In today’s article, we’ll show you how to scrape hotel prices from one of the biggest aggregators: Google!
Why should you scrape Google hotel prices?
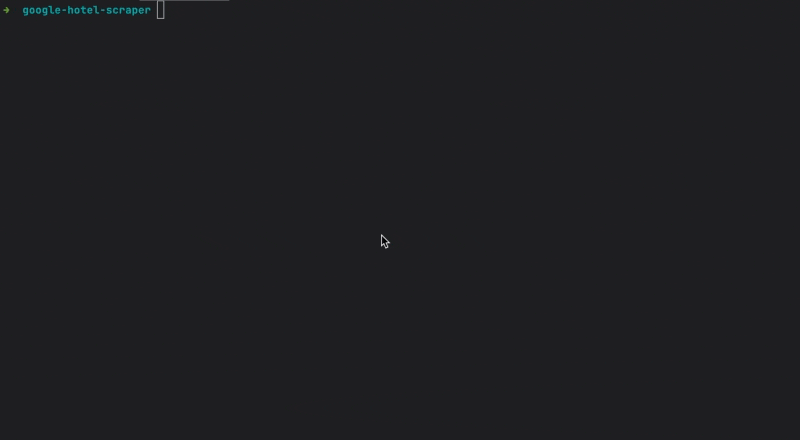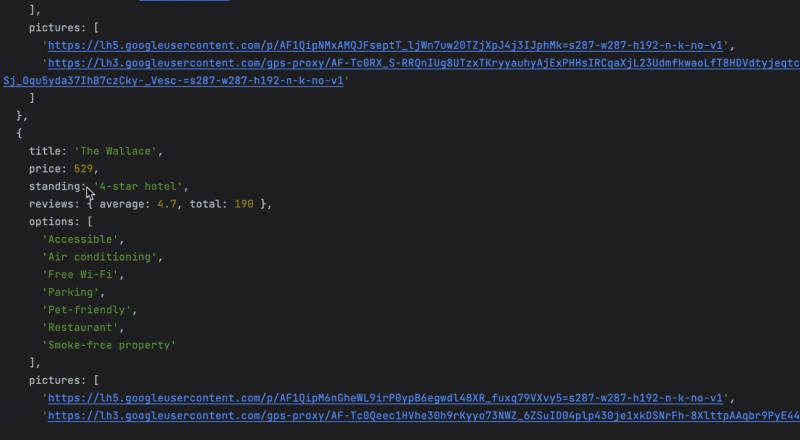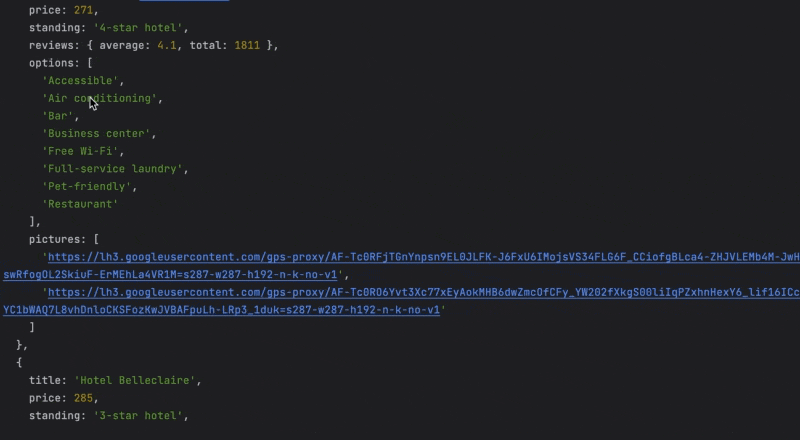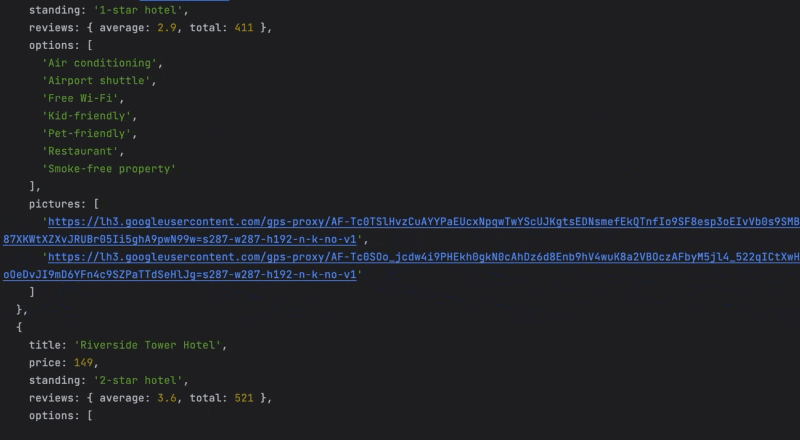
If you search hotel-related keywords, Google will generate its own hotel-focused section with names, images, addresses, ratings, and prices for thousands of hotels.
