



Highly Targeted Websites
The first website type that is commonly tough to scrape is highly targeted websites. They can be understood in two ways:
- Websites that have a lot of traffic
- Websites that are common targets for bots
In both cases, highly targeted websites present a vast amount of valuable information and usually have complex anti-scraping mechanisms that can easily detect bots and block them almost immediately.
For example, these websites can use CAPTCHA tests to block your scraper from getting to the page or detect patterns on your requests (or your scraper behavior) to detect your bot.
To scrape this type of pages, it’s best to use a web scraping tool like ScraperAPI to automate the necessary infrastructure required to bypass all anti-scraping measures and get access to the target data.
A good example of this is Yahoo Finance. It has a lot of valuable data for investors and financial institutions, so it’s a very common target.
Let’s see what happens when we try to send a request to https://finance.yahoo.com/currencies to get forex data:
import requests
response = requests.get('https://finance.yahoo.com/currencies')
print(response.status_code)
The response from the server is a big 404 status code. And even if it works the first time, your IP will get blocked after a couple of attempts.
That said, we can easily bypass these anti-scraping mechanisms with ScraperAPI.
First, create a free ScraperAPI account to get access to a unique API key and 5,000 free API credits. Then, we’ll send our request through ScraperAPI instead of directly from our machine.
import requests
payload = {
'api_key': 'YOUR_API_KEY',
'url': 'https://finance.yahoo.com/currencies',
}
response = requests.get('https://api.scraperapi.com', params=payload)
print(response.status_code)
Note: If you want to try this code snippet, make sure to pip install requests and add your API key to the api_key parameter within the payload.
This time, running the code will return a 200 status code. But why?
To summarize what’s happening in the backend, ScraperAPI is using years of statistical analysis and machine learning to decide which combination of IP address and headers to use when sending the requests, as well as handling any CAPTCHA or any other anti-scraping mechanism in the way.
At scale, it will also smartly rotate IP addresses when necessary from a pool of over 40M IPs across 50+ countries. This means you can send hundreds or thousands of requests consistently without getting blocked.
Related: Learn how to scrape Forex markets using Beautiful Soups.
Highly Complex and Changing Websites
The second website type that is typically hard to scrape is the highly complex and changing websites. Besides having very effective anti-scraping mechanisms, most in-demand websites have complex data structures that can definitely be hard to work with in the page’s raw HTML form.
Some pages can be using dynamic CSS classes and attributes or are continually changing the structure of their pages – or both.
A good example of this is search engines like Google. For every keyword you’re looking for, the search engine result page (SERP) can be hugely different from others, making it time-consuming and hard to collect SERP data consistently.
For this exact reason, ScraperAPI provides a series of structured data endpoints (SDEs) that allow turning unstructured web data from in-demand domains into simple-to-use JSON format.
In the case of Google, we can use any of the following endpoints from ScraperAPI:
Here’s an example of how to use the Google SERP endpoint:
import requests
payload = {
'api_key': 'YOUR_API_KEY',
'country': 'us',
'query': 'video+marketing'
}
response = requests.get(
'https://api.scraperapi.com/structured/google/search', params=payload)
print(response.text)
For convenience, here’s just the first part of the JSON response containing Google Ad data:
{
"search_information": {
"total_results": 2940000000,
"time_taken_displayed": 0.37
},
"ads": [
{
"position": 0,
"block_position": "top",
"title": "Everything You Need to Know About Video Marketing",
"link": "https://www.charterandcompany.com/everything-and-more-you-need-to-know-about-video-marketing",
"displayed_link": "https://www.charterandcompany.com",
"tracking_link": "https://www.google.com/aclk?sa=l&ai=DChcSEwj38ZHKt7j_AhUCYZEKHWG-C1YYABAAGgJjZQ&ae=2&sig=AOD64_03XoPiDzoqEGVMRBVYW3fNiPBGwg&q&adurl",
"description": "Follow Our Hot Tips To Make High-Quality Video Content For Your Video Marketing. Our Team Of Passionate Professionals With Years Of Experience Can Help You Get Started Now."
}
]
}
Check a full Google SERP response sample or learn how to use ScraperAPI structured data endpoints with our step-by-step tutorial.
Note: ScraperAPI provides SDEs for Amazon and Twitter; more are in development.
Dynamic Pages
Websites that host dynamic pages are also normally difficult to scrape. To understand why dynamic pages are a challenge, you first need to understand how web scrapers work.
When a scraper sends an HTTP request, the server responds by sending the raw HTML file of the URL requested.
However, dynamic pages inject content through JavaScript – e.g., infinite scrolling pages using lazy loading to inject new items to a page after the visitor scrolls to the bottom.
When your browser finds the JS links/scripts, it’ll download the necessary JS files and render the page. This doesn’t happen when a bot request the page because there’s no JavaScript rendering. Therefore, the raw HTML, most likely, won’t have the information you see on your screen.
There are two solutions:
- Using a headless browser through a library like Puppeteer or Selenium would download and execute JavaScript like a real user – the problem with this approach is that your proxies can get exposed, putting your project at risk; plus, it requires high-level coding skills and adds an extra layer of complexity.
