

ScraperAPI helps you scrape websites without getting blocked. It takes care of proxies, CAPTCHAs, and headless browsers so you can focus on getting data. In this guide, we’ll show you how to use ScraperAPI with chromedp, a Go library for controlling Chrome.
You’ll learn how to load JavaScript-heavy pages, render content, and store your API key securely using environment variables.
Getting Started: chromedp without Scraper API
Before integrating ScraperAPI, here’s a simple chromedp script that fetches the HTML of a webpage:
package main
import (
"context"
"fmt"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
var res string
err := chromedp.Run(ctx,
chromedp.Navigate("https://example.com"),
chromedp.OuterHTML("html", &res),
)
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(res)
}
This works for simple sites. But it fails when sites use CAPTCHAs, blocks, or anti-bot protection. That’s where ScraperAPI helps.
Integration Methods
Recommended: API Endpoint Method
This is the best way to use ScraperAPI with chromedp. You send a regular GET request to the ScraperAPI endpoint Instead of using it as a proxy. ScraperAPI renders the page and returns clean HTML, which you can load into chromedp if needed.
Why This Works Best
- Avoids proxy issues and browser flags
- Easy to set up and debug
- Works well with most websites
Requirements
To run this guide, you’ll need the following:
- Go 1.20 or higher installed
chromedpgodotenv
Install the Dependencies
In your project folder, initialize a Go module:
go mod init your-project
Then run these commands to install the dependencies:
go get -u github.com/chromedp/chromedp
go get -u github.com/joho/godotenv
Set Up Your .env FileCreate an .env file in the root of your project:
SCRAPERAPI_KEY=your_api_key_here
Your Script
In a file scraperapi-chromedp.go, paste:
package main
import (
"context"
"fmt"
"io"
"net/http"
"os"
"time"
"github.com/chromedp/chromedp"
"github.com/joho/godotenv"
)
func main() {
err := godotenv.Load()
if err != nil {
fmt.Println("Error loading .env file")
return
}
apiKey := os.Getenv("SCRAPERAPI_KEY")
if apiKey == "" {
fmt.Println("Missing SCRAPERAPI_KEY")
return
}
// Use API instead of proxy
targetURL := "https://httpbin.org/ip"
scraperURL := fmt.Sprintf("http://api.scraperapi.com?api_key=%s&url=%s&render=true", apiKey, targetURL)
// Step 1: Fetch pre-rendered HTML from ScraperAPI
resp, err := http.Get(scraperURL)
if err != nil {
fmt.Println("HTTP request failed:", err)
return
}
defer resp.Body.Close()
bodyBytes, err := io.ReadAll(resp.Body)
if err != nil {
fmt.Println("Failed to read response:", err)
return
}
// Step 2: Load the HTML into a data URL for chromedp to parse
htmlContent := string(bodyBytes)
dataURL := "data:text/html;charset=utf-8," + htmlContent
// Step 3: Use chromedp to parse/extract from the static HTML
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
ctx, cancel = context.WithTimeout(ctx, 20*time.Second)
defer cancel()
var parsed string
err = chromedp.Run(ctx,
chromedp.Navigate(dataURL),
chromedp.Text("body", &parsed),
)
if err != nil {
fmt.Println("Scraping failed:", err)
return
}
fmt.Println("Parsed response:\n", parsed)
}
This code above uses ScraperAPI to fetch and render a webpage, then uses chromedp to parse the HTML content in Go.
Not Recommended: Using ScraperAPI as a Proxy in chromedp
You can try to use ScraperAPI as a proxy in chromedp, but it’s not reliable. We tested this method and ran into issues like:
net::ERR_INVALID_ARGUMENTnet::ERR_NO_SUPPORTED_PROXIES
Why You Should Avoid It
- Proxy settings in Chrome are tricky to configure in Go
- TLS and authentication often fail silently
- Debugging is harder and less consistent
This method may work for some users, but we don’t recommend it unless you know how to handle Chrome proxy flags in headless mode.
Advanced Usage
Session ManagementYou can opt to keep the same session across pages by updating your scraperURL like so:
scraperURL := fmt.Sprintf("http://api.scraperapi.com?api_key=%s&session_number=1234&url=%s", apiKey, targetURL)
Country Targeting
To use IPs from a specific country:
scraperURL := fmt.Sprintf("http://api.scraperapi.com?api_key=%s&url=%s&country_code=us", apiKey, targetURL)
Best Practices
Store API Key Securely
Use a .env file and godotenv to load your key instead of hardcoding it.
Use Timeouts
Avoid long waits by setting a timeout:
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel()
Retry Logic
Simple retry pattern:
for i := 0; i < 3; i++ {
err := chromedp.Run(...)
if err == nil {
break
}
time.Sleep(2 * time.Second)
}
Run the Code
Save your code as scraperapi-chromedp.go, then run:
go run scraperapi-chromedp.go
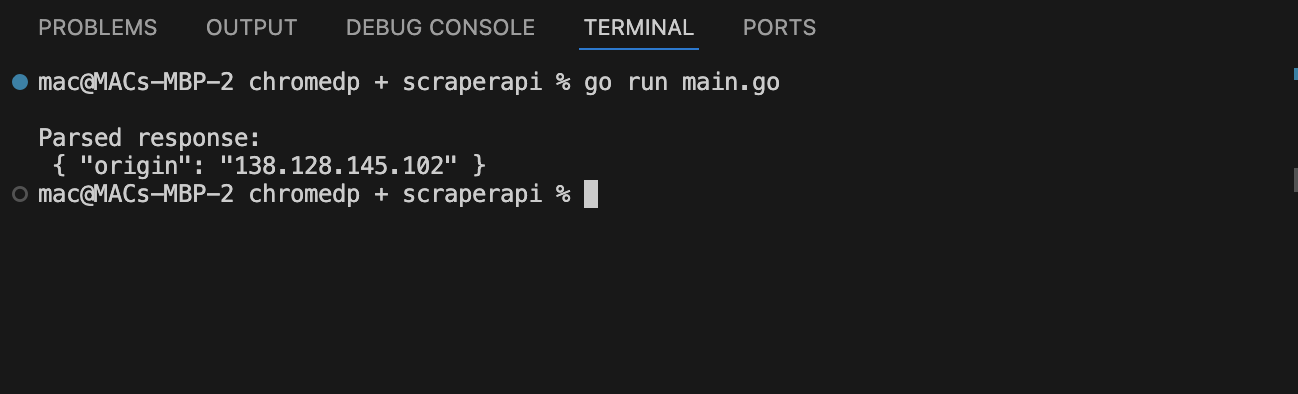
If you test it with https://httpbin.org/ip, the IP should reflect ScraperAPI’s proxy server, the one that ScraperAPI assigned.
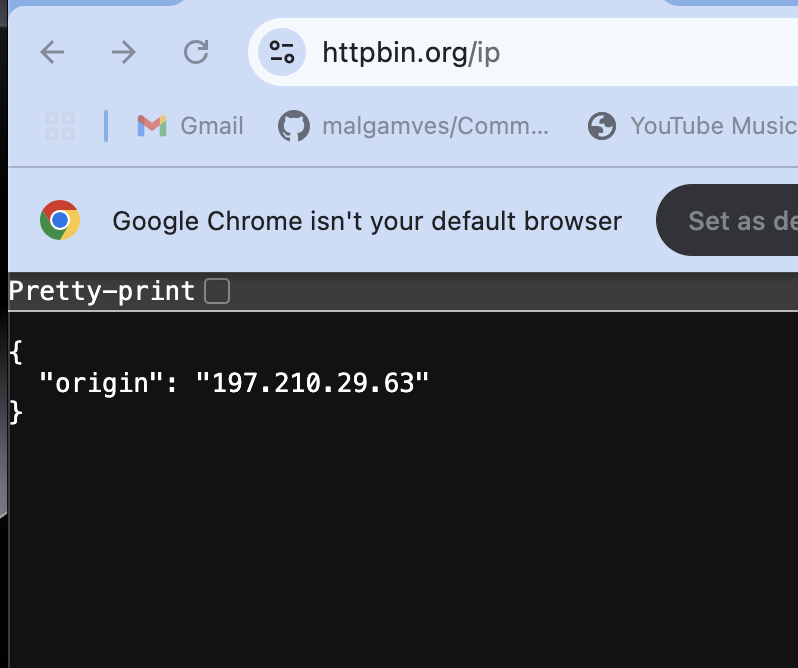
This confirms that ScraperAPI is handling the request.
For more, visit ScraperAPI Documentation

