



In this tutorial, you will learn everything you need to know to scrape data from Walmart effectively.
TL;DR: Full Walmart Scraper
If you are in a hurry and just want to read the final code, here it is:
import json
import requests
from bs4 import BeautifulSoup
url = "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177"
payload = {"api_key": "YOUR_API_KEY", "url": url, "render": "true"}
html = requests.get("http://api.scraperapi.com", params=payload)
product_info = {}
soup = BeautifulSoup(html.text)
product_info['product_name'] = soup.find("h1", attrs={"itemprop": "name"}).text
product_info['rating'] = soup.find("span", class_="rating-number").text
product_info['review_count'] = soup.find("a", attrs={"itemprop": "ratingCount"}).text
image_divs = soup.findAll("div", attrs={"data-testid": "media-thumbnail"})
all_image_urls = []
for div in image_divs:
image = div.find("img", attrs={"loading": "lazy"})
if image:
image_url = image["src"]
all_image_urls.append(image_url)
product_info['all_image_urls'] = all_image_urls
product_info['price'] = soup.find("span", attrs={"itemprop": "price"}).text
next_data = soup.find("script", {"id": "__NEXT_DATA__"})
parsed_json = json.loads(next_data.string)
description_1 = parsed_json["props"]["pageProps"]["initialData"]["data"]["product"][
"shortDescription"
]
description_2 = parsed_json["props"]["pageProps"]["initialData"]["data"]["idml"][
"longDescription"
]
product_info['description_1_text'] = BeautifulSoup(description_1, 'html.parser').text
product_info['description_2_text'] = BeautifulSoup(description_2, 'html.parser').text
print(product_info)
Note: Do not forget to replace YOUR_API_KEY with your ScraperAPI API key.
Please continue reading the tutorial to understand how the code works.
Scraping Walmart Product Data
In this tutorial, you’ll learn how to scrape data from an individual Walmart product page, extracting the following annotated information (and the product description):
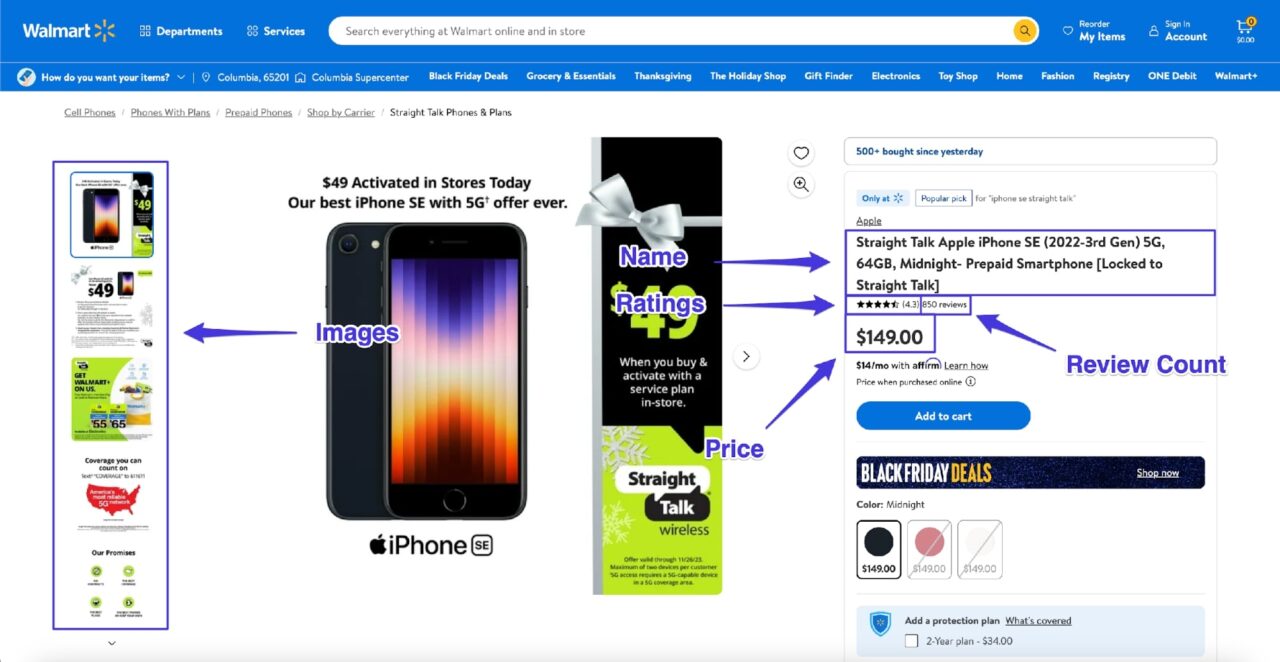
Requirements
This tutorial relies on Python version 3.12. If you have any Python version greater than 3.8, you should be fine. However, if something doesn’t work as shown, then try upgrading your Python version to 3.12.
