



In the world of data, context is vital for business growth. If you want to uncover insights and accomplish new goals, you need to ensure you’re collecting and analyzing the correct datasets.
Let’s say you’re a business that wants to enter new markets. To do so, you will need to collect localized data to help your teams understand new audiences, their needs, buying journeys, etc. However, collecting localized data through web scraping requires a series of tools like IP rotation systems to mimic the behavior of a local searcher. For example, sending your requests through French-based IPs to collect data from a French site – this is what we call geotargeting.
A common use case for geotargeting is scraping websites that display different results based on your IP location, like search engines and eCommerce sites. So, in this tutorial, we’ll show you how to use ScraperAPI’s localized IP pools to extract local data from NewChic, a marketplace serving over 20 countries in 10+ languages, using Python.
Quick Code Snippet
For those with experience, here’s the final code snippet. You can change the country_code parameter to a specific country using any supported country codes from our documentation.
For this project to work, we’ll use three main tools:
import requests
from bs4 import BeautifulSoup
import pandas as pd
product_data = []
payload = {
'api_key': 'YOUR_API_KEY',
'country_code': 'us',
'url': 'https://www.newchic.com/kitchen-tools-and-gadgets-c-5037/'
}
response = requests.get('https://api.scraperapi.com', params=payload)
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('div.mb-lg-32')
for product in products:
product_name = product.find('a', class_='product-item-name-js').text
product_data.append({
'product': product_name
})
df = pd.DataFrame(product_data)
df.to_json('test.json', indent=2)
Keep reading to learn how we built it!
1. Understanding Multi-Language Websites
The first thing we need to do is get to know our target site.
Although all websites are built using pretty much the same technologies (HTML, CSS, and JavaScript), the truth is that each site is a unique puzzle that’ll require some research before being able to solve it.
For example, some websites can add all the page’s content dynamically, which would require rendering JavaScript to be able to access the page, while others could be routing traffic based on their IP location to subdomains.
Checking For Dynamic Content
Before we start figuring out how to extract the content, let’s look at the source code and make sure we’ll be able to access its content from the HTML file.
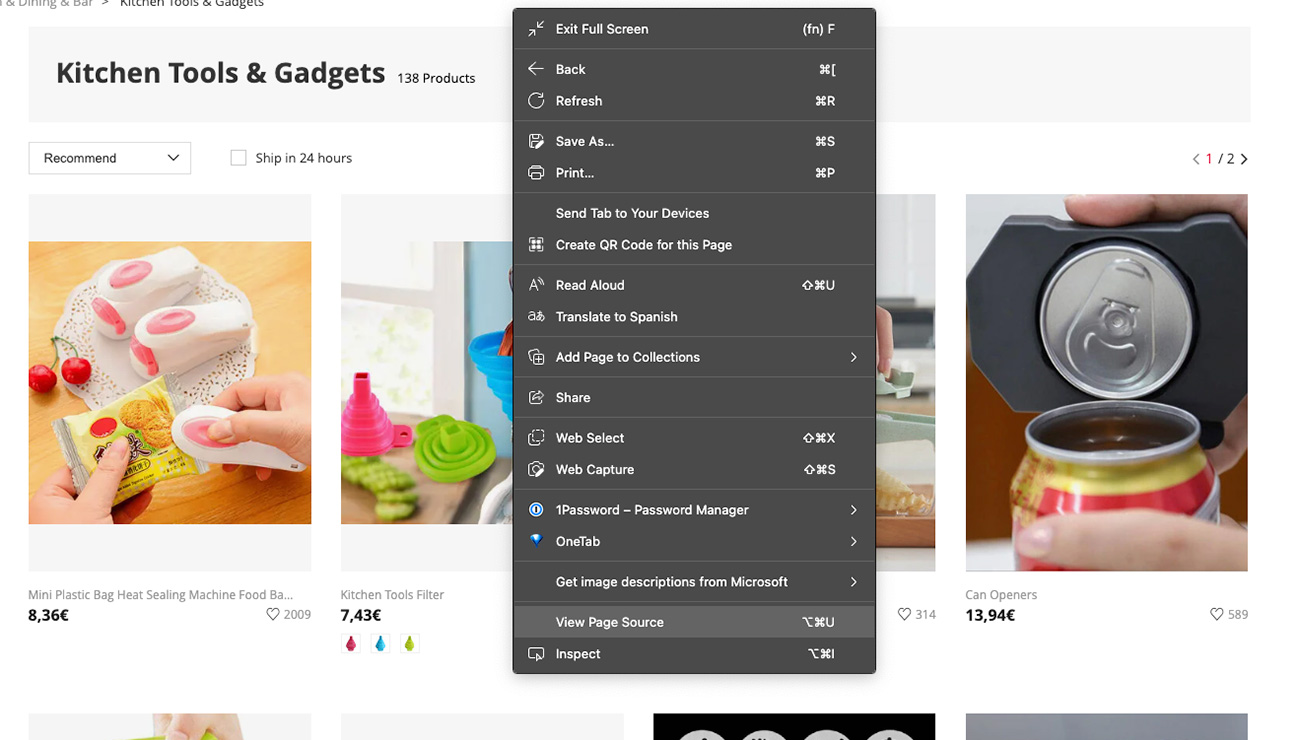
For this exercise, we’ll want to extract the name of all products within the page, so let’s copy the name of the third product and look for it in the source code.

