


If you want to scrape Zillow data, you’ve come to the right place. Zillow is one of the largest real estate platforms, providing valuable insights into property prices, addresses, home details, agent contacts, and market trends. Scraping Zillow can help you collect and analyze real estate data at scale.
However, Zillow doesn’t make it easy to extract data in bulk, and its website has protections against web scraping. That means you need the right tools and techniques to avoid blocks and efficiently gather data.
In this guide, we’ll show you how to scrape Zillow listings using Python and ScraperAPI, making it simple to collect property data for research, investment, or analytics. We’ll also explore other methods, including Selenium for browser-based scraping and the Zillow API for structured access to listing data.
By the end of this tutorial, you’ll have a working solution to scrape Zillow real estate data quickly and efficiently.
Let’s get started!
Why Scrape Zillow for Real Estate Data?
Here’s how Zillow data can help you:
- Track market trends in real-time: See how property prices are shifting, compare Zestimates across different locations, and identify neighborhoods with the best investment potential.
- Find undervalued properties before others do: By analyzing listing data, price reductions, and historical trends, you can spot hidden investment opportunities before they gain attention.
- Build more innovative real estate investment models: With access to historical property prices, square footage, and local market data, you can develop more accurate projections for appreciation and rental income.
- Generate high-quality leads: Pull data on real estate agents, brokers, and property owners to create targeted outreach lists for networking and deals.
- Understand local demand and competition: Analyze for sale and rental listings, compare similar properties, and track how quickly homes sell in a specific area.
With the correct Zillow data, you can move faster, make better decisions, and gain a competitive edge.
How to Scrape Zillow Data with Python and ScraperAPI
Before scraping Zillow for real estate data, let’s review the essential project requirements. Since Zillow dynamically loads listings using JavaScript, we need a robust approach to extract data effectively.
Project Requirements
Here’s what we need:
1. Python Environment & Libraries
To build our Zillow scraper, we need Python and a few essential libraries:
requests– To send HTTP requests to Zillow via ScraperAPI.beautifulsoup4– To parse and extract data from Zillow’s HTML.pandas– To store and export the extracted data in a CSV file.json– To work with ScraperAPI’s render instruction set.time– To introduce delays and prevent rate-limiting.
Installation: Run the following command to install all required packages:
pip install requests beautifulsoup4 pandas
2. ScraperAPI for JavaScript-Rendered Pages
Since Zillow loads data dynamically, standard requests won’t fetch the listings. That’s why we use ScraperAPI, a powerful proxy-based tool that renders JavaScript before delivering the HTML.
You’ll need a ScraperAPI key, which you can get for free by signing up at ScraperAPI.
3. URL Structure for Zillow Listings
Zillow organizes its real estate listings by location. For example, Houston’s main page is:
https://www.zillow.com/houston-tx/
For paginated results (pages 2, 3, 4, etc.), Zillow follows this format:
https://www.zillow.com/houston-tx/2_p/
https://www.zillow.com/houston-tx/3_p/
This allows us to loop through multiple pages when scraping.
