


In this web scraping tutorial, we will cover how to scrape product data from Amazon using Node.js and Puppeteer.
Today’s ecommerce landscape is driven by data-driven decision-making. Online stores and retailers increasingly rely on fresh, reliable product and pricing information from various sources, including Amazon. By scraping data from Amazon, ecommerce businesses can gain valuable insights to optimize their product and pricing strategies and enhance customer experiences.
Additionally, scraping Amazon product listings allows you to:
- Assess product competition
- Evaluate competitors’ listings to adjust your marketing strategy
- Find pricing trends and opportunities
- Analyze competitors’ reviews to find improvement opportunities
- Compare product features against competitors to build a winning product offer
- Collect market data to find trending products
- And much more.
In other words, collecting Amazon data will give you a competitive advantage and help you create a better eCommerce strategy for market domination.
But how can you collect Amazon data at scale?
In this article, we’ll show you how to scrape Amazon products using Node.js and Puppeteer in two ways:
- Collect Amazon product information using Node.js and Puppeteer (a traditional, more time-consuming data aggregating option).
- Extract Amazon product data using ScraperAPI (a more accessible and scalable data extraction approach).
Building an Amazon Data Scraper in Node.js and Puppeteer (Traditional Method)
Before we start our project, it’s important to remember that this approach is great for small Amazon data scraping jobs. Still, without using supportive web scraping tools to overcome anti-bot systems, you’ll quickly get blocked if you try to collect Amazon data at scale.
Note: to scale our project to a large data set, we’d have to build an infrastructure capable of bypassing Amazon’s anti-bot system, IP blocks, and parsing acquired data. Don’t want the hassle? Skip to this step and start scraping in minutes.
After you take care of that, let’s review the web scraping tools you’ll need to build a simple Amazon product scraper.
Step 1. Check the Prerequisites
Before diving deeper into this Amazon data aggregation tutorial, ensure these tools are installed.
- Node.js 18+ and NPM — Download the newest version if you don’t have one
- Puppeteer — a powerful API to control a Chrome/Chromium instance.
Note: Take a look at our Node.js web scraping for beginners tutorial if you’d like a quick overview of the basics.
Step 2. Set up a Project for Scraping Amazon Product Listings
Let’s start with creating a folder that will hold the code source of the Amazon web scraper.
mkdir node-amazon-scraper
Once done, initialize a Node.js project by running the command below:
cd node-amazon-scraper
npm init -y
The last command will create a package.json file in the folder. Next, create a file index.js and add a simple JavaScript instruction inside.
touch index.js
echo "console.log('Hello world!');" > index.js
Execute the file index.js using the Node.js runtime.
This command will print Hello World! in the terminal.
Step 3. Install Puppeteer for Web Scraping
Puppeteer provides several functions for web scraping. Installing it automatically downloads a recent version of the Chrome browser that can take around 200MB of disk space.
Run the following command to install it:
npm install puppeteer
We’ll take a screenshot of a web page to see Puppeteer in action.
Let’s update the file index.js with the following code:
const puppeteer = require('puppeteer');
const PAGE_URL = "https://amazon.com";
const SAVE_PICTURE_PATH = "./amazon-homepage.png";
const main = async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto(PAGE_URL);
await page.screenshot({ path: SAVE_PICTURE_PATH, type: 'png' });
await browser.close();
}
main();
On the code above, we’re telling Puppeteer to:
- Create an instance of the browser
- Open a new page
- Navigate to the Amazon home page
- Take a screenshot of the page
- Store it on the disk
Once done, it closes the browser instance.
If you browse the project directory, you will see the file amazon-homepage.png.
Step 4. Identify the Information to Retrieve on the Amazon Product Page
We will use the Amazon listing results for the “MacBook Pro” search term and retrieve the product title and price.
Navigate to Amazon and search for the term. Then, inspect the page to see the DOM structure. Next, find the selector related to this information.
The picture below shows the location of the product title and price in the DOM.
