

ScraperAPI is a powerful scraping tool that handles proxies, browsers, and CAPTCHAs automatically. In this guide, you’ll learn how to integrate ScraperAPI with HtmlUnit, a fast and lightweight headless browser for Java.
Getting Started
Before we integrate ScraperAPI, here’s a basic HtmlUnit scraping example:
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class BasicHtmlUnit {
public static void main(String[] args) throws Exception {
WebClient client = new WebClient(BrowserVersion.CHROME);
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
HtmlPage page = client.getPage("https://httpbin.org/ip");
System.out.println(page.asNormalizedText());
client.close();
}
}
This works for basic scraping but does not solve problems like IP bans or captchas.
Integration Methods
Recommended: API Endpoint Method
The best way to use ScraperAPI with HtmlUnit is to call the API endpoint directly and pass the target URL as a query parameter. This ensures your request routes through ScraperAPI’s proxy network with built-in CAPTCHA handling.
Required Setup
1. Install Java (if not already installed)
# Ubuntu
sudo apt-get update
sudo apt-get install default-jdk
# MacOS
brew install openjdk@2
Then add to your shell config (e.g. .zshrc or .bash_profile):
export JAVA_HOME="/Library/Java/JavaVirtualMachines/temurin-21.jdk/Contents/Home"
export PATH="$JAVA_HOME/bin:$PATH"
echo 'export JAVA_HOME="/Library/Java/JavaVirtualMachines/temurin-21.jdk/Contents/Home"' >> ~/.bash_profile
echo 'export PATH="$JAVA_HOME/bin:$PATH"' >> ~/.bash_profile
Reload your shell:
source ~/.zshrc
# or
source ~/.bash_profile
Confirm Java is installed:
java -version
2. Install Maven
# Ubuntu
sudo apt update
sudo apt install maven
# MacOS
brew install maven
Check:
mvn -v
3. Set Up Project Structure
Create a folder and initialize the Maven project:
mkdir htmlunit-scraperapi && cd htmlunit-scraperapi
Inside, create the structure:
src/
main/
java/
MarketPrice.java
4. Add Dependencies in pom.xml
At the root of your project folder, create a file pom.xml and paste the following:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.scraperapi</groupId>
<artifactId>htmlunit-scraperapi</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- HtmlUnit for headless browser -->
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.70.0</version>
</dependency>
<!-- Java dotenv to read .env variables -->
<dependency>
<groupId>io.github.cdimascio</groupId>
<artifactId>java-dotenv</artifactId>
<version>5.2.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Plugin to run Java classes with main method -->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<mainClass>MarketPrice</mainClass>
</configuration>
</plugin>
</plugins>
</build>
</project>
5. Add .env File in Root
In the same folder, create a .env file:
SCRAPERAPI_KEY=your_api_key_here
You can get your ScraperAPI key here.
Full Working Code
Paste this inside MarketPrice.java:
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import io.github.cdimascio.dotenv.Dotenv;
import java.io.IOException;
public class MarketPrice {
public static void main(String[] args) throws IOException {
// Load ScraperAPI key from .env
Dotenv dotenv = Dotenv.load();
String apiKey = dotenv.get("SCRAPERAPI_KEY");
if (apiKey == null || apiKey.isEmpty()) {
System.err.println("SCRAPERAPI_KEY is missing in your .env file.");
return;
}
// Target a real HTML site
String targetUrl = "https://quotes.toscrape.com";
String scraperApiUrl = String.format("http://api.scraperapi.com?api_key=%s&url=%s",
apiKey, targetUrl);
// Initialize headless browser
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
// Fetch and parse page
HtmlPage page = (HtmlPage) webClient.getPage(scraperApiUrl);
DomNodeList<DomNode> quoteBlocks = page.querySelectorAll(".quote");
System.out.println("\n📌 Scraped Quotes from https://quotes.toscrape.com:\n");
for (DomNode quote : quoteBlocks) {
String text = quote.querySelector(".text").asNormalizedText();
String author = quote.querySelector(".author").asNormalizedText();
DomNodeList<DomNode> tags = quote.querySelectorAll(".tags .tag");
System.out.println("📝 Quote: " + text);
System.out.println("👤 Author: " + author);
System.out.print("🏷️ Tags: ");
for (DomNode tag : tags) {
System.out.print(tag.asNormalizedText() + " ");
}
System.out.println("\n------------------------------------------\n");
}
webClient.close();
}
}
Make sure to set your API key in the environment variable SCRAPERAPI_KEY.
Not Recommended: Proxy Mode
HtmlUnit allows proxy configuration, but ScraperAPI uses query string authentication, which doesn’t work with HtmlUnit’s proxy model.
Why It Fails
- ScraperAPI needs the API key in the URL query.
