



Amazon, the world’s largest e-commerce giant with nearly $514 billion in worldwide net sales revenue in 2022, is a goldmine of valuable data for your business. Imagine gaining insights into Amazon product data, including competitive pricing strategies, detailed product descriptions, and insightful customer reviews.
This tutorial teaches you to scrape Amazon products using Python. We’ll guide you through the web scraping process with the help of BeautifulSoup and requests, providing all the necessary web scraping code to build your own Amazon product data scraper.
Towards the end, you will also learn about ScraperAPI’s Structured Data endpoint, which turns this:
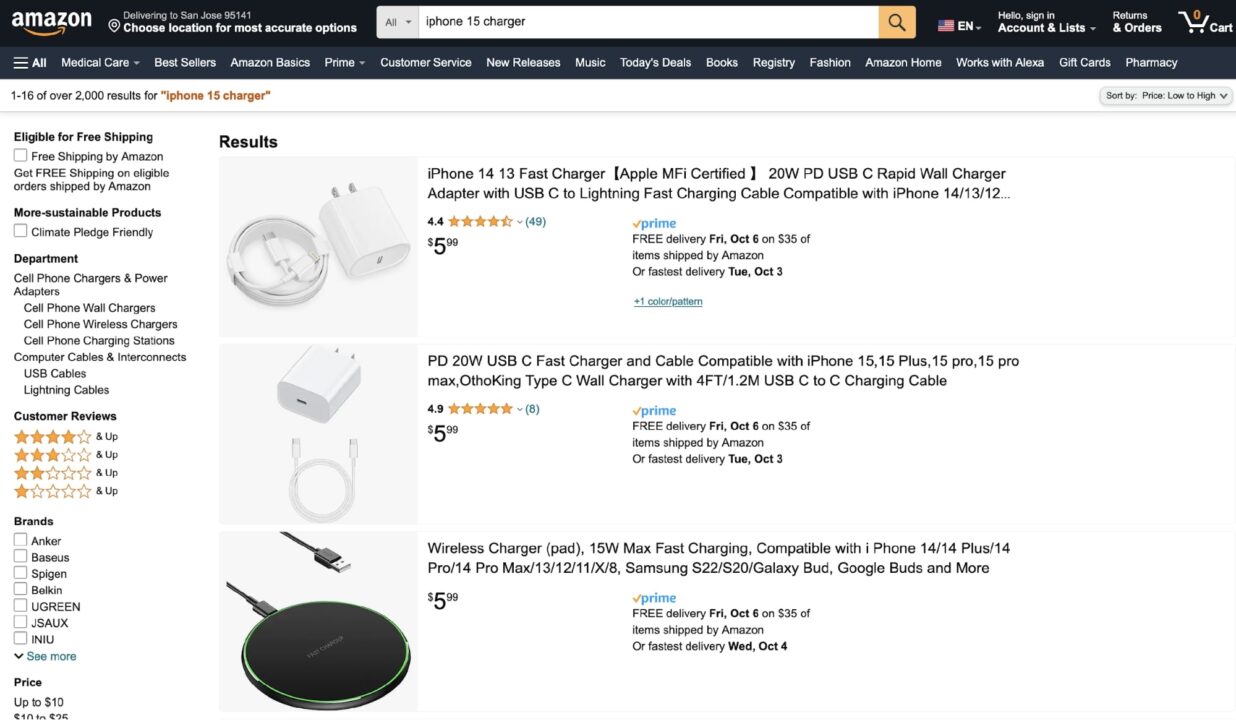
Into this with a simple Amazon API call:
</p>
<pre> {
"results":[
{
"type":"search_product",
"position":1,
"asin":"B0CD6YLMBK",
"name":"iPhone 15 Charger, [Apple Certified] 20W USB C Wall Charger Block with 6.6FT USB C to C Fast Charging Cord for 15 Pro/15 Pro Max/15 Plus, iPad Pro 12.9/11, iPad 10th Generation, iPad Air 5/4, iPad Min",
"image":"https://m.media-amazon.com/images/I/51Mp6Zpg7qL.jpg",
"has_prime":true,
"is_best_seller":false,
"is_amazon_choice":false,
"is_limited_deal":false,
"stars":4.3,
"total_reviews":34,
"url":"https://www.amazon.com/iPhone-Charger-Certified-Charging-Generation/dp/B0CD6YLMBK/ref=sr_1_1?keywords=iphone+15+charger&qid=1697051475&sr=8-1",
"availability_quantity":null,
"spec":{
},
"price_string":"$16.99",
"price_symbol":"$",
"price":16.99
},
# ... truncated ...
]
</pre>
<p>So, without wasting any more time, let’s begin!
