



TL;DR: The Full Script for eBay Product Review Python Scraper
For those in a hurry, here’s the complete eBay product review web scraping script we’ll be building:
from bs4 import BeautifulSoup
import requests
import json
API_KEY = "YOUR_API_KEY"
url = "https://www.ebay.com/itm/185982388419?hash=item2b4d6a08c3:g:4soAAOSw0gJkrbma&var=694001364789"
reviews = []
def request_function(url):
payload = {"api_key": API_KEY, "url": url}
response = requests.get("http://api.scraperapi.com", params=payload).text
return response
def organize_data(product_name:str, product_price:str, reviews_list:list):
result = {
"product_name" : product_name,
"product_price" : product_price,
"reviews" : reviews_list
}
output = json.dumps(result, indent=2, ensure_ascii=False).encode("ascii", "ignore").decode("utf-8")
try:
with open("output.json", "w", encoding="utf-8") as json_file:
json_file.write(output)
except Exception as err:
print("Encountered an error: {e}")
response = request_function(url)
soup = BeautifulSoup(response, "lxml")
PRODUCT_NAME = soup.find("span", class_="ux-textspans ux-textspans--BOLD").text
PRODUCT_PRICE = soup.find("div", class_="x-price-primary").text.split(" ")[-1]
feedback_url = soup.find("a", class_="fdbk-detail-list__tabbed-btn fake-btn fake-btn--large fake-btn--secondary").get('href')
soup = BeautifulSoup(request_function(feedback_url), "lxml")
received_reviews = soup.find_all('div', class_="card__comment")
user_and_rating = soup.find_all('div', class_="card__from")
for each in range(len(received_reviews)):
review = {
"User" : user_and_rating[each].text.split('(')[0],
"Rating" : user_and_rating[each].text.split("(")[-1].rstrip(")"),
"User_Review" : received_reviews[each].text,
"Review_Time" : soup.find('span', {'data-test-id': f'fdbk-time-{each + 1}'}).text
}
reviews.append(review)
organize_data(PRODUCT_NAME, PRODUCT_PRICE, reviews)
If you’re eager to dive into the code right away, be sure to sign up for a free ScraperAPI account to obtain YOUR_API_KEY, which you will need when running the script.
How Does eBay Product Review Work?
To get started, we need to provide our scraper a URL to collect data from.
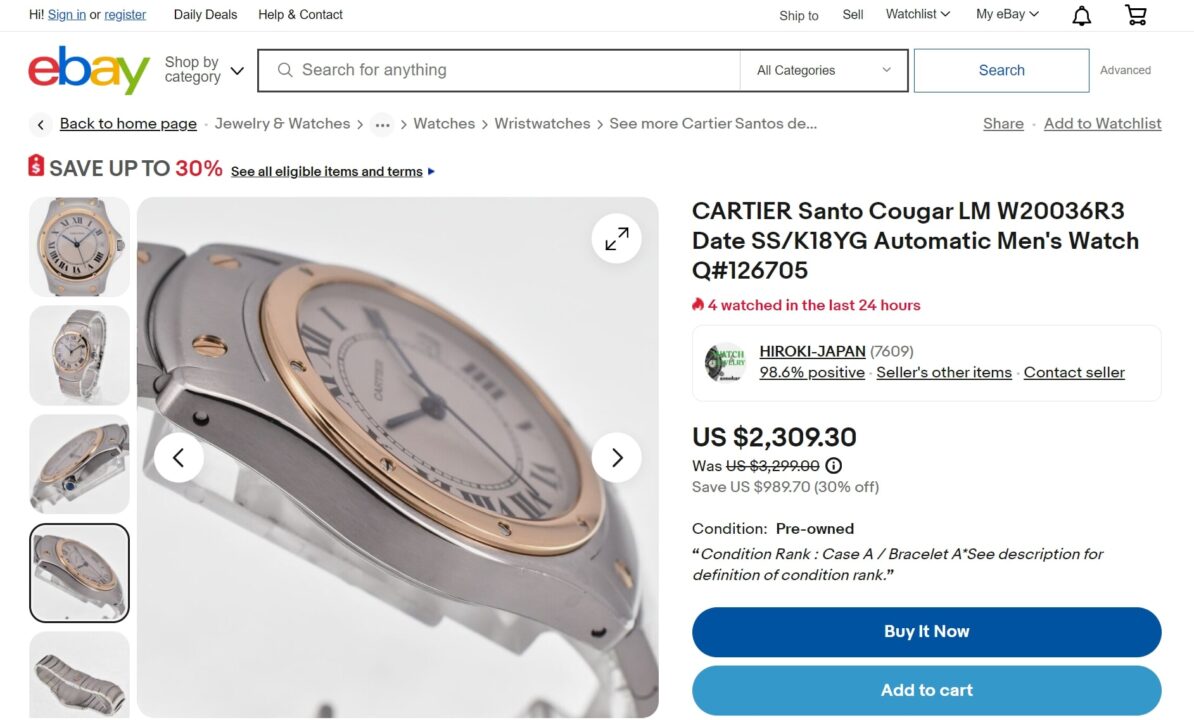
We’ll get some of the information on this page, like the product name and the product price, but that’s not all. At the lower part of the page, you should see a button that allows you to read all the reviews received by the seller on the product and the service rendered.
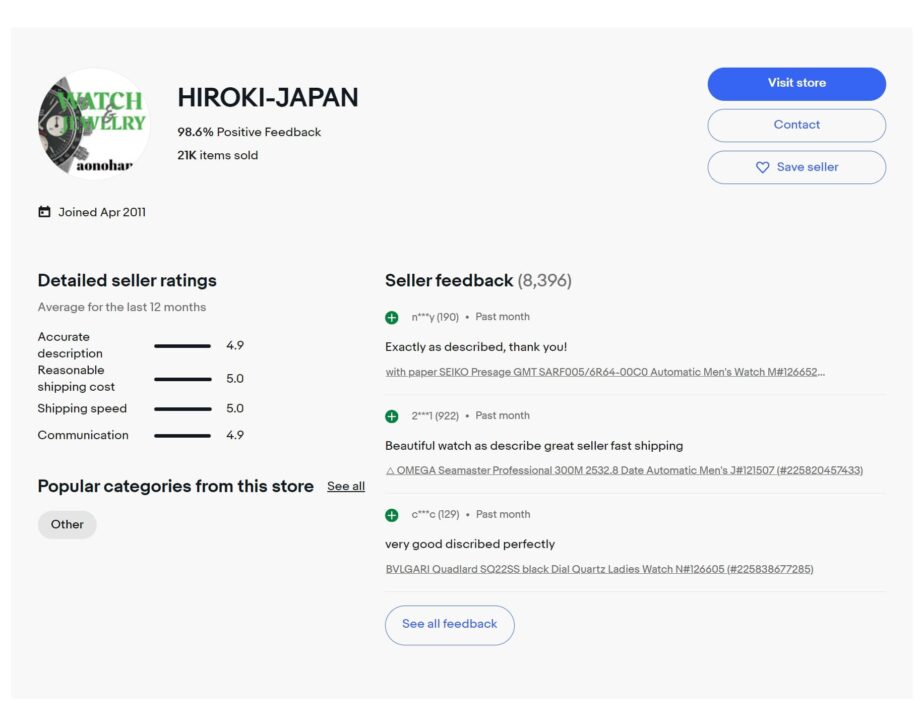
Clicking the button will take you to a page similar to the one in the image below.
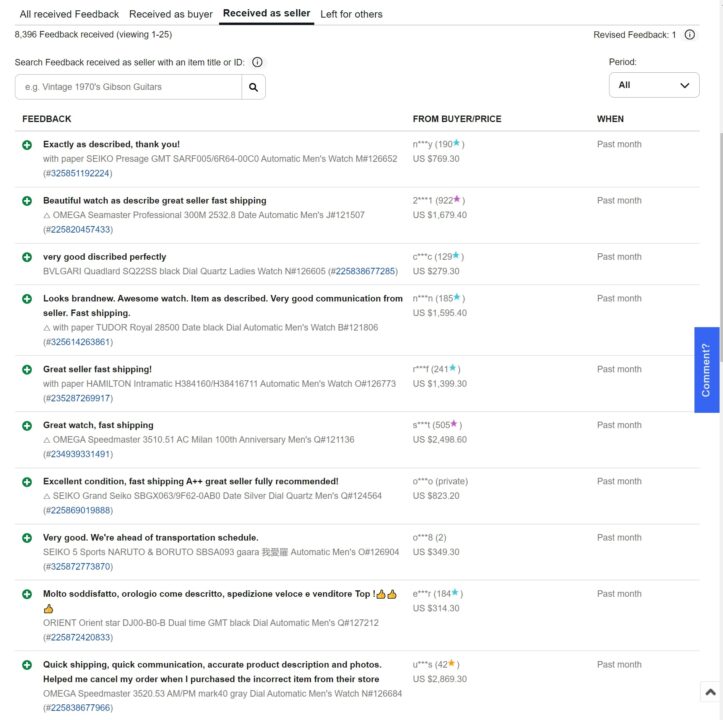
The final piece of the information that we need is on this page.
To avoid getting blocked, you’ll need to add your ScraperAPI’s API_KEY, as well as the URL of the product whose reviews you want to collect.
Enough of the explanations, let us jump into our IDE and get coding!
Scraping eBay for Product Reviews Using Python
Our focus here is on scraping the most recent reviews of a product on eBay, and to achieve this, we’ll need to use:
- Python
Requestmodule to send HTTP requests to the eBay product page to pull its HTML BeautifulSoupandlxmlto parse the responsejsonto properly format the data into a JSON file
Prerequisites of Extracting Product Reviews from eBay
This guide requires a basic understanding of Python – and of course, you need to have it installed on your machine.
As mentioned earlier, you will also need a couple of Python modules to build this, which you can install using the command below:
pip install beautifulsoup4 requests lxml
Note: You do not have to install json because it is a Python built-in package.
Next, let’s create a folder for this project and a .py file for the script.
You can achieve all of the above by executing these commands in your command prompt:
mkdir ebay-scraper
cd ebay-scraper
type nul > scraper.py
Now that everything has been installed, we can proceed to build each segment of our scraper tool.
Step 1: Setting Up Our eBay Scraping Project
Before we begin to write any logic, first, we need to import BeautifulSoup, json, and requests into our Python file.
from bs4 import BeautifulSoup
import requests
Import json
We also have to create 3 variables:
- The first will contain
YOUR_API_KEY. - The
URLvariable will hold the link to the product page we wish to scrape. - The
reviewslist will hold the reviews we have scraped.
API_KEY = '5bc85449d28e162fb0416d6c5b4ac5b0'
url = "https://www.ebay.com/itm/185982388419?hash=item2b4d6a08c3:g:4soAAOSw0gJkrbma&var=694001364789"
reviews = []
Step 2: Send the Request and Parse the HTML
Whenever we make a request to a product page, we receive the page’s HTML in return. Since this process is a repetitive one, writing a function dedicated to performing that action makes everything easier.
from bs4 import BeautifulSoup
import requests
Import json
This function is responsible for sending the request through ScraperAPI, alongside the URL and the API_KEY.
Now, we can create a variable, response, to catch the return value from the call we made to request_function().
response = request_function(url)
soup = BeautifulSoup(response, "lxml")
To complete this process, we pass the response into BeautifulSoup for parsing, capturing the response in a soup object.
Step 3: Extract eBay Product Reviews from the HTML
Building on the foundation laid in Step 2, we can now use the soup variable for the product name and its price.
Since we are looking for the first occurrence of a span element with class ux-textspans ux-textspans--BOLD and x-price-primary for the product name and product price, respectively, we have to use the find() method instead of find_all().
We also have to get the text element contained therein to get what we were looking for.
PRODUCT_NAME = soup.find("span", class_="ux-textspans ux-textspans--BOLD").text
PRODUCT_PRICE = soup.find("div", class_="x-price-primary").text.split(" ")[-1]
Note: The product price needed a little work. We had to split the text into multiple elements and grab the last one using [-1]. This way, we are left with $XX.XX for the price and not some unnecessary text.
To get the feedback URL, let’s target the href attribute within the a tag with the class fdbk-detail-list__tabbed-btn fake-btn fake-btn--large
fake-btn--secondary</code
>.
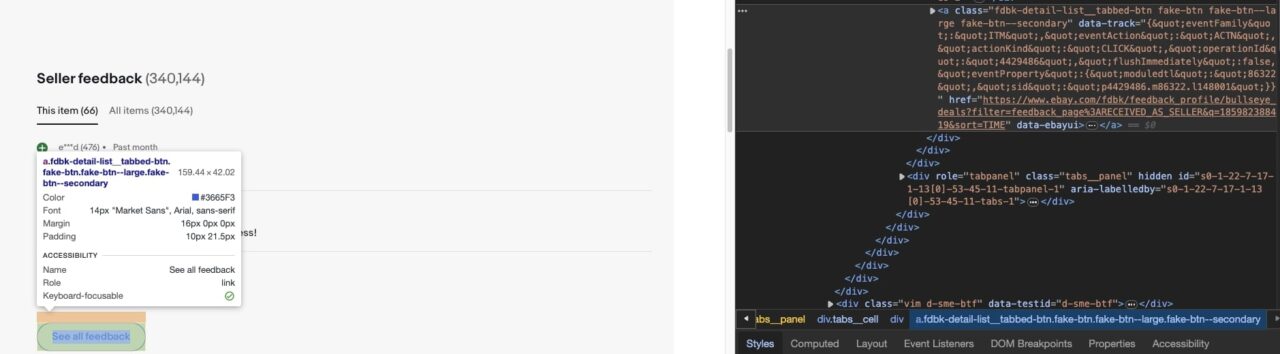
feedback_url = soup.find("a", class_="fdbk-detail-list__tabbed-btn fake-btn fake-btn--large fake-btn--secondary").get('href')
Step 4: Extract the Desired Information
Now that we have the URL containing the reviews, we can send a request to receive the HTML of the feedback page that we will parse to extract all product reviews.
To do so, we’ll:
- Send a request to the
feedback_urlthroughrequest_function() - Pass the response into the
BeautifulSoupinstance we created earlier
Note: Essentially, we are overwriting the information in soup with the HTML generated from the feedback page.
- Use the BeautifulSoup
find_all()method to locate every occurrence of the div element withcard__commentandcard__fromclass in the HTML - The response generated will be a list, which we will pass into
received_reviewsanduser_and_rating, respectively
soup = BeautifulSoup(request_function(feedback_url), "lxml")
received_reviews = soup.find_all('div', class_="card__comment")
user_and_rating = soup.find_all('div', class_="card__from")
- Loop through
received_reviewsto get the index of each review and use it to locate the review that matches a particular user, user review, and rating of the product in thereceived_reviewsanduser_and_ratinglists.
💡 Important
For this to work properly, we have to do a couple of string manipulations, like splitting the string in
user_and_ratingso that we can get the rating and the username separately.The
rstrip()method strips everything to the right of the closing parenthesis.
for each in range(len(received_reviews)):
review = {
"User" : user_and_rating[each].text.split('(')[0],
"Rating" : user_and_rating[each].text.split("(")[-1].rstrip(")"),
"User_Review" : received_reviews[each].text,
"Review_Time" : soup.find('span', {'data-test-id': f'fdbk-time-{each + 1}'}).text
}
reviews.append(review)
- Finally, to get when the review was actually made, we examine the HTML in soup for every span element with the attribute seen above. Each span element found has a
data-test-idattribute, and since each attribute is marked with an index, we use the formatted string to locate each one using the index from the loop increased by one because it starts with 1, not 0.
All of this information is added to a dictionary, review, appended to reviews at the end of the loop, and viola, we are done extracting our product reviews.
Obviously, extracting the information is not enough, we need to organize this data and, in our case, write the organized data into a JSON file.
Step 5: Organize and Write the Results to a JSON file
def organize_data(product_name:str, product_price:str, reviews_list:list):
result = {
"product_name" : product_name,
"product_price" : product_price,
"Reviews" : reviews_list
}
output = json.dumps(result, indent=2, ensure_ascii=False).encode("ascii", "ignore").decode("utf-8")
try:
with open("output.json", "w", encoding="utf-8") as json_file:
json_file.write(output)
except Exception as err:
print("Encountered an error: {e}")
The organize_data() function is responsible for writing the data into a JSON file, starting with the product name, followed by the product price, and finally, we add the list of reviews in the file as well.
To do this, we had to create a Python dictionary, result, which holds all the information we want to write in the file.
Once this dictionary has been created, we must convert it into JSON using the dumps() method.
Writing to the JSON file is tricky. There are special characters used by users to express their pleasure/displeasure about the product they received. When you scrape the reviews, which sometimes include emojis, it shows the unicode, not the emojis.
To remove it so we get clean data, we need to set the ensure_ascii flag in json.dumps() to False, as shown in the code snippet above – doing this gives us the clean data that we need.
After this is done, open a file with the JSON extension and write the data into it.
💡 Important
Defining
organize_data()doesn’t imply automatic execution. To trigger its operation, we must invoke the function with the product name, product price, and the previously generated reviews.
Upon completion, your output should look like the result below:
{
"product_name": "Shipping and returns",
"product_price": "$179.55/ea",
"reviews": [
{
"User": "l***e",
"Rating": "56",
"User_Review": "Thanks ",
"Review_Time": "Past month"
},
{
"User": "a***r",
"Rating": "33",
"User_Review": "Ordered an older product by mistake. Couldn't sync with me main computer. Return was easy. Good vendor",
"Review_Time": "Past month"
},
{
"User": "i***0",
"Rating": "190",
"User_Review": "The purchase was not the right product for me. Seller made my return quick and easy.",
"Review_Time": "Past month"
},
{
"User": "u***e",
"Rating": "2",
"User_Review": "Better than I expected and totally worth it.",
"Review_Time": "Past month"
},
{
"User": "w***o",
"Rating": "21",
"User_Review": "its over all good but the battery died fast ",
"Review_Time": "Past month"
},
{
"User": "r***7",
"Rating": "130",
"User_Review": "As described and works good ",
"Review_Time": "Past month"
},
{
"User": "s***s",
"Rating": "2",
"User_Review": "This is savage better than brand new.",
"Review_Time": "Past 6 months"
},
{
"User": "u***r",
"Rating": "4",
"User_Review": "Wowgood condition I love it thank you so much ",
"Review_Time": "Past 6 months"
},
{
"User": "t***e",
"Rating": "492",
"User_Review": "I bought this laptop for my grandson. He loves it.",
"Review_Time": "Past 6 months"
},
{
"User": "k***b",
"Rating": "11",
"User_Review": "Great",
"Review_Time": "Past 6 months"
},
{
"User": "8***j",
"Rating": "636",
"User_Review": "Good Seller A++++++++++++++++",
"Review_Time": "Past 6 months"
},
{
"User": "n***n",
"Rating": "1747",
"User_Review": "Fast delivery. As described. No problems. Thanks!",
"Review_Time": "Past 6 months"
},
{
"User": "1***r",
"Rating": "16",
"User_Review": "item came in perfect condition and before expected five stars ",
"Review_Time": "Past 6 months"
},
{
"User": "o***s",
"Rating": "292",
"User_Review": "Awesome ",
"Review_Time": "Past 6 months"
},
{
"User": "g***u",
"Rating": "5",
"User_Review": "Great - efficient delivery & packaging. Great condition. ",
"Review_Time": "Past 6 months"
},
{
"User": "o***h",
"Rating": "8",
"User_Review": "The computer was delivered quickly. The quality is excellent. I recommend this seller for shopping from him.",
"Review_Time": "Past 6 months"
},
{
"User": "0***9",
"Rating": "1",
"User_Review": "Excellent customer services. ",
"Review_Time": "Past 6 months"
},
{
"User": "r***g",
"Rating": "122",
"User_Review": "All I have to say is that the quality is amazing!!! Spoke to the seller with a few questions, and he responded very quickly also really fast shipping. I would definitely buy again from this seller. ",
"Review_Time": "Past 6 months"
},
{
"User": "j***c",
"Rating": "158",
"User_Review": "Good Seller",
"Review_Time": "Past 6 months"
},
{
"User": "e***0",
"Rating": "340",
"User_Review": "Product is in good condition. The shipping in the listing said 2 day free FedEx shipping. It took 8 days. One of those days was a holiday so I understand that but it didn't actually ship for 4 or 5 days after I hit buy it now. Contacted seller to ask if it could go out next day air and was just told a delivery date and no resolution. ",
"Review_Time": "Past 6 months"
},
{
"User": "r***r",
"Rating": "2",
"User_Review": "This MacBook Air has been a new experience for me, as I have always used IBM DOS and Microsoft OS systems. The experience has been great and I really enjoy the MacBook Air and it has operated flawlessly. ",
"Review_Time": "Past 6 months"
},
{
"User": "4***4",
"Rating": "1",
"User_Review": "amazing communication and fast shipping",
"Review_Time": "Past 6 months"
},
{
"User": "s***m",
"Rating": "239",
"User_Review": "A+++",
"Review_Time": "Past 6 months"
},
{
"User": "u***a",
"Rating": "187",
"User_Review": "Good item fast delivery ",
"Review_Time": "Past 6 months"
},
{
"User": "t***7",
"Rating": "2193",
"User_Review": "ok",
"Review_Time": "Past 6 months"
}
]
}
Full Scraping Code of eBay Product Review Phyton Scraper
Now that the groundwork has been laid, and all the necessary components are in order, let’s piece together the complete scraping code.
This consolidated code will integrate all the techniques and steps we’ve covered, providing a streamlined approach to gather the reviews from eBay product pages in one go.
from bs4 import BeautifulSoup
import requests
import json
API_KEY = "YOUR_API_KEY"
url = "https://www.ebay.com/itm/185982388419?hash=item2b4d6a08c3:g:4soAAOSw0gJkrbma&var=694001364789"
reviews = []
def request_function(url):
payload = {"api_key": API_KEY, "url": url}
response = requests.get("http://api.scraperapi.com", params=payload).text
return response
def organize_data(product_name:str, product_price:str, reviews_list:list):
result = {
"product_name" : product_name,
"product_price" : product_price,
"reviews" : reviews_list
}
output = json.dumps(result, indent=2, ensure_ascii=False).encode("ascii", "ignore").decode("utf-8")
try:
with open("output.json", "w", encoding="utf-8") as json_file:
json_file.write(output)
except Exception as err:
print("Encountered an error: {e}")
response = request_function(url)
soup = BeautifulSoup(response, "lxml")
PRODUCT_NAME = soup.find("span", class_="ux-textspans ux-textspans--BOLD").text
PRODUCT_PRICE = soup.find("div", class_="x-price-primary").text.split(" ")[-1]
feedback_url = soup.find("a", class_="fdbk-detail-list__tabbed-btn fake-btn fake-btn--large fake-btn--secondary").get('href')
soup = BeautifulSoup(request_function(feedback_url), "lxml")
received_reviews = soup.find_all('div', class_="card__comment")
user_and_rating = soup.find_all('div', class_="card__from")
for each in range(len(received_reviews)):
review = {
"User" : user_and_rating[each].text.split('(')[0],
"Rating" : user_and_rating[each].text.split("(")[-1].rstrip(")"),
"User_Review" : received_reviews[each].text,
"Review_Time" : soup.find('span', {'data-test-id': f'fdbk-time-{each + 1}'}).text
}
reviews.append(review)
organize_data(PRODUCT_NAME, PRODUCT_PRICE, reviews)
Seamless eBay Product Review Extraction with ScrapingAPI
Well done! You’ve successfully built an eBay scraper to extract product reviews from eBay.
The purpose of this eBay web scraping guide is to equip you to:
- Easily extract eBay product reviews using Python, Beautiful Soup, and Requests
- Leverage LXML for effective data formatting
- Use JSON to organize your output, transforming raw HTML into structured data for analysis
Notably, it also underscores the role of ScraperAPI in enhancing your scraping endeavors by preventing IP blocking, and ensuring a smoother experience while extracting data from websites.
If you are working on a large project, needing more than 3M API credits, reach out to our team of experts and let us help you streamline your data acquisition process.
Until next time, happy scraping!
Check out other eBay scraping tutorials from ScraperAPI:




