

Idealista (Idealista.com) is a leading property listing website in Spain. It features millions of real estate information, providing details such as price, location, size, photos, and even virtual tours of the properties.
While web scraping offers the most efficient way for real estate agents and brokers to stay updated on these real estate data, extracting Idealista data presents a significant challenge. Its robust anti-bot measures prevent automated data collection.
In this real estate web scraping guide, we’ll show you how to build an Idealista web scraper using Python and ScraperAPI. This web scraping tool combination enables you to extract Idealista property listing details without getting blocked.
TL;DR of Full Idealista Real Estate Scraper Code
For those in a hurry, here is the complete code of Idealista.com web scraper:
import json
from datetime import datetime
import requests
from bs4 import BeautifulSoup
scraper_api_key = 'api_key'
idealista_query = "https://www.idealista.com/en/venta-viviendas/barcelona-barcelona/"
scraper_api_url = f'https://api.scraperapi.com/?api_key={scraper_api_key}&url={idealista_query}'
response = requests.get(scraper_api_url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Extract each house listing post
house_listings = soup.find_all('article', class_='item')
# Create a list to store extracted information
extracted_data = []
# Loop through each house listing and extract information
for index, listing in enumerate(house_listings):
# Extracting relevant information
title = listing.find('a', class_='item-link').get('title')
price = listing.find('span', class_='item-price').text.strip()
# Find all div elements with class 'item-detail'
item_details = listing.find_all('span', class_='item-detail')
# Extracting bedrooms and area from the item_details
bedrooms = item_details[0].text.strip() if item_details and item_details[0] else "N/A"
area = item_details[1].text.strip() if len(item_details) > 1 and item_details[1] else "N/A"
description = listing.find('div', class_='item-description').text.strip() if listing.find('div', class_='item-description') else "N/A"
tags = listing.find('span', class_='listing-tags').text.strip() if listing.find('span', class_='listing-tags') else "N/A"
# Extracting images
image_elements = listing.find_all('img')
print(image_elements)
image_tags = [img.prettify() for img in image_elements] if image_elements else []
print(image_tags)
# Store extracted information in a dictionary
listing_data = {
"Title": title,
"Price": price,
"Bedrooms": bedrooms,
"Area": area,
"Description": description,
"Tags": tags,
"Image Tags": image_tags
}
# Append the dictionary to the list
extracted_data.append(listing_data)
# Print or save the extracted information (you can modify this part as needed)
print(f"Listing {index + 1}:")
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Bedrooms: {bedrooms}")
print(f"Area: {area}")
print(f"Description: {description}")
print(f"Tags: {tags}")
print(f"Image Tags: {', '.join(image_tags)}")
print("=" * 50)
# Save the extracted data to a JSON file
current_datetime = datetime.now().strftime("%Y%m%d%H%M%S")
json_filename = f"extracted_data_{current_datetime}.json"
with open(json_filename, "w", encoding="utf-8") as json_file:
json.dump(extracted_data, json_file, ensure_ascii=False, indent=2)
print(f"Extracted data saved to {json_filename}")
else:
print(f"Error: Unable to retrieve HTML content. Status code: {response.status_code}")
After running the code, you should have the data dumped in the extracted_data(datetime).json file.
The image below shows how your extracted_data(datetime).json file should look like.
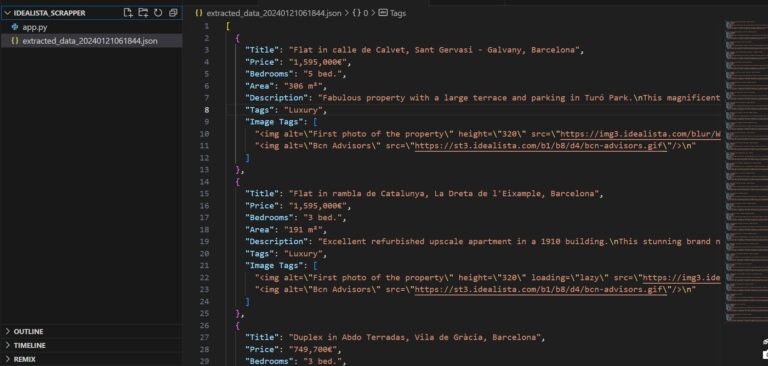
Note: Before running the code, add your API key to the scraper_api_key parameter. If you don’t have one, create a free ScraperAPI account to get 5,000 API credits and access to your unique key.