Perfect! If the name is in the source code, that means we’ll be able to get it from the HTML file.
Showing Different Languages on the Page
The second thing to learn is how the URL structure of the pages changes with languages. Currently, we’re on the US version of the site, and this is the URL shown:
https://www.newchic.com/kitchen-tools-and-gadgets-c-5037/?country=223&NA=1
When clicking on the country menu, we have the following options:
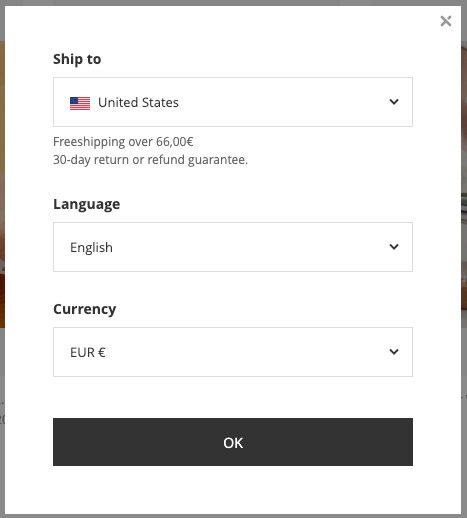
Let’s change shipping to Italy and see how the URL reacts.
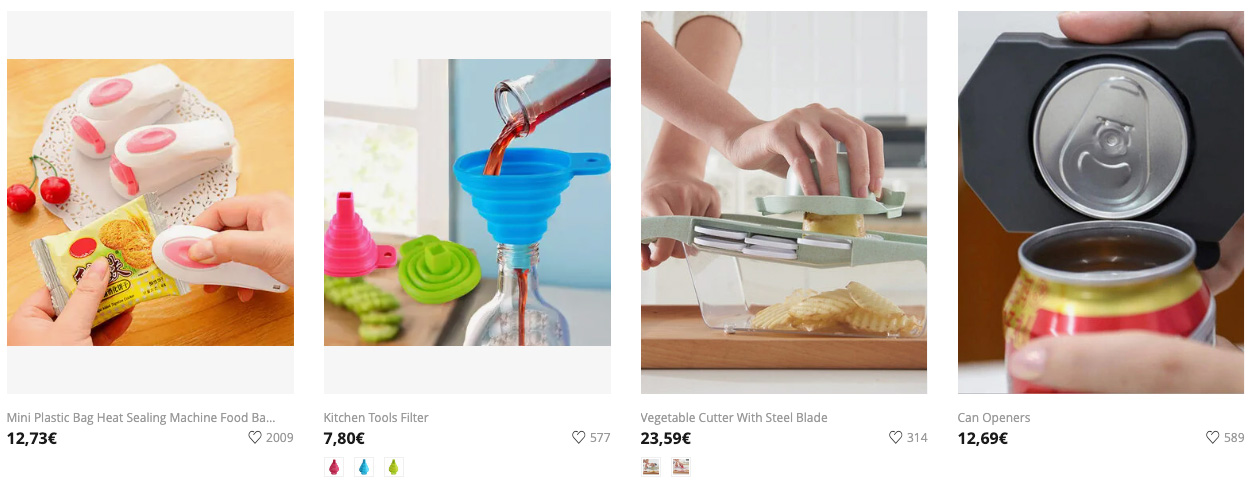
https://www.newchic.com/kitchen-tools-and-gadgets-c-5037/?country=105&WE=1
The new URL has different country and WE parameters but doesn’t change the language of the products on the page.