You can check your Python version by running this code in the terminal:
$ python --version
To keep everything organized, create a new folder with an app.py file within it:
$ mkdir walmart_scraper
$ cd walmart_scraper
$ touch app.py
You can also set up a virtual environment if you want further isolation:
python -m venv venv
source venv/bin/activate
Next, you need to install Requests and BeautifulSoup. You will be using Requests to issue HTTP requests and BeautifulSoup to parse the response data. You can easily install both of them using PIP:
$ pip install requests, beautifulsoup4
Step 1: Signing up for ScraperAPI
As much as you want to scrape Walmart, the retail giant doesn’t want its data to be scraped. Due to this, Walmart’s website employs a lot of anti-bot measures that will return wrong/useless data in response to automated requests.
There are a few different ways to get around this issue.
You can either try to make the bot mimic a real user’s behavior as much as you can, or you can use third-party proxies.
The first option can work for some simple cases, but it is too fragile, and as Walmart continues to update its anti-bot measures, it is a question of “when” your bot will break and not “if”.
This makes the proxy option very attractive. With this option, you offload the difficult task of making sure Walmart returns the correct response to a third party and thus have more time to focus on your business logic.
In this tutorial, we’ll cover the proxy option and utilize ScraperAPI as our proxy provider.
The best part is that ScraperAPI provides 5,000 free API credits for 7 days on a trial basis and then provides a generous free plan with recurring 1,000 API credits to keep you going. This is enough to scrape data for general use.
You can quickly get started by going to the ScraperAPI dashboard page and signing up for a new account:
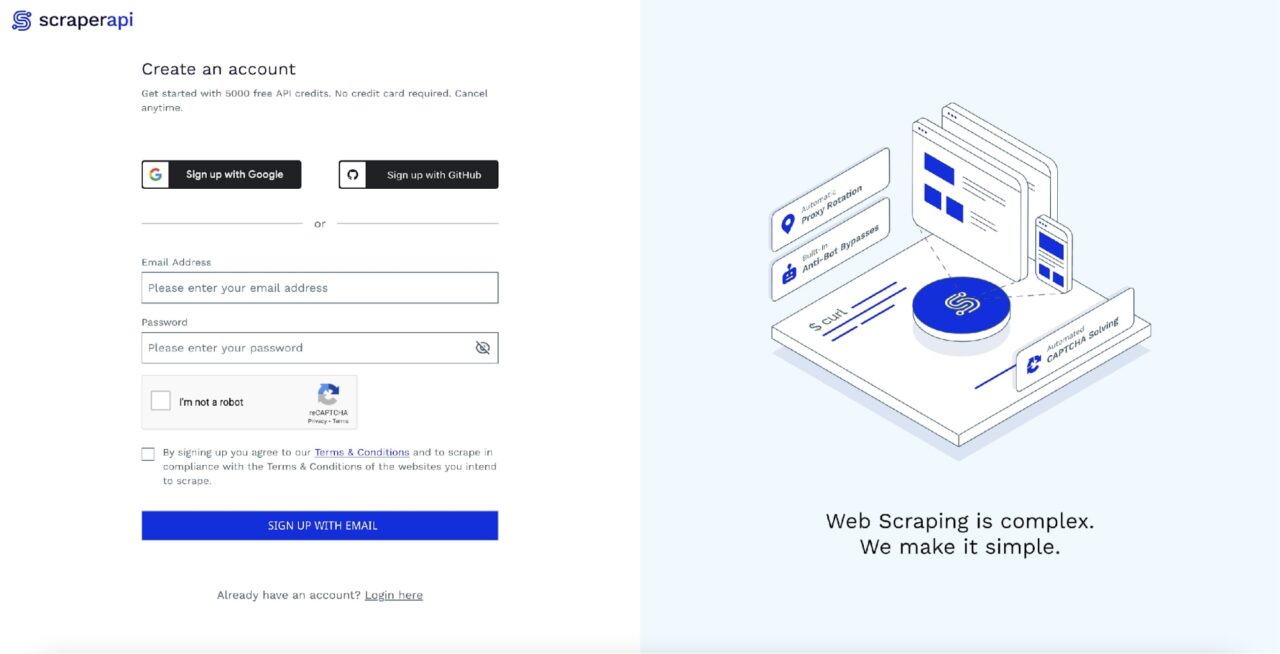
After signing up, you will see your API Key:
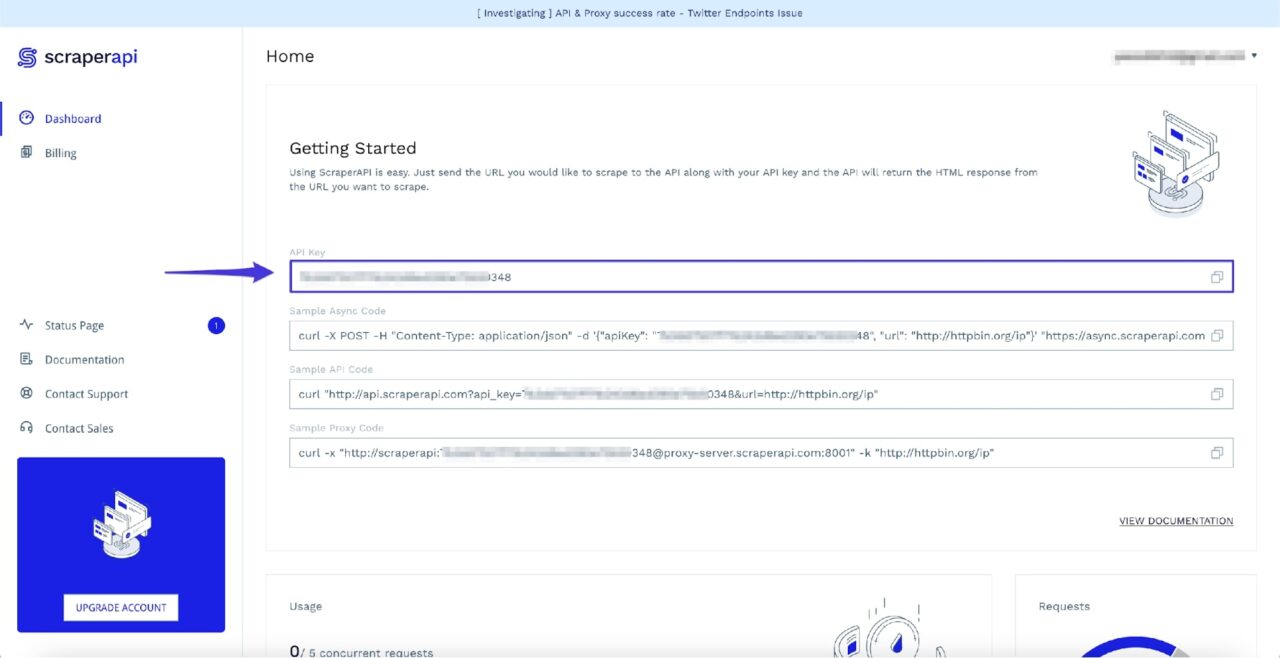
Keep a note of this API key for now, as you will need it in the next step.