Amazon Product Data Scraper – Project Requirements
This tutorial is based on Python 3.10, but it should work with any Python version from 3.8 onwards. Make sure you have a supported version installed before continuing.
Additionally, you also need to install Requests and BeautifulSoup.
- The Requests library will let you download Amazon’s search result page
- BeautifulSoup will let you traverse through the DOM and extract the required data.
You can install both of these libraries using PIP:
$ pip install requests bs4
Note: You can also scrape Amazon using Scrapy, which allows you to build and manage several spiders from a single codebase.
Now create a new directory and a Python file to store all of the code for this tutorial:
$ mkdir amazon_scraper
$ touch amazon_scraper/app.py
With the requirements sorted, you are ready to head on to the next step!
Deciding What Amazon Data to Scrape
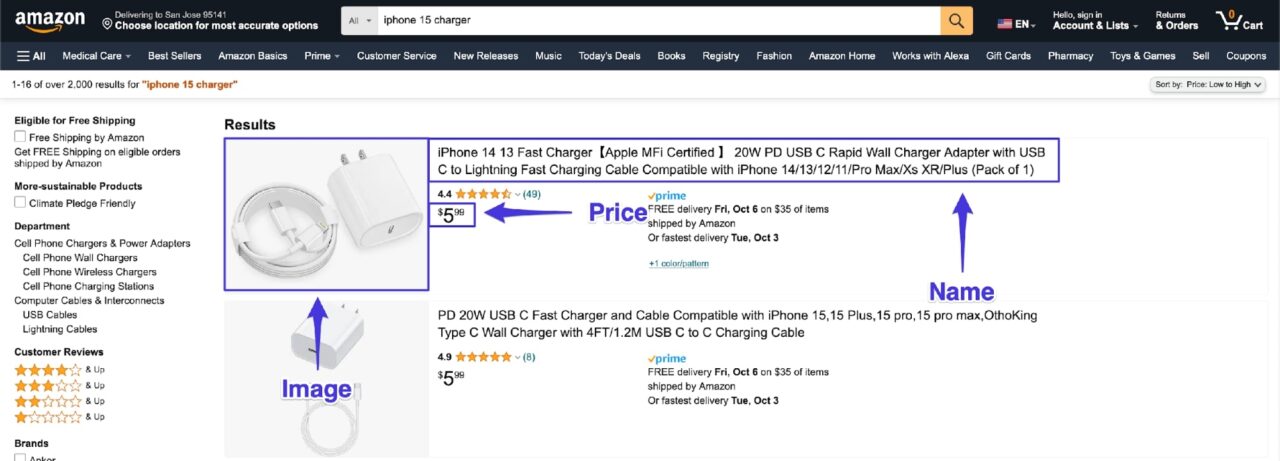
With every web scraping project, it is very important to decide early on what you want to scrape. This helps in planning the plan of action. For this particular tutorial, you will be learning how to scrape the following attributes of each Amazon product result:
- Name
- Price
- Image
The screenshot below has annotations for where this information is located on an Amazon search results:
We’ll take a look at how to extract each of these attributes in the next section. And just to make things a bit spicy, we will sort the data in ascending order according to the price before scraping it.
Fetching Amazon Search Result Page
Let’s start by fetching the Amazon search result page.
This is a typical search page URL: https://www.amazon.com/s?k=iphone+15+charger.
However, if you want to sort the results according to the price, you must use this URL: https://www.amazon.com/s?k=iphone+15+charger&s=price-asc-rank.
You can use the following Requests code to download the HTML:
import requests
url = "https://www.amazon.com/s?k=iphone+15+charger&s=price-asc-rank"
html = requests.get(url)
print(html.text)
However, as soon as you run this code, you will realize that Amazon has put some basic anti-bot measures in place. You will receive the following response from Amazon:
“To discuss automated access to Amazon data please contact api-services-support@amazon.com. —trucated—“
You can bypass this initial anti-bot measure by sending a proper user-agent header as part of the request:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'
}
html = requests.get(url, headers=headers)
If you inspect the html variable, you will see that this time you received the complete search result page as desired.