Let’s put US shipping back and set the language to Italian, and see what happens:
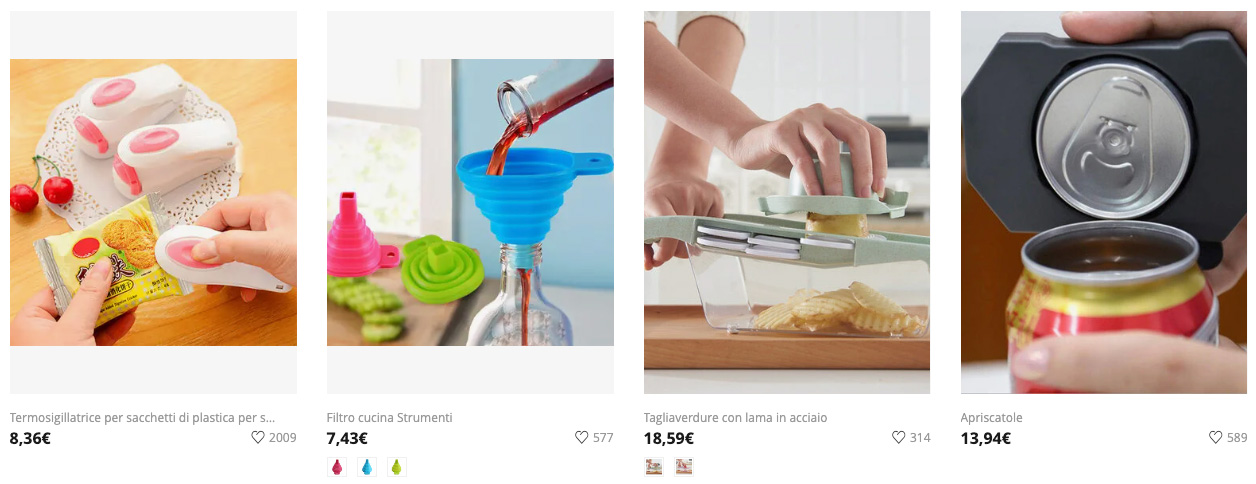
Now that did the trick. The products’ names are now in Italian, but we’re also in an IT subdomain:
https://it.newchic.com/kitchen-tools-and-gadgets-c-5037/?country=223&NA=1
Overall, this experiment tells us two things:
- The parameters at the end of the URL determines the shipping information
- The subdomain changes the language of the page
With these two pieces of information, we can now go ahead and start coding a beat!
2. Testing CSS Selectors
It sounds logical that multi-language websites use the same HTML and CSS structure across all their site versions. Sadly, that’s not always the case, so testing our CSS selectors on each subdomain will make our lives that much easier.
Let’s begin by inspecting the US site version to spot where in the structure are the product names.

As you can see in the image above, the product name is inside a <a> tag with the class="lg text-ellipsis d-block text-hover-underline text-secondary-hover font-small-12 text-grey product-item-name-js".
After checking several products, we can confirm they all share the same class. For practicality, though, let’s try and use the product-item-name-js part of the class and see if we can pick all product names through the browser’s console.
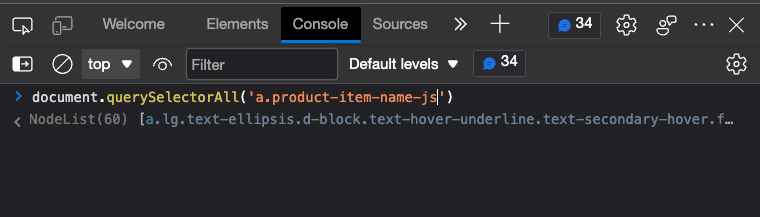
It returns a node list with 60 items, which is the exact number of products per page. If we expand it and hover over one item, we’ll see it highlights the name of the product on the page.

Now, let’s do the same thing on the Italian and French versions.