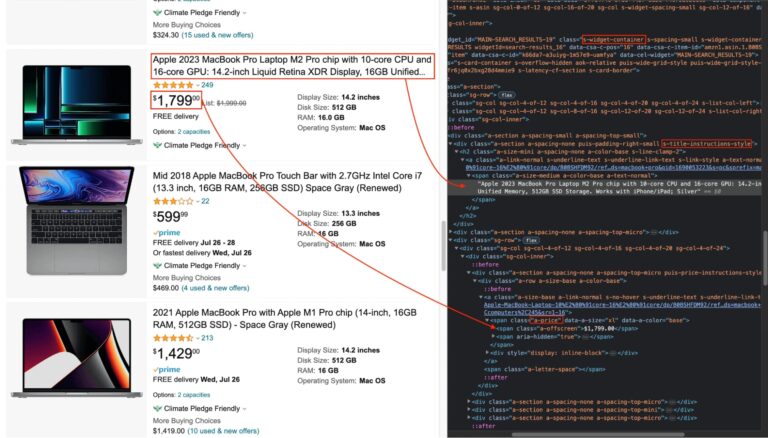
From there, we can match each piece of information with the corresponding DOM selector. Here’s a table with the selectors we’ll be using:
| Information | DOM selector | Description |
| Product container | s-widget-container | A product item in the results list |
| Product’s title | s-title-instructions-style | Title of the product/td> |
| Product’s price | a-price | Product’s price |
The product’s title and price selector are far from the DOM element because you must find unique selectors to avoid duplicates. You can use DOM traversal to find the child element containing the element (you’ll see it later while implementing the code).
Step 5. Scrape the Amazon Product Page
Now, let’s download the HTML content of the results page using the following code – update your index.js file with it:
const puppeteer = require('puppeteer');
const PAGE_URL = 'https://www.amazon.com/s?k=macbook+pro&i=computers&sprefix=macbo%2Ccomputers%2C245&ref=nb_sb_ss_ts-doa-p_2_5';
const main = async () => {
const browser = await puppeteer.launch({ headless: 'new' });
const page = await browser.newPage();
await page.goto(PAGE_URL);
const html = await page.content();
await browser.close();
console.log(html)
}
main();
Run the code with the command node index.js, and the HTML content of the page will be printed in the terminal.
Step 6. Extract Information From the HTML
Of course, in its raw HTML form, this data is practically unusable, so we’ll need to parse the response in order to extract any specific data point
For this task, we’ll use Cheerio, a flexible implementation of jQuery. This library allows you to use jQuery’s familiar and simple syntax to manipulate the HTML content.
First, install it using the following command:
npm install cheerio
Next, update the file index.js to extract the content with Cheerio, put it in an array, and sort products from the highest to the lowest price.
const puppeteer = require('puppeteer');
const cheerio = require("cheerio");
const PAGE_URL = 'https://www.amazon.com/s?k=macbook+pro&i=computers&sprefix=macbo%2Ccomputers%2C245&ref=nb_sb_ss_ts-doa-p_2_5';
const main = async () => {
const browser = await puppeteer.launch({ headless: 'new' });
const page = await browser.newPage();
await page.goto(PAGE_URL);
const html = await page.content();
await browser.close();
const $ = cheerio.load(html);
const products = [];
$('.s-widget-container').each((i, element) => {
const titleElement = $(element).find('.s-title-instructions-style');
const priceElement = $(element).find('.a-price > span').first();
const title = titleElement.text();
const price = parseInt(priceElement.text().replace(/[$,]/g, ""), 10);
if (!title || isNaN(price)) {
return;
}
products.push({
title,
price,
priceInDollarFormat: priceElement.text(),
})
});
const sortedProducts = products.slice().sort((p1, p2) => p2.price - p1.price);
console.log(sortedProducts);
}
main();
We used the selector we identified earlier to find the information in the HTML content of the product page. Now — run the code to see the result.