While we are at it, let’s load the response in a BeautifulSoup object as well:
</p>
from bs4 import BeautifulSoup
soup = BeautifulSoup(html.text)
<p>Sweet! Now that you have the complete response in a BeautifulSoup object, you can start extracting relevant data from it.
Scraping Amazon Product Attributes
The easiest way to figure out how to scrape the required data is by using the Developer Tools, which are available in almost all famous browsers.
The Developer Tools will let you explore the DOM structure of the page.
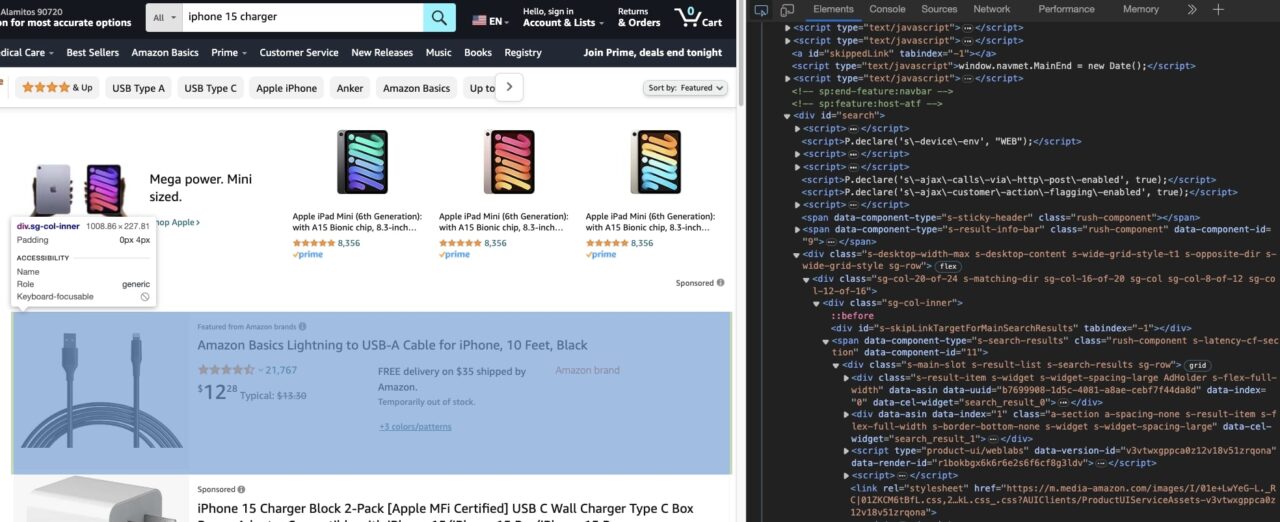
The main goal is to figure out which HTML tag attributes can let you uniquely target an HTML tag.
Most of the time, you will rely on the id and class attributes. Then you can supply these attributes to BeautifulSoup and ask it to return whatever text/attribute you want to scrape from that particular tag.
Web Scraping Amazon Product Name
Let’s take a look at how you can extract the product name. This will give you a good understanding of the general process.
