



In this tutorial, we’ll show you how to build a Zoopla web scraper capable of bypassing its anti-bot protection using Node.js and ScraperAPI to never get blocked again.
TL;DR: Full Zoopla Scraper
For those in a hurry, here is the full Node.js code:
const axios = require('axios');
const cheerio = require('cheerio');
const ZOOPLA_PAGE_URL = 'https://www.zoopla.co.uk/for-sale/property/liverpool/?q=Liverpool%2C+Merseyside&results_sort=newest_listings&search_source=home';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '' // <--- Enter your API key here
const webScraper = async () => {
console.log('Fetching data with ScraperAPI...');
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: ZOOPLA_PAGE_URL,
country_code: 'uk'
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const propertyList = [];
console.log('Extracting information from the HTML...');
$(".dkr2t82").each((_, el) => {
const link = $(el).find('a._1lw0o5c2').attr('href');
const tagsElement = $(el).find('ul._1ial65f0 li');
const configsElement = $(el).find('ul._1wickv0 li');
const price = $(el).find('._1egbt4s3r p:last-child').text();
const title = $(el).find('h2.m6hnz61').text();
const address = $(el).find('address.m6hnz62').text();
const description = $(el).find("p.m6hnz63").text();
const tags = [];
const configs = {};
tagsElement.each((_, el) => {
tags.push($(el).text().replaceAll(' ', '_').toLowerCase())
})
configsElement.each((_, el) => {
const label = $(el).find('span._1wickv2').text().replaceAll(' ', '_').toLowerCase();
const count = $(el).find('span:last-child').text();
configs[label] = +count;
})
propertyList.push({
description,
price,
title,
address,
tags,
configuration: configs,
link: link.startsWith('https') ? link : `https://www.zoopla.co.uk${link}`
});
});
console.log('JSON result:', propertyList);
} catch (error) {
console.log(error)
}
};
void webScraper();
Note: Before running this code, install the dependencies and set your API key, which you can find in the ScraperAPI dashboard.
Want to learn how to build this scraper from scratch? Let’s jump into the tutorial!
How to Scrape Zoopla Property Listings
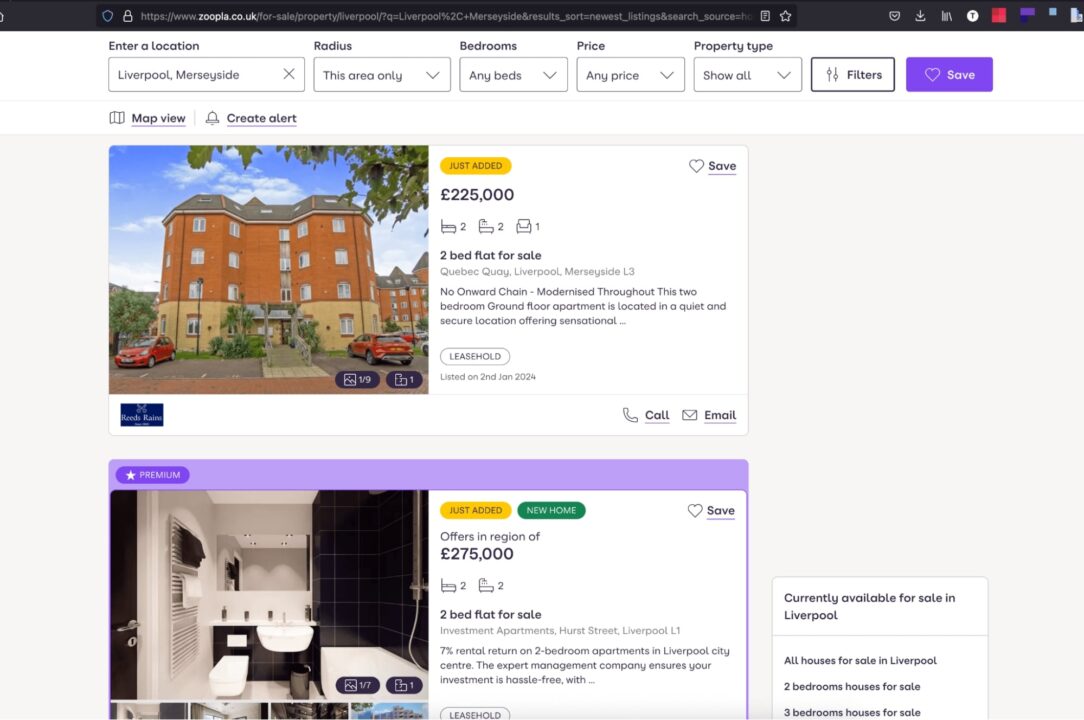
To show you how to scrape Zoopla property data, we’ll write a scraper that finds properties for sale in the city of Liverpool.
For each property for sale, we’ll retrieve the following information:
- Title
- Description
- Address
- Price
- Configuration
- Property URL
The script will return the list of properties in JSON format, so you can easily use it for other purposes.
Prerequisites
You must have these tools installed on your computer to follow this tutorial.
- Node.js 18+ and NPM
- Basic knowledge of JavaScript and Node.js API
- A ScraperAPI account; sign up and get 5,000 free API credits to get started
Note: Check this tutorial if this is your first time using Node.js for web scraping.
Step 1: Set Up the Project
Let’s create a folder that will contain the source code of the Zoopla Web scraper.
mkdir zoopla-scraper
Enter the folder and initialize a new Node.js project
cd zoopla-scraper
npm init -y
The second command above will create a package.json file in the folder. Let’s create a file index.js and add a simple JavaScript instruction inside.
touch index.js
echo "console.log('Hello world!');" > index.js
Run the file index.js using the Node.js runtime.
node index.js
This execution will print the message Hello world! in the terminal.
Step 2: Install the Dependencies
We must install two Node.js packages to build the Zoopla Web scraper:
- Axios – to build the HTTP request (headers, body, query string parameters, etc.), send it to ScraperAPI, and download the HTML content.
- Cheerio – to extract the information from the HTML downloaded from the Axios request.
Run the command below to install these packages:
npm install axios cheerio
Step 3: Identify the DOM Selectors to Target
Navigate to https://www.zoopla.co.uk, the property for sale is the default option. Type “Liverpool” in the search bar and press enter.
When the search result appears listing the properties, inspect the page to display the HTML structure and identify the DOM selector associated with the HTML tag wrapping the information we want to extract.
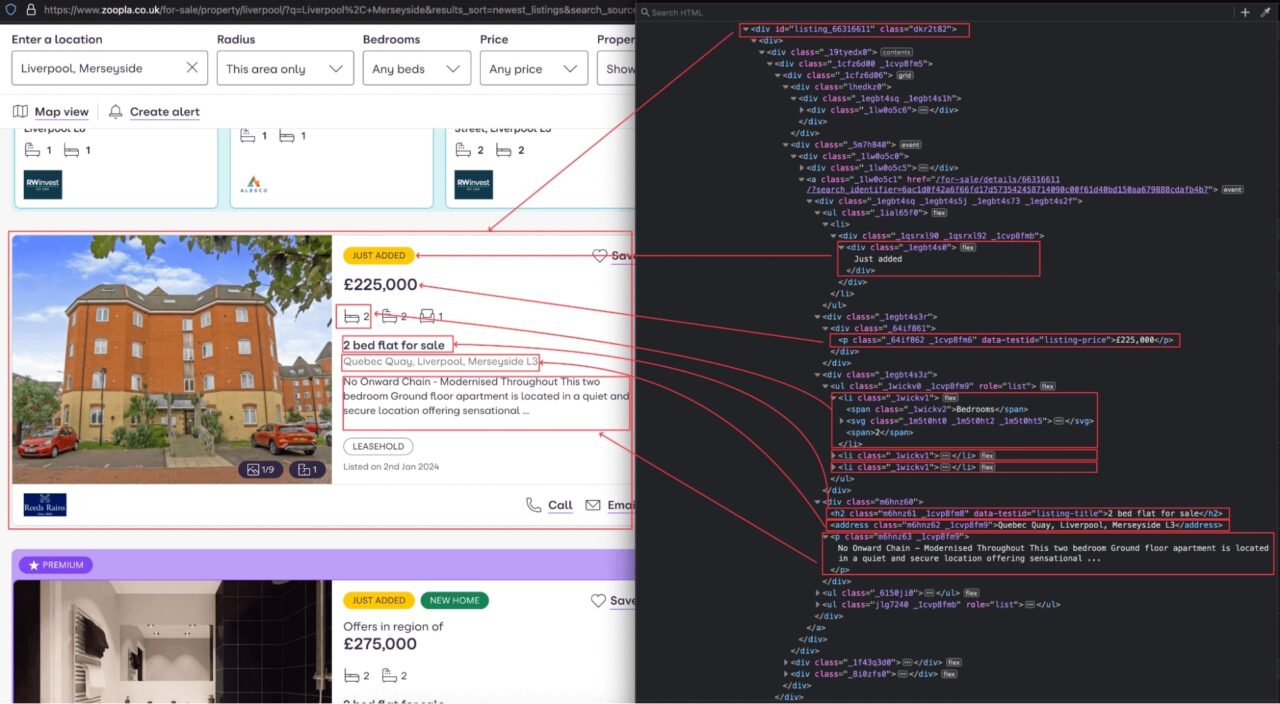
From the above picture, here are all the DOM selectors the Web scraper will target to extract the information of each property.
| Information | DOM Selector |
| Title | .dkr2t82 h2.m6hnz61 |
| Description | .dkr2t82 p.m6hnz63 |
| Price | .dkr2t82 ._1egbt4s3r p:last-child |
| Address | .dkr2t82 address.m6hnz62 |
| Property’s configuration | .dkr2t82 ul._1wickv0 li |
| Property’s link | .dkr2t82 a._1lw0o5c2 |
Be careful when writing the selector because a misspelling will prevent the script from retrieving the correct value.
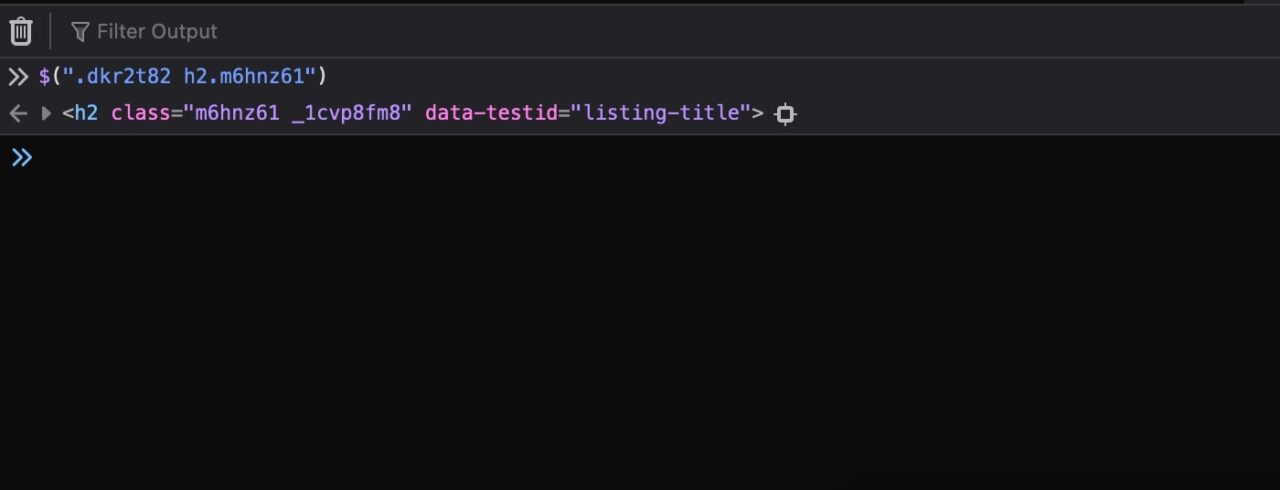
Note: A good method to avoid errors when building your selectors is to try them with jQuery first. In the browser console, type your selector like $(".dkr2t82 h2.m6hnz61") if it returns the correct DOM element, then you are good to go.
Step 4: Scrape Zoopla’s property page
We will use Axios to build the HTTP request to send to the ScraperAPI’s API. The request needs the following query parameters:
- The URL to scrape: it is the URL of the Zoopla properties search page; you can copy it into the address bar of your browser.
- The API Key: to authenticate against the Scraping API and perform the scraping; if you still have enough credit, find it on the dashboard page of your ScraperAPI account.
Use of geotargeting for Web scraping
Geo-targeting refers to delivering content, advertisements, or services to users based on their geographic location, mainly determined by their IP address.
In the real estate industry, location is one of the most critical factors for property buyers or renters. Using ScraperAPI’s geo-targeting makes scraping Zoopla more precise by allowing us to gather localized information as local searchers would.
With ScraperAPI, you can specify the country code from which the request must be sent. In the HTTP request query parameter, set the key country_code with the value uk to indicate the request comes from the United Kingdom.
Note: Check out the ScraperAPI’s API documentation to view the supported country codes.
Edit the index.js to add the code below that builds the HTTP request, sends it, receives the response, and prints it in the terminal.
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const ZOOPLA_PAGE_URL = 'https://www.zoopla.co.uk/for-sale/property/liverpool/?q=Liverpool%2C+Merseyside&results_sort=newest_listings&search_source=home';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const webScraper = async () => {
console.log('Fetching data with ScraperAPI...');
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: ZOOPLA_PAGE_URL,
country_code: 'uk'
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
console.log("HTML content", html);
} catch (error) {
console.log(error)
}
};
void webScraper();
</pre>
Note: Don’t have an API key yet? Create a free ScraperAPI account and get 5,000 API credits, plus access to all our tools.
Step 5: Extract Zoopla Property Details
Now that we have the HTML content of the page, let’s parse it with Cheerio to easily navigate through the DOM and extract all the information we want.
Cheerio provides functions to load HTML text, then navigate through the structure to extract information using the DOM selectors.
The code below goes through each element, extracts the information, and returns an array containing all the properties.
const cheerio = require('cheerio');
const $ = cheerio.load(html);
const propertyList = [];
console.log('Extract information from the HTML...');
$(".dkr2t82").each((_, el) => {
const link = $(el).find('a._1lw0o5c2').attr('href');
const tagsElement = $(el).find('ul._1ial65f0 li');
const configsElement = $(el).find('ul._1wickv0 li');
const price = $(el).find('._1egbt4s3r p:last-child').text();
const title = $(el).find('h2.m6hnz61').text();
const address = $(el).find('address.m6hnz62').text();
const description = $(el).find("p.m6hnz63").text();
const tags = [];
const configs = {};
tagsElement.each((_, el) => {
tags.push($(el).text().replaceAll(' ', '_').toLowerCase())
})
configsElement.each((_, el) => {
const label = $(el).find('span._1wickv2').text().replaceAll(' ', '_').toLowerCase();
const count = $(el).find('span:last-child').text();
configs[label] = +count;
})
propertyList.push({
description,
price,
title,
address,
tags,
configuration: configs,
link: link.startsWith('https') ? link : `https://www.zoopla.co.uk${link}`
});
});
console.log('JSON result:', propertyList);
As you can see, we’re using the identified HTML tags and CSS selectors to navigate the DOM and pick specific elements.
Once our scraper gets all these details, we then push() the results into our empty list (propertyList) to get them organized, making it easier to export the information into a JSON file.
Here is the complete code of the index.js file:
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const cheerio = require('cheerio');
const ZOOPLA_PAGE_URL = 'https://www.zoopla.co.uk/for-sale/property/liverpool/?q=Liverpool%2C+Merseyside&results_sort=newest_listings&search_source=home';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const webScraper = async () => {
console.log('Fetching data with ScraperAPI...');
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: ZOOPLA_PAGE_URL,
country_code: 'uk'
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const propertyList = [];
console.log('Extract information from the HTML...');
$(".dkr2t82").each((_, el) => {
const link = $(el).find('a._1lw0o5c2').attr('href');
const tagsElement = $(el).find('ul._1ial65f0 li');
const configsElement = $(el).find('ul._1wickv0 li');
const price = $(el).find('._1egbt4s3r p:last-child').text();
const title = $(el).find('h2.m6hnz61').text();
const address = $(el).find('address.m6hnz62').text();
const description = $(el).find("p.m6hnz63").text();
const tags = [];
const configs = {};
tagsElement.each((_, el) => {
tags.push($(el).text().replaceAll(' ', '_').toLowerCase())
})
configsElement.each((_, el) => {
const label = $(el).find('span._1wickv2').text().replaceAll(' ', '_').toLowerCase();
const count = $(el).find('span:last-child').text();
configs[label] = +count;
})
propertyList.push({
description,
price,
title,
address,
tags,
configuration: configs,
link: link.startsWith('https') ? link : `https://www.zoopla.co.uk${link}`
});
});
console.log('JSON result:', propertyList);
} catch (error) {
console.log(error)
}
};
void webScraper();
</pre>
Run the code with the command node index.js, and appreciate the result.
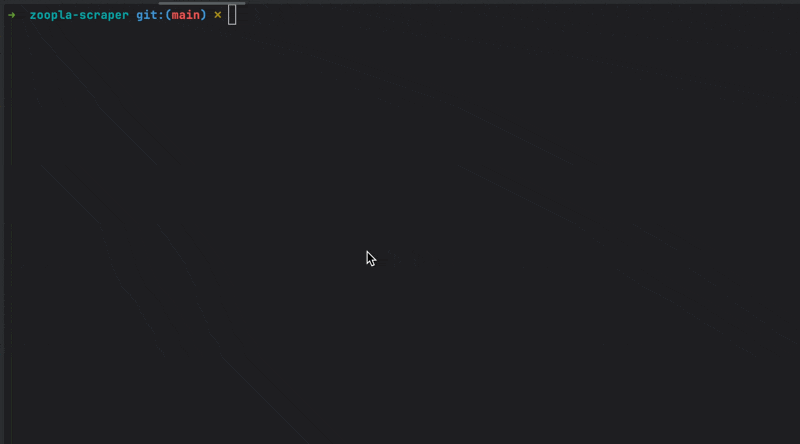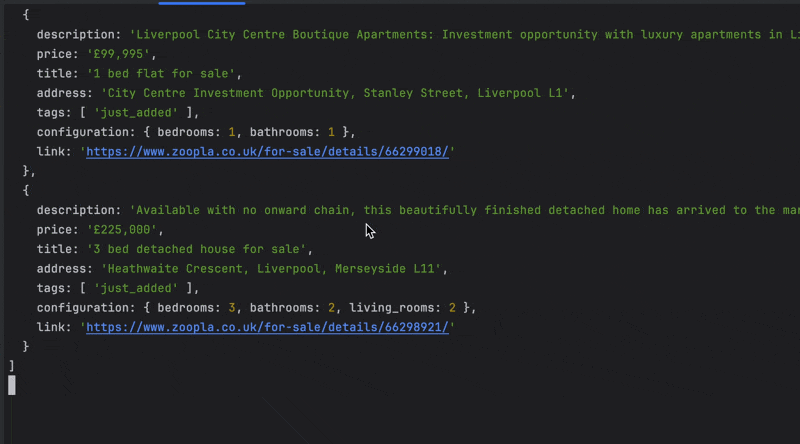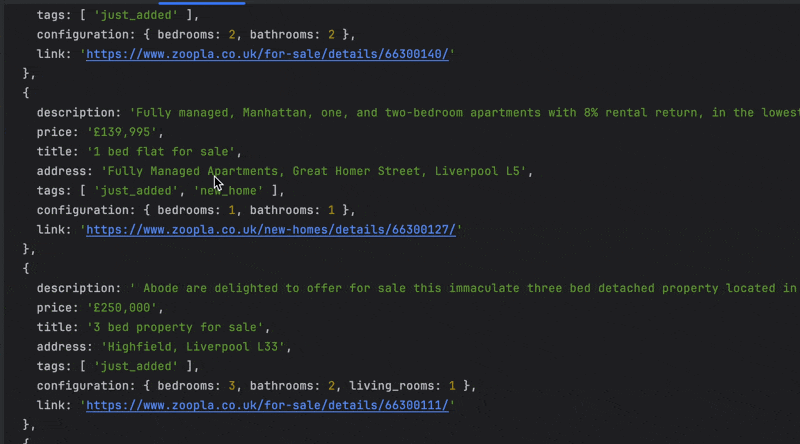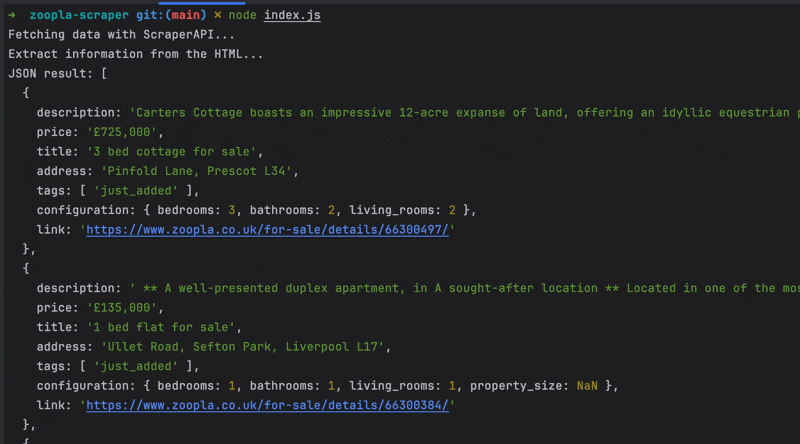
Wrapping Up
Building a web scraper for Zoopla can be done in the following steps:
- Use Axios to send a request to ScraperAPI with the Zoopla page to scrape, and download the HTML content.
- Parse the HTML with Cheerio to extract the data based on DOM selectors.
- Format and transform the data retrieved to suit your needs.
The result is a list of relevant information about the properties for sale displayed on the Zoopla website.
Here are a few ideas to go further with this Zoopla Web scraper:
- Retrieve the information about properties to rent
- Make the Web scraper dynamic by allowing you to type the city directly.
- Store the data in a database (RDBMS, JSON files, CSV files, etc…) to build historical data and make business decisions.
- Use the Async Scraper service to scrape up to 10,000 URLs asynchronously.
To learn more, check out ScraperAPI’s documentation for Node.js.