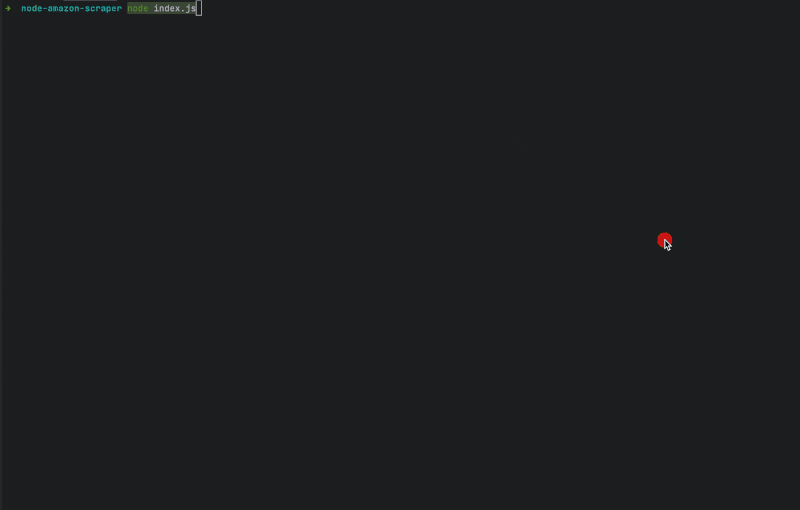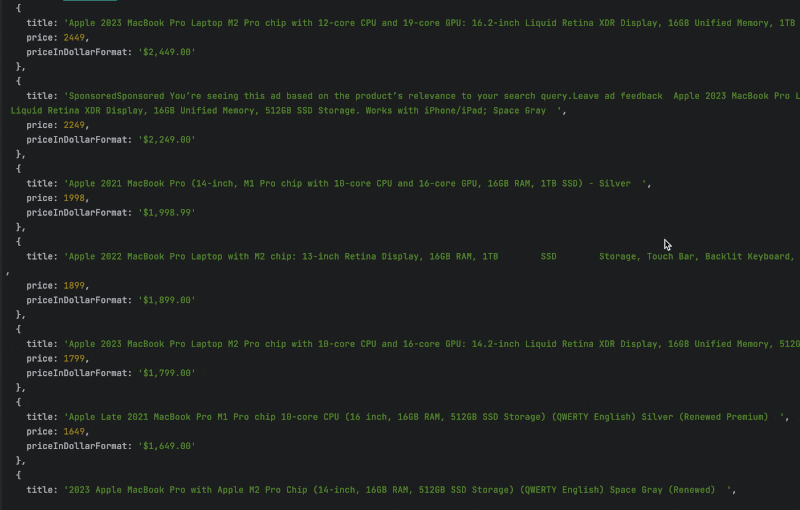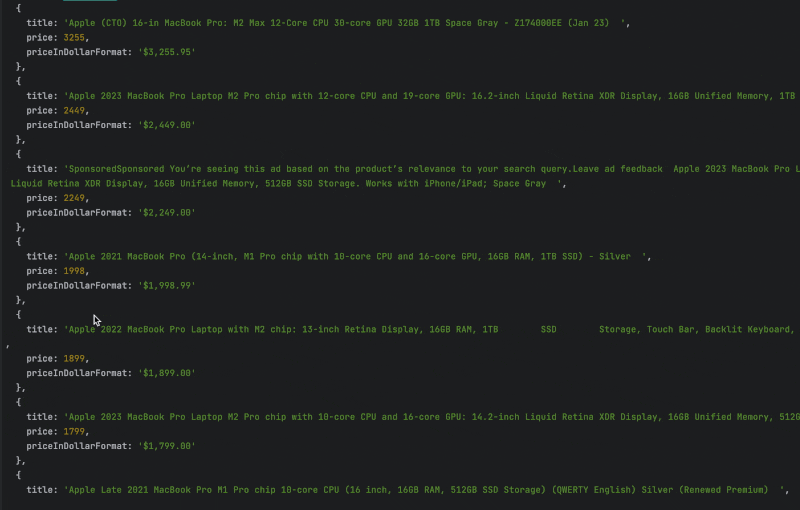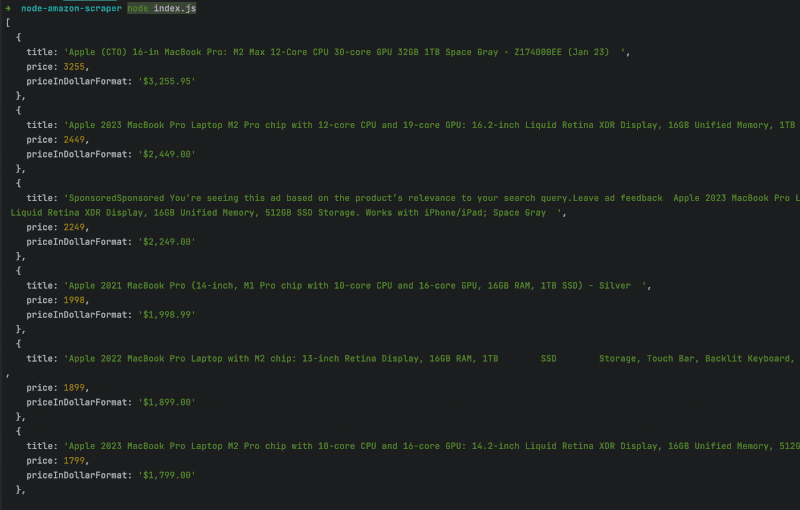
That’s it — the Amazon data you wanted to scrape is now in your hand!
However, there’s still a big challenge to resolve: to prevent abuse from bots, Amazon has advanced bot protection features that ask for CAPTCHA verification or ban an IP address for sending too many requests to the server – just to mention a few techniques.
This makes it impossible to scrape at a significant scale, automate scraping, and schedule scrapers to run at specific intervals.
The good news is that we can automatically handle all of these issues by using ScraperAPI.
With just a simple API call, ScraperAPI rotates your IP address – when needed – from a pool of over 40M curated proxies across 50+ countries, it handles CAPTCHAs and uses machine learning to bypass any anti-scraping mechanism in your way.
That said, there’s one more reason we’ll be using it for this scenario.
Scrape Amazon Products at Scale With ScraperAPI
Extracting Amazon data in Node.js is suitable for small, infrequent scraping projects. However, for frequent or large-scale scraping, a robust web scraping solution like ScraperAPI offers significant advantages. Two key benefits include:
- DataPipeline – This no-code solution allows you to automate and schedule web scraping jobs (visually or using cron scheduling) to retrieve data periodically.