Scraping Idealista Real Estate Listings
For this article, we’ll focus on Barcelona Real estate listings on the Idealista website: https://www.idealista.com/en/venta-viviendas/barcelona-barcelona/ and extract information like Titles, Prices, Bedrooms, Areas, Descriptions, Tags, and Images.
Project Requirements
You will need Python 3.8 or newer – ensure you have a supported version before continuing – and you’ll need to install Request and BeautifulSoup4.
- The Request library helps you to download Idealista’s post search results page.
- BS4 makes it simple to scrape information from the downloaded HTML.
Install both of these libraries using PIP:
pip install requests bs4
Now, create a new directory and a Python file to store all of the code for this tutorial:
mkdir Idealista_Scrapper
echo. > app.py
You are now ready to go on to the next steps!
Understanding Idealists’s Website Layout
To understand the Idealista website, inspect it to see all the HTML elements and CSS properties.
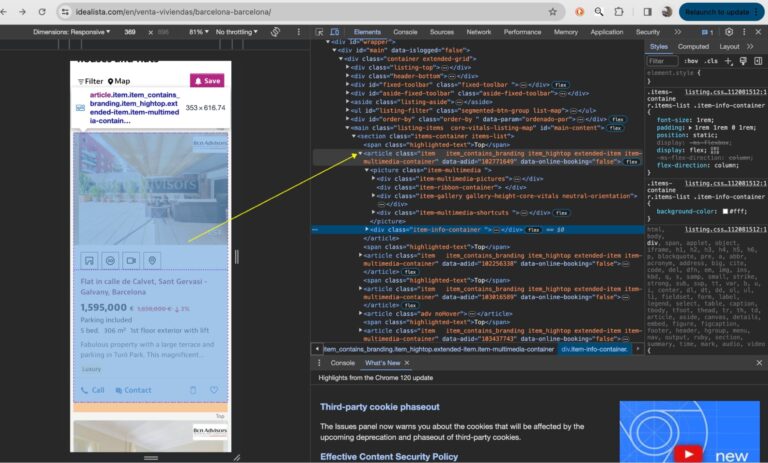
The HTML structure shows that each listing is wrapped in an <article> element. This is what we’ll target to get the listings from Idealista.
The <article> element contains all the property features we need. You can expand the entire structure fully to see them.
Using ScraperAPI to Scrape Idealista Property Data
Idealista is known for blocking scrapers from its website, making collecting data at any meaningful scale challenging. For that reason, we’ll be sending our get() requests through ScraperAPI, effectively bypassing Idealista’s anti-scraping mechanisms without complicated workarounds.
To get started, create a free ScraperAPI account to access your API key.
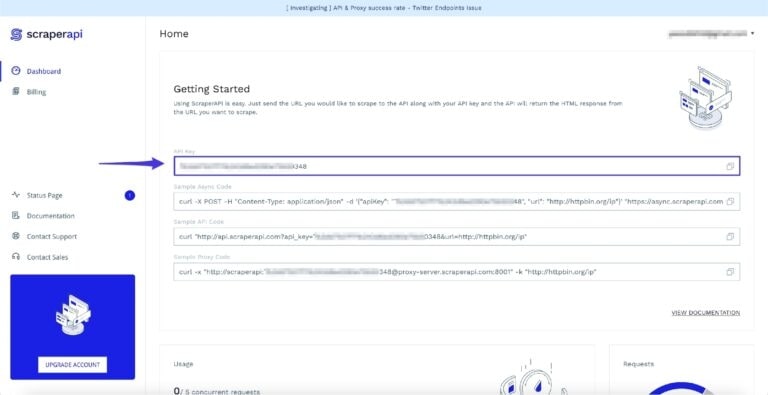
You’ll receive 5,000 free API credits for a seven-day trial, starting whenever you’re ready.
Now that you have your ScraperAPI account let’s get down to business!!
Step 1: Importing Your Libraries
For any of this to work, you must import the necessary Python libraries: json, request, and BeautifulSoup.
import json
from datetime import datetime
import requests
from bs4 import BeautifulSoup
Next, create a variable to store your API key
scraper_api_key = 'ENTER KEY HERE'
Step 2: Downloading Idealista.com’s HTML
ScraperAPI serves as a crucial intermediary, mitigating common challenges encountered during web scraping, such as handling CAPTCHAs, managing IP bans, and ensuring consistent access to target websites.
By routing our requests through ScraperAPI, we offload the intricacies of handling these obstacles to a dedicated service, allowing us to focus on extracting the desired data seamlessly.
Let’s start by adding our initial URL to idealista_query and constructing our get() requests using ScraperAPI’s API endpoint.
idealista_query = f"https://www.idealista.com/en/venta-viviendas/barcelona-barcelona/"
scraper_api_url = f'https://api.scraperapi.com/?api_key={scraper_api_key}&url={idealista_query}'
r = requests.get(scraper_api_url)
Step 3: Parsing Idealista
Next, let’s parse Idealista’s HTML (using BeautifulSoup), creating a soup object we can now use to select specific elements from the page:
soup = BeautifulSoup(r.content, 'html.parser')
articles = soup.find_all('article', class_='item')
Specifically, we’re searching for all <article> elements with a CSS class of item using the find_all() method. The resulting list of articles is assigned to the variable house_listings, which contains each post.
Resource: CSS Selectors Cheat Sheet.
Step 4: Scraping Idealista Listing Information
Now that you have scraped all <article> elements containing each listing, it is time to extract each property and its information!
# Loop through each house listing and extract information
for index, listing in enumerate(house_listings):
# Extracting relevant information
title = listing.find('a', class_='item-link').get('title')
price = listing.find('span', class_='item-price').text.strip()
# Find all div elements with class 'item-detail'
item_details = listing.find_all('span', class_='item-detail')
# Extracting bedrooms and area from the item_details
bedrooms = item_details[0].text.strip() if item_details and item_details[0] else "N/A"
area = item_details[1].text.strip() if len(item_details) > 1 and item_details[1] else "N/A"
description = listing.find('div', class_='item-description').text.strip() if listing.find('div', class_='item-description') else "N/A"
tags = listing.find('span', class_='listing-tags').text.strip() if listing.find('span', class_='listing-tags') else "N/A"
# Extracting images
image_elements = listing.find_all('img')
print(image_elements)
image_tags = [img.prettify() for img in image_elements] if image_elements else []
print(image_tags)
# Store extracted information in a dictionary
listing_data = {
"Title": title,
"Price": price,
"Bedrooms": bedrooms,
"Area": area,
"Description": description,
"Tags": tags,
"Image Tags": image_tags
}
# Append the dictionary to the list
extracted_data.append(listing_data)
# Print or save the extracted information (you can modify this part as needed)
print(f"Listing {index + 1}:")
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Bedrooms: {bedrooms}")
print(f"Area: {area}")
print(f"Description: {description}")
print(f"Tags: {tags}")
print(f"Image Tags: {', '.join(image_tags)}")
print("=" * 50)
In the code above, we checked if the HTTP response status code is 200, indicating a successful request.
If successful, it parses the HTML content of the Idealista webpage and extracts individual house listings by finding all HTML elements with the tag <article> and class 'item'. These represent individual house listings on the Idealista webpage.
The script then iterates through each listing and extracts its details.
The extracted information for each listing is stored in dictionaries, which are appended to a list called extracted_data.
The script prints the extracted information for each listing to the console, displaying details like:
- Title
- Price
- Bedrooms
- Area
- Description
- Tags
- Image tags
Step 5: Exporting Idealista Properties Into a JSON File
Now that you have extracted all the data you need, it is time to save them to a JSON file for easy usability.
