



Paid advertising (PPC) is a competitive space, that requires smart tactics to succeed. As this advertising channel matures, and ad costs continue to rise significantly, we’ve seen a heavier focus on data.
Scraping advertising data can help marketers understand their customers and how they interact with their services. It can also help them understand competitors’ strategies and find missing gaps.
In this article, we highlight how web scraping is a scalable approach for PPC research, prospecting, and overall trend analysis. We’ll show you how to build a Google Ads data scraper so you can confidently compete online – without burning out your team (or your pocket).
Why Scrape Google Ads Data?
In paid advertising, understanding where and how your competition shows up in Google search results is a great way to inform your strategy. For starters, if you use a web scraper, you can extract Google Ads data from millions of queries in just a few hours – which would be impossible to do manually.
Then, you can use this scraped Google Ads data to improve your PPC strategies, as listed below.
Understand Your Competitors’ Marketing Positioning Based on Ad Titles and Descriptions
Google Ads are, in essence, text advertising. They rely on their copy to entice users to click on the link. In other words, your competitors pay a lot of attention to the wording in their titles and ad descriptions.
For example, if you search for project management software, you’ll find the following ClickUp ad:
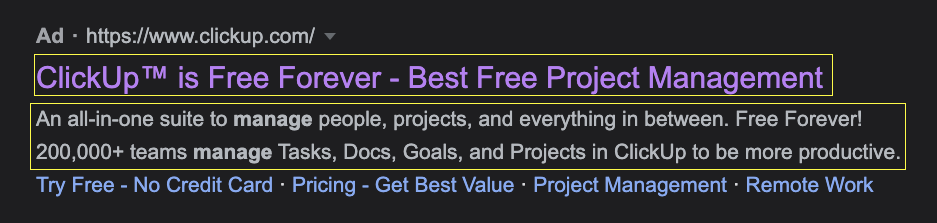
Just from reading its copy, you can see there’s a lot of emphasis on their free offering – even using site links to build on “no credit card,” giving us a clue of their ad messaging.
Now, by scaling this data extraction process to all related keywords, you can create a complete database of titles and descriptions of your competitors’ ads for each relevant keyword. Use this to create a clear map that will allow you to:
- Differentiate their offers and solutions from the competition, showing their unique brand and USP through the copy.
- Improve upon the competitors’ offers to gain the clicks of potential customers
- Identify relevant keywords with weak ad copy you can win over
Get a Sense of Competitor’s PPC Costs Based on the Frequency They Appear on the SERPS
Knowing (even an approximate) of your competitors’ ad spending can help you plan and present a clear work plan that takes into consideration competition and budget. By knowing how much your competitors are investing in their PPC campaigns, you can:
- Forecast how much your company would need to invest to compete in the SERPs, helping you better sell your strategy to your stakeholders
- If we add ad position to the mix, you can figure out for which keywords your competitor is outbidding the rest and, with the average CPC cost, find places where it would be more cost-effective to compete
- If you operate an agency, you can use ad data to scale your clients’ ad budget, showing concrete reasons for the budget you’re proposing
- Categorize your competitors’ ad investment by location (e.g., country), keyword and search intent, and buyers’ journey stage – to name a few categories
To go even further, you can set your web scraper to periodically scrape the SERPs to update this information and spot shifts in strategy or generate trends from different competitors.
Identify and Analyze Your Competitors’ Landing Pages by Following Their Ad Links
Landing pages are the salesman behind the advertisement, and you can learn a lot about your competition by analyzing their landing page’s copy, structure, and offer.
You can build a Google Search scraper that extracts ad information and then follows each link associated with the ad to scrape the landing page’s heading, content, meta description, meta title, images, videos, etc., and create a birds-eye view of the entire PPC campaign they’re implementing. In return, you can find gaps in their marketing, offer opportunities, content ideas, and funnel ideas to launch your campaign.
