



Why Scrape Google Maps Data?
There are some benefits of extracting data from Google Maps. This includes:
- Gain Business Insights: Analyzing Google Maps data offers insights into businesses, such as their locations, contact information, opening hours, and customer reviews. This information can be valuable for market research and competitor analysis.
- Create Location-Based Service: Developers can use scraped location data from Google Maps to create location-based services, such as finding nearby restaurants, hotels, bookshops, and other points of interest.
- Perform Geographic Analysis: Business analysts can use scraped geographic data from Google Maps to study population density, traffic flow, and urban development.
- Build Travel and Tourism Services: The Google Maps scraped data can power travel planning platforms, providing users with information about attractions, accommodations, transportation, and more.
- Enrich Datasets: Businesses can update their existing datasets with location-based information, enhancing customer profiles and improving targeted marketing efforts.
How to Scrape Google Maps: A Beginner-Friendly Guide
To demonstrate how to scrape Google Maps, we’ll write a script that finds bookshops in California.
For each bookshop, we’ll extract the:
- Name
- Type
- Description
- Address
- Phone number
- Availability hours
- Availability status
- Average rating
- Total reviews
- Delivery options
- Google Maps link
Also, we’ll export the data to JSON to make it easier to handle.
Web Scraping Project Prerequisites
You must have these tools installed on your computer to follow this Google Maps scraper tutorial.
- Node.js 18+ and NPM – Download link
- Second item of a list
1. Set Up the Google Maps Data Collection Project
Let’s create a folder that will hold the code source of our Google Maps web scraper.
mkdir google-maps-scraper
Now, initialize a Node.js project by running the command below:
cd google-maps-scraper npm init -y