Step 2: Fetching Walmart’s Product Page
Once you have your ScraperAPI account set up, you are ready to make the initial request using Python to download Walmart’s product page. To follow along, you can use this product page.
You have a few different options for how you want to route your requests via ScraperAPI.
- You can either configure ScraperAPI as a proxy while using requests or…
- You can send a request to ScraperAPI’s API endpoint and pass the target Walmart URL as a payload.
Important Update
There’s a new and easier way to scrape Walmart product pages!
Using our Walmart Products structured data endpoint (SDE), you can now collect product details like product name, price, description, reviews, images, and more in JSON format with a simple API call.
Just send you requests to our endpoint alongside your API key and the product ID you want to collect data from.
Here’s a code snippet to get you started:
import requests payload = { 'api_key': 'YOUR_API_KEY', 'product_id': '616074177', } response = requests.get('https://api.scraperapi.com/structured/walmart/product', params=payload) print(response.text)Want to learn more? Here’s how ScraperAPI helps you scrape Walmart.
You can learn more about these options in the official documentation.
In our case, we’ll make use of the latter option and pass a URL as a payload to ScraperAPI’s API endpoint.
You can use the following code to fetch Walmart’s product page via ScraperAPI:
import requests
url = "https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177"
payload = {"api_key": "YOUR_API_KEY", "url": url, "render": "true"}