Find Out Who Your Main Competitors Are for Specific Keywords
Your known competitors are not the only ones investing in PPC and Google Ads. By scraping ad data at scale, you can quickly identify companies competing for the same keywords you are after. This is especially useful when your business wants to enter a new geographical market.
Building a Google Ads scraper can help you collect a massive amount of ad data to identify big local players and the level of competition you’ll be facing to gain market share.
How to Scrape Google Ads Data from Search Result Pages with Scrapy
There are many tools to scrape Google that can be useful for scraping a couple of queries. However, if you want to send millions of scraping requests, you’ll need a more advanced solution like ScraperAPI.
Our API does all the heavy lifting of handling IP rotation, choosing the right headers, and changing the geolocation of your requests – so you can scrape ad data from anywhere. Moreover, it has an auto parser designed explicitly for Google, so you don’t have to worry about selectors or future changes to Google’s platform.
For this project, we’ll use ScraperAPI to handle these complexities and Scrapy to build the script.
Note: If you haven’t used Scrapy before, check out our Scrapy beginner guide, which covers all the basics.
1. Setting Up Our Google Ads Web Extraction Project
To get things started, you’ll need to create a virtual environment to install Scrapy. Open your terminal navigate to the desktop (or wherever you want to create the project), and use the command:
python -m venv g-ad-tutorial
You’ll notice a new folder has been created. This is your virtual environment; to activate it – on Mac – use the following command:
source g-ad-tutorial/bin/activate
If it’s active, you should see the name of your VENV like this:

Next, create a new project inside your VENV:
cd g-ad-tutorial >pip3 install scrapy scrapy startproject g_ad_scraper
… and open it with VScode or your preferred code editor. Inside the spidersfolder, create your Python file. In our case, we called it g_adscraper.py, but you can name it as you please.
To finish configuring the project, add the following code snippet to import all necessary dependencies:
import scrapy from urllib.parse import urlencode from urllib.parse import urlparse #ScraperAPI autoparser will return data in JSON format import json API_KEY='YOUR_API_KEY'
Note: Remember to add your API key to the API_KEY variable. You can create a free ScraperAPI account here.
2. Creating the Google Search URL
Google implements a standard and query-able URL structure we can take advantage of by understanding its parameters. It always starts with “http://www.google.com/search?” and from there, we can add several parameters to specify what we want. For this project, we’re only going to focus on two of them:
- The q parameter specifies the query/keyword we want to run a search for. Here’s an example: http://www.google.com/search?q=web+scraping
- When generating your keywords, remember the as_sitesearch parameter limits the searches to one domain or website. For example, we could say http://www.google.com/search?q=web+scraping&as_sitesearch=scraperapi.com
If you’ve used search operators before, these are already common to you. If not, here’s a complete list of search operators worth keeping at hand.
That said, let’s build our first function and create our target search query:
defcreate_google_url(query, site=''):
google_dict = {'q': query}
if site :
web = urlparse(site).netloc
google_dict['as_sitesearch'] = web
return 'http://www.google.com/search?' + urlencode(google_dict)
return 'http://www.google.com/search?' + urlencode(google_dict)
We’ll set our queries later in the script, so for now, we’ll assign query to the q parameter – it’ll also make it easier for you to make changes.
Important Note
When scraping organic results, we would use the num parameter to make Google display the maximum number of results per request (currently 100 results per page). However, Google ads are presented by page and don’t get influenced by the number of results on the page they appear on.
In other words, there’s no need to use this parameter because we only want the ad data. If we wanted more “ad results” for a single keyword, we actually want to send more requests – not less – to extract more ads from every 10-results page.
3. Using ScraperAPI with Scrapy
To use ScraperAPI capabilities, we need to send the request through ScraperAPI’s servers. For that, we’ll need to use payload and urlencode to construct its structure and then use it in conjunction with the Google query we just built.
Let’s add the following logic before our create_google_url() function:
def get_url ( url ):
payload = { 'api_key' : API_KEY , 'url' : url , 'autoparse' : 'true' , 'country_code' : 'us' }
proxy_url = 'http://api.scraperapi.com/?' + urlencode ( payload )
return proxy_url
Within the payload, we can set the different components for ScraperAPI:
- The first one, of course, it’s our API key which we already stablished above
- The url will be the target URL we want ScraperAPI to parse, which we’ll be generating it using the create_google_url() function
- We’re setting auto parse to true, so ScraperAPI knows to send us the JSON data
- Lastly, we’re specifying we want to send all requests from US IP addresses
And that’s it, we’re ready to write our spider!
4. Creating a Custom Spider
To run our script, we need to scrape a spider (also known as a Class). In Scrapy, we can create as many spiders as we want inside one single project, making it easier to manage big projects that require scraping multiple sites.
We must allow ScraperAPI’s endpoint because our request will go to the server, and ScraperAPI is the one retrieving the response from the target query.
class GoogleAdSpider(scrapy.Spider):
name = 'adsy'
allowed_domains = ['api.scraperapi.com']
custom_settings = {'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS_PER_DOMAIN': 10,
'RETRY_TIMES': 5}
We’re also configuring some custom settings built-in in Scrapy. Most importantly, we’re configuring our concurrent requests and the maximum number of tries.
If you want to learn more about these custom settings, Scrapy has them very well documented.
5. Sending the HTTP Requests
Scrapy makes it super easy to send our requests using the scrapy.Request() method, but in order to send the requests out, we first need to establish the URL, and for that, we need a set of queries.
In this step, your team will need to decide which keywords are important for your business. This is usually done by your PPC team, marketing manager, or SEO team.
Just for fun, let’s say that we’re a project management software company, and we want to see what ads appear on these ten keywords:
- project management software
- project management app
- best project management software
- task management software
- project management tools
- comparing project management software
- project planning & management
- agile project management software
- project tracker
- project management for software development
We can use SEO tools to get these terms based on volume and difficulty or scrape Google with a seed keyword and then extract and navigate to all related terms links.
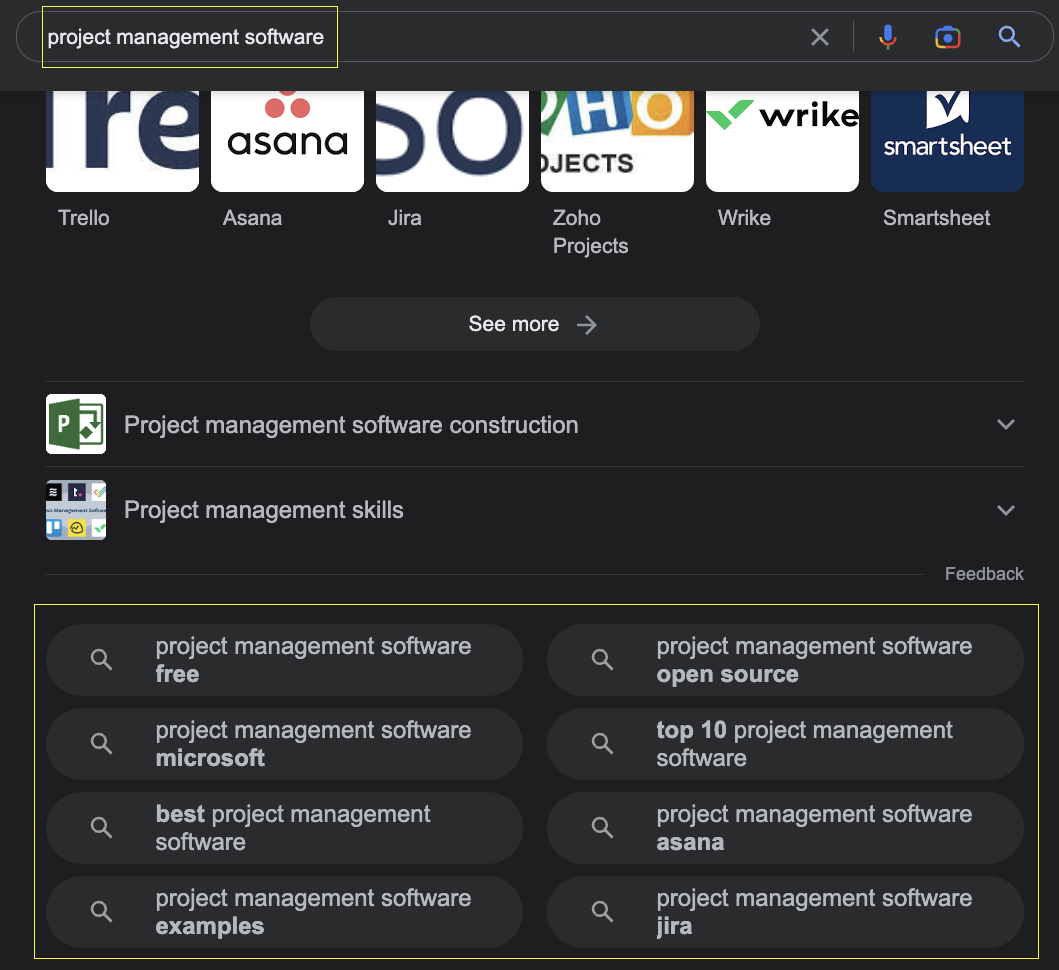
If you’d like to go through this route, we created a guide to scrape organic Google results with Scrapy you can check.
Now, using these queries, let’s start building our function:
def start_requests(self): queries = [ 'project+management+software', 'best+project+management+software', 'project+management+tools', 'project+planning+management', 'project+tracker', 'project+management+app', 'task+management+software', 'comparing+project+management+software', 'agile+project+management+software' ]
Notice that we replace all space with a plus (+) symbol. This is part of Google’s standard structure, so keep an eye out for it.
So what’s next? If we have the queries, now we can build our Google search query. As you can imagine, we want to build a different URL for each query. To do so, we can loop through the list and pass each one to our create_google_url() function:
for query in queries: url = create_google_url(query)
And inside the same loop, we yield the new url to the get_url() function, so we pass it as a parameter and construct a complete ScraperAPI method.
yield scrapy.Request(get_url(url), callback=self.parse)
6. Extracting Google Ad Data from ScraperAPI Auto Parser
Once ScraperAPI sends the requests to Google, it will return with JSON data. Within this JSON we’ll be able to find all major elements from the search result page.
Here’s a complete example of the response from Google auto parser, but to keep it concise, let’s focus on the ad data:
"ads": [
{
"position": 1,
"block_position": "top",
"title": "7 Best VPN Services for 2019 | Unlimited Worldwide Access",
"link": "https://www.vpnmentor.com/greatvpn/",
"displayed_link": "www.vpnmentor.com/Best-VPN/For-2019",
"tracking_link": "https://www.googleadservices.com/pagead/aclk?sa=L&ai=DChcSEwjphbjWlprlAhUHyN4KHR9YC10YABAAGgJ3Yg&ohost=www.google.ca&cid=CAASE-Roa2AtpPVJRsK0-RiAG_RCb3U&sig=AOD64_0dARmaWACDb7wQ5rCwGfAERVWsdg&q=&ved=2ahUKEwj9gLPWlprlAhUztHEKHdnCBBwQ0Qx6BAgSEAE&adurl=",
"description": "Our Best VPN for Streaming Online, Find Your Ideal VPN and Stream Anywhere",
"sitelinks": []
},
{
"position": 2,
"block_position": "top",
"title": "Top 10 Best VPN Egypt | Super Fast VPNs for 2019",
"link": "https://www.top10vpn.com/top10/free-trials/",
"displayed_link": "www.top10vpn.com/Best-VPN/Egypt",
"tracking_link": "https://www.googleadservices.com/pagead/aclk?sa=L&ai=DChcSEwjphbjWlprlAhUHyN4KHR9YC10YABABGgJ3Yg&ohost=www.google.ca&cid=CAASE-Roa2AtpPVJRsK0-RiAG_RCb3U&sig=AOD64_3hbcS-4qdyR_QK0mSCy2UJb61xiw&q=&ved=2ahUKEwj9gLPWlprlAhUztHEKHdnCBBwQ0Qx6BAgTEAE&adurl=",
"description": "Enjoy Unrestricted Access to the Internet. Compare Now & Find the Perfect VPN. Stay Safe & Private Online with a VPN. Access Your Websites & Apps from Anywhere. 24/7 Support. Free Trials. Coupons. Instant Setup. Strong Encryption. Fast Speeds. Beat Censorship.",
"sitelinks": []
}
]
All data is inside of the ads object, so if we loop through each of the items inside the object, we can select all the elements we need.
Let’s get the title, description, displayed_link, and link. Also, for it to make more sense, we’ll get the query_desplayed value from the search_information object.
"search_information": {
"total_results": 338000000,
"time_taken_displayed": 0.47,
"query_displayed": "vpn"
}
That way, we’ll keep track from which query each ad on the list is.
def parse(self, response): all_data = json.loads(response.text) keyword = all_data['search_information']['query_displayed']
After loading the JSON data into the all_data variable, we can use it to navigate the response and grab the query_displayed element. We can do the same for the rest of the ad data inside a loop:
for ads in all_data['ads']: title = ads['title'] description = ads['description'] displayed_link = ads['displayed_link'] link = ads['link']
In other words, we’re assigning each element inside the ads JSON object to an ads variable and then selecting each element to extract its value.
Lastly, let’s organize each set of attributes into one ad object and yield it – always inside the loop:
ad = {
'keyword': keyword,'title': title, 'description': description, 'Displayed Link': displayed_link, 'Link': link
}
yield ad
Now, for every iteration of the loop, we’ll have an ad item storing all the data organized.
7. Run the Spider and Export the Data to a JSON File
If you’ve been following us so far, here’s how your Python script should look like:
import scrapy
from urllib.parse import urlencode
from urllib.parse import urlparse
import json
API_KEY = 'your_api_key'
#constructing the ScraperAPI method
def get_url(url):
payload = {'api_key': API_KEY, 'url': url, 'autoparse': 'true', 'country_code': 'us'}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
#building the Google search query
def create_google_url(query, site=''):
google_dict = {'q': query, 'num': 10, }
if site:
web = urlparse(site).netloc
google_dict['as_sitesearch'] = web
return 'http://www.google.com/search?' + urlencode(google_dict)
return 'http://www.google.com/search?' + urlencode(google_dict)
class GoogleAdSpider(scrapy.Spider):
name = 'adsy'
allowed_domains = ['api.scraperapi.com']
custom_settings = {'ROBOTSTXT_OBEY': False, 'LOG_LEVEL': 'INFO',
'CONCURRENT_REQUESTS_PER_DOMAIN': 10,
'RETRY_TIMES': 5}
#sending the requests
def start_requests(self):
queries = [
'project+management+sotware',
'best+project+management+software',
'project+management+tools',
'project+planning+&+management',
'project+tracker',
'project+management+app',
'task+management+software',
'comparing+project+management+software',
'agile+project+management+software'
]
for query in queries:
#constructing the Google search query
url = create_google_url(query)
#adding the url to ScraperAPI endpoint
yield scrapy.Request(get_url(url), callback=self.parse)
def parse(self, response):
all_data = json.loads(response.text)
#grabbing the keyword for organization
keyword = all_data['search_information']['query_displayed']
#lopping through each item inside the ads object
for ads in all_data['ads']:
title = ads['title']
description = ads['description']
displayed_link = ads['displayed_link']
link = ads['link']
ad = {
'keyword': keyword,'title': title, 'description': description, 'Displayed Link': displayed_link, 'Link': link
}
yield ad
Remember: You’ll need to add your API key for this to work.