- The better approach is to find the potential hidden API the site is using to inject the information into the page.
This second approach is how we built a LinkedIn scraper. The website loads new jobs into the page using an AJAX call – basically sending a request to a page where the information is located.
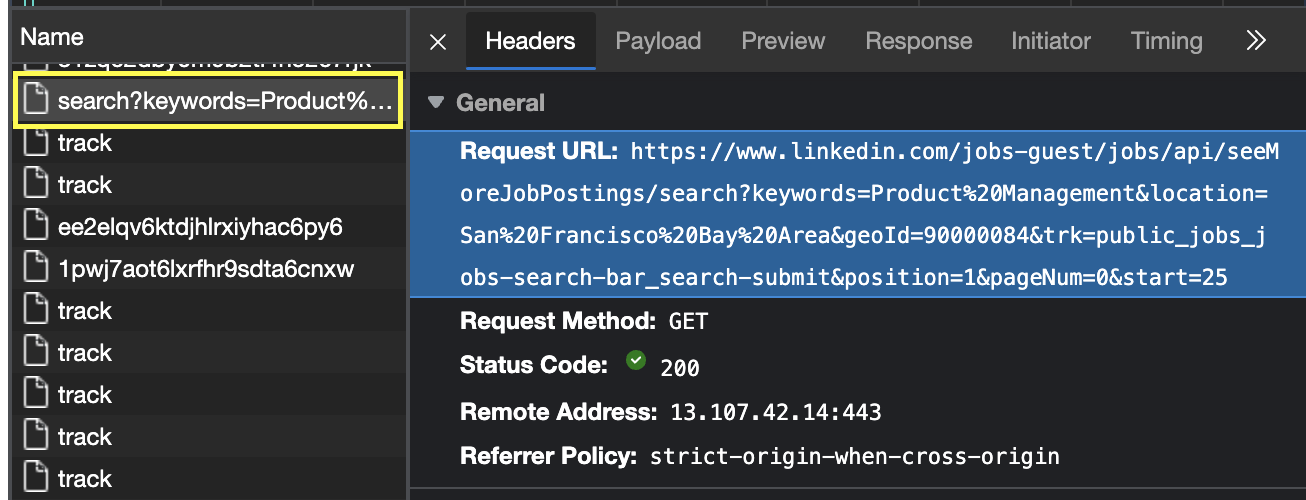
You can find the hidden API of a dynamic site by analyzing the network tab within your browser DevTools.
Of course, sending a request to these pages from your original IP address is very risky, so consider using ScraperAPI to hide it and get access to the data without getting blocked.
Check our blog for the step-by-step tutorial on how to scrape LinkedIn and similar sites.
Paginated Pages
It’s common for eCommerce sites or blog pages to use pagination to distribute content through several pages, preventing visitors from getting overwhelmed by a list of 100+ items.
Although that’s great for users, collecting data programmatically becomes a bit tougher.
Here are two potential solutions you can use to navigate the paginated series:
Option 1: Use a Crawler to Navigate the Pagination Through the Next Button
There are instances where predicting the next URL is just not necessary. Instead, we can build a crawler to find the next URL and extract the data from each page one by one.
For example, we can use the Scrapy library in Python to build custom spiders and reduce development time.
Most paginated pages use a similar structure:

If you can find a “next” button on the page, then you’ve won 80% of the battle.
In Scrapy, we can use the following logic to follow that link:
next_page = response.css('a.action.next').attrib['href']
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
If you’ve never used Scrapy before, here’s a complete guide on dealing with pagination in Scrapy.
Option 2: Navigate the Pagination by Manipulating the URL
In other instances, there isn’t a “next” button, or we just don’t want to use a crawler because of its complexity. So what can we do instead?
If you take a closer look at the URL inside the “next” button, you’ll notice there’s a number within it:
https://footdistrict.com/zapatillas/f/b/jordan/?p=2
And if we keep changing the number, we also move through the pagination:
https://footdistrict.com/zapatillas/f/b/jordan/?p=3
Taking advantage of this pattern, we can simply manipulate the URL through this parameter within a range() loop:
import requests
for page in range(1, 4):
response = requests.get(
f'http://api.scraperapi.com?api_key=YOUR_API_KEY&url=https://footdistrict.com/zapatillas/f/b/jordan/?p={page}'
)
print(response.status_code)
CODE
Using the range function, we can tell our scraper to substitute the variable “page” within the URL for a number starting from 1 and finishing at 4, but not including 4 – in other words, we’ll be sending a request to:
https://footdistrict.com/zapatillas/f/b/jordan/?p=1 https://footdistrict.com/zapatillas/f/b/jordan/?p=2 https://footdistrict.com/zapatillas/f/b/jordan/?p=3
The only thing left to do is to find out which is the last page in the pagination, allowing us to set a proper range.
In both of these options, we’ll be sending several requests to the same domain, increasing the risk of being detected, so keep that in mind.