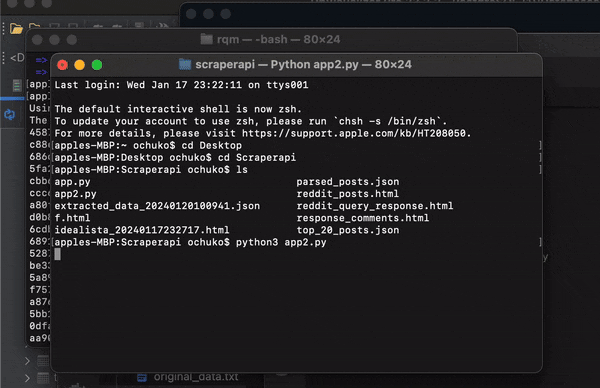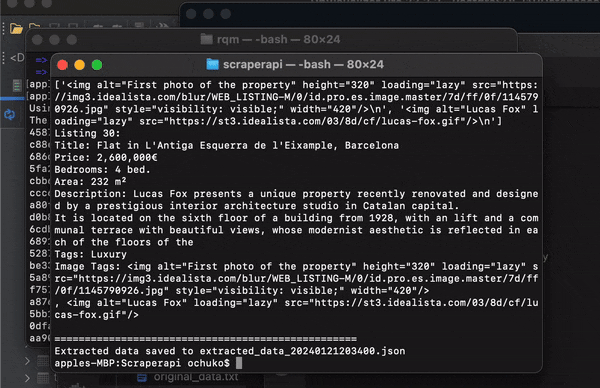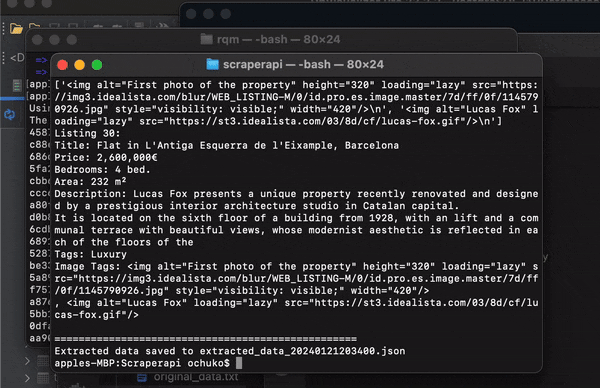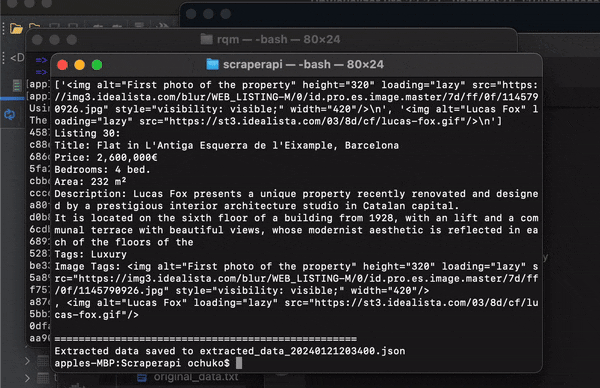
Congratulations, you have successfully scraped data from Idealista, and you are free to use the data any way you want!
How to Turn Idealista Listings into LLM-Readable Data
Real estate platforms like Idealista are packed with valuable data—rental prices, locations, number of bedrooms, square footage, and property features. But this information is buried in complex layouts that aren’t LLM-friendly out of the box.
Instead of scraping raw HTML and manually parsing tags, we can use ScraperAPI’s output_format=markdown to pull a clean, structured version of Idealista’s listings. This Markdown format makes it easier for models like Google Gemini to extract useful summaries from the page.
Step 1: Get Your API Keys
Before starting, ensure you have a ScraperAPI key and a Google Gemini API key. If you already have them, you can skip ahead. Otherwise:
- Get your ScraperAPI key: Sign up here for 5,000 free API credits.
- Get your Google Gemini API key:
- Go to Google AI Studio
- Sign in with your Google account
- Click Create API Key and follow the prompts
Step 2: Scrape Idealista Listings in Markdown Format
We’ll use ScraperAPI to fetch rental listings from Idealista’s Madrid page. Instead of parsing raw HTML, we request the page in Markdown format using output_format=markdown, which returns clean, readable content that’s easier for LLMs like Gemini to process.
Here’s how to do it:
import requests
API_KEY = "YOUR_SCRAPERAPI_KEY"
url = "https://www.idealista.com/en/alquiler-viviendas/madrid-madrid/"
payload = {
"api_key": API_KEY,
"output_format": "markdown",
"url": url
}
response = requests.get("https://api.scraperapi.com", params=payload)
markdown_data = response.text
print(markdown_data)
The response will be a full Markdown version of the listings page. This will include rental prices, locations, square meter sizes, number of bedrooms, and sometimes extras like “furnished,” “balcony,” or “elevator access”—all formatted as readable text.
Here’s a snippet of how the markdown output would look:
[Flat / Apartment in calle de la Infanta Mercedes, 96, Cuzco-Castillejos, Madrid](/en/inmueble/98556655/ "Flat / Apartment in calle de la Infanta Mercedes, 96, Cuzco-Castillejos, Madrid")
1,350€/month Parking included
1 bed. 47 m² 10th floor exterior with lift 13 hours
ABSTAIN REAL ESTATE AGENCIES! Cozy, cheerful and functional, it has a spacious living room with integrated kitchen, dining room, and a bedroom with large fitted wardrobes. It has a bathroom with a large shower and a cabinet with great storage. The apartment is very bright as well as having a terrace with spectacular vi
Apartment
Call View phone Discard Save
1/29
.....
This Markdown output is what we’ll feed into Gemini in the next step.
Step 3: Analyse the Listings with Gemini
Now that we’ve extracted a clean Markdown version of the Idealista rental page, we can pass it directly to Google Gemini for analysis. This time, instead of just listing raw property data, we’ll ask Gemini to act like a real estate analyst, identifying which listings offer the best value based on rent, size, and features.
First, make sure you’ve installed the Gemini SDK:
pip install google-generativeai
Next, we’ll send the markdown data to Gemini using our custom prompt and see what insights it can pull out for us.
import google.generativeai as genai
# Configure Gemini with your API key
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel(model_name="gemini-2.0-flash")
# Custom prompt for rental analysis
prompt = f"""
You are a real estate analyst. Below is a text-based version of rental listings from Idealista for apartments in Madrid.
From the information provided, extract the **top 5 listings** that offer the best value for renters. For each listing, include:
- Monthly rent
- Number of bedrooms
- Location (neighbourhood or district)
- Property size in square meters (if available)
- Any notable features (e.g. furnished, balcony, elevator, newly renovated)
- Why you consider it a good deal (brief reasoning)
Summarize in a clean, easy-to-read format.
Here is the data:
{markdown_data}
"""
# Generate the summary
response = model.generate_content(prompt)
print(response.text)
Gemini will respond with a curated list of the most attractive listings from the Idealista page, giving you a quick way to spot value and compare options without scrolling through dozens of entries.
Here’s an example of what the output from Gemini might look like:
Okay, here are the top 5 rental listings based on the provided data, ranked by perceived value. Please note that this is based solely on the text and lacks visual inspection of the properties. A real-world analysis would involve visiting the properties and assessing their true condition and surroundings.
**Top 5 Best Value Rental Listings in Madrid (based on text data):**
1. **Monthly Rent:** €800
* **Bedrooms:** 1
* **Location:** San Diego
* **Size:** 45 m²
* **Features:** Lift
* **Why a good deal:** This is the lowest price for a 1-bedroom apartment with a lift, which are usually more expensive in the city. However, the apartment is interior, which could make it less desirable.
2. **Monthly Rent:** €920 (Parking included)
* **Bedrooms:** 2
* **Location:** Pau de Carabanchel
* **Size:** 55 m²
* **Features:** Lift, garage included, unfurnished, kitchen furnished with appliances, built-in wardrobes, landscaped common areas.
* **Why a good deal:** Modern apartment including garage is a big plus, especially since it is already equipped with kitchen appliances. The fact that it is unfurnished gives the renter freedom to make it their own.
3. **Monthly Rent:** €990
* **Bedrooms:** 2
* **Location:** El Pardo
* **Size:** 50 m²
* **Features:** Newly renovated, fully equipped kitchen, two large storage closets, vinyl flooring.
* **Why a good deal:** Newly renovated apartments are desirable. Having 2 bedrooms for under €1000 is a very good price for Madrid.