Right-click on the product name and click on Inspect:
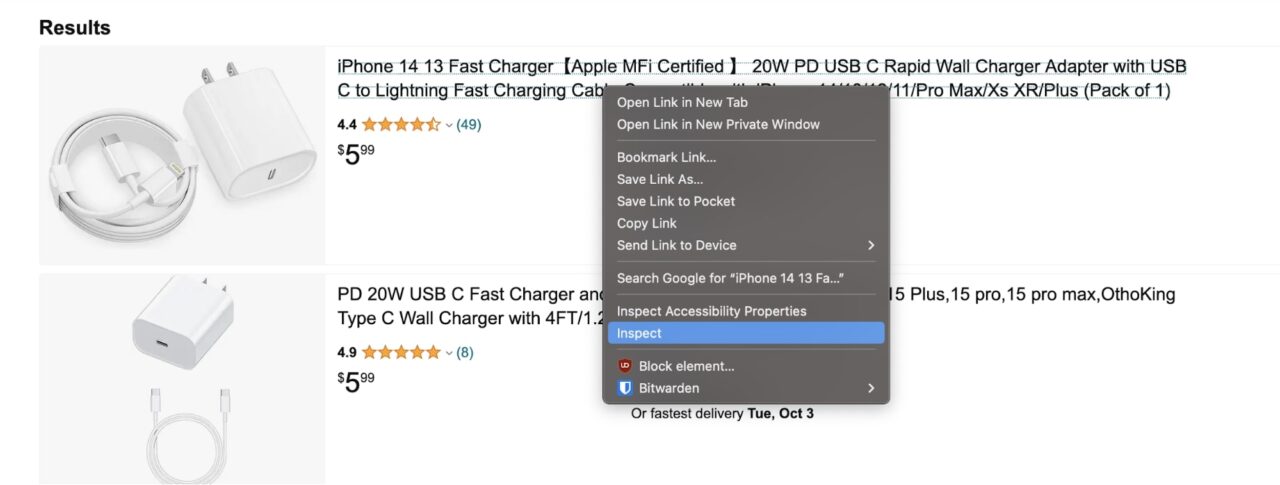
This will open up the developer tools:
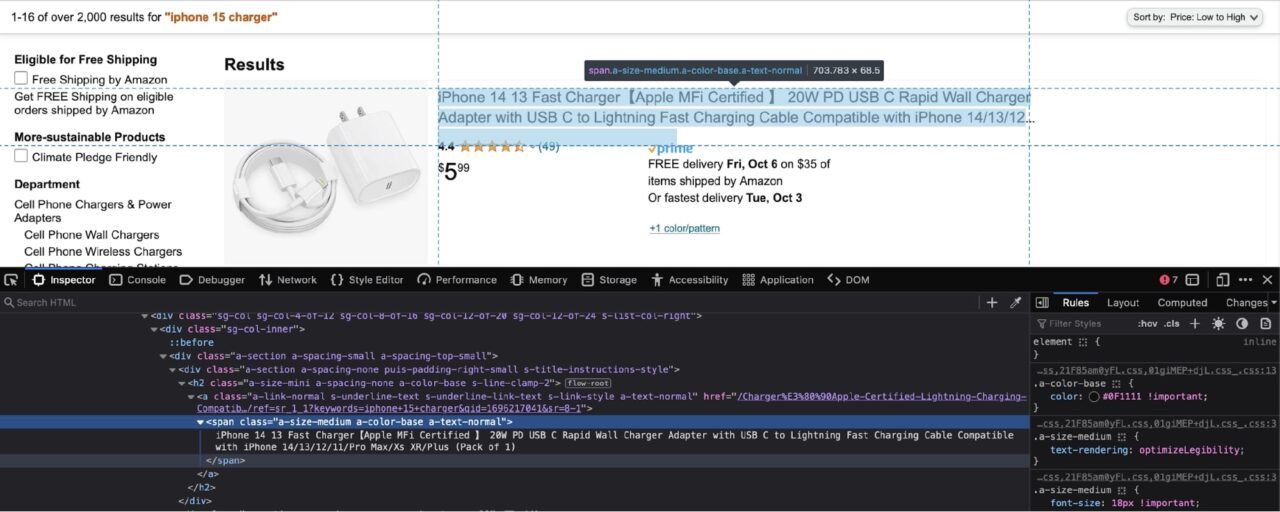
As you can observe in the screenshot above, the product name is nested in a span with the following classes: a-size-medium a-color-base a-text-normal.
At this point, you have a decision to make: you can either ask BeautifulSoup to extract all the spans with these classes from the page, or you can extract each result div and then loop over those divs and extract data for each product.
I generally prefer the latter method as it helps identify products that might not have all the required data. This tutorial will also showcase this same method.
Therefore, now you need to identify the div that wraps each result item:
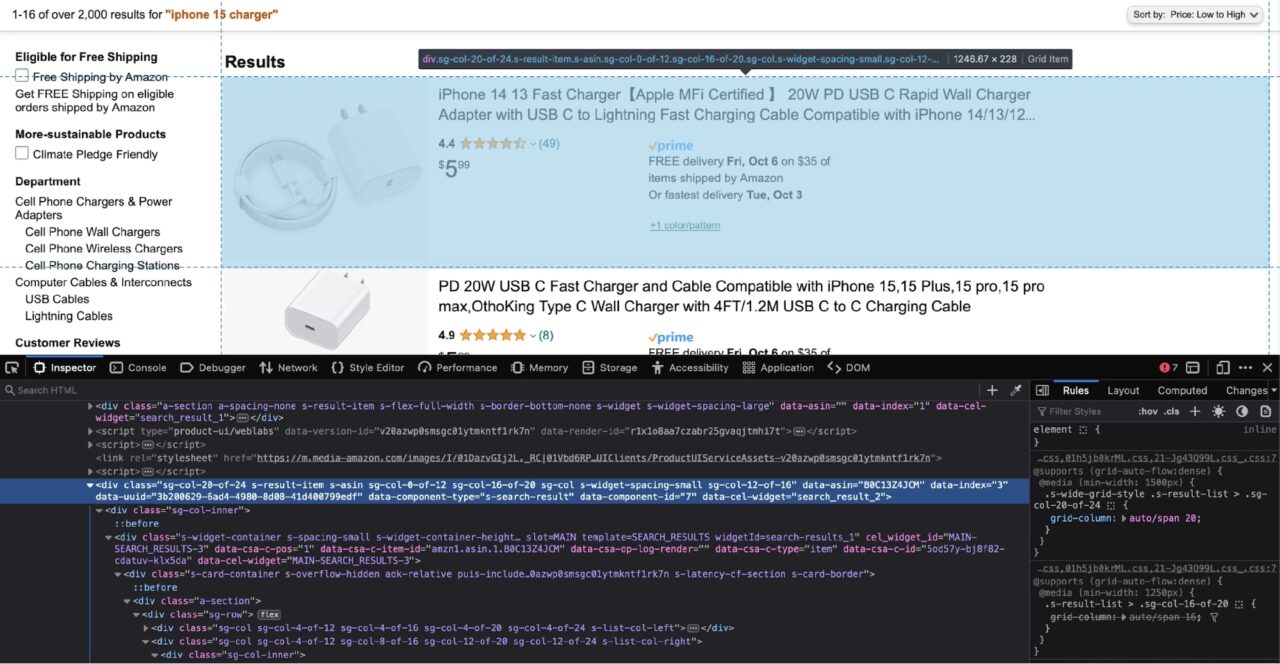
According to the screenshot above, each result is nested in a div tag with the data-component-type attribute of s-search-result.
Let’s use this information to extract all the result divs and then loop over them and extract the nested product titles:
</p>
results = soup.find_all('div', attrs={'data-component-type': 's-search-result'})
for r in results:
print(r.select_one('.a-size-medium.a-color-base.a-text-normal').text)
<p>Here’s a simple breakdown of what this code is doing:
- It uses the
find_all()method provided by BeautifulSoup - It returns all the matching elements from the HTML
- It then uses the
select_one()method to extract the first element that matches the CSS Selector passed in
Notice that here we append a dot (.) before each class name. This tells BeautifulSoup that the passed-in CSS Selector is a class name. There is also no space between the class names. This is important as it informs BeautifulSoup that each class is from the same HTML tag.
If you are new to CSS selectors, you should read our CSS selectors cheat sheet, we go over the basics of CSS selectors and provide you with an easy-to-use framework to speed up the process.
Web Scraping Amazon Product Price
Now that you have extracted the product name, extracting the product price is fairly straightforward.
