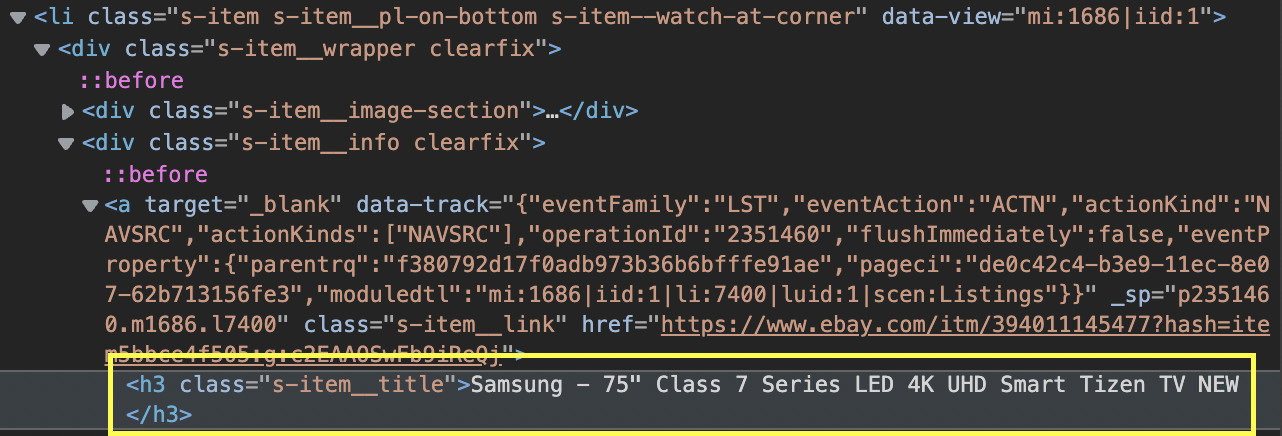
In the case of the price, it’s wrapped within a span element with the class “s-item__price.”

Technically it would still work for us because we’ll be telling our scraper to look for the element inside the list. However, just to be sure, we’ll be going up in the hierarchy and grabbing the div containing the URL and then moving down to the a tag itself like this: 'div.s-item__info.clearfix > a'.
Step 5: Extracting eBay Data
So the logic would be like this:
// Pick all li elements
// Go through each element within the list and extract the:
// tvName, tvPrice, tvLink
Let’s put it all together now, as we already know the selectors:
const tvs = $('li.s-item.s-item__pl-on-bottom.s-item--watch-at-corner');
tvs.each((index, element) => {
const tvName = $(element).find('h3')
const tvPrice = $(element).find('span.s-item__price')
const tvLink = $(element).find('div.s-item__info.clearfix > a')
})
However, we’re not done yet. We need to add a new method at the end of each string, otherwise, we’ll be getting the entire HTML information which isn’t what we want.
We want the text inside the element for the name and price, so all we need to do is add the text() method at the end. For the URL, we want the value stored inside the href attribute, so we use the attr() method and pass the attribute we want the value from.
const tvs = $('li.s-item.s-item__pl-on-bottom.s-item--watch-at-corner');
tvs.each((index, element) => {
const tvName = $(element).find('h3').text()
const tvPrice = $(element).find('span.s-item__price').text()
const tvLink = $(element).find('div.s-item__info.clearfix > a').attr('href')
})
We could log each variable to the console but we would be getting a lot of messy data. Instead, let’s give it some structure before testing the scraper.
Step 6: Pushing the Extracted eBay Data to an Empty Array
This is actually quite an easy process that will help us to organize the data and making it ready to export.
