



TL;DR: Using Newspaper3k
To get started, install the Newspaper3k package:
<pre class="wp-block-syntaxhighlighter-code">pip install newspaper3k </pre >Here are some code snippets that come in handy when using the package:
- Download the page’s HTML for parsing
article.download </pre >
- Parse the HTML response to extract specific data points
</pre> <pre class="wp-block-syntaxhighlighter-code">article.parse() </pre >
- Extract all the authors from an article page
</pre> <pre class="wp-block-syntaxhighlighter-code">article.authors </pre >
- Extract the article’s published date
</pre> <pre class="wp-block-syntaxhighlighter-code">article.publish_date </pre >
- Extract the article’s text from the HTML
</pre> <pre class="wp-block-syntaxhighlighter-code">article.text </pre >
- Extract the article’s feature image
</pre> <pre class="wp-block-syntaxhighlighter-code">article.top_image </pre >
- Download any video on the article
</pre> <pre class="wp-block-syntaxhighlighter-code">article.movies </pre >
- Use natural language processing (NLP) to analyze the article before extracting additional data, allowing you to get keywords and a summary of the article
</pre> <pre class="wp-block-syntaxhighlighter-code">article.nlp() </pre >
- Extract relevant search terms from the article
</pre> <pre class="wp-block-syntaxhighlighter-code">article.keywords </pre >
- Generate a concise summary of an article
</pre> <pre class="wp-block-syntaxhighlighter-code"> article.summary </pre >Want to learn how to use all of this in a real project? Keep reading!
What is Newspaper3k?
Newspaper3k is a powerful tool for web scraping. It is a Python library that scrapes content from web pages structured like online articles.
Besides that, Newspaper3k also has other features that allow developers to parse HTML content to extract news article data like author, title, main text, publication date, and sometimes images or video content associated with the news article.
How to Scrape News Articles with Newspaper3k
To scrape a news article using Newspaper3k, start by creating a project folder and a file named index.py within it. Then, follow the steps below.
Step 1: Install the Newspaper3k Package
Install the Newspaper3k package by running the command below:
pip install newspaper3k
Step 2: Download and Parse the Article
Import the package and grab the URL from the news page you want to scrape. First, we download the article by calling the download() method on the article. Then, we parse the article by calling the method parse(), as shown below.
from newspaper import Article url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html' article = Article(url) article.download() article.parse()
Step 3: Extract the Desired News Data
The parse method we called in the previous step extracts the data from the HTML page. These data include:
- title – extracts the article title
- authors – extracts the author or list of authors of the article and returns the result in an array.
- publish_date – extracts the date and time of the publication of the article
- text – extracts the article’s textual content
- html – returns the full HTML of the page
- top_image – returns the featured image of the article (if present)
- images – returns an object containing the URL of all the images in the article
- videos – extracts all the videos in the article (if present)
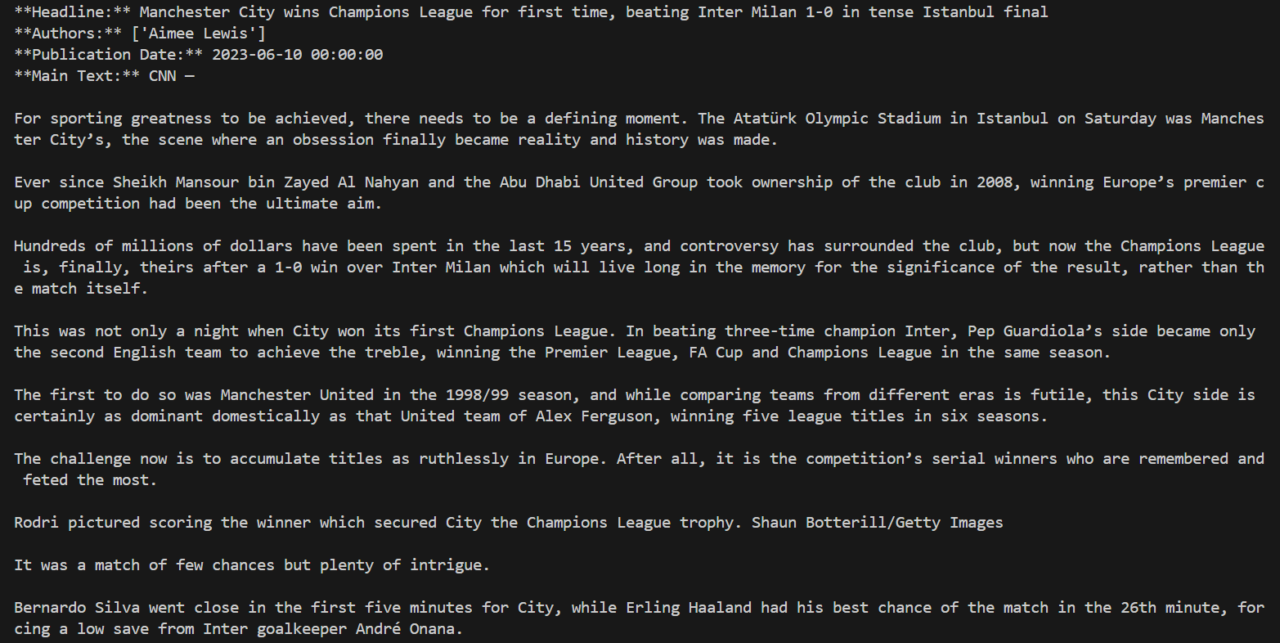
# Extract and print the desired data
print("**Headline:**", article.title)
print("**Authors:**", article.authors)
print("**Publication Date:**", article.publish_date)
print("**Main Text:**", article.text)
Run the script by running the command below.
python index.py
The result should be similar to the image below.
Step 4: Specify the News Article’s Language
The Newspaper3k package also has an embedded seamless language detection and extraction feature. This allows the developer to specify a language to use for data extraction. If no language is specified, Newspaper3k auto-detects a language and uses it by default.
Let’s see how to specify the language when scraping data:
url = 'https://www.bbc.com/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics' article = Article(url, language='zh') #Chinese
At the time of writing, Newspaper3k supports the following languages:
Your available languages are: input code full name ar Arabic be Belarusian bg Bulgarian da Danish de German el Greek en English es Spanish et Estonian fa Persian fi Finnish fr French he Hebrew hi Hindi hr Croatian hu Hungarian id Indonesian it Italian ja Japanese ko Korean mk Macedonian nb Norwegian (Bokmål) nl Dutch no Norwegian pl Polish pt Portuguese ro Romanian ru Russian sl Slovenian sr Serbian sv Swedish sw Swahili tr Turkish uk Ukrainian vi Vietnamese zh Chinese
Add Proxy Rotation in Newspaper3k Using ScraperAPI
Many newspapers and article websites use anti-bot technologies, making it difficult for the package to scrape websites at scale. Optimizing headers and using proxies to extract raw HTML data from the websites is usually inevitable in these situations.
However, a major setback of Newspaper3k is that its download functionality does not have built-in support for proxies. Therefore, an HTTP client like Python Request should be used to implement this, and then the HTML should be parsed using the Newspaper3k library.
For this example, we’ll use ScraperAPI’s scraping API</a > as a proxy solution to extract and pass the HTML content into Newspaper3k for parsing.
Note: To use the ScraperAPI Proxy Endpoint method, you must create a free ScraperAPI account to access Your API Key in your dashboard – your free trial will include 5,000 API credits, which in most cases will allow you to scrape up to 5,000 pages for free.
import requests
from urllib.parse import urlencode
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
## Download HTML using ScraperAPI Proxy
payload = {'api_key': ‘API-KEY', 'url': url}
response = requests.get('https://api.scraperapi.com', params=urlencode(payload))
## Insert HTML into the Newspaper3k article object and parse the article
article.download(input_html=response.text)
article.parse()
print("Headline: ", article.title)
print("Authors: ", article.authors)
print("Publication Date: ", article.publish_date)
With this combination, you’ll be able to scale your scrapers to millions of pages without worrying about CAPTCHAs, rate limiting, and other potential challenges.
How to Use Newspaper3k’s NLP Methods
Newspaper3k also offers a Natural Language Processing (NLP) feature. This allows developers to analyze the content before extracting it. The nlp() method can obtain the summary and keywords in the article.
The NLP method is just as expensive as the parse method. Hence, it is important to use it only when necessary. Below is a demo of how to implement the NLP method.
from newspaper import Article
url = 'https://edition.cnn.com/2023/06/10/sport/manchester-city-wins-champions-league-for-first-time-beating-inter-milan-1-0-in-tense-istanbul-final/index.html'
article = Article(url)
article.download()
article.parse()
article.nlp()
# Extract and print the desired data
print("**Text Summary:**", article.summary)
print("**Keywords: **", article.keywords)
The result should be similar to the image below.

Troubleshooting Tips for Newspaper3k NLP Method
This error may occur when implementing the nlp() method for the first time.

This error can be resolved by adding the code below to the top of the script:
import nltk
nltk.download('punkt')
After doing this, rerun the script. This script downloads the punkt package needed for the nlp function to execute. The two lines of code can then be deleted afterward without affecting the script execution.
Using Newspaper3k’s Multi-Threading Article Download Feature
This feature allows developers to extract news from multiple news sources simultaneously. Spamming a single news source with multiple threads or multiple async-io requests simultaneously will cause rate limiting. Hence, Newspaper3k provides 1-2 threads for each news source provided.
To implement the multi-threading feature for the article download feature, use the following code:
import newspaper
from newspaper import news_pool
ted = newspaper.build('https://ted.com')
cnbc = newspaper.build('https://cnbc.com')
fox_news = newspaper.build('https://foxnews.com/')
papers = [ted, cnbc, fox_news]
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 threads total
news_pool.join()
# At this point, you can safely assume that download() has been
# called on every single article for all three sources.
print(cnbc.size())
The join() method calls the download function for every article from each source. Hence, each source returns an array, and the data within each array can be accessed as shown below.
for article in cnbc.articles:
print(article.title)
Collect News Data Effortlessly with ScraperAPI Web Scraping Tool
In this newspaper and news media web scraping article, we have learned how to:
- Use Newspaper3k package to scrape newspaper and news-related articles
- Integrate Newspaper3k with ScraperAPI to scale your infrastructure in seconds
- Use the nlp() method to extract relevant search terms and generate a summary for each article
The package provides a few more features, including the hot and popular_url methods on the newspaper package. These methods return the trending terms and popular news sources, respectively. You can check out its official documentation</a > to learn more about this package.
If you want to learn more about scraping with Python, check out some of these resources:
- Beginner’s Guide to Python Scraping
- How to Scrape Google Search Results with Python
- Scrape Tables from Web Pages Using Python
Until next time, happy scraping!