html = requests.get("http://api.scraperapi.com", params=payload)
Note: Make sure you replace YOUR_API_KEY with your ScraperAPI API key
Once you get the HTML response, you can use it to create a BeautifulSoup object and, later on, use it to scrape the required data:
from bs4 import BeautifulSoup
# ...
soup = BeautifulSoup(html.text, 'html.parser')
It is a perfect time to go ahead and start scraping data using BeautifulSoup.
Step 3: Extracting the Product Name
BeautifulSoup provides a find() method that takes in different kinds of filters and then uses those filters to scan and filter the HTML tree.
The most important filters you need to know are the string and attribute filters.
- The string filter takes in a string that BeautifulSoup uses to match an HTML tag name.
- The attribute filter further assists in filtering all matched HTML tags against a particular attribute value.
But how do you know which HTML tag contains the data you want? This is where Developer Tools come into play.
The Developer Tools come bundled with most of the famous browsers and let you easily figure out which HTML tag contains the data you want to extract.
You can access the developer tools by simply right-clicking on the product name and clicking on inspect.
This is what it will look like with the Developer Tools open on Firefox (Chrome should also look somewhat similar):
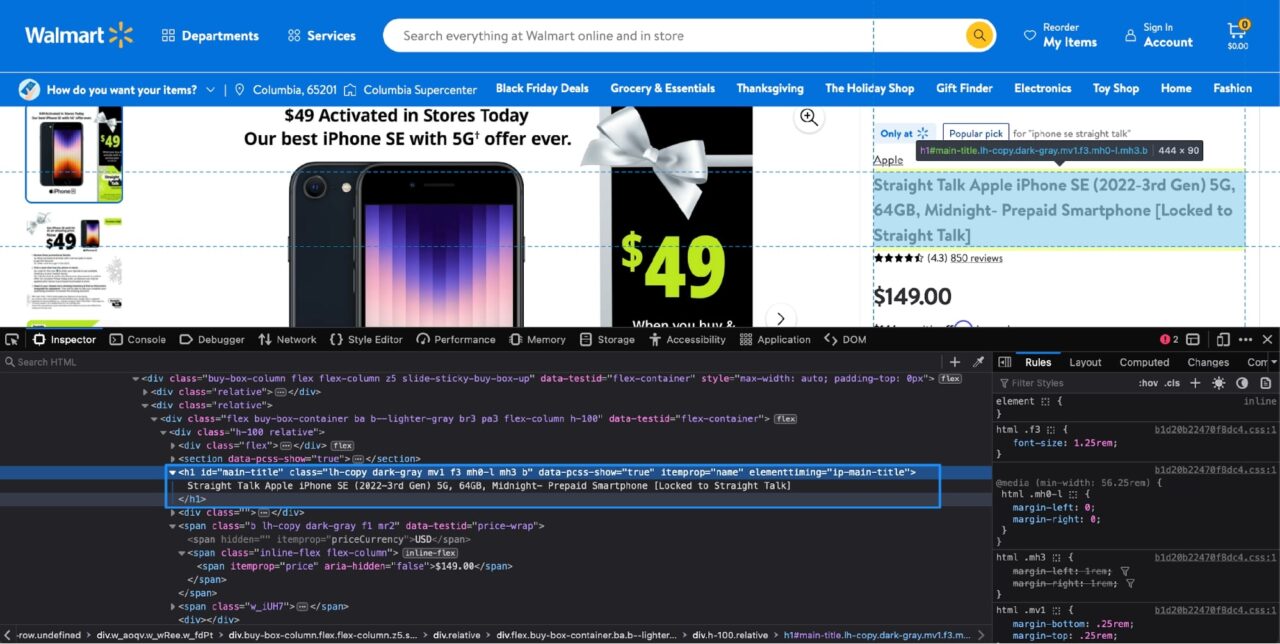
The highlighted section in the Inspector tab tells you that the product name is stored in an h1 tag with the itemprop attribute set to name.