- Amazon Structured Data Endpoint – Integrating this endpoint into your project will send your request through ScraperAPI servers, returning every Amazon page in structured JSON format.
These ScraperAPI tools have integrated unique know-how and mechanisms to collect Amazon product data without getting blocked.
Also, the tool constantly updates its code to account for changes in the page structure or new blockers, significantly decreasing the time to insights.
Scraping Amazon with ScraperAPI is a simple process, and you can do it in two ways:
- Creating a new no-code project — it’s the top choice if you want to get data straight away and need to outsource scraping to a hosted (managed) platform.
- Using ScraperAPI’s API key – if you want to integrate it with your code infrastructure.
Let’s first see how to get structured Amazon data with DataPipeline, as it’s the easiest way to get data at scale and high speed.
Step 1. Creating a No-Code Project With ScraperAPI
First, create a free ScraperAPI account to access the tool – you’ll also get 5,000 free API credits.
Next, create a new no-code project.
Once inside, you’ll see several methods to get started. Pick the Amazon Product Pages template.
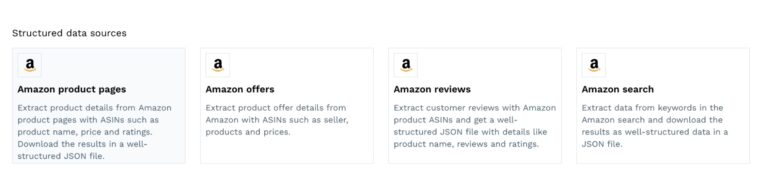
This template uses the product Amazon Standard Identification Numbers (ASINs) as input to start the scraping job. If you’re unsure how to find them, we created a step-by-step tutorial to scrape thousands of Amazon product ASINs in minutes.