4. **Monthly Rent:** €1,010 (Parking included)
* **Bedrooms:** 1
* **Location:** Ensanche de Vallecas - La Gavia
* **Size:** 58 m²
* **Features:** Terrace, parking included, storage room included, unfurnished, fully equipped kitchen, hardwood floors, built-in wardrobes.
* **Why a good deal:** Good size for a 1-bedroom, terrace and parking are highly desirable. The price is reasonable considering the amenities.
5. **Monthly Rent:** €1,150 (Parking included)
* **Bedrooms:** 2
* **Location:** Canillas
* **Size:** 80 m²
* **Features:** Luminous, air conditioning in all rooms, fully furnished kitchen, garage space for a large car, whirlpool.
* **Why a good deal:** Large, luminous, and air conditioned. In addition to all these amenities, it also includes parking.
**Important Considerations:**
* **"Exterior" vs. "Interior":** Exterior apartments are generally preferred as they have street views and more natural light. Interior apartments face an inner courtyard and can be quieter but sometimes darker.
* **Furnished vs. Unfurnished:** This is a matter of personal preference. Unfurnished apartments may offer more flexibility but require additional upfront costs for furniture.
* **Location:** Proximity to public transportation, amenities, and the renter's workplace or school is crucial. Some neighbourhoods are more expensive than others.
Using ScraperAPI to format the page as markdown and crafting a clear prompt for Gemini, we can quickly surface useful rental information like pricing patterns, standout features, and common listing types. You can easily adapt this approach for other cities or filter for specifics like furnished apartments or listings with balconies—just tweak the URL or prompt and run it again!
Extract Fresh Property Data from Idealista with ScraperAPI
This tutorial presented a step-by-step approach to scraping data from Idealista, showing you how to:
- Collect the 50 most recent listings in Barcelona on Idealista
- Loop through all listings to collect information
- Send your requests through ScraperAPI to avoid getting banned
- Export all extracted data into a structured JSON file
As we conclude this insightful journey into the realm of Idealista scraping, we hope you’ve gained valuable insights into the power of Python and ScraperAPI in unlocking the treasure trove of information Idealista holds.
Leverage ScraperAPI’s 7-day free trial to test our web scraping tool, and tell us what you think! Sign up here.
Until next time, happy scraping!
P.S. If you’d like to explore another approach to scraping Idealista and bypassing DataDome, check out this publication by The Web Scraping Club. It was created in collaboration between our own Leonardo Rodriguez and Pierluigi Vinciguerra, Co-Founder and CTO at Databoutique.
Check out ScraperAPI’s other real estate web scraping guide:
- How to Scrape Homes.com Property Listing
- How to Scrape Zoopla Property Listings
- How to Scrape Redfin Property Data with Node.js
- How to Web Scrape Zillow
Frequently-Asked Questions
You can Scrape a handful of data from Idealista.com. Here is a list of all major data you can scrape:
– Property Prices
– Location Data
– Property Features
– Number of Bedrooms
– Number of Bathrooms
– Property Size (Square Footage)
– Property Type (e.g., apartment, house)
– Listing Descriptions
– Contact Information of Sellers/Agents
– Availability Status
– Images or Photos of the Property
– Floor Plans (if available)
– Additional Amenities or Facilities
– Property ID or Reference Number
– Date of Listing Publication
The possibilities with Idealista data are endless! Here are just a few examples:
– Market Research: Analyze property prices and trends in specific neighborhoods or cities and understand the real estate market’s demand and supply dynamics.
– Investment Decision-Making: Identify potential investment opportunities by studying property valuation and market conditions.
– Customized Alerts for Buyers and Investors: Set up personalized alerts for specific property criteria to ensure timely access to relevant listings.
– Research for Academia: Researchers can use scraped data for academic studies on real estate trends, thereby gaining insights into urban development, housing patterns, and demographic preferences.
– Competitive Analysis for Agents: Real estate agents can analyze competitor listings and pricing strategies and stay ahead by understanding market trends and consumer preferences.
Yes, Idealista blocks web scraping directly using techniques like IP blocking and Fingerprinting. To avoid your scrapers from breaking, we advise using a tool like ScraperAPI to bypass anti-bot mechanisms and automatically handle most of the complexities involved in web scraping.