Note: There can be multiple attributes assigned in a tag. Your job is to figure out what combination of attributes is enough to identify this particular tag uniquely. Luckily, in this case, you only need the itemprop attribute as there is no other h1 tag on this page that has the itemprop attribute set to name.
You can use this knowledge to craft this method call to extract the product name using BeautifulSoup:
product_name = soup.find("h1", attrs={"itemprop": "name"}).text
The text attribute at the end of the method call simply extracts the text from the matching HTML element.
If you try to print the value of the product_name variable, you should see this output:
>>> print(product_name)
Straight Talk Apple iPhone SE (2022-3rd Gen) 5G, 64GB, Midnight- Prepaid Smartphone [Locked to Straight Talk]
Sweet! That worked! Now you can try scraping the rest of the data from the page.
Step 4: Extracting the Product Price
It is a similar process to extract the product price. If you Inspect the price using the Developer Tools, this is what you will see:
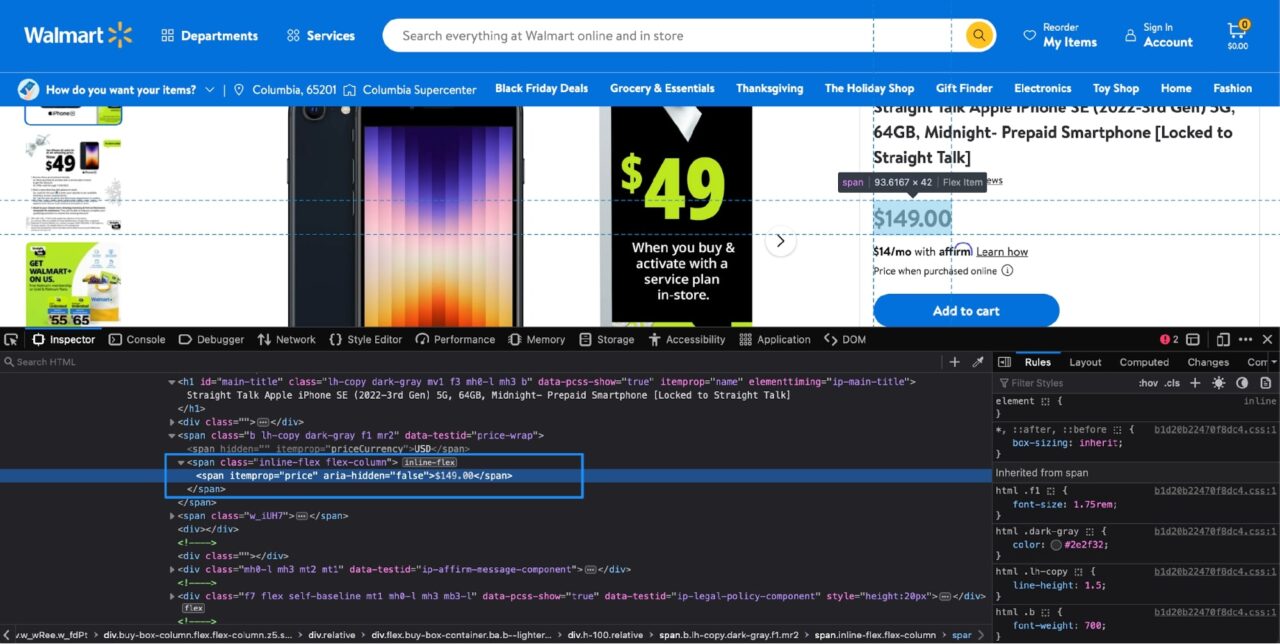
The price information is contained in a span tag with the itemprop attribute set to price. This results in the following Python code:
price = soup.find("span", attrs={"itemprop": "price"}).text
Step 5: Extracting the Product Ratings & Reviews Count
It is roughly the same set of steps required to extract each bit of information from the product page. If you Inspect the ratings, you should see the following DOM structure:
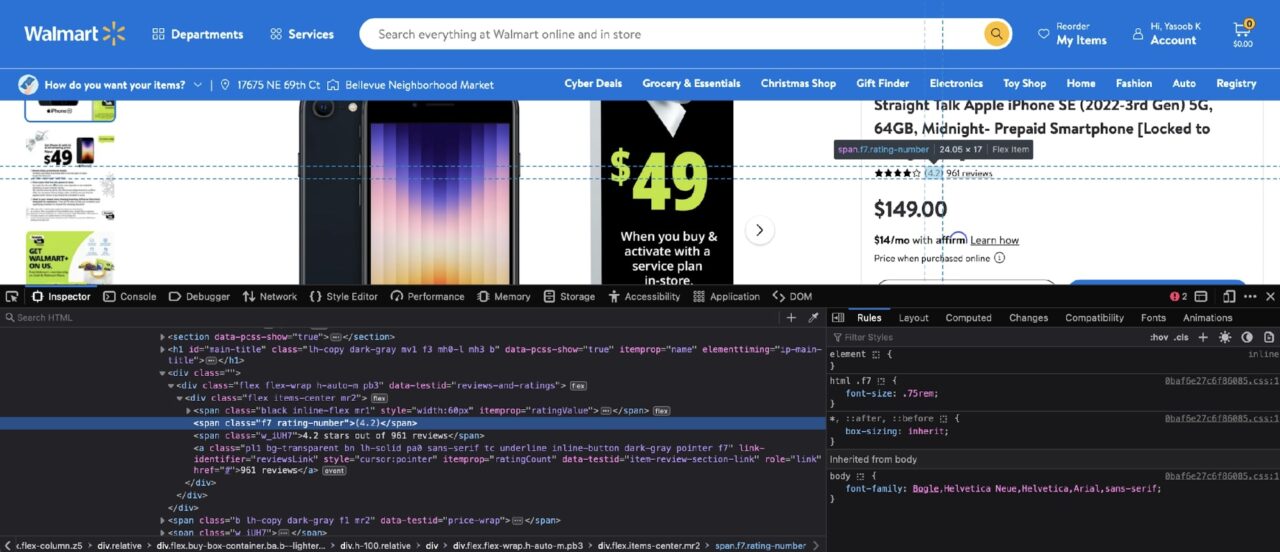
The rating number is contained in a span with a class of rating-number, and the review count is contained in an a tag with the itemprop attribute set to ratingCount.
Here is the resulting Python code:
rating = soup.find("span", class_="rating-number").text
review_count = soup.find("a", attrs={"itemprop": "ratingCount"}).text
The only difference in this code from the previous extraction codes is that you are using the class_ argument to pass in the class name to BeautifulSoup. This is just a different way to filter with class names. You can learn about all the different filters in the official documentation.
Step 6: Extracting the Product Images
Now, it is time to tackle the product images. This is what the DOM structure looks like for product images:
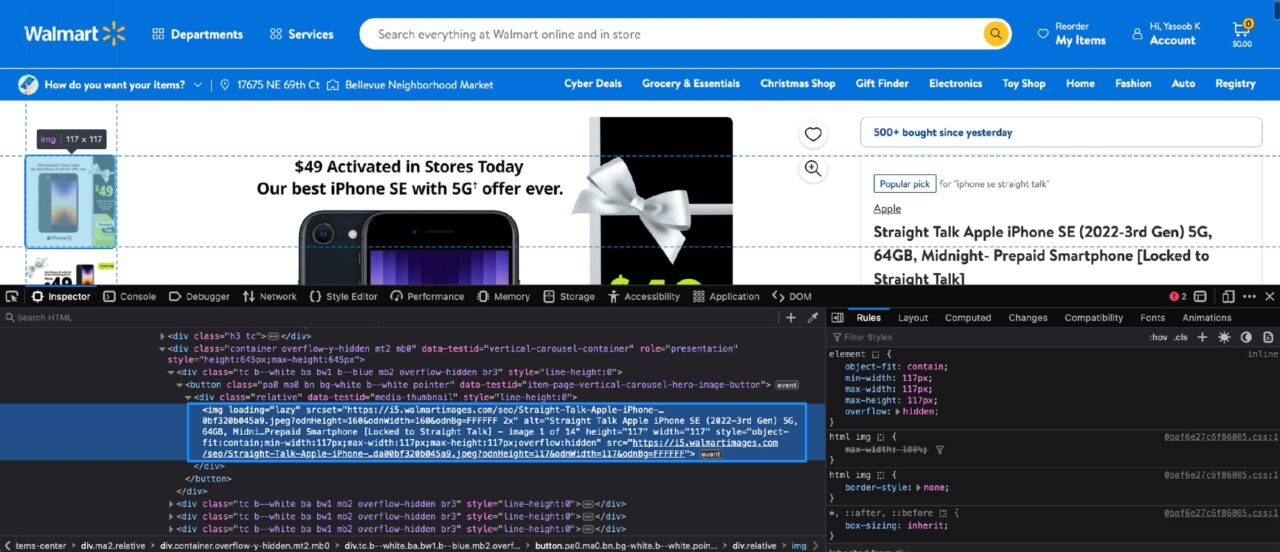
Each product image is contained in a similar img tag with the loading attribute set to lazy.
You can use BeautifulSoup and apply a filter to get these img tags and then extract the src attribute, which contains the actual image URL.
There is just one small issue. There are other img tags on this page as well that have the loading attribute set to lazy. If we do not add some additional filtering, then BeautifulSoup will return more tags than we expect.
One solution is to first filter for another tag to narrow down the search scope and then run an additional filter on that returned tag to get all the required nested img tags.
If you look closely, you can observe that the parent div tag contains a data-testid attribute set to media-thumbnail. You can use this knowledge to write the following Python code:
image_divs = soup.find_all("div", attrs={"data-testid": "media-thumbnail"})
all_image_urls = []
for div in image_divs:
image = div.find("img", attrs={"loading": "lazy"})
if image:
image_url = image["src"]
all_image_urls.append(image_url)
This code will first find all the divs that contain the product image, and then for each div it will apply additional filtering to get the relevant img tag’s source attribute.
Step 7: Extracting the Product Description
You are almost at the home stretch now. The last remaining bit of information you need to extract is the product description.
However, as you will see in a bit, this is also the most confusing one. If you Inspect the product description, you will come across the following DOM structure:