Follow the same steps from the last section and use the Developer Tools to inspect the price:
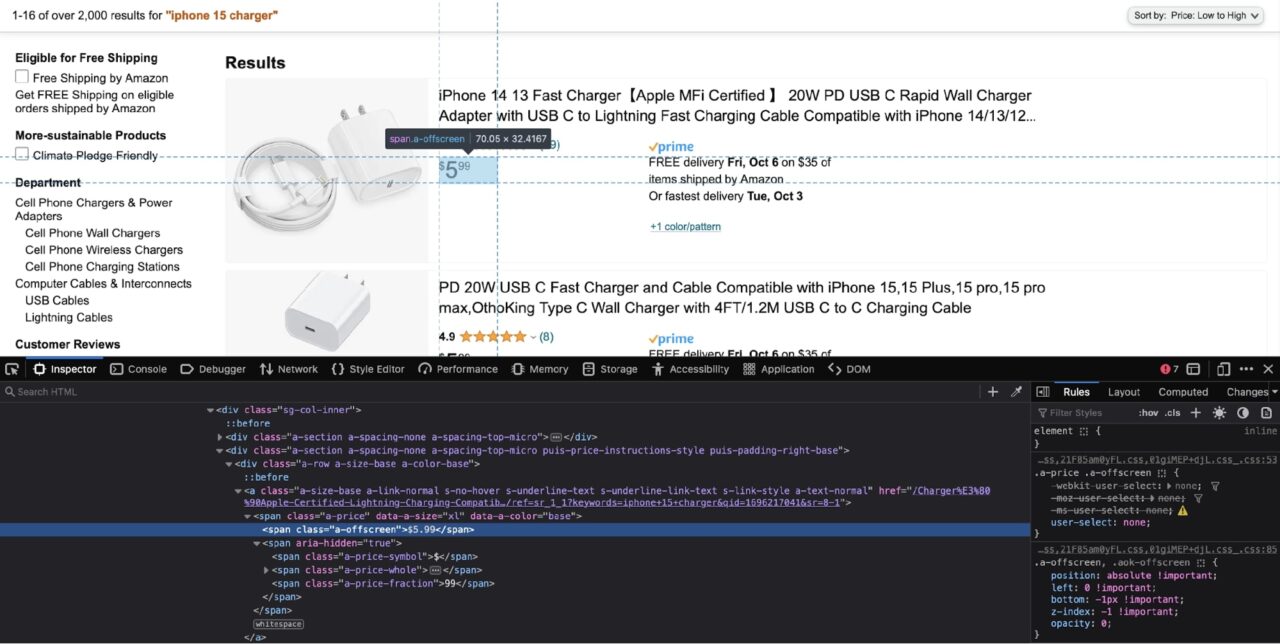
The price can be extracted from the span with the class of a-offscreen. This span is itself nested in another span with a class of a-price. You can use this knowledge to craft a CSS selector:
</p>
for r in results:
# -- truc --
print(r.select_one('.a-price .a-offscreen').text)
<p>As you want to target nested spans this time, you have to add a space between the class names.
Web Scraping Amazon Product Image
Try following the steps from the previous two sections to come up with the relevant code on your own. Here is a screenshot of the image being inspected in the Developer Tools window:
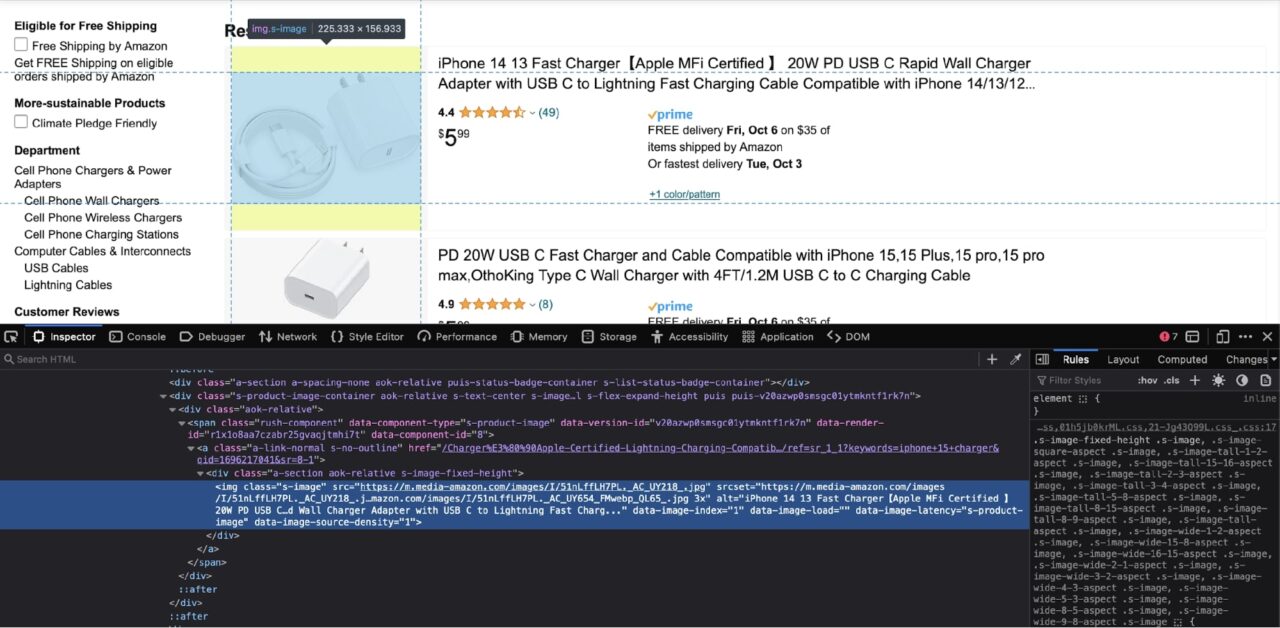
The img tag has a class of s-image. You can target this img tag and extract the src attribute (the image URL) using this code:
</p>
for r in results:
# -- truc --
print(r.select_one('.s-image').attrs['src'])
<p>Note: Extra points if you do it on your own!