4. Data Points to Extract
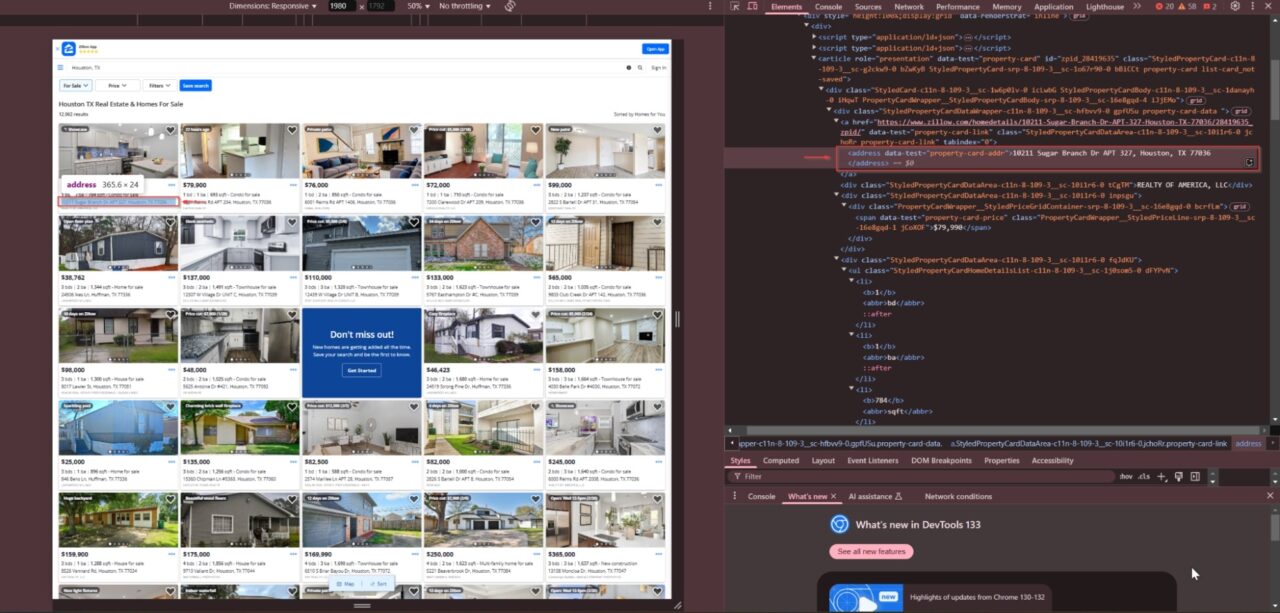
We want to collect the price, address, number of beds, baths, and square footage from each listing. We need to inspect the Zillow page’s HTML structure to locate this information.
To get the correct CSS selectors:
- Open the Zillow search results page
- Press F12 or right-click and select Inspect
- Navigate to the Elements tab
- Hover over elements to find the relevant HTML structure
We can see that each listing contains an address wrapped in an <address> tag. The data-test attribute uniquely identifies it:
The price of the property is stored inside a <span> element with the data-test="property-card-price" attribute:

The beds, baths, and square footage details are located inside a <ul> list with the class StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0:

Each data point is stored within <li> tags:
- Beds: First
<li> - Baths: Second
<li> - Square Footage: Third
<li>
Using these CSS selectors, we ensure that our scraper accurately targets the correct elements on the page and extracts clean, structured real estate data.
Now that we have all our requirements, let’s dive into the actual scraping process!
Step 1: Set Up ScraperAPI for JavaScript Execution
Since Zillow listings load dynamically, using ScraperAPI ensures we get fully rendered HTML. We pass our API key in the request headers:
# ScraperAPI Key
API_KEY = "YOUR_SCRAPERAPI_KEY" # Replace with your key
# ScraperAPI headers
HEADERS = {
"x-sapi-api_key": API_KEY,
"x-sapi-render": "true"
}
Regular requests.get() calls won’t work because Zillow loads listings via JavaScript. ScraperAPI renders the page before sending us the HTML.
Step 2: Understand Zillow’s Pagination Structure
Zillow organizes listings into multiple pages, using URLs like:
https://www.zillow.com/houston-tx/2_p/ # Page 2
https://www.zillow.com/houston-tx/3_p/ # Page 3
To handle this, we create a loop that cycles through 5 pages:
BASE_URL = "https://www.zillow.com/houston-tx/{}_p/"
for page in range(1, 6): # Scrape first 5 pages
page_url = BASE_URL.format(page)
print(f"Scraping Page {page}: {page_url}")
The {}_p/ in the BASE_URL is a placeholder that gets replaced by the page number in our loop, allowing us to scrape multiple pages dynamically.
Step 3: Handle JavaScript-Loaded Data with ScraperAPI Render Instructions Set
Zillow loads listings asynchronously, so we need to tell ScraperAPI to:
- Wait until property prices appear
- Scroll down to load more listings
- Wait a few extra seconds for everything to stabilize
We define these steps in a JSON instruction set:
instruction_set = json.dumps([
{"type": "wait_for_selector", "selector": {"type": "css", "value": "span[data-test='property-card-price']"}},
{"type": "scroll", "direction": "y", "value": "bottom"},
{"type": "wait", "value": 5} # Wait 5 seconds for content
])
This ensures that ScraperAPI mimics human-like browsing behavior.
Step 4: Extract Key Details from Each Listing
Once the page fully loads, we use BeautifulSoup to parse the HTML and extract property details:
soup = BeautifulSoup(response.text, "html.parser")
property_cards = soup.find_all("li", class_="ListItem-c11n-8-109-3__sc-13rwu5a-0 StyledListCardWrapper-srp-8-109-3__sc-wtsrtn-0 gnrjeR kZVExn")
for card in property_cards:
price = card.find("span", {"data-test": "property-card-price"})
address = card.find("address", {"data-test": "property-card-addr"})
details_list = card.find("ul", class_="StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 dFYPvN")
Now, let’s clean the extracted data.
Step 5: Clean and Format the Data
Raw data from Zillow often contains extra characters, inconsistent formatting, or missing values. If we save the data directly, it will be messy and complicated to analyze. That’s why we must clean and format the extracted data before storing it.
To achieve this, we use three helper functions:
1. clean_text() – Removing Unwanted Characters
Zillow listings sometimes include unnecessary line breaks (\n), carriage returns (\r), or excessive spaces in their text.
def clean_text(text):
return text.replace("\n", " ").replace("\r", "").strip() if text else "N/A"
What this function does:
- Replaces newlines (
\n) and carriage returns (\r) with spaces - Removes leading and trailing spaces using
.strip() - If the text is empty or missing, it returns
"N/A"to maintain consistency
2. format_price() – Standardizing Price Data
Zillow lists prices in a human-readable format with dollar signs and commas (e.g., $350,000). But if we want to use this data for analysis or calculations, we must strip out these symbols and store the price as a clean number.
def format_price(price):
return price.replace("$", "").replace(",", "").strip() if price else "N/A"
What this function does:
- Removes the dollar sign (
$) and commas (,) from the price string - Uses
.strip()to remove any leading/trailing spaces - If the price is missing, it returns
"N/A"
3. format_number() – Extracting Numeric Values from Text
Beds, baths, and square footage values are often displayed in a descriptive format like "3 bds", "2 ba", or "1,500 sqft". However, for structured data, we only need to extract the numbers.
def format_number(value):
return "".join(filter(str.isdigit, value)) if value and any(char.isdigit() for char in value) else "N/A"
What this function does:
- Extracts only digits from a string (e.g.,
"3 bds"→"3") - If no digits are found, it returns
"N/A"to handle missing values properly
Now, let’s apply it to our data:
formatted_price = format_price(price.text.strip() if price else "N/A")
formatted_address = clean_text(address.text if address else "N/A")
formatted_beds = format_number(beds)
formatted_baths = format_number(baths)
formatted_sqft = format_number(sqft)
Before formatting, our scraped data might look like this:
Price: $350,000
Address:
1234 Main St
Houston, TX 77002
Beds: 4 bds
Baths: 2 ba
Sqft: 1,800 sqft
After applying our cleaning functions, the formatted output will be:
Price: 350000
Address: 1234 Main St, Houston, TX 77002
Beds: 4
Baths: 2
Sqft: 1800
When saved to CSV, it will look like this:
Price ($),Address,Beds,Baths,Sqft
350000,1234 Main St, Houston, TX 77002,4,2,1800
This ensures consistency, cleanliness, and ease of analysis when working with the data.
Step 6: Save the Data to a CSV File
Once we have collected and formatted the data, the final step is to store it in a structured format for analysis, reporting, or visualization. The most common format for storing structured data is a CSV (Comma-Separated Values) file, which can be opened in Excel, Google Sheets or used in data science projects.
We use pandas to create a CSV file from the extracted listings:
if listings:
# Remove entries where price is "N/A" since they are likely incomplete listings
listings = [listing for listing in listings if listing["Price ($)"] != "N/A"]
# Convert the cleaned data into a DataFrame
df = pd.DataFrame(listings)
# Save the DataFrame as a CSV file
df.to_csv("zillow_houston_listings.csv", index=False)
print("✅ Data saved to zillow_houston_listings.csv")
Code Breakdown:
Filtering Out Incomplete Listings
- Some properties might not have a listed price (e.g., “Contact for price”).
- We remove such entries to ensure data consistency.
Creating a Pandas DataFrame
pd.DataFrame(listings)converts our list of dictionaries into a structured format.- Each row represents a property, and each column represents a property attribute (price, address, beds, baths, sqft).
Saving the Data to CSV
.to_csv("zillow_houston_listings.csv", index=False)saves the DataFrame as a CSV file.- We set
index=Falseto avoid adding an extra index column in the CSV.
After running the scraper, our CSV file (zillow_houston_listings.csv) will look like this:
Price ($) Address Beds Baths Sqft Page
250000 8017 Lawler St, Houston, TX 77051 3 1 1300 1
320000 1234 Main St, Houston, TX 77002 4 2 1800 2
175000 5678 Oak Dr, Houston, TX 77005 3 2 1500 3
Now, we have cleaned, structured real estate data that can be used for data analysis, pricing trends, or market research!
Here’s the complete code:
import requests
import json
import time
import pandas as pd
from bs4 import BeautifulSoup
# ScraperAPI Key
API_KEY = "YOUR_SCRAPERAPI_KEY" # Replace with your ScraperAPI key
# Zillow URL format for pagination
BASE_URL = "https://www.zillow.com/houston-tx/{}_p/" # {} will be replaced with the page number
# ScraperAPI headers
HEADERS = {
"x-sapi-api_key": API_KEY,
"x-sapi-render": "true"
}
# Render Instruction Set
instruction_set = json.dumps([
{"type": "wait_for_selector", "selector": {"type": "css", "value": "span[data-test='property-card-price']"}},
{"type": "scroll", "direction": "y", "value": "bottom"},
{"type": "wait", "value": 5} # Wait 5 seconds for all content to load
])
def clean_text(text):
"""Removes unwanted characters and trims spaces."""
return text.replace("\n", " ").replace("\r", "").strip() if text else "N/A"
def format_price(price):
"""Cleans up price formatting (e.g., '$98,000' -> '98000')."""
return price.replace("$", "").replace(",", "").strip() if price else "N/A"
def format_number(value):
"""Extracts numeric values from strings like '3 bds' -> '3'."""
return "".join(filter(str.isdigit, value)) if value and any(char.isdigit() for char in value) else "N/A"
def scrape_zillow_listings(max_pages=5):
"""Scrape Zillow listings"""
properties = []
for page in range(1, max_pages + 1): # Loop through the first 5 pages
page_url = BASE_URL.format(page)
print(f"Scraping Page {page}: {page_url}")
for attempt in range(3): # Retry up to 3 times if necessary
try:
headers = HEADERS.copy()
headers["x-sapi-instruction_set"] = instruction_set
response = requests.get("https://api.scraperapi.com/", params={"url": page_url, "render": "true"}, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
property_cards = soup.find_all("li", class_="ListItem-c11n-8-109-3__sc-13rwu5a-0 StyledListCardWrapper-srp-8-109-3__sc-wtsrtn-0 gnrjeR kZVExn")
for card in property_cards:
price = card.find("span", {"data-test": "property-card-price"})
address = card.find("address", {"data-test": "property-card-addr"})
details_list = card.find("ul", class_="StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 dFYPvN")
# Extract beds, baths, and sqft from the <li> tags
details = details_list.find_all("li") if details_list else []
beds = details[0].text.strip() if len(details) > 0 else "N/A"
baths = details[1].text.strip() if len(details) > 1 else "N/A"
sqft = details[2].text.strip() if len(details) > 2 else "N/A"
# Clean and format data
formatted_price = format_price(price.text.strip() if price else "N/A")
formatted_address = clean_text(address.text if address else "N/A")
formatted_beds = format_number(beds)
formatted_baths = format_number(baths)
formatted_sqft = format_number(sqft)
properties.append({
"Price ($)": formatted_price,
"Address": formatted_address,
"Beds": formatted_beds,
"Baths": formatted_baths,
"Sqft": formatted_sqft,
"Page": page # Add page number for reference
})
print(f"Scraped {len(properties)} total properties so far.")
time.sleep(3) # Wait before scraping the next page
break # Exit retry loop on success
elif response.status_code == 500:
print(f"Error 500 on attempt {attempt + 1}. Retrying in {2 * attempt} seconds...")
time.sleep(2 * attempt)
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
return properties
# Run the scraper
listings = scrape_zillow_listings()
# Save results to CSV
if listings:
listings = [listing for listing in listings if listing["Price ($)"] != "N/A"]
df = pd.DataFrame(listings)
df.to_csv("zillow_houston_listings.csv", index=False)
print("Data saved to zillow_houston_listings.csv")
Other Methods to Scrape Zillow Data
While using ScraperAPI is an efficient way to extract Zillow listings, it’s not the only option. If you need more control over the scraping process or prefer structured data, there are two key alternatives: Selenium and the Zillow API.
- Selenium allows you to automate a real browser, making it ideal for handling dynamic content and interactive elements. However, it’s slower and more resource-intensive than API-based scraping.
- The Zillow API provides structured access to real estate data without web scraping but with access restrictions and rate limits.
Scraping Zillow with Selenium: A Browser-Based Zillow Scraper
Instead of relying on ScraperAPI alone, Selenium enables us to load Zillow listings in a real browser, interact with dynamic content, and extract structured real estate data. Although this method offers more flexibility, it requires more resources and is slower than a traditional API-based web scraping tool.
Step 1: Set Up Selenium with ScraperAPI Proxy
To create a Zillow scraper, we configure Selenium Wire to route traffic through ScraperAPI. This helps bypass bot detection mechanisms and prevents Zillow from blocking requests due to high activity.
import time
import pandas as pd
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
# ScraperAPI Key
API_KEY = "YOUR_SCRAPERAPI_KEY" # Replace with your key
# Zillow URL (Houston, TX - First Page)
URL = "https://www.zillow.com/houston-tx/"
# Proxy options with ScraperAPI
proxy_options = {
'proxy': {
'http': f'https://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'https': f'https://scraperapi.render=true.country_code=us.premium=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
# Chrome options to ignore certificate errors
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--ignore-certificate-errors')
# Initialize the WebDriver
driver = webdriver.Chrome(seleniumwire_options=proxy_options, options=chrome_options)
This setup ensures our requests are routed through ScraperAPI, allowing us to extract data from Zillow listings while minimizing the chances of getting blocked.
Step 2: Extract Zillow Listings with Selenium
Once the Zillow page loads, we identify and parse property listings using CSS selectors. The script collects real estate data, including property prices, addresses, beds, baths, and square footage.
def scrape_zillow_page():
"""Scrape a single Zillow search results page and extract listing data."""
properties = []
print(f"Scraping: {URL}")
driver.get(URL)
time.sleep(5) # Wait for the page to load
listings = driver.find_elements(By.CLASS_NAME, "ListItem-c11n-8-109-3__sc-13rwu5a-0")
for listing in listings:
try:
price = listing.find_element(By.CSS_SELECTOR, "span[data-test='property-card-price']").text
address = listing.find_element(By.CSS_SELECTOR, "address[data-test='property-card-addr']").text
details = listing.find_elements(By.CSS_SELECTOR, "ul.StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 li")
beds = details[0].text if len(details) > 0 else "N/A"
baths = details[1].text if len(details) > 1 else "N/A"
sqft = details[2].text if len(details) > 2 else "N/A"
properties.append({
"Price ($)": price.replace("$", "").replace(",", "").strip(),
"Address": address.replace("\n", ", ").strip(),
"Beds": "".join(filter(str.isdigit, beds)) if beds != "N/A" else "N/A",
"Baths": "".join(filter(str.isdigit, baths)) if baths != "N/A" else "N/A",
"Sqft": "".join(filter(str.isdigit, sqft)) if sqft != "N/A" else "N/A",
})
except Exception:
continue # Skip listings that fail to load
print(f"Scraped {len(properties)} properties.")
return properties
This function:
- Loads Zillow property listings in Chrome using Selenium
- Extracts property details, including address, price, and size
- Parses the extracted HTML elements for structured data
Step 3: Store Extracted Zillow Data in a CSV File
After extracting the real estate data, we save it in a CSV file for further analysis in Excel, Google Sheets, or a database.
# Run the scraper
listings = scrape_zillow_page()
# Close WebDriver
driver.quit()
# Save results to CSV
if listings:
df = pd.DataFrame(listings)
df.to_csv("zillow_houston_selenium.csv", index=False)
print("Data saved to zillow_houston_selenium.csv")
This will generate a structured CSV file with Zillow’s real estate data!
Price ($),Address,Beds,Baths,Sqft
250000,8017 Lawler St, Houston, TX 77051,3,1,1300
320000,1234 Main St, Houston, TX 77002,4,2,1800
175000,5678 Oak Dr, Houston, TX 77005,3,2,1500
Selenium requires loading an actual browser; it is significantly slower and more resource-intensive than using ScraperAPI’s render instructions. For most data scraping tasks, ScraperAPI remains the preferred method.
Both approaches provide ways to extract data from Zillow, but the choice depends on whether speed or interactivity is more important for your use case.
Using the Zillow API for Real Estate Data
Another alternative to web scraping is the Zillow API, which provides access to structured real estate data without manually extracting it from Zillow pages. This API can be helpful if you need direct access to property data without handling CAPTCHAs, proxies, or JavaScript rendering.
Pros of the Zillow API
- Structured data: Unlike scraping, which involves parsing raw HTML, the API returns JSON or XML in a well-organized format.
- No need for HTML parsing: Since data is delivered directly, you don’t have to extract details from messy web pages.
- More stable than web scraping: Website structures can change frequently, while an API remains relatively stable.
Cons of the Zillow API
- Limited access: The API does not provide full access to property listings, pricing history, or real estate agent contacts.
- Requires an API key: You must apply for access, and Zillow does not guarantee approval.
- Usage restrictions: The API enforces rate limits, making large-scale data collection difficult.
To explore the Zillow API further, you can check out their official documentation here. However, web scraping is still the best approach if you need unrestricted access to Zillow listings, agent contacts, and market trends.
How to Turn Zillow Pages into LLM-Ready Data
Zillow pages are full of dynamic content, inconsistent layouts, and complex code. If you’ve ever tried to analyse them with a large language model (LLM), you know how painful parsing raw HTML can be.
But there’s a better way.
By scraping Zillow with output_format=markdown with ScraperAPI, you get clean, readable content that tools like Google Gemini can process effortlessly. It’s perfect for generating summaries, comparing listings, or extracting functional patterns, without cleaning up the data yourself.
Let’s walk through how to go from messy pages to a polished property analysis fast.
Step 1: Obtain and Secure Your API Keys
To get started, you’ll need two things: a ScraperAPI key and a Google Gemini API key. If you already have them, you can skip to the next step.
If you don’t have them yet, no stress:
You can get your ScraperAPI key from your dashboard or sign up here for a free one with 5,000 API credits.
To get a Gemini API key:
- Go to Google AI Studio
- Sign in with your Google account
- Click on Create API Key
- Follow the prompts to generate your key
Step 2: Scrape Zillow as Markdown
Let’s start by scraping Zillow listings from Houston, Texas, using ScraperAPI, but with output_format=markdown included in the request payload. This returns a text-based version of the page that LLMs can easily understand.
import requests
API_KEY = "YOUR_API_KEY"
url = "https://www.zillow.com/houston-tx/"
payload = {
"api_key": API_KEY,
"output_format":"markdown",
"render":"true",
"country":"us",
"url": url}
response = requests.get("https://api.scraperapi.com", params=payload)
markdown_data = response.text
print(markdown_data)
Sample Output:
* [8014 Wray Ct, Houston, TX 77088](https://www.zillow.com/homedetails/8014-Wray-Ct-Houston-TX-77088/28164905%5Fzpid/)
TEXAS GRAND REAL ESTATE INC.
$344,900
* **5** bds
* **3** ba
* **2,957** sqft
\- House for sale
Show more
[TRUNCATED]
Step 3: Summarize the Zillow Page with Gemini
With our Markdown output in hand, it’s time to extract a clean summary using Google Gemini.
Start by installing the Gemini SDK if you haven’t already:
pip install google-generativeai
Now, configure Gemini with your API key, and use a prompt that tells Gemini exactly what to extract. You can tweak this prompt later to pull other fields or formats:
# --- Step 2: Configure Gemini ---
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel(model_name="gemini-2.0-flash")
# --- Step 3: Ask for a summary ---
prompt = f"""
You're a real estate market analyst. Below is a Markdown-formatted list of property listings from Zillow for homes in Houston, TX.
From this data, identify the **top 5 most attractive listings** for a potential homebuyer. For each, include:
- Price
- Bedrooms and bathrooms
- Location
- Size in square feet
- Key features (e.g., yard, garage, renovations)
- Why this is a strong listing
Summarize it clearly and concisely for a real estate blog.
Here's the data:
{markdown_data}
"""
response = model.generate_content(prompt)
print(response.text)
Scraping Zillow with output_format=markdown gives you a clean input that LLMs like Gemini can easily understand. And because it’s just text, you don’t need to do any parsing or tag extraction yourself
You should see a response similar to this:
Here's a summary of the top 5 most attractive listings from the provided Zillow data for a potential Houston homebuyer, formatted for a real estate blog:
## Houston's Hottest Homes: Top 5 Listings This Week!
Looking for your dream home in Houston? We've analyzed the latest Zillow listings and compiled a list of the top 5 properties that offer the best value and features for potential buyers.
1. **8014 Wray Ct, Houston, TX 77088**
* **Price:** \$344,900
* **Beds/Baths:** 5 beds / 3 baths
* **Size:** 2,957 sqft
* **Key Features:** Spacious layout, ideal for larger families
* **Why it's strong:** A fantastic price for a 5-bedroom home of this size in Houston. Offers plenty of room to grow. The open house provides an immediate opportunity to view the property.
2. **10902 Brentway Dr, Houston, TX 77070**
* **Price:** \$375,000
* **Beds/Baths:** 5 beds / 4 baths
* **Size:** 3,142 sqft
* **Key Features:** Expansive space and multiple bathrooms.
* **Why it's strong:** Similar to Wray Ct, this home offers generous space at a competitive price point. The additional bathroom is a major plus for larger families or those who frequently host guests.
3. **14202 Double Pine Dr, Houston, TX 77015**
* **Price:** \$249,900
* **Beds/Baths:** 3 beds / 2 baths
* **Size:** 2,308 sqft
* **Key Features:** Good size for the price.
* **Why it's strong:** This listing is a great value for the square footage offered. It's a solid choice for first-time homebuyers or those looking for a more manageable property.
4. **14615 Woodmaple Ct, Houston, TX 77015**
* **Price:** \$270,000
* **Beds/Baths:** 4 beds / 3 baths
* **Size:** 2,137 sqft
* **Key Features:** 4 bedrooms and 3 bathrooms at a competitive price.
* **Why it's strong:** Offers a great balance of space, number of bedrooms and bathrooms, and affordability. Ideal for growing families.
5. **8530 Lake Crystal Dr, Houston, TX 77095**
* **Price:** \$239,000
* **Beds/Baths:** 3 beds / 3 baths
* **Size:** 1,996 sqft
* **Key Features:** Three bathrooms are desirable.
* **Why it's strong:** A three-bathroom home at this price is appealing. This property would suit families or roommates looking for space and convenience.
As Gemini’s summary shows, this method gives you a quick, easy-to-read snapshot of Zillow listings. No need to dig through dozens of pages. We pulled out the key details: price, size, number of bedrooms, location, and special features like parking or renovations.
The best part? It’s flexible. You can tweak the prompt to match your goals, like finding the best value rentals, comparing neighbourhoods, or filtering by features like balconies or furnished apartments.
One ScraperAPI request and a well-crafted Gemini prompt are all it takes to skip the stress of scraping Zillow and make sense of the housing market at scale.
Conclusion: Choose the Best Zillow Scraper for Your Needs
There are multiple ways to scrape Zillow data, but the best method depends on your needs.
- ScraperAPI Render Instructions: This is the best choice for fast, scalable, and hassle-free scraping. It automatically handles IP rotation, CAPTCHA solving, and JavaScript rendering, so you don’t have to.
- Selenium: A good option if you need browser automation, but it’s slower, more complex, and harder to scale.
- Zillow API: Provides structured data but has access restrictions and rate limits, making it less flexible for large-scale scraping.
For most users, using the ScraperAPI Render Instructions Set is the easiest and most efficient way to scrape Zillow listings at scale. It removes the need for complex proxies, user agents, and headless browsers, letting you focus on extracting the real estate data you need.
Ready to start scraping Zillow? Sign up for a free ScraperAPI account and try it on your Zillow scraping projects today!