If your list is ready, you can submit it by pasting the ASINs in the text box or uploading a file.

And that’s it. You can now run your project and let ScraperAPI take care of the rest.
After the job is finished, you’ll receive your data directly to your set Webhook or download it as a file from your project’s dashboard.

You can access your scraping jobs from the projects tab and receive custom notifications to track their success.
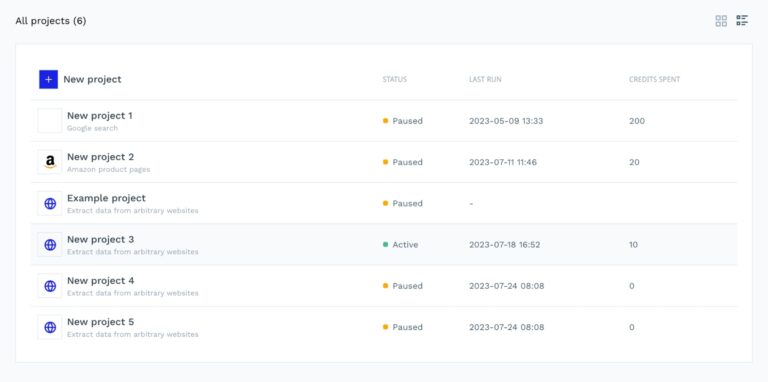
Of course, you can also configure DataPipeline to your needs by specifying parameters like top-level domains (e.g., “.com.au”, “.es”) to target, the location of the proxies you want to use (to collect localized data), set up scraping intervals, etc.
Step 2. Using the API to Collect Amazon Data
Integrating ScraperAPI into your codebase is quite simple, and it doesn’t require a different account. You can access your API key and DataPipeline using the same account. Learn more about scraping Amazon with ScraperAPI.
Navigate to your dashboard to find your key under Getting Started.
With the structured data endpoint for Amazon, you can retrieve product details, reviews, and offers from any product ASIN (there’s also an endpoint to scrape Amazon Search using search terms).
Here are the steps to use them:
- Find the Structured data endpoint URL to call (product, review, search, or offer)
- Prepare the request body requiring the ASIN (or search terms), the API key, and the target country
- Send the request and use the response to do whatever you want with the data.
Step 3. Retrieving Data from Amazon Product Listings
Let’s see how you can extract Amazon product data using ScraperAPI’s structured data endpoints.
First, you’ll need an HTTP client to send the request and the Node.js code.
We’ll use Axios — let’s install it first.
npm install axios
Let’s start by getting a list of products using the Amazon Search structure endpoint and search the keyword Mackboo Pro.
In your project, create a file structured-data.js and add the code below:
const axios = require("axios");
const API_KEY = '';
const searchProducts = async (keywords) => {
const API_SEARCH_URL = 'https://api.scraperapi.com/structured/amazon/search';
const payload = {
api_key: API_KEY,
query: keywords,
country: 'us'
};
const searchParams = new URLSearchParams(payload);
const response = await axios.get(`${API_SEARCH_URL}?${searchParams}`);
return response.data;
};
const main = async () => {
const result = await searchProducts('Macbook Pro');
console.log(result);
};
- Replace
your-api-key-herewith your ScraperAPI key - Execute the code with the command:
node structured-data.js
You must get the following output:
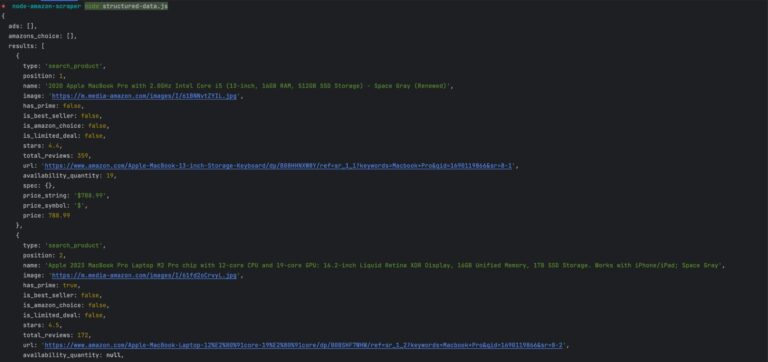
The response provides helpful information about the product, and for full details, you can use the dedicated endpoint.
The search response contains URLs for the paginated page, which is great for retrieving all the search results.
Step 4. Collecting Amazon Product Reviews
You can use a dedicated endpoint in ScraperAPI to get a list of reviews from Amazon in a well-structured file.
https://api.scraperapi.com/structured/amazon/review
Let’s retrieve all the reviews for the first product from the search result list.
First, find the product ASIN which can be extracted from the product URL.
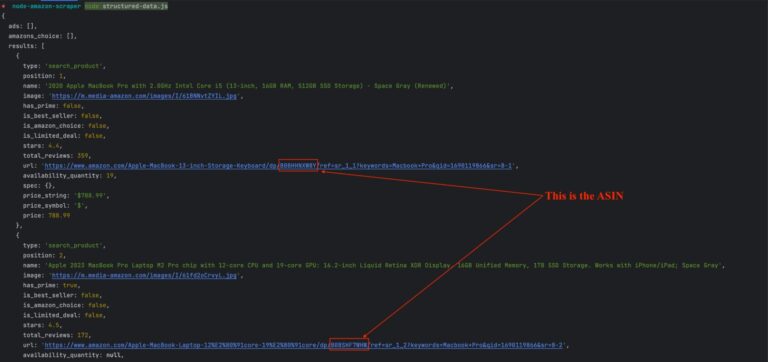
You can use a function to extract it from the URL and send a request to retrieve the reviews for this product.
Replace the content structured-data.js with the code below:
const findProductReviews = async (productId) => {
const API_REVIEW_URL = 'https://api.scraperapi.com/structured/amazon/review';
const payload = {
api_key: API_KEY,
asin: productId,
country: 'us'
}
const searchParams = new URLSearchParams(payload);
const response = await axios.get(`${API_REVIEW_URL}?${searchParams}`);
return response.data;
};
const extractASIN = (productURL) => {
return productURL.match(/\/([A-Z0-9]{10})(?:[/?]|$)/)[1];
};
const main = async () => {
const searchResult = await searchProducts('Macbook Pro');
console.log(`The search returned ${searchResult.results.length} products`);
const firstProduct = searchResult.results[0];
console.log(`Retrieve reviews for the product [${firstProduct.name}]`);
const firstProductASIN = extractASIN(firstProduct.url);
console.log(`The product ASIN is: ${firstProductASIN}`);
const reviewResult = await findProductReviews(firstProductASIN);
console.log(reviewResult);
};
main();
Run the code, and you’ll get the following output:

As for the search response, there are URLs for the paginated page to retrieve all the reviews.
Scraping Amazon Product Data is Easy with ScraperAPI
Collecting Amazon product listings using Node.js is great, but this isn’t the most efficient way. There are many factors that can negatively impact your web scraping project success. To simplify Amazon product data scraping, adopt ScraperAPI.
With ScraperAPI as your web scraping tool, not only you are free from getting blocked, but you can also enjoy the DataPipeline and Structured Data Endpoints web scraping solutions.
ScraperAPI’s DataPipeline allows you to automate web scraping jobs in a few minutes with near-zero development time. It’s as easy as adding the parameters, submitting your list of ASINs or search terms, and clicking start scraping. Each project can monitor up to 10,000 Amazon pages, and there’s no limit to the number of projects you can create.
If you already have a running web scraping infrastructure you’d like to keep but want to increase its success rate while working with a simpler data format, then our Amazon Structured Data Endpoints will be a perfect fit.
The good news is that you can try both of them for free for 7 days by signing up here. Try them out, and let us know what you think!
Until next time, happy scraping!
Additional Information for Scraping Amazon Product Listings
- Check out the ScraperAPI’s documentation to see what you do with it.
- Find the code source of this post on this GitHub repository.
- 10 Best Rotating Proxies For Amazon Web Data Scraping
- Scrape Amazon Reviews: How to Scale the Process
- Scrape Amazon ASIN: How to Do It at Scale