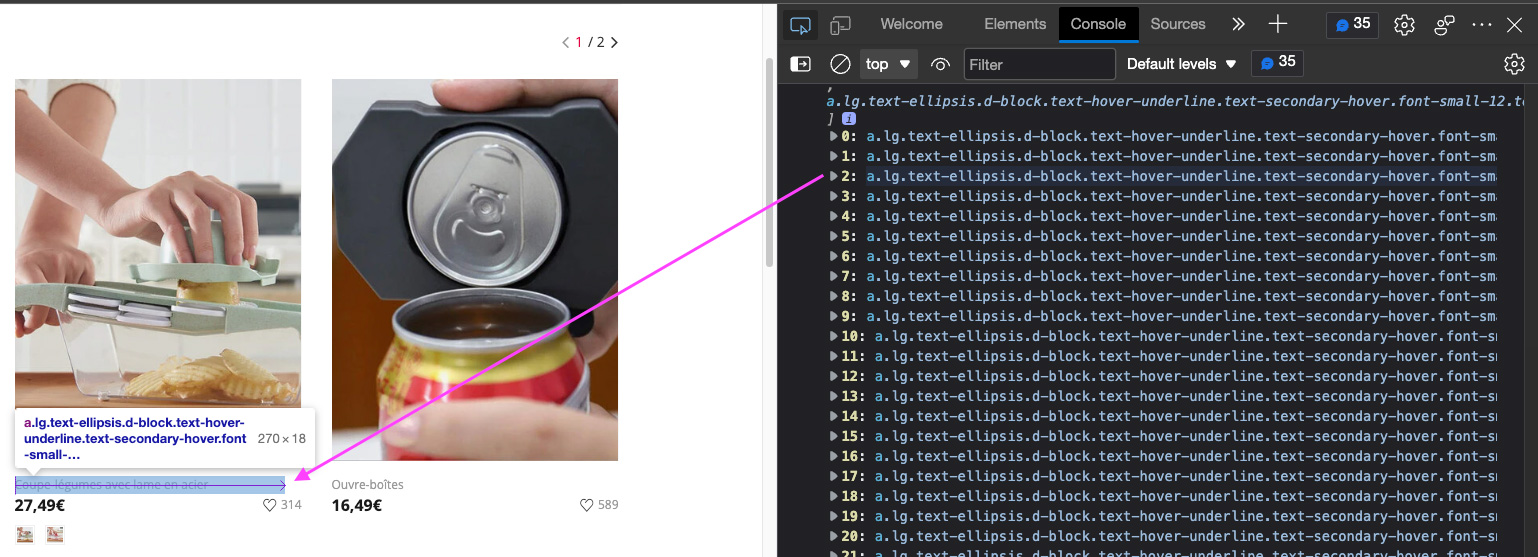
Both times worked. The same class is used across all subdomains, and we can now use it to target the products’ names.
3. Sending Our Requests Through ScraperAPI
Remember we said we’d be using ScraperAPI to access its pool of localized IPs? Well, there’s one more reason for it.
NewChic uses heavy anti-scraping mechanisms that can easily spot any bots trying to scrape their site. In fact, without ScraperAPI, we got a 403 forbidden response every time, no matter the HTTP headers we were sending.
However, ScraperAPI uses machine learning and years of statistical analysis to smartly pick the right combination of IPs and headers and rotate them as necessary, giving us access to the site without hardcoding every system necessary to bypass their anti-scraping mechanisms.
To start using ScraperAPI, create a free account to retrieve your API key – plus 5,000 API credits.
From there, let’s create a new file (we named ours newchic_scraper.py), import Requests, and create a payload to send along your get() request:
import requests
payload = {
'api_key': 'YOUR_API_KEY',
'url': 'https://www.newchic.com/kitchen-tools-and-gadgets-c-5037'
}
response = requests.get('https://api.scraperapi.com', params=payload)
print(response)
If you run your code, it should return a 200 successful response.
4. Building Our Parser
Taking a closer look at the page, you can see that every product is like a card:
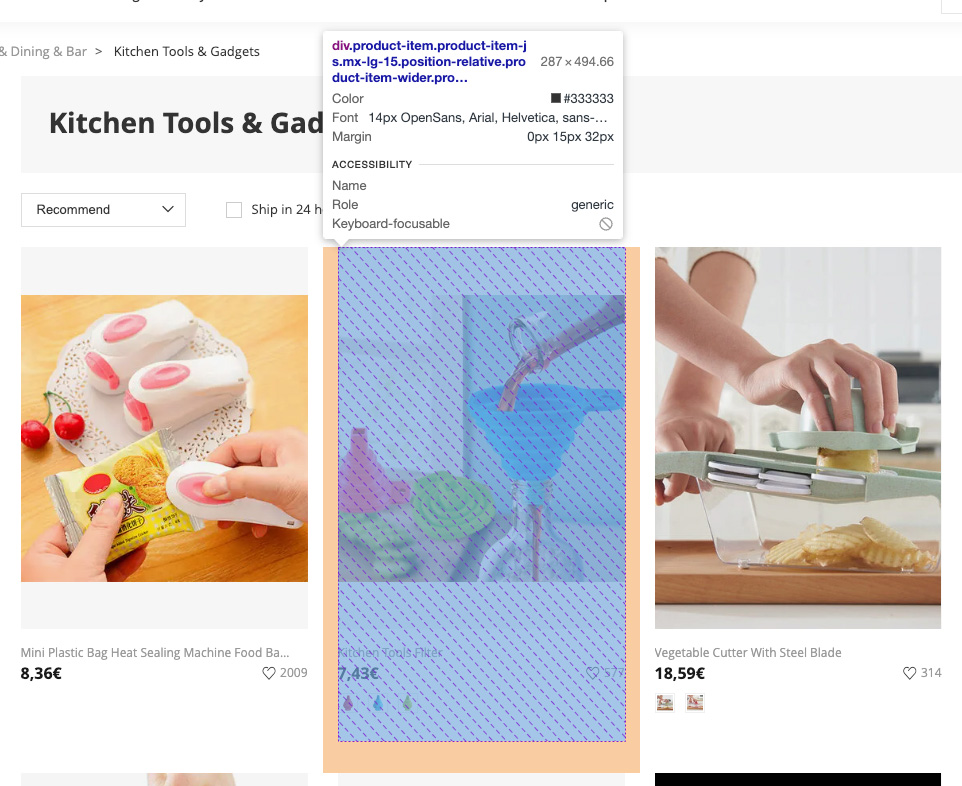
And each card is represented by a <div> with class="product-item product-item-js mx-lg-15 position-relative product-item-wider product-item-show-color mb-lg-32" in the HTML structure:
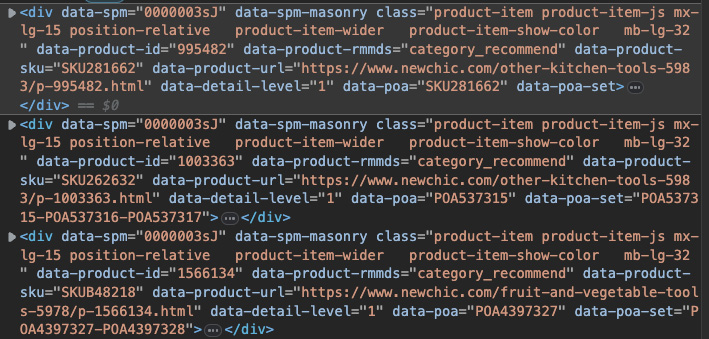
To extract the information, we can parse the HTML response using BeautifulSoup and create a list with all these <div> tags – we’ll be using the shortened version of the class as no other element uses the mb-lg-32 bit of it.
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('div.mb-lg-32')
Note: Remember to add from bs4 import BeautifulSoup at the top of the file.
With all the elements inside products, we can now loop through each product and extract the products’ name using the same CSS selector from before:
for product in products:
product_name = product.find('a', class_='product-item-name-js').text
Before running the script, let’s give it a little order to see better what happens.
5. Sending the Scraped Data to a JSON File
Before the payload, create an empty array where we’ll store each product’s name:
product_data = []
Now, we can use the .append() method on our array to store the names from within our for loop:
product_data.append({
'product': product_name
})
After the entire for loop runs, all information will be formatted inside product_data.
Finally, let’s import Pandas at the top of the file to create a data frame we can easily export as a JSON file using the .to_json() method:
df = pd.DataFrame(product_data)
df.to_json('us-products.json', indent=2)
6. Running Our Code Without Geotargeting
So far, your script should look like this:
import requests
from bs4 import BeautifulSoup
import pandas as pd
product_data = []
payload = {
'api_key': 'YOUR_API_CODE',
'url': 'https://www.newchic.com/kitchen-tools-and-gadgets-c-5037/'
}
response = requests.get('https://api.scraperapi.com', params=payload)
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('div.mb-lg-32')
for product in products:
product_name = product.find('a', class_='product-item-name-js').text
product_data.append({
'product': product_name
})
df = pd.DataFrame(product_data)
df.to_json('us-products.json', indent=2)
If we run it, it’ll create a JSON file, with 60 product names, inside the project’s directory:
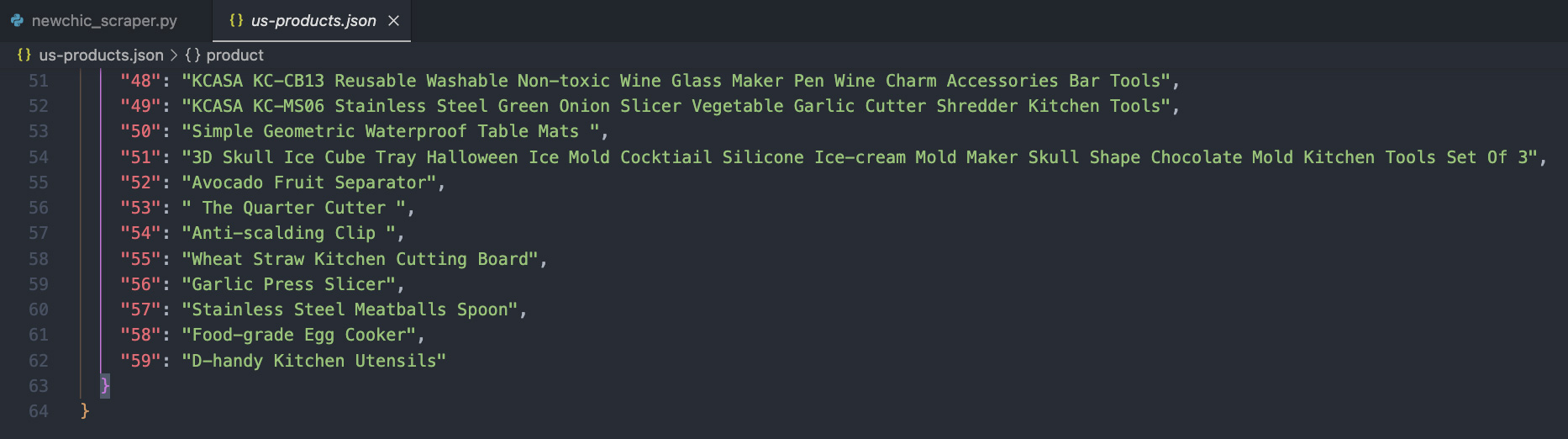
Note: The last item is number 59 because the first item is numbered as 0.
7. Enabling Geotargeting
To use ScraperAPI’s geotargeting, the only thing we have to do is adding the country_code parameter to our payload and set it to our country of choice – you can find all codes inside the documentation.
Let’s start by setting the parameter to it and changing the name of our JSON output to italy-products.json:
payload = {
'api_key': 'YOUR_API_KEY',
'country_code': 'it',
'url': 'https://www.newchic.com/kitchen-tools-and-gadgets-c-5037/'
}
Here’s the result after running the script:
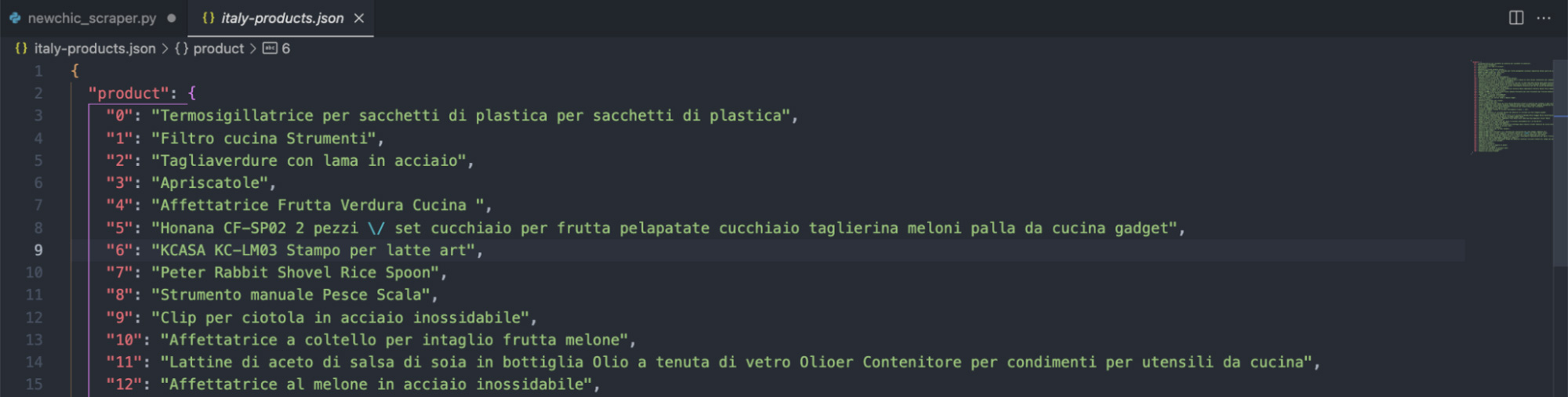
One thing you might have noticed is that we’re sending the request targeting the US version of the site, but because we’re telling ScraperAPI to use an Italy-based IP, NewChic is redirecting our script to the Italian subdomain.
The same happens if, for example, we set country_code=fr:
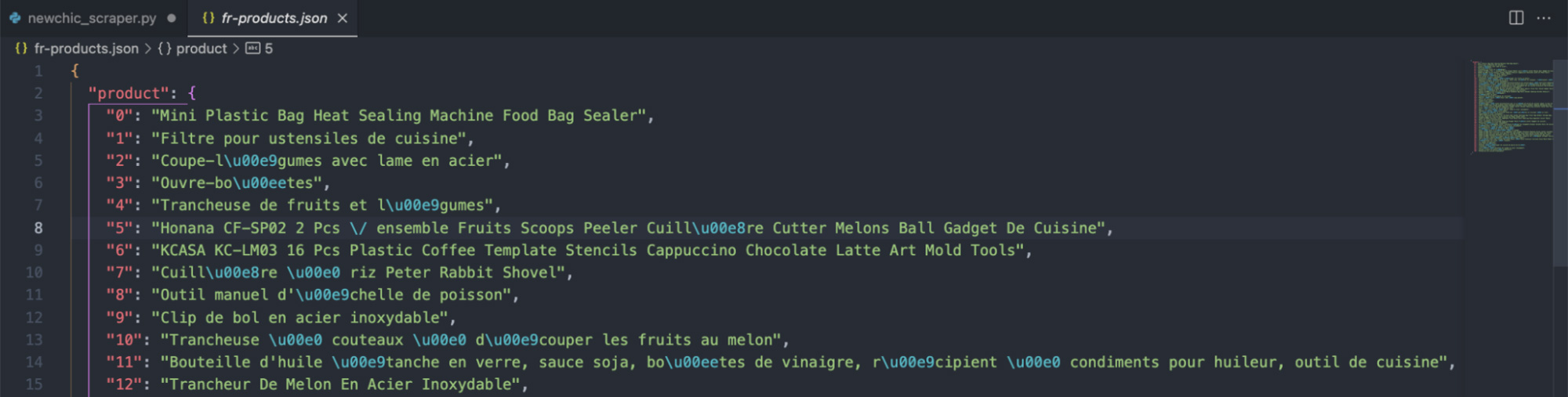
Just like that, we can use scraped localized data in any language and from any location without getting blocked by anti-scraping mechanisms.
Wrapping Up
You might wonder why we would use geotargeting if we could just target the corresponding subdomain. After all, if we send our request to https://it.newchic.com/kitchen-tools-and-gadgets-c-5037, we would get the same list of products with Italian names, right? Well… kinda.
As we said before, every website is different, so there are little nuances you need to keep in mind when collecting localized data.
For example, when using a different IP location (e.g., es) to send a request to the main version (which is in English), the server recognizes we’re in another country and routes us to the corresponding subdomain.
However, if we do the same but target a localized subdomain, that’s not what happens. No matter if we send a request with country_code=fr to the https://it.newchic.com/ version, we’ll always get data in Italian.
Although for NewChic itself doesn’t matter too much, in other scenarios, you could use this interaction to send a US request to the Italian subdomain of your target page and, more likely than not, get different results.
That’s because eCommerce sites want to sell you their products. So an Italian site will show you the products it can ship to the US.
A good example of this is Amazon. We can use ScraperAPI to send an IT request to Amazon’s Canada TLD (amazon.ca), and it’ll show us the best results from its Canadian catalog that has available shipping to Italy.
If you understand how sites work and the context of the data you need, geotargeting with ScraperAPI will be a powerful tool to get accurate results every time.
Until next time, happy scraping!