To run your spider and export all data to a JSON file, use the command…
scrapy runspider g_adscraper.py -o ad_data.json
…and voilà! We just scrape 48 ads in 34 seconds and add all of it to a JSON file.
If you haven’t run it yet, let us show you some examples from the file you’re about to create:
{
"keyword": "comparing+project+management+software",
"title": "10 Best Project Management - Side-by-Side Comparison (2022)",
"description": "Compare the Best Project Management Software. Plan, Track, Organize, and Manage Your Time. Powerful, Flexible Project Management for Any Team. Task Management & Custom...",
"Displayed Link": "https://www.consumervoice.org/top-software/project-manager",
"Link": "https://www.consumervoice.org/top-project-management-software"
},
{
"keyword": "project+management+sotware",
"title": "Project Management Software - Plan, Track, Collaborate",
"description": "Plan projects, track progress, and collaborate with your team. Sign up for free!",
"Displayed Link": "https://www.zoho.com/",
"Link": "https://www.zoho.com/projects/"
},
{
"keyword": "task+management+software",
"title": "10 Best Task Management Tools - 10 Best Task Management App",
"description": "The Comfort Of a Simple Task Management Software Is Priceless. Apply Today & Save! Team Tasks Management Made Oh-So Easy! Get Your Work Going with These Great...",
"Displayed Link": "https://www.top10.com/task_management/special_offer",
"Link": "https://www.top10.com/project-management/task-manager-comparison"
},
Note: If you want to make the keyword item cleaner, you can use the .replace() method as follows:
keyword = all_data['search_information']['query_displayed'].replace("+", " ")
Effectively replacing the plus symbol (+) with a space.
{
"keyword": "best project management software",
"title": "Project Management Software - Plan, Track, Execute, Report",
"description": "Plan projects, track progress, and collaborate with your team. Sign up for free! Get work done on time, all the time. Start with 2 projects free today! Simplify complex tasks.",
"Displayed Link": "https://www.zoho.com/projects",
"Link": "https://www.zoho.com/projects/"
}
Focus on Scraping the Ads on the First Google Page
Every page in the SERPs series of a query will show different ads, so it might sound like a good idea to follow these links for every query and extract all data you can.
Although there could be some value in this, the reality is that only a tiny percentage of traffic goes to page 2, and almost no click to page 3. Just think of the last time you clicked on page 2.
ScraperAPI will provide you the following link inside the [‘pagination’][‘nextPageUrl’] object, but this is more recommended to scrape organic search results, related searches, and people also ask boxes.
We recommend scraping page 1 for every keyword variation for Google Ads data.
Scaling Your Google Web Scraping Projects
You’ve done great so far! We hope you learned a thing or two from this Google Ads web scraping tutorial, and we’re excited to see what you build with this.
If you don’t know where to go from here, you can scale this project by creating a longer list of keywords. We recommend using a tool like Answer the Public to generate a list of relevant keywords and make your script read the queries from there.
For constant monitoring, you can also make it so that every time you update the spreadsheet with new keywords, your Google Ads scraper sends a new request for it.
Also, if you want to invest in PPC but in different languages, you can also build a new spider and change the country_code parameter in the payload. This is useful, for example, if you want to run ads in different countries that speak the same language (think UK, US, Canada, etc.)
As long as you keep your mind open to the possibilities, you’ll find more and more ways to gather data faster and use it to build ROI-positive campaigns.
If you want to learn more about marketing and web scraping, we have broken down all the ways web scraping can help you make better marketing decisions.
Interested in adopting ScraperAPI to power your data-extracting needs? Sign up today and get a 7-day free trial!
Until next time, happy scraping!