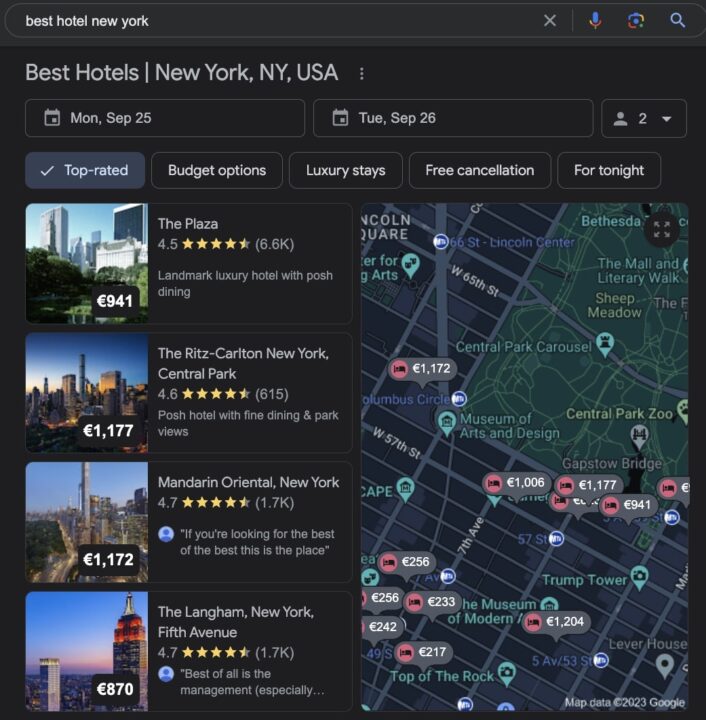
This is because Google has access to millions of travel and hotel websites and aggregates all this information into a single place.
Travelers, businesses, and analysts can use all of this data for many use cases:
- Price Comparison – compare prices across booking platforms and travel websites to find the best deals.
- Data Analysis – analysts can use hotel pricing data to uncover pricing trends, seasonal fluctuations, and competitive pricing opportunities.
- Dynamic Pricing Strategies – businesses can optimize revenue and occupancy rates by adjusting prices based on demand, availability, and competitor prices.
- Customized Alerts – monitor price drops to alert customers or for personal use.
- Travel Aggregation Services – provide users with a consolidated view of hotel prices and options from various sources.
- Budget and Planning – travelers can anticipate accommodation costs and adjust their plans accordingly.
In the end, there are many things you can do with data, but before you can get insights from it, you need to collect enough of it.
Let’s jump to the fun part and start collecting Google hotel prices!
Scraping Google Hotel Prices with Node.js
In this tutorial, we’ll write a script that finds the best hotel prices in New York by collecting hotel pricing data and then sorting the hotel list from the cheapest to the most expensive.
1. Prerequisites
You must have these tools installed on your computer to follow this tutorial.
- Node.js 18+ and NPM
- Basic knowledge of JavaScript and Node.js API.
Note: Although anyone can follow this tutorial, for those completely unfamiliar with web scraping, we advise starting by reading our JavaScript web scraping for beginners tutorial.
2. Set Up Your Project
Create a folder for the project.
mkdir google-hotel-scraper
Now, initialize a Node.js project by running the command below from the terminal:
cd google-hotel-scraper
npm init -y
The last command will create a package.json file in the folder. Create a file index.js and add a simple JavaScript instruction inside.
touch index.js
echo "console.log('Hello world!');" > index.js
Execute the file index.js using the Node.js runtime.
node index.js
This command will print Hello world! in the terminal. If it works, then your project is up and running.
3. Install the Necessary Dependencies
To build our scraper, we need these two Node.js packages:
- Puppeteer – to load Google Hotel pages and download the HTML content.
- Cheerio – to extract the hotel information from the HTML downloaded by Puppeteer.
Run the command below to install these packages:
npm install puppeteer cheerio
4. Identify the Information to Retrieve on the Google Hotel Page
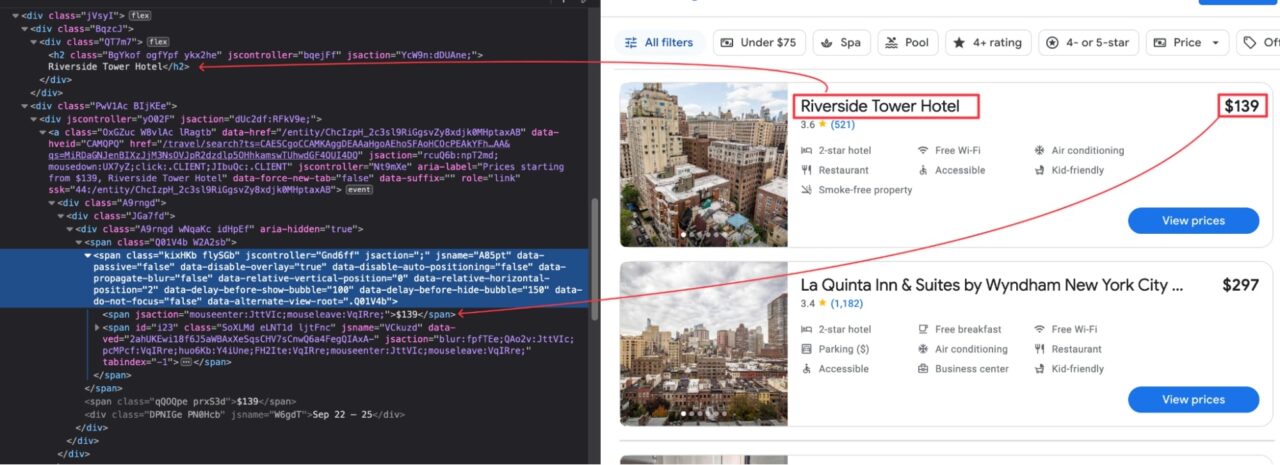
To extract a piece of information from a page, we first have to identify which DOM selector we can use to target its HTML tag.
Here’s what we mean: the picture below shows the location of the hotel’s name and price in the DOM.