The second command above will create a package.json file in the folder. Let’s create a file index.js and add a simple JavaScript instruction inside.
touch index.js
echo "console.log('Hello world!');" > index.js
Execute the file index.js using the Node.js runtime.
node index.js
This command will print Hello world! in the terminal.
2. Install the Dependencies
To perform Google Maps Web scraping, we need these two Node.js packages:
- Puppeteer – to load the Google Maps website, search for the bookshop, scroll the page to load more results, and download the HTML content.
- Cheerio – to extract the information from the HTML downloaded by Puppeteer
Run the command below to install these packages:
npm install puppeteer cheerio
3. Identify the DOM Selectors to Target
Navigate to https://www.google.com/maps; in the text input at the top-left, type “bookshop” and press enter.
Now that we see the search result, inspect the page to identify the DOM selector associated with the HTML tag wrapping the information we want to extract.
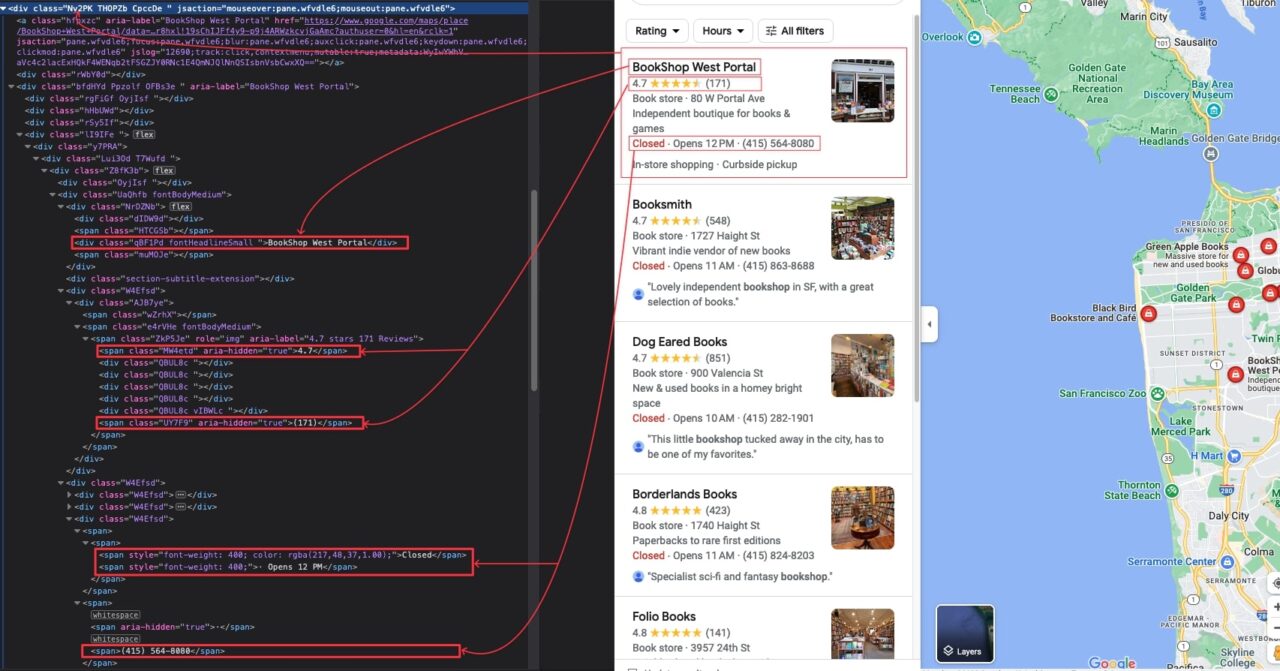
After close inspection, here are all the DOM selectors our script will be targeting to extract the information:
| Information | DOM Selector |
| Bookshop’s name | .qBF1Pd |
| Type | .W4Efsd:last-child .W4Efsd span:first-child > span |
| Description | .W4Efsd:last-child .W4Efsd span > span |
| Address | .W4Efsd:last-child .W4Efsd span:last-child span:last-child |
| Phone Number | .W4Efsd:last-child .W4Efsd span span:last-child span:last-child |
| Hour’s Availability | .W4Efsd:last-child .W4Efsd span > span > span:last-child |
| Availability Status | .W4Efsd:last-child .W4Efsd span > span > span:first-child |
| Average Rating | .MW4etd |
| Total Reviews | .UY7F9 |
| Delivery options | .qty3Ue |
| Google Maps link | a.hfpxzc |
The DOM selectors of the Google Maps page are not human-friendly, so be careful when copying them to avoid issues.
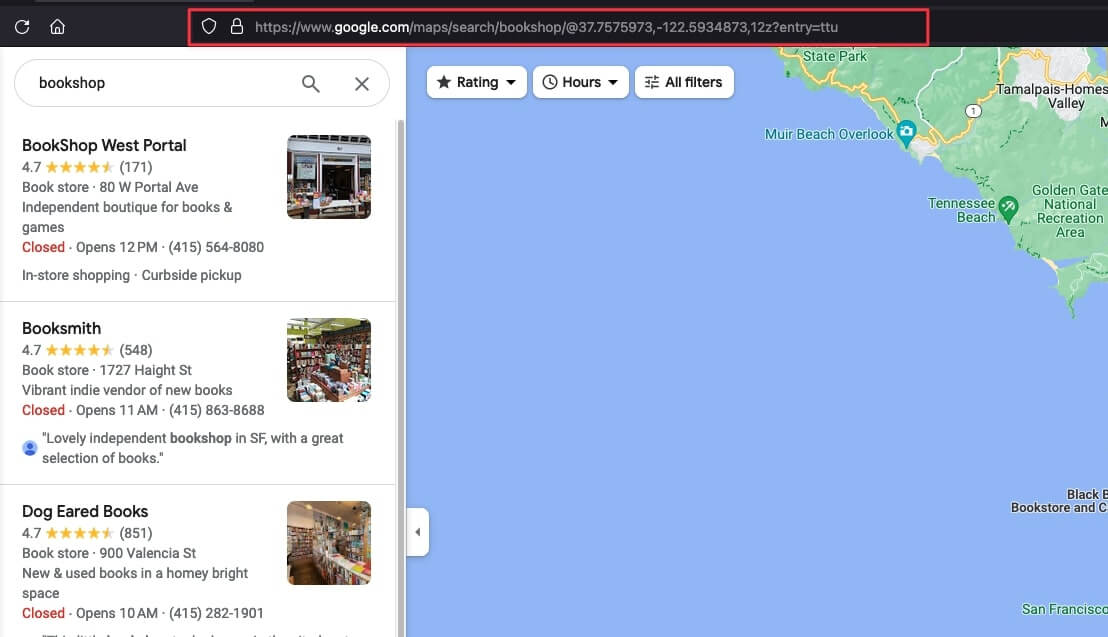
In my case, the URL is the following: https://www.google.com/maps/search/bookshop/@37.7575973,-122.5934873,12z?entry=ttu.
Let’s update the code of the index.js with the following code:
const puppeteer = require("puppeteer");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const main = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@36.6092093,-129.3569836,6z/data=!3m1!4b1" , {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(5000);
};
void main();
This code above creates a browser instance with the headless mode deactivated; it is helpful in development mode to view the interaction on the page, enhancing the feedback loop.
We define the browser User-Agent so Google Maps treats us as a real browser, and then we navigate to the Google page.
In some countries (Mostly in Europe), a page to ask for consent will be displayed before redirecting to the URL; here, we click on the button to reject everything and wait five seconds for the Google Maps page to load completely.
const TOTAL_SCROLL = 10;
let scrollCounter = 0;
const scrollContainerSelector = '.m6QErb[aria-label]';
while (scrollCounter < TOTAL_SCROLL) {
await page.evaluate(`document.querySelector("${scrollContainerSelector}").scrollTo(0, document.querySelector("${scrollContainerSelector}").scrollHeight)`);
await waitFor(2000);
scrollCounter++;
}
const html = await page.content();
await browser.close();
console.log(html);
The code above performs ten scrolls on the result list section; each scroll waits two seconds for new data to load. After the ten scrolls, we download the HTML content of the page and close the browser instance.
To increase the number of search results to retrieve, increase the number of total scrolls.
const extractPlacesInfo = (htmlContent) => {
const result = [];
const $ = cheerio.load(htmlContent);
$(".Nv2PK").each((index, el) => {
const link = $(el).find("a.hfpxzc").attr("href");
const title = $(el).find(".qBF1Pd").text();
const averageRating = $(el).find(".MW4etd").text();
const totalReview = $(el).find(".UY7F9").text();
const infoElement = $(el).find(".W4Efsd:last-child").find('.W4Efsd');
const type = $(infoElement).eq(0).find("span:first-child > span").text();
const address = $(infoElement).eq(0).find("span:last-child span:last-child").text();
let description = null;
let availability = null;
let availabilityStatus = null;
let phoneNumber = null;
if (infoElement.length === 2) {
availabilityStatus = $(infoElement).eq(1).find("span > span > span:first-child").text();
availability = $(infoElement).eq(1).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(1).children("span").last().find("span:last-child").text();
}
if (infoElement.length === 3) {
description = $(infoElement).eq(1).find("span > span").text();
availabilityStatus = $(infoElement).eq(2).find("span > span > span:first-child").text();
availability = $(infoElement).eq(2).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(2).children("span").last().find("span:last-child").text();
}
const deliveryOptions = $(el).find(".qty3Ue").text();
const latitude = link.split("!8m2!3d")[1].split("!4d")[0];
const longitude = link.split("!4d")[1].split("!16s")[0];
const placeInfo = sanitize({
address,
availability,
availabilityStatus,
averageRating,
phoneNumber,
deliveryOptions,
description,
latitude,
link,
longitude,
title,
type,
totalReview
});
result.push(placeInfo);
});
return result;
};
The information extracted is passed to a sanitize() function we wrote in the file utils.js to clean and format the data; browse the code repository to see its implementation.
Here is the complete code of the index.js file:
const puppeteer = require("puppeteer");
const cheerio = require("cheerio");
const { sanitize } = require("./utils");
const waitFor = (timeInMs) => new Promise(r => setTimeout(r, timeInMs));
const extractPlacesInfo = (htmlContent) => {
const result = [];
const $ = cheerio.load(htmlContent);
$(".Nv2PK").each((index, el) => {
const link = $(el).find("a.hfpxzc").attr("href");
const title = $(el).find(".qBF1Pd").text();
const averageRating = $(el).find(".MW4etd").text();
const totalReview = $(el).find(".UY7F9").text();
const infoElement = $(el).find(".W4Efsd:last-child").find('.W4Efsd');
const type = $(infoElement).eq(0).find("span:first-child > span").text();
const address = $(infoElement).eq(0).find("span:last-child span:last-child").text();
let description = null;
let availability = null;
let availabilityStatus = null;
let phoneNumber = null;
if (infoElement.length === 2) {
availabilityStatus = $(infoElement).eq(1).find("span > span > span:first-child").text();
availability = $(infoElement).eq(1).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(1).children("span").last().find("span:last-child").text();
}
if (infoElement.length === 3) {
description = $(infoElement).eq(1).find("span > span").text();
availabilityStatus = $(infoElement).eq(2).find("span > span > span:first-child").text();
availability = $(infoElement).eq(2).find("span > span > span:last-child").text();
phoneNumber = $(infoElement).eq(2).children("span").last().find("span:last-child").text();
}
const deliveryOptions = $(el).find(".qty3Ue").text();
const latitude = link.split("!8m2!3d")[1].split("!4d")[0];
const longitude = link.split("!4d")[1].split("!16s")[0];
const placeInfo = sanitize({
address,
availability,
availabilityStatus,
averageRating,
phoneNumber,
deliveryOptions,
description,
latitude,
link,
longitude,
title,
type,
totalReview
});
result.push(placeInfo);
});
return result;
}
const main = async () => {
const browser = await puppeteer.launch({
headless: false,
args: ["--disabled-setuid-sandbox", "--no-sandbox"],
});
const page = await browser.newPage();
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@37.7575973,-122.5934873,12z?entry=ttu", {
waitUntil: 'domcontentloaded',
timeout: 60000
});
const buttonConsentReject = await page.$('.VfPpkd-LgbsSe[aria-label="Reject all"]');
await buttonConsentReject?.click();
await waitFor(5000);
const TOTAL_SCROLL = 5;
let scrollCounter = 0;
const scrollContainerSelector = '.m6QErb[aria-label]';
while (scrollCounter < TOTAL_SCROLL) {
await page.evaluate(`document.querySelector("${scrollContainerSelector}").scrollTo(0, document.querySelector("${scrollContainerSelector}").scrollHeight)`);
await waitFor(2000);
scrollCounter++;
}
const html = await page.content();
await browser.close();
const result = extractPlacesInfo(html);
console.log(result);
};
void main();
Run the code with the command node index.js, and appreciate the result:
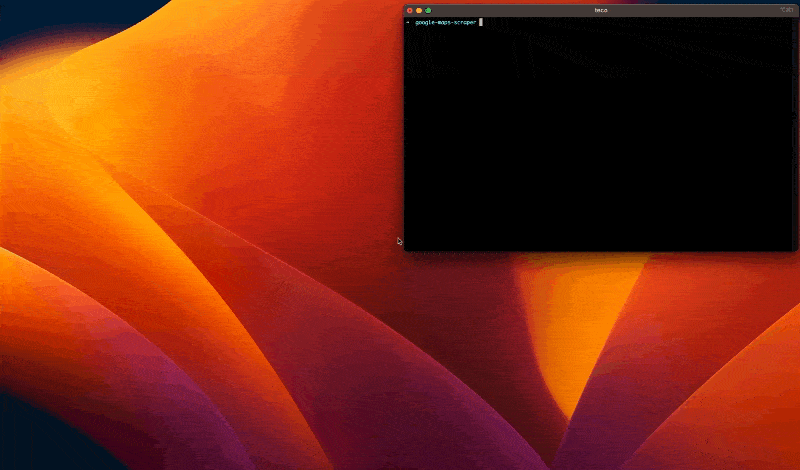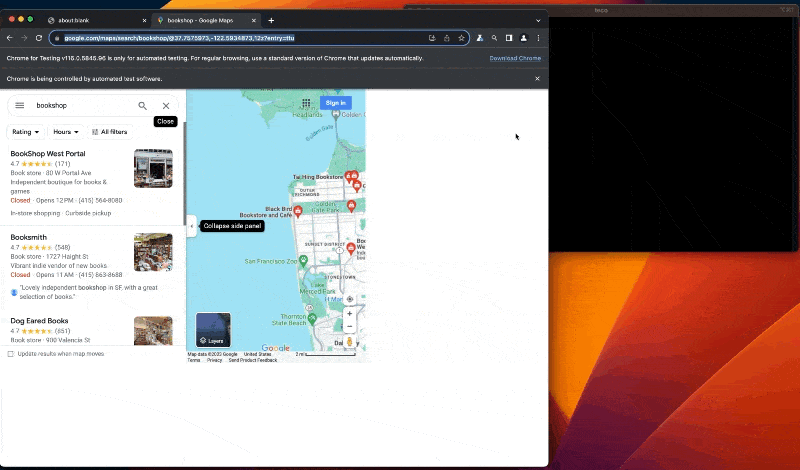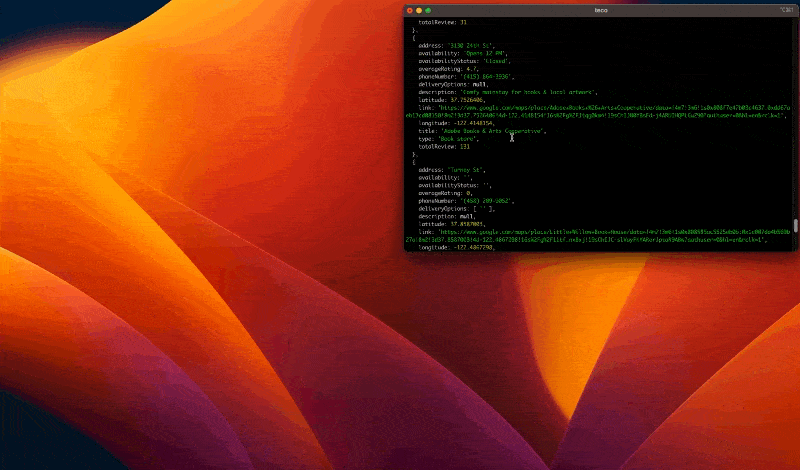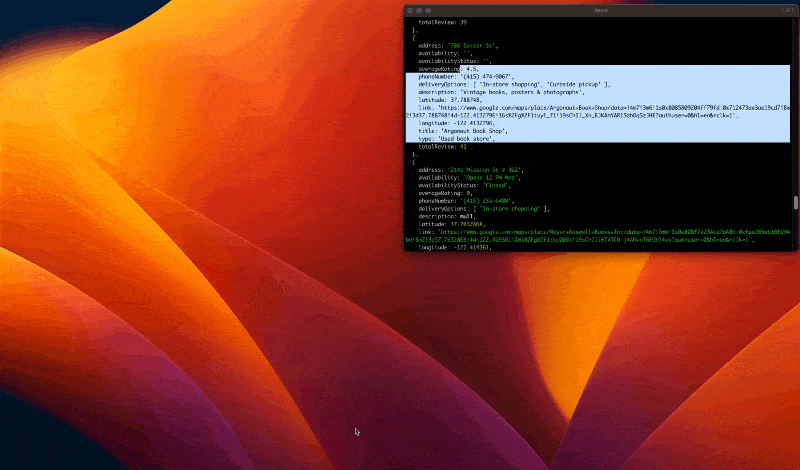
Now that we are assured our code works, we can launch the browser instance in Headless mode.
Tips on Scaling Your Google Maps Scraper
The great advantage of the scraper we wrote is that it works for any search term, such as museums, movie theaters, banks, restaurants, hospitals, etc. on Google Maps. Each search returns thousands of results from which you can collect data.
However, to keep your data up-to-date, you’ll need to run the script periodically, sending hundreds to thousands of requests every time, which can be challenging without using the proper tools.
As it is, our Google Maps scraper is very easy to detect by anti-scraping mechanisms, putting your IP at risk of getting banned.
To overcome these challenges, you must get access to a pool of high-quality proxies, prune burned proxies periodically, create a system to rotate these proxies, handle CAPTCHAs, set proper headers, and build many more systems to overcome any roadblocks.
Or you can integrate ScraperAPI into your scraper and let us take your success rate to near 100%, no matter the scale of your project.
With just a simple API call, ScraperAPI will handle CAPTCHAs, smart rotate your IPs and headers as needed, handle retries, and make your scrapers more resilient, even when sending millions of requests.
Using ScraperAPI’s Standard API to collect Google Maps information
To make our scraper work at scale with ScraperAPI, we must change how we create the browser instance and open a new page using ScraperAPI’s Google Maps data extraction API.
To connect to ScraperAPI’s servers through Puppeteer, we need the proxy server, port, username, and password. You can find this information on your dashboard.
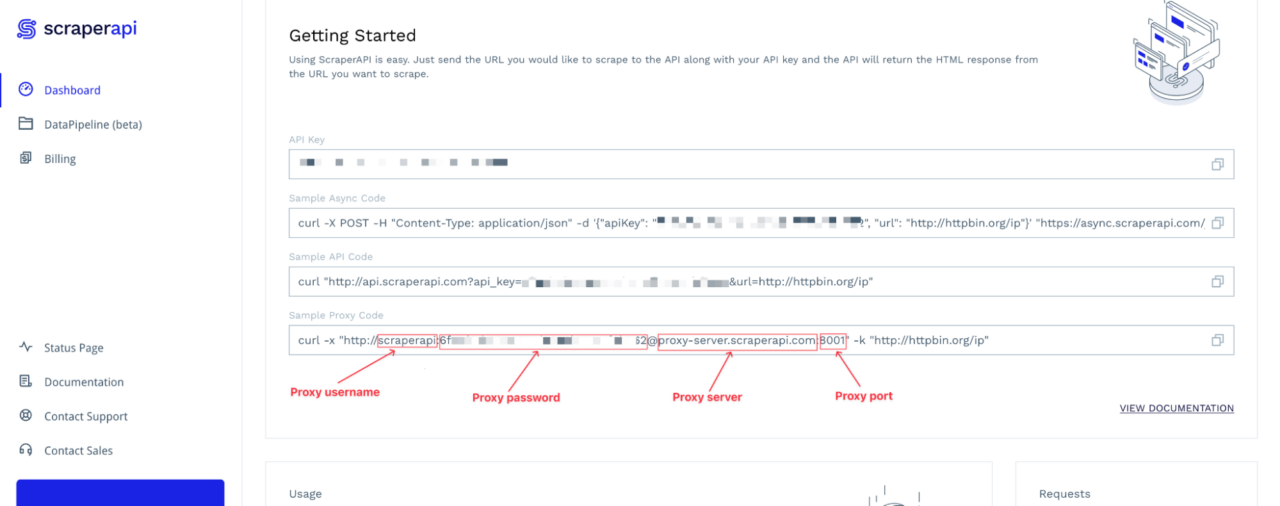
The Proxy password value is your API key.
Note: You don’t have one? Create a ScraperAPI account and get 5,000 free API credits to get started.
Here is the code to scrape Google Maps using Puppeteer and ScraperAPI proxy:
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = 'API_KEY'; // <-- enter your API_Key here
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
const main = async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: [
`--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}`
]
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
await page.setExtraHTTPHeaders({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13.5; rv:109.0) Gecko/20100101 Firefox/117.0",
});
await page.goto("https://www.google.com/maps/search/bookshop/@37.7575973,-122.5934873,12z?entry=ttu" , {
waitUntil: 'domcontentloaded',
timeout: 60000
});
// The rest of the code here
};
Run the command node index.js, you will still get the same result as before, but now, each instance you create will be seen as a new user navigating to the page.
Extracting Google Maps Data Made Easy with ScraperAPI
To recap, in this Google Maps scraper tutorial we:
- Used Puppeteer to launch a browser instance, interact with the page, and download the rendered HTML content
- Integrated ScraperAPI into our scraper to avoid getting blocked
- Parsed the HTML with Cheerio to extract the data based on DOM selectors
- Formated all our elements with a sanitize() function
This results in a list of bookshops containing all the relevant information for each business.
Here are a few ideas to scale this Google Maps scraper project:
- Increase the number of scrolls performed by Puppeteer to load more results
- Create different versions of this script to target different businesses
- Use geotargeting to find businesses in different areas and countries
- Use DataPipeline to monitor over 10,000 URLs (per project) with no-code
To learn more, check out ScraperAPI’s documentation for Node.js. For easy access, here’s this project’s GitHub repository.
Until next time, happy scraping!