First, we’ll create an empty array outside our function.
const scrapedTVs = [];
From inside the function, we can call this variable and use the push() method to add all elements to our empty array. We’ll add the following snippet of code inside tvs.each(), right after the tvLink variable:
scrapedTVs.push({
'productName': tvName,
'productPrice': tvPrice,
'productURL': tvLink,
})
Run the test with a console.log(scrapedTVs) and see what we get:
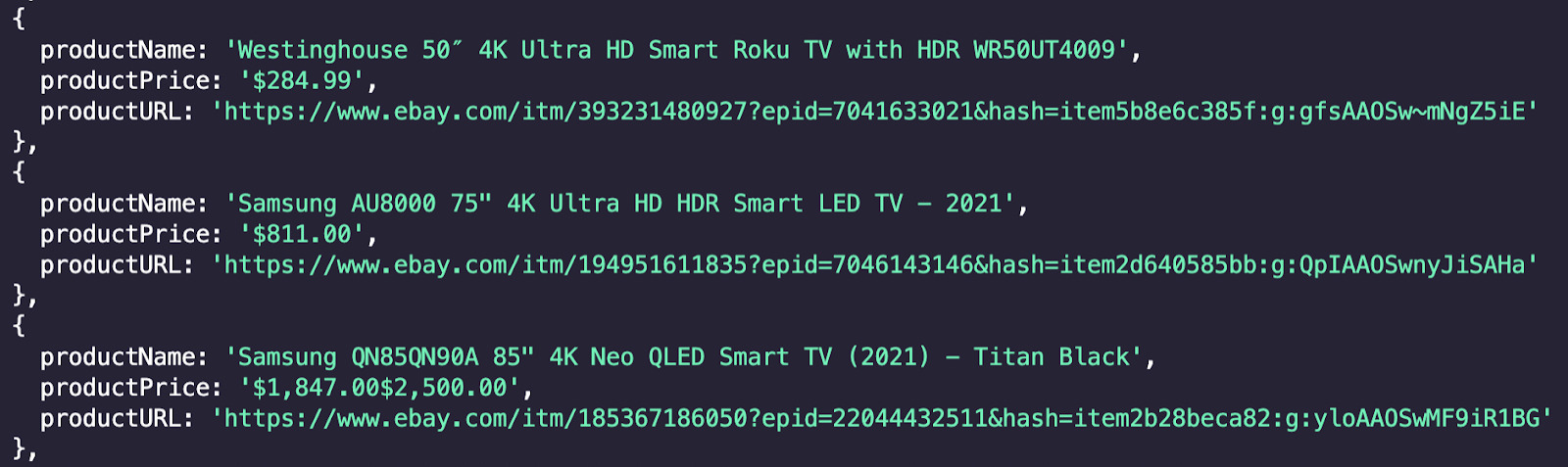
Nothing can beat the feeling of our code working! Our data is structured and clean. In perfect shape to be exported.
Step 7: Exporting the Extracted Data to a CSV File
Exporting data into a CSV is made super simple with the ObjectsToCsv package. Just npm i objects-to-csv and add it to the dependencies at the top.
const ObjectsToCsv = require('objects-to-csv');
ObjectsToCsv has an easy syntax:
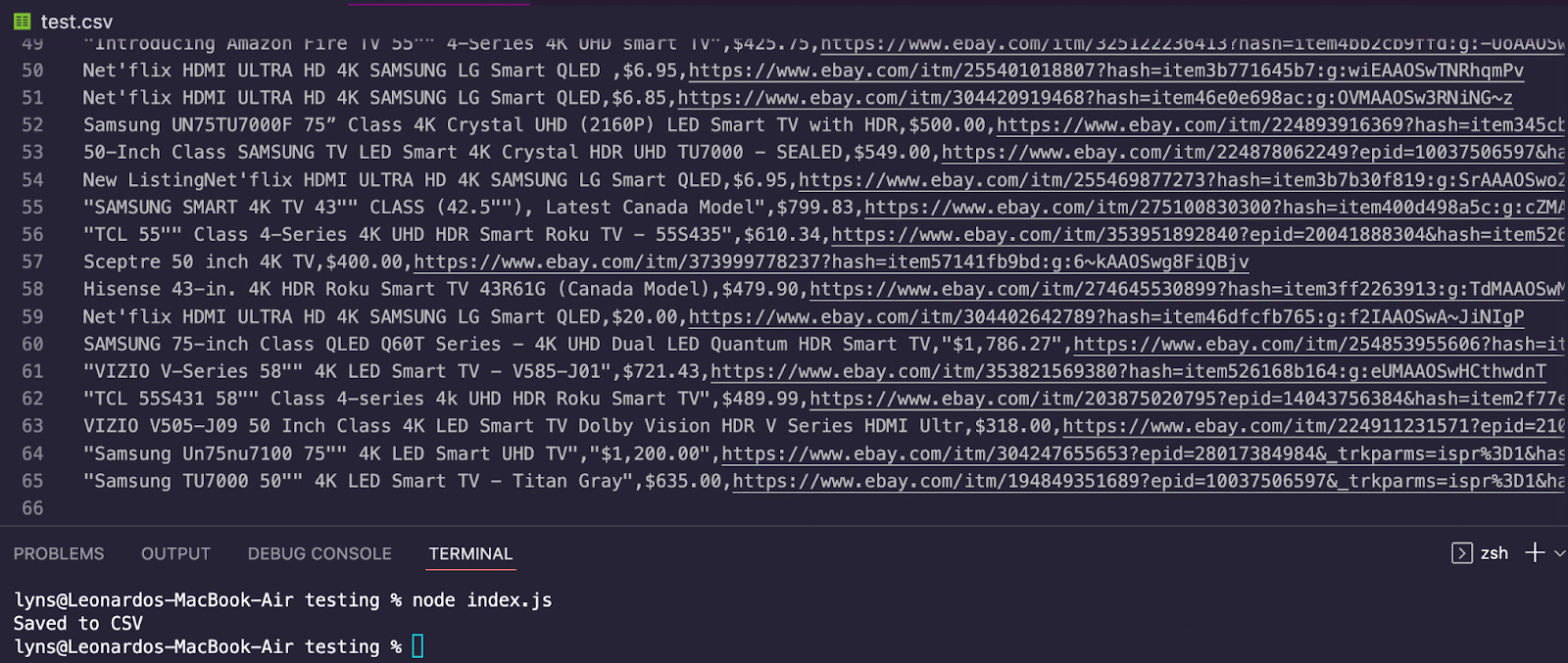
const csv = new ObjectsToCsv(scrapedTVs)
await csv.toDisk('./test.csv', { append: true })
console.log("Saved to CSV")
To create initiate the export, we need to create a new ObjectsToCsv() instance and pass it our dataset. Then, we’ll await the promise to resolve and save the result into a CSV file by giving it the path. We’re also setting append to true (it’s false by default) because we’re going to be adding more data to it from each page of the pagination.
For testing, we’ll log “Saved to CSV” to the console:
Step 8: Scrape eBay’s Pagination
We already know we can scrape all pages inside the pagination by changing the _pgn parameter in the URL. So for this project, we can implement a for loop that changes this number after every iteration.
But we also need to know when to stop. Let’s head back to the website and see how many pages the pagination has.

It caps at 21. However, if we push the URL and add a 22 in the parameter, the page still responds with a page, but it loads the last page of the series, in other words, page 21.
We now can write the three statements for the for loop and put everything inside of it:
let pageNumber = 1 //to set the initial state
pageNumber & <= 21 //it'll run as long as pageNumber is less or equal to 21
pageNumber += 1 //after running, pageNumber increments by 1
Here’s how it should look like:
for (let pageNumber = 1; pageNumber & <= 21; pageNumber += 1) {
}
If we put all our previous code inside this for loop (which is inside of our async function), it’ll keep running until it meets the condition and breaks. Still, there are two changes we need to make before we call it for the day.
First, we need to add the pageNumber variable inside the URL, which can be done using ${} and a backtick (`) to surround the string. Like this:
`https://www.ebay.com/sch/i.html?_from=R40&nkw=4k+smart+tv&sacat=0&pgn=${pageNumber}
The second change we’ll want to make is sending our request through ScraperAPI servers to handle IP rotation and headers automatically. To do so, we’ll need to create a free ScraperAPI account. It’ll provide us with an API key and the string we’ll need to add to the URL for it to work:
`https://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.ebay.com/sch/i.html?_from=R40&nkw=4k+smart+tv&sacat=0&pgn=${pageNumber}`
This way we can avoid any kind of anti-scraping mechanism that could block our script.
The Full Scraping Code for eBay Cheerio (JavaScript) Web Scraper
Here’s the finished code ready to use:
//Dependencies
const axios = require('axios');
const cheerio = require('cheerio');
const ObjectsToCsv = require('objects-to-csv');
//Empty array
const scrapedTVs = [];
(async function () {
//The for loop will keep running until pageNumber is greater than 21
for (let pageNumber = 1; pageNumber & <= 21; pageNumber += 1) { //Sends the request, store the data and parse it with Cheerio const response = await axios(`https://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.ebay.com/sch/i.html?_from=R40&nkw=4k+smart+tv&sacat=0&pgn=${pageNumber}`); const html = await response.data; const $ = cheerio.load(html); //Grabs all the li elements containing the product cards const tvs = $('li.s-item.s-item__pl-on-bottom.s-item--watch-at-corner'); //Goes through every element inside tvs to grab the data we're looking for tvs.each((index, element) => {
const tvName = $(element).find('h3').text()
const tvPrice = $(element).find('span.s-item__price').text()
const tvLink = $(element).find('div.s-item__info.clearfix > a').attr('href')
//Pushes all the extracted data to our empty array
scrapedTVs.push({
'productName': tvName,
'productPrice': tvPrice,
'productURL': tvLink,
})
});
//Saves the data into a CSV file
const csv = new ObjectsToCsv(scrapedTVs)
await csv.toDisk('./scrapedTVs.csv', { append: true })
//If everything goes well, it logs a message to the console
console.log('Save to CSV')
}
})();
How to Turn eBay Pages into LLM-Ready Data
Scraping raw data from a website like eBay is just the beginning. If you’re planning to feed that data into a large language model (LLM) like Gemini or GPT, structure matters a lot more than you think. LLMs thrive on clean, readable formats, such as plain text or Markdown.
In this section, I’ll show you how to use ScraperAPI with the output_format=markdown parameter to fetch eBay listings in a format that’s perfect for LLM processing. Then, we’ll feed that into Google Gemini to summarize and extract insights.
Step 1: Get Your API Keys
Before we start, ensure you have both a ScraperAPI key and a Google Gemini API key. If you already have them, you can skip to the next step. You can obtain your ScraperAPI key from your dashboard or sign up here to receive a free one with 5,000 API credits.
To obtain a Gemini API key:
- Go to Google AI Studio
- Sign in with your Google account
- Click on Create API Key
- Follow the prompts to generate your key
Step 2: Extract eBay Search Results as Clean Markdown
Instead of spending time parsing HTML manually like we did earlier, ScraperAPI lets you request the rendered page in Markdown format using the output_format=markdown parameter. This instantly gives you cleaner, more structured output that’s easier for an LLM to understand and work with.
Here’s the code to get started:
import requests
API_KEY = "YOUR_SCRAPER_API_KEY"
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
payload = {
"api_key": API_KEY,
"output_format": "markdown",
"country": "us",
"url": url
}
response = requests.get("https://api.scraperapi.com", params=payload)
markdown_data = response.text
print(markdown_data)
This returns a full Markdown-rendered version of the search results page, including titles, prices, seller info, and more.
A sample of the Markdown output would look like this:
**Top Rated Plus**
* Sellers with highest buyer ratings
* Returns, money back
* Ships in a business day with tracking
[Learn More](https://pages.ebay.com/trp/index.html)Top Rated Plusamazing-wireless (146,417) 99.6%
* [](https://www.ebay.com/itm/205453578546?%5Fskw=airpods+pro&itmmeta=01JSZEY2HD8HB6Z2RR9T28F307&hash=item2fd5fcd132:g:IlQAAeSwVbpoEAU7&itmprp=enc%3AAQAKAAAA8FkggFvd1GGDu0w3yXCmi1cTktUH6hFH2fgZxtunc4RgFpIW77YeGZpozpkz1UAkLwye8GD7OYFV%2B4w4Wli%2Ff7JOsBF2DQCJfqYyTexUJ1PVVIj%2BYnxloObMIP34h25sztLuUqLnYpVwkV4UZ8xJ9gc3aRZoSuPCKhqscyAR1mX2bzj2VE%2FgkelkxeKH4nXwa4VT%2FQaxdtOs2jXrKxyfiTSAZIaezN%2FWyWRZK8SuAzvWAJFIGHRuF3qs4cjaNjGYDqnSv36%2BTQcnYRautsSitkY%2BKidQLFaYwqaKIEbqnFRYVaUObwrBZxfSA6%2BLHOOJUw%3D%3D%7Ctkp%3ABFBM-Kj47s9l)
[New ListingAirPods Pro 2nd Generation with MagSafe Wireless Charging Case (USB‑C)Opens in a new window or tab](https://www.ebay.com/itm/205453578546?%5Fskw=airpods+pro&itmmeta=01JSZEY2HD8HB6Z2RR9T28F307&hash=item2fd5fcd132:g:IlQAAeSwVbpoEAU7&itmprp=enc%3AAQAKAAAA8FkggFvd1GGDu0w3yXCmi1cTktUH6hFH2fgZxtunc4RgFpIW77YeGZpozpkz1UAkLwye8GD7OYFV%2B4w4Wli%2Ff7JOsBF2DQCJfqYyTexUJ1PVVIj%2BYnxloObMIP34h25sztLuUqLnYpVwkV4UZ8xJ9gc3aRZoSuPCKhqscyAR1mX2bzj2VE%2FgkelkxeKH4nXwa4VT%2FQaxdtOs2jXrKxyfiTSAZIaezN%2FWyWRZK8SuAzvWAJFIGHRuF3qs4cjaNjGYDqnSv36%2BTQcnYRautsSitkY%2BKidQLFaYwqaKIEbqnFRYVaUObwrBZxfSA6%2BLHOOJUw%3D%3D%7Ctkp%3ABFBM-Kj47s9l)
Open Box
$90.00
or Best Offer
Free delivery
The full Markdown output will include several products like this. You can feed the raw markdown_data directly into a large language model (LLM) for analysis without needing additional HTML parsing.
Step 3: Summarize the Results with Gemini
Now that we have a clean, easy-to-parse Markdown listing from eBay, it’s time to put it to work. In this step, we’ll use Google’s Gemini LLM to analyze and summarize the product listings. By prompting a large language model (LLM) with well-formatted Markdown, we enable it to understand the context of each listing and extract relevant details, such as product names, features, and pricing, without requiring additional preprocessing.
We’re using Gemini’s generative Python SDK for this, which is lightweight and easy to set up.Install the SDK (if you haven’t already) using pip:
pip install google-generativeai
Next, we’ll configure Gemini and use it for our summary:
import google.generativeai as genai
# Initialize Gemini with your API key
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel(model_name="gemini-2.0-flash")
# Create a prompt that gives the model clear instructions
prompt = f"""
Below is a snippet of an eBay search results page.
Your task is to extract the first 3 listings based on the listings available and summarize:
- Product title
- Price
- Key features
- What makes it stand out
Here is the data:
{markdown_data}
"""
response = model.generate_content(prompt)
print(response.text)
Why This Prompt Works:
- We’re not just asking Gemini to “summarize”—we’re giving it specific fields to extract.
- The format aligns with how LLMs are trained to reason over structured data.
- Markdown formatting ensures clean input, avoiding noise from HTML tags.
You should see a response that looks like this (your actual results may vary depending on listings and region):
Here's a summary of the first three listings for "airpods pro" based on the provided eBay search results:
**1. Apple AirPods Pro 2nd Gen**
* **Price:** $69.99
* **Condition:** Open Box
* **Key Features:** Not explicitly stated, but assumed to include Active Noise Cancellation, Bluetooth connectivity, etc. (standard AirPods Pro 2nd Gen features)
* **What makes it stand out:** Relatively low price for a recent model, free delivery, and high number of units sold (76+). Sold by a seller with 100% positive feedback.
**2. AirPods Pro 2nd Generation with MagSafe Charging Case**
* **Price:** $65.00 or Best Offer
* **Condition:** Pre-Owned
* **Key Features:** Not explicitly stated, but assumed to include Active Noise Cancellation, Bluetooth connectivity, etc. (standard AirPods Pro 2nd Gen features with MagSafe).
* **What makes it stand out:** Lower price point, but has a delivery fee of $6.03, resulting in a slightly higher total than the first listing. Sold by a seller with 0% positive feedback.
**3. AirPods Pro 2nd Generation with MagSafe Charging Case**
* **Price:** $65.00 or Best Offer
* **Condition:** New (Other)
* **Key Features:** Not explicitly stated, but assumed to include Active Noise Cancellation, Bluetooth connectivity, etc. (standard AirPods Pro 2nd Gen features with MagSafe).
* **What makes it stand out:** Free Delivery and labelled as a 'New Listing'. Seller feedback percentage is also zero. 7 watchers.
This gives you a simple, easy-to-read summary of the top listings—great for adding to a dashboard, sharing with another tool, or quickly understanding what’s being sold.
How ScraperAPI Makes eBay Data Collection Easy
Scraping eBay data can be a challenging task due to eBay’s anti-bot measures and frequent changes in their techniques.
You already saw a glimpse of this at the beginning of this tutorial, where a request without the proper headers was blocked by eBay.
However, this approach will only work for small projects (scraping a couple of tens of URLs).
To scale our project to collect millions of product details, we’ll use ScraperAPI. This solution is designed to help you bypass these challenges effortlessly. It also takes care of handling IP rotation, ensuring that your scraping process runs smoothly without interruptions.
Getting Started with ScraperAPI for Extracting eBay Listings
Using ScraperAPI is straightforward. All you need to do is send the URL of the webpage you want to scrape, along with your API key. Here’s how it works:
- Sign Up for ScraperAPI: Go to the ScraperAPI dashboard page and sign up for a new account. This comes with 5,000 free API credits for 7 days, allowing you to explore the service’s capabilities.
- Obtain Your API Key: Upon signing up, you will receive your API Key.
Now, you can use the following code to access eBay search results.
Note: Replace API_KEY in the code with your own ScraperAPI API key.
import requests
import json
from bs4 import BeautifulSoup
API_KEY = "YOUR_API_KEY"
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=p4432023.m570.l1312&_nkw=airpods+pro&_sacat=0"
payload = {"api_key": API_KEY, "url": url}
r = requests.get("https://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
result_list = []
# Find all product items on the page
listings = soup.find_all("div", class_="s-item__info clearfix")
images = soup.find_all("div", class_="s-item__wrapper clearfix")
for listing, image_container in zip(listings, images):
title = listing.find("div", class_="s-item__title").text
price = listing.find("span", class_="s-item__price").text
product_url = listing.find("a")
link = product_url["href"]
product_status_element = listing.find("div", class_="s-item__subtitle")
product_status = (
product_status_element.text
if product_status_element is not None
else "No status available"
)
if title and price:
title_text = title.strip()
price_text = price.strip()
status = product_status.strip()
image = image_container.find("img")
image_url = image["src"]
result_dict = {
"title": title_text,
"price": price_text,
"image_url": image_url,
"status": status,
"link": link,
}
result_list.append(result_dict)
# print(result_list)
# Output the result in JSON format
output_json = json.dumps(result_list, indent=2)
# Write the JSON data to a file
with open("ebay_results.json", "w", encoding="utf-8") as json_file:
json_file.write(output_json)
print("JSON data has been written to ebay_results.json")
This is the output, as seen in the ebay_results.json file
[
{
"title": "Apple AirPods Pro",
"price": "$200.00",
"image_url": "https://ir.ebaystatic.com/rs/v/fxxj3ttftm5ltcqnto1o4baovyl.png",
"status": "Brand New",
"link": "https://ebay.com/itm/123456?hash=item28caef0a3a:g:E3kAAOSwlGJiMikD&amdata=enc%3AAQAHAAAAsJoWXGf0hxNZspTmhb8%2FTJCCurAWCHuXJ2Xi3S9cwXL6BX04zSEiVaDMCvsUbApftgXEAHGJU1ZGugZO%2FnW1U7Gb6vgoL%2BmXlqCbLkwoZfF3AUAK8YvJ5B4%2BnhFA7ID4dxpYs4jjExEnN5SR2g1mQe7QtLkmGt%2FZ%2FbH2W62cXPuKbf550ExbnBPO2QJyZTXYCuw5KVkMdFMDuoB4p3FwJKcSPzez5kyQyVjyiIq6PB2q%7Ctkp%3ABlBMULq7kqyXYA"
},
{
"title": "Apple AirPods Pro 2nd Generaci\u00f3n PRECINTADOS",
"price": "USD213.60",
"image_url": "https://i.ebayimg.com/thumbs/images/g/uYUAAOSwAnRlOs3r/s-l300.webp",
"status": "Totalmente nuevo",
"link": "https://www.ebay.com/itm/296009215198?hash=item44eb862cde:g:uYUAAOSwAnRlOs3r&amdata=enc%3AAQAIAAAA4C51eeZHbaBu1XSPHR%2Fnwuf7F8cSg34hoOPgosNeYJP9vIn%2F26%2F3mLe8lCmBlOXTVzw3j%2FBwiYtJw9uw7vte%2FzAb35Chru0UMEOviXuvRavQUj8eTBCYWcrQuOMtx1qhTcAscv4IBqmJvLhweUPpmd7OEzGczZoBuqmb%2B9iUbmTKjD74NWJyVZvMy%2B02JG1XUhOjAp%2BVNNLH0dU%2Bke530dAnRZSd1ECJpxuqSJrH8jn6WcvuPHt4YRVzKuKzd8DBnu%2F0q%2FwkEkBBYy8AlLKj6RuRf4BOimd5C5QFRRey1p9D%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "Apple AirPods Pro 2da Generaci\u00f3n con Estuche de Carga Inal\u00e1mbrico MagSafe - SELLADO",
"price": "USD74.24",
"image_url": "https://i.ebayimg.com/thumbs/images/g/ce4AAOSwA6NlP5jN/s-l300.webp",
"status": "Totalmente nuevo",
"link": "https://www.ebay.com/itm/155859459163?hash=item2449f29c5b:g:ce4AAOSwA6NlP5jN&amdata=enc%3AAQAIAAAA4A9XuJkJREhc3yfSLaVZvBooRWQQJkXbWAXmnSwndqFI7UgsJgH2U98ZoS6%2BiExiDMoeL6W7E6l7y9KCZDHdxwCixGLPwJKvM7WiZNcXhuH5NsSgCjcvJt56K%2BXCLMuQhmJvfih%2BWeZlqRXTwfUKDE0NMNSXE98u1tAOMohQ1skdT%2FKS7RDJ7Dpo%2BcGb1ZCt9KRAoNMKOkmnr5BVTMHFpzAOOC6fQAlRFt8e5yXrlZYwbyMchnboMF3F3xODe5dEvxv3YiHinOAoLl93pNmz1Yn1ToO%2FrIef4ZCbsiECkfk3%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "AURICULARES BLUETOOTH APPLE AIRPODS PRO AURICULARES CON ESTUCHE DE CARGA INAL\u00c1MBRICA",
"price": "USD80.99",
"image_url": "https://i.ebayimg.com/thumbs/images/g/v78AAOSw-NFkS37t/s-l300.webp",
"status": "De segunda mano",
"link": "https://www.ebay.com/itm/144890564294?hash=item21bc268ec6:g:v78AAOSw-NFkS37t&amdata=enc%3AAQAIAAAA4LD7XbJuhs0J9HL02DzzbH8fZ7T5wxLjkMhC2%2B%2Bwg5WrsH3ni7TcbBIqImnuOYtcDKznUPm%2F2%2FHNoD43mA6%2Ffw23995rH3%2BW9Wb5QPimLoCn3cA1PUbPBO6zG99gyg04JbxmtGH6f%2FYaZlfXVo3vWLvSqwux3ZsP1okWWuuz5y1OjJvXQB9ACVoLSCC6au2RpqS3DdOPwi%2FGrP0Osj44XNbT8UHtSKF6N%2FmbqNTLXoaJVunBjlnpjvE%2BPTKAxSuFX3GvptHXOqFCKAkdKpmH8%2BW8hRTX0q9gVxv9Nw6epsC%2B%7Ctkp%3ABFBMoLnxs_Ni"
},
{
"title": "Auriculares AirPods Pro 2 Bluetooth con estuche de carga inal\u00e1mbrica MagSafe para tel\u00e9fonos",
"price": "USD58.53",
"image_url": "https://i.ebayimg.com/thumbs/images/g/ol8AAOSw~e9lLfXD/s-l300.webp",
"status": "Nuevo (otro)",
"link": "https://www.ebay.com/itm/295718525142?hash=item44da3298d6:g:ol8AAOSw~e9lLfXD&amdata=enc%3AAQAIAAAA4GHg1xYgyvcQRhTwQRVL2l5CvX3zSMsR281hXacuujxxm9F%2F5pYTo9aEp9ZL7e8jsJB9qlUMUF7kLuYgPHFoEh%2B0qQtajGFWTi3NqY3h8vYwhFCWqITUnrV%2BhJ0voFK4qvh3CmnzDVbYnkYPY36OehktFXjrS%2B6WWx24w7a1TXAJSCwEi0Oh9SWqDyrkSH19m7Ft0t2gMq3EpMYy7IidY2HOfQkZe7MUpHNqVoUnzaNiKv129JAfiWGkOPtwABqRt2b09iKMpoPjTfPUIHMj%2F5yL97%2B%2BCj5A4zGc5TRPsIrG%7Ctkp%3ABFBMoLnxs_Ni"
},
]
With ScraperAPI, you can focus on extracting valuable eBay data without worrying about being blocked or keeping your scraper updated with eBay’s evolving anti-bot techniques.
You can perform a wide range of analyses with the collected data and use it for your specific purposes, including price comparison and market research.
Extract eBay Data at Scale with Python and JavaScript (Cheerio)
This eBay web scraping tutorial provides a quick rundown of how to scrape data from eBay using Python and Cheerio (JavaScript).
If you’re ready to scale your data collection to thousands or even millions of pages, consider exploring ScraperAPI’s Business Plan; which offers advanced features, premium support, and an account manager.
Do you need 10M+ API credits? Contact sales for a custom plan.
Feel free to reach out if you have any further questions or need assistance!
Until next time, happy scraping!
FAQs about eBay Web Scraping
Data obtained from eBay can offer insights into product trends, pricing, and competitor analysis, help users find the best deals, and enable data-driven decision-making.
Learn how to gain a competitive edge with ecommerce data.
Yes, it is legal to scrape data from eBay. What’s important to keep in mind is that you should only scrape publicly available data. As long as you are not bypassing login walls and you are using the data for a proper goal, like market research and academic research, there won’t be any legal action against you.
When scraping eBay, you can collect product details like:
– Names
– Descriptions
– Prices
– Seller information
– Shipping details
– Customer reviews
– Product ratings
And much more.
As long as the data is publicly available, you can use web scrapers to collect such data.