- HtmlUnit proxy setup expects a static IP or basic authentication.
Error Output:
Use the API Endpoint method instead.
Optional Parameters
ScraperAPI supports various options via query parameters:
{
Render = true, // Load JavaScript
CountryCode = "us", // Use US IP
Premium = true, // Enable CAPTCHA solving
SessionNumber = 123 // Maintain session across requests
};
| Parameter | What It Does | When to Use It |
render=true |
Tells ScraperAPI to execute JavaScript | Use for SPAs and dynamic content |
country_code=us |
Routes requests through US proxies | Great for geo-blocked content |
premium=true |
Enables CAPTCHA solving and advanced anti-bot measures | Essential for heavily protected sites |
session_number=123 |
Maintains the same proxy IP across requests | Use when you need to maintain login sessions |
These parameters cover most scraping scenarios. Check the ScraperAPI documentation for additional options.
Example:
String scraperApiUrl = String.format("http://api.scraperapi.com?api_key=%s&url=%s&render=true&country_code=us", apiKey, java.net.URLEncoder.encode(targetUrl, "UTF-8"));
Best Practices
- Always store your ScraperAPI key in an environment variable
- Use
render=truewhen targeting JavaScript-heavy sites - Avoid using proxy settings in HtmlUnit
- Implement retry logic when scraping large datasets
- Disable JavaScript/CSS for better performance on static pages
Run the Scraper
Run your MarketPrice.java file using:
mvn compile exec:java -Dexec.mainClass=MarketPrice
Expected Output:
Your terminal should display structured quote data like this:
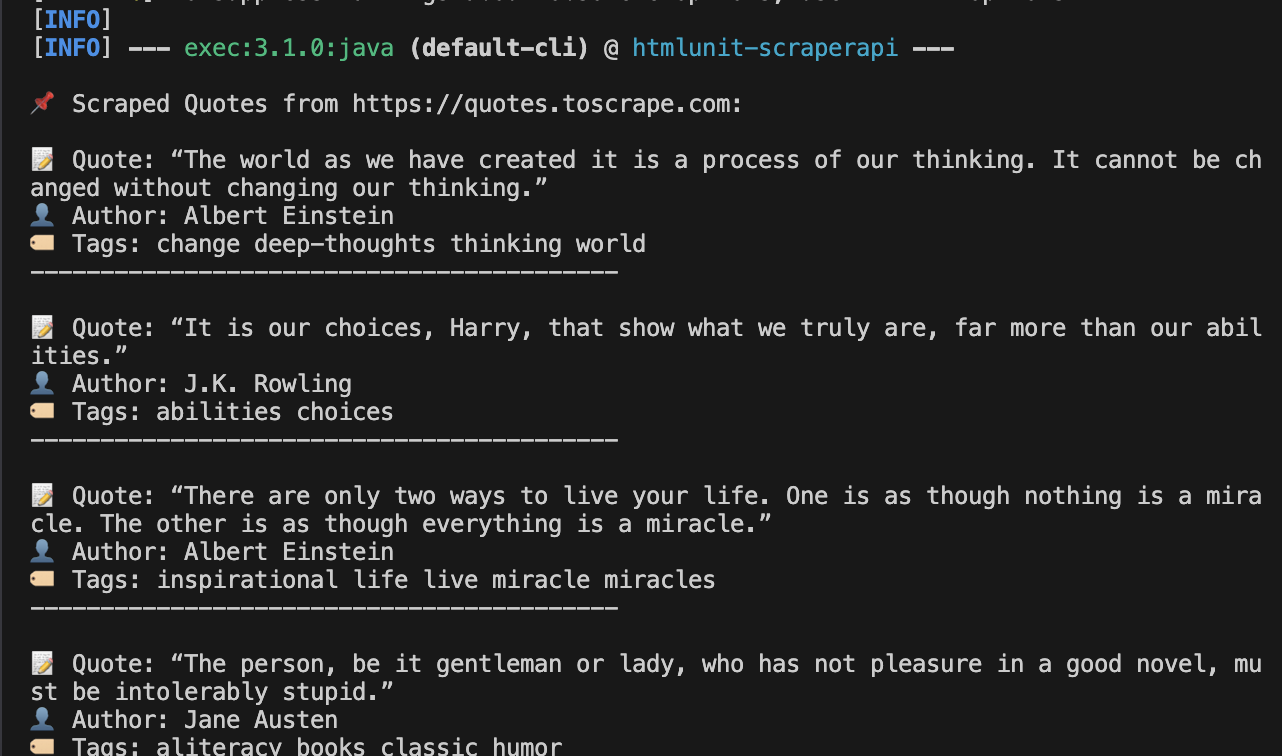
This confirms ScraperAPI handled the request and routed it through its network.