The Complete Amazon Web Scraping Code
You have all the bits and pieces to put together the complete web scraping code.
Here is a slightly modified version of the Amazon scraper that appends all the product results into a list at the very end:
</p>
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/s?k=iphone+15+charger&s=price-asc-rank"
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text)
results = soup.find_all('div', attrs={'data-component-type': 's-search-result'})
result_list = []
for r in results:
result_dict = {
"title": r.select_one('.a-size-medium.a-color-base.a-text-normal').text,
"price": r.select_one('.a-price .a-offscreen').text,
"image": r.select_one('.s-image').attrs['src']
}
result_list.append(result_dict)
<p>You can easily repurpose this result_list to power different APIs or store this information in a spreadsheet for further analysis.
Using Structured Data Endpoint – Amazon API
This tutorial did not focus too much on the gotchas of scraping Amazon product data at scale.
Amazon is notorious for banning scrapers and making it difficult to scrape data from their websites.
You already saw a glimpse of this during the very beginning of the tutorial, where a request without the proper headers was blocked by Amazon.
Luckily, there is an easy solution to this problem. Instead of sending a request directly to Amazon, you can send the request to ScraperAPI’s Structured Data endpoint, and ScraperAPI will respond with the scraped data in nicely formatted JSON.

This is a very powerful feature offered by ScraperAPI, as by using this, you do not have to be worried about getting blocked by Amazon or keeping your scraper updated with the never-ending changes in Amazon’s anti-bot techniques.
The best part is that ScraperAPI provides 5,000 free API credits for 7 days on a trial basis and then provides a generous free plan with recurring 1,000 API credits to keep you going. This is enough to scrape data for general use.
You can quickly get started by going to the ScraperAPI dashboard page and signing up for a new account:
After signing up, you will see your API Key:
Now you can use the following code to access the search results from Amazon using the Structured Data – Amazon API endpoint:
</p>
import requests
payload = {
'api_key': 'API_KEY,
'query': 'iphone 15 charger',
's': 'price-asc-rank'
}
response = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
print(response.json())
<p>Note: Don’t forget to replace API_KEY in the code above with your own ScraperAPI API key.
As you might have already observed, you can pass in most query params that Amazon accepts as part of the payload. This means all the following sorting values are valid for the s key in the payload:
- Price: High to low =
price-desc-rank - Price: Low to high =
price-asc-rank - Featured =
rerelevanceblender - Avg. customer review =
review-rank - Newest arrivals =
date-desc-rank
If you want the same result_list data as from the last section, you can add the following code at the end:
</p>
result_list = []
for r in response.json()['results']:
result_dict = {
"title": r['name']
"price": r['price_string'],
"image": r['image']
}
result_list.append(result_dict)
<p>You can learn more about this endpoint over at the ScraperAPI docs.
Scrape Amazon Products with ScraperAPI’s Amazon API
This tutorial was a quick rundown of how to scrape data from Amazon with Phython and Beautiful Soup.
- It taught you a simple bypass method for the bot detection system used by Amazon.
- It showed you how to use the various methods provided by BeautifulSoup to extract the required data from the HTML document.
- Lastly, you learned about the Structured Data endpoint offered by ScraperAPI and how it solves quite a few problems.
If you are ready to take your data collection from a couple of pages to thousands or even millions of pages, our Business Plan is a great place to start.
Need 10M+ API credits? Contact sales for a custom plan, including all premium features, premium support, and an account manager.
Until next time, happy scraping!





