



TL;DR: Full Trustpilot Reviews Scraper Code
Here’s the completed code for Trustpilot.com web scraper for those in a hurry:
from bs4 import BeautifulSoup
import requests
import csv
company = "nookmart.com"
base_url = f"https://www.trustpilot.com/review/{company}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'accept-language': 'en-US,en;q=0.9'
}
payload = {
'api_key': "YOUR API KEY",
'url': base_url,
'render': 'true',
'keep_headers': 'true',
}
try:
response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
pages_to_scrape = 10
with open('trustpilot_reviews.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['Reviewer', 'Rating', 'Review', 'Date'])
for page in range(1, pages_to_scrape):
payload['url'] = f"{base_url}?page={page}"
page_response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
reviews = page_soup.find_all('div', {"class": "styles_reviewCardInner__EwDq2"})
for review in reviews:
reviewer = review.find("span", attrs={"class": "typography_heading-xxs__QKBS8"}).text
rating = review.find("div", attrs={"class": "styles_reviewHeader__iU9Px"})["data-service-review-rating"]
content_element = review.find("p", attrs={"class": "typography_body-l__KUYFJ"})
content = content_element.text if content_element else 'None'
date = review.find("p", attrs={"class":"typography_body-m__xgxZ_ typography_appearance-default__AAY17"}).text
csv_writer.writerow([reviewer, rating, content, date])
print("Data Extraction Successful!")
except Exception as e:
print("An error occurred:", e)
Before running the code, add your API key to the api_key parameter within the payload.
Note: Don’t have an API key? Create a free ScraperAPI account to get 5,000 API credits to try all our tools for 7 days.
Want to see how we built it? Keep reading and join us on this exciting scraping journey!
Requirements for Extracting Reviews from Trustpilot
Before we start scraping Trustpilot reviews, it’s crucial to set up our environment with all the essential tools and libraries. Here’s how you can get started:
- Python Installation: Ensure you have Python installed, ideally version 3.10 or later, which you can download from the official Python website.
- Library Installations: We’ll need two essential Python libraries –
requestsandBeautifulSoup(bs4). Open your terminal or command prompt and install them using the command:
pip install requests beautifulsoup4
requests: This library is our trusty tool for sending HTTP requests to ScraperAPI. It’s essential for fetching the HTML content from Trustpilot, acting as the bridge between our script and the website. Essentially, it retrieves the HTML we need, playing a vital role in connecting our data extraction efforts with Trustpilot’s online reviews.- bs4 (
Beautiful Soup): BeautifulSoup is our go-to for parsing HTML. It navigates through the complex structure of Trustpilot’s web pages, allowing us to extract the specific data we need – the reviews, ratings, and user comments. This powerful parser simplifies the process of sifting through complex page structures, enabling us to extract meaningful data efficiently.
Understanding Trustpilot’s Website Layout
Now that we have our environment set up for scraping, let’s break down how Trustpilot’s site is set up to figure out how the information we need is stored on the site.
Understanding the site’s layout and identifying key HTML elements that hold the review data is crucial for our scraping. We need to pinpoint and extract important details from each review, such as ratings, customer comments, and reviewer names.
Grasping Trustpilot’s webpage structure will streamline our scraping process, ensuring we accurately collect the valuable insights these reviews offer.
In this article, we’re going to be looking at the Trustpilot review page for the company “Nookmart”, which is an online platform where players of the game “Animal Crossing: New Horizons” can purchase various in-game items.
This is what the page looks like on Trustpilot:
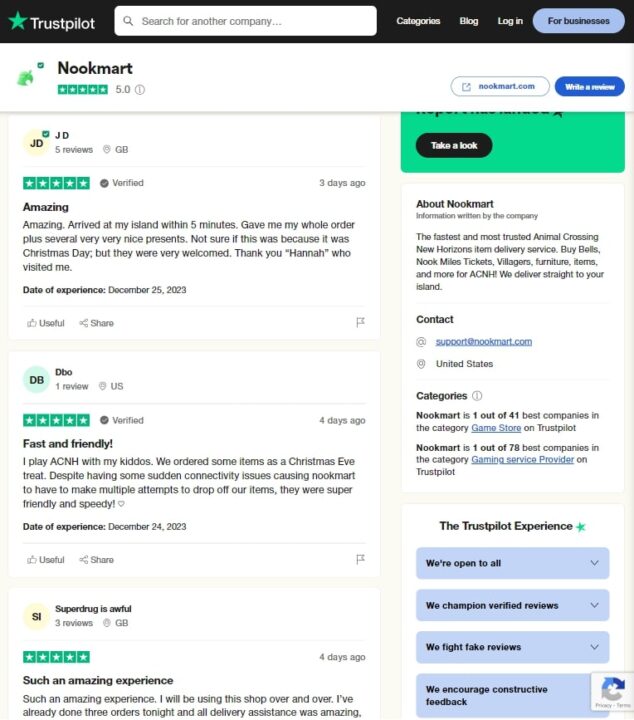
We are going to be scraping each individual review, so we need to locate the HTML elements holding the data we need. To do this, we’ll use the developer tools (right-click on the webpage and select ‘inspect’) to examine the HTML structure.
This div tag containsthe information of each individual review: styles_reviewCardInner__EwDq2.
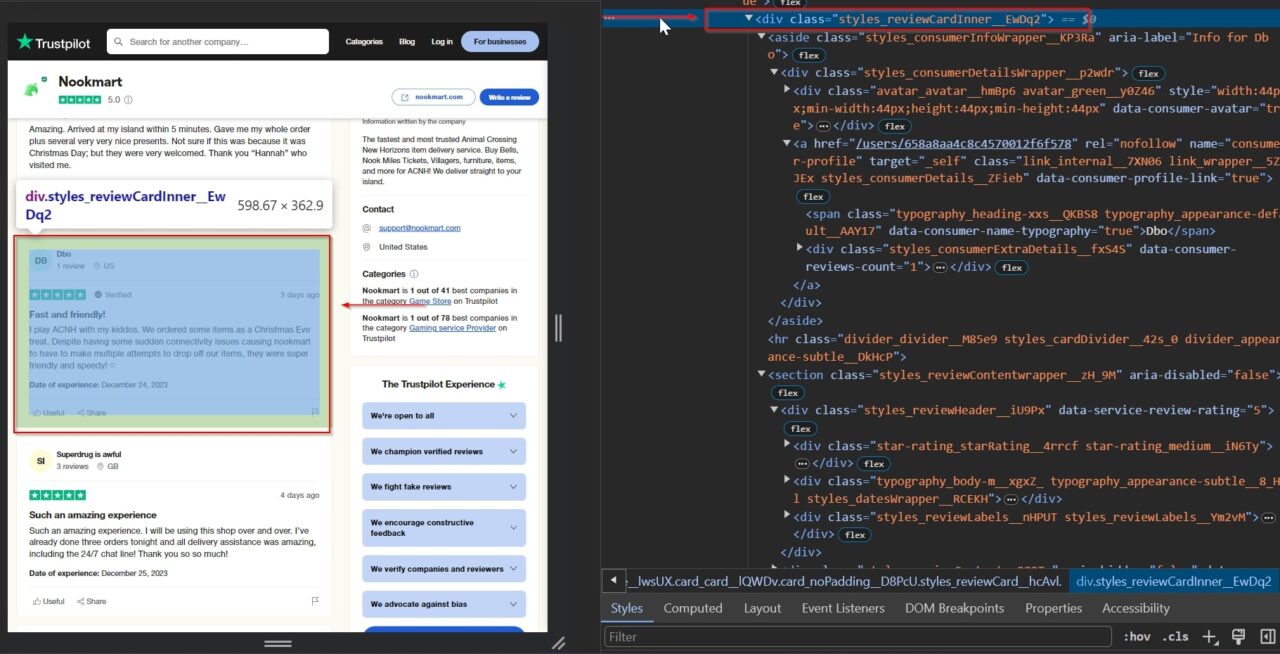
Extracting reviewer names from Trustpilot helps authenticate reviews, enables trend analysis from repeated feedback, and facilitates personalized customer engagement.
Additionally, it can also offer demographic insights and help build profiles for frequent reviewers.
This span tag contains the reviewer’s name:
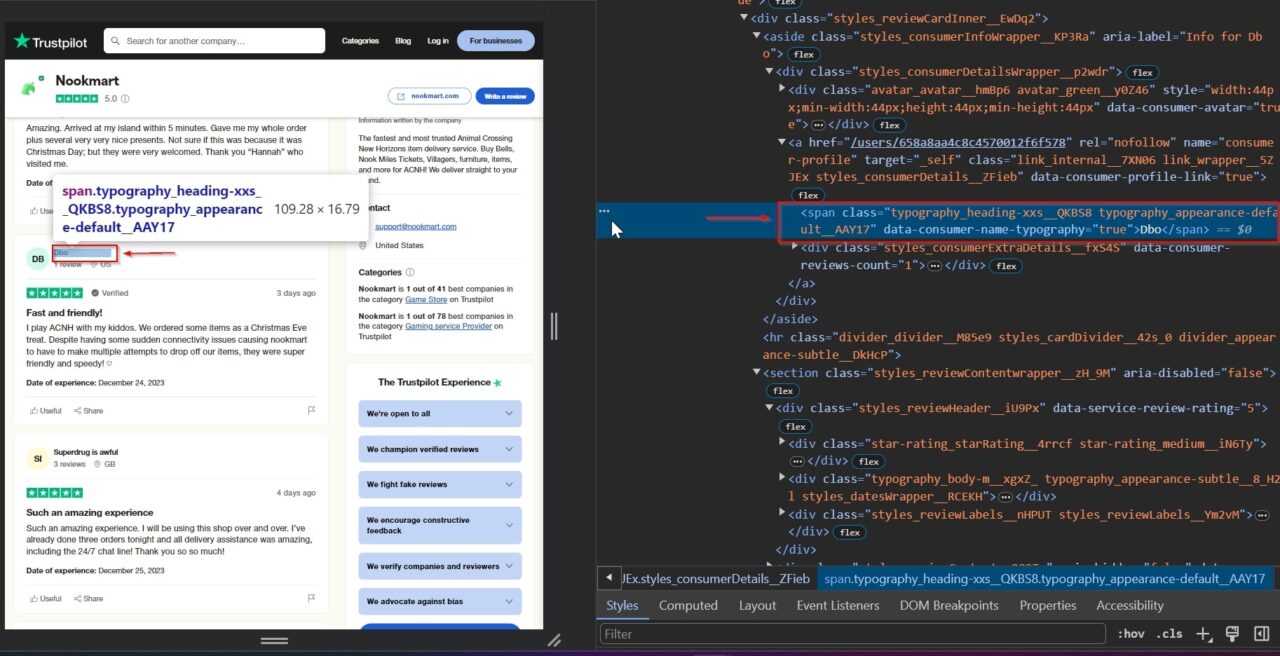
We’ll also be scraping the rating given by the reviewer. The ratings offer a direct measure of customer satisfaction, which is crucial for assessing product or service quality. They allow you to gauge overall customer sentiment, track performance trends, and conduct comparative analyses with competitors.
Analyzing these ratings can reveal essential areas for improvement and help enhance business offerings.
This div tag contains the rating: styles_reviewHeader__iU9Px. It’s stored within an attribute called data-service-review-rating.
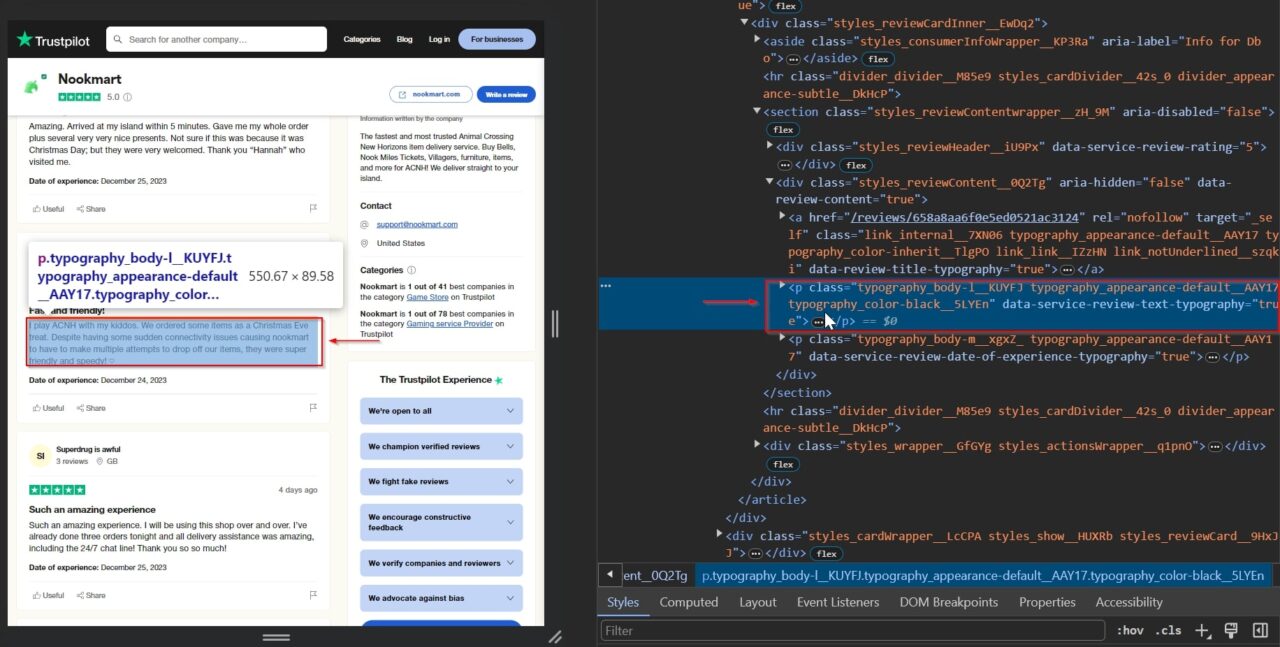
We’ll also be scraping the actual review content, which is key to unlocking deeper customer insights. This content is invaluable for gaining deeper insights into customer satisfaction, as it contains detailed feedback beyond just ratings.
Understanding these nuances aids in making targeted improvements, fostering better customer relationships, and ultimately elevating the overall quality of your offerings.
This p tag contains the actual review content: typography_body-l__KUYFJ
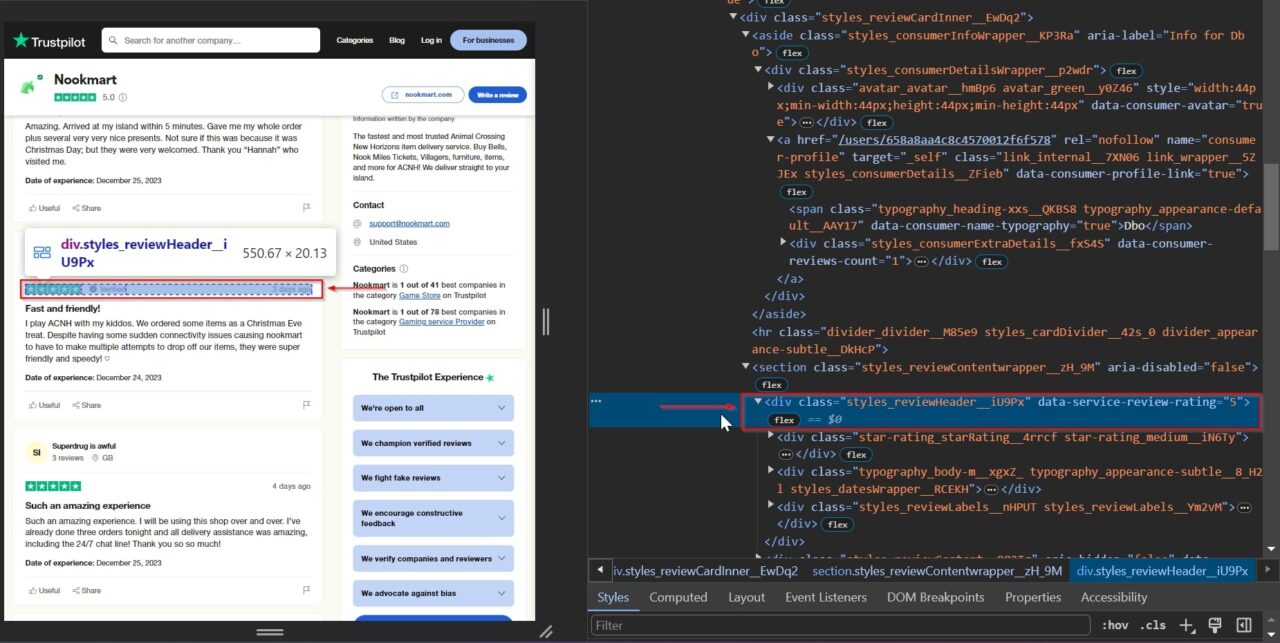
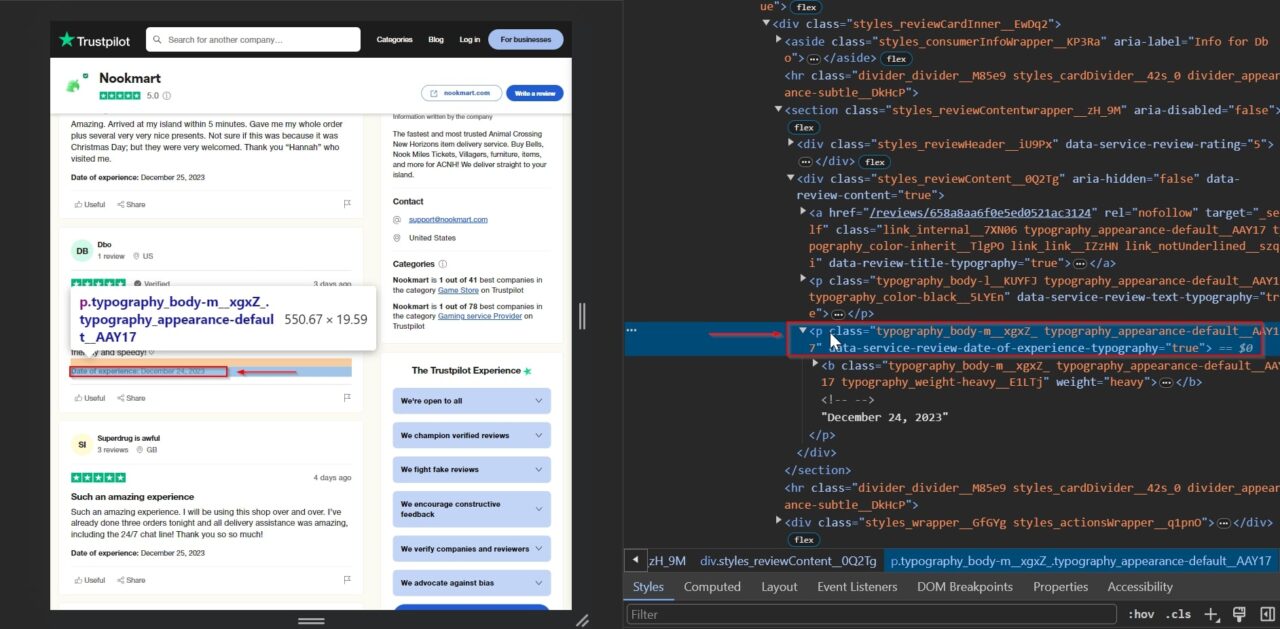
Lastly, we will be scraping the date the customer experienced what they are describing in the review. This helps provide context to the review, helping us understand when the described experience took place.
This p tag contains the date of experience: typography_body-m__xgxZ_ typography_appearance-default__AAY17.
Now we’re all set to start scraping!
How to Scrape Trustpilot Reviews and Company Data with Python
To scrape Trustpilot reviews, our script will systematically loop through the review pages, collecting key details like reviewer names, ratings, review content, and the date of experience from each one.
This approach ensures a streamlined and automated process, allowing us to gather a comprehensive dataset of customer feedbacks for in-depth analysis.
Step 1: Import Libraries and Define the Target URL
We start by importing the necessary Python libraries – BeautifulSoup for HTML parsing, requests for making HTTP requests, and csv for file operations.
We define the target URL, pointing to the Trustpilot review page of ‘nookmart.com’.
The company variable can be changed to any company you want to scrape.
from bs4 import BeautifulSoup
import requests
import csv
company = "nookmart.com"
base_url = f"https://www.trustpilot.com/review/{company}"
Step 2: Configure Request Parameters and Send Request
Next, we set up our script to interact with the web like a browser, using HTTP headers and a ‘User-Agent’, which is a string that tells Trustpilot’s server what kind of browser we’re using.
The payload, including our ScraperAPI key and Trustpilot’s URL, directs ScraperAPI to the right page. We also enable full-page rendering, ensuring dynamic content is loaded.
headers = {
'User-Agent': 'Mozilla/5.0 ...',
'accept-language': 'en-US,en;q=0.9'
}
payload = {
'api_key': "YOUR_API_KEY",
'url': base_url,
'render': 'true',
'keep_headers': 'true',
}
Next, we send our request to ScraperAPI; ScraperAPI then accesses Trustpilot’s page on our behalf, handles any potential anti-bot measures, and retrieves the site’s HTML content, which our script can then process. This setup is key to successfully scraping data from websites with anti-scraping technologies.
response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
Step 3: Parse Trustpilot with BeautifulSoup
We use BeautifulSoup to parse the HTML content received from Trustpilot. This helps us in breaking down the webpage structure for easy data extraction – which is super important because it’s what makes it possible for us to pull out the reviews and analyze them.
soup = BeautifulSoup(response.content, 'html.parser')
Step 4: Store Trustpilot Reviews in a CSV File
After parsing, we open a CSV file named ‘trustpilot_reviews.csv’ for writing. We then prepare column headers for storing reviewer names, ratings, review content – including negative reviews–, and the date of the review.
with open('trustpilot_reviews.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['Reviewer', 'Rating', 'Review', 'Date'])
Step 5: Loop Through Trustpilot’s Pagination and Extract the Reviews
Now, we get to the heart of our scraping process. We loop through 10 pages of Trustpilot reviews for ‘Nookmart’.
On each page, we send a request and then extract critical information from every review present using the HTML elements we identified earlier.
For each review found, we write these details into our trustpilot_reviews.csv file, ensuring the data is neatly organized and ready for any subsequent analysis.
By processing multiple pages, we build a rich dataset that represents a wide array of customer experiences and opinions, providing a thorough understanding of the company’s service as seen through the eyes of its customers.
for page in range(1, pages_to_scrape):
payload['url'] = f"{base_url}?page={page}"
page_response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
reviews = page_soup.find_all('div', {"class": "styles_reviewCardInner__EwDq2"})
for review in reviews:
reviewer = review.find("span", attrs={"class": "typography_heading-xxs__QKBS8"}).text
rating = review.find("div", attrs={"class": "styles_reviewHeader__iU9Px"})["data-service-review-rating"]
content_element = review.find("p", attrs={"class": "typography_body-l__KUYFJ"})
content = content_element.text if content_element else 'None'
date = review.find("p", attrs={"class":"typography_body-m__xgxZ_ typography_appearance-default__AAY17"}).text
csv_writer.writerow([reviewer, rating, content, date])
By doing it this way, we ensure that we’re not just limited to the reviews on the first page, thereby enriching our analysis with different insights from a larger pool of customer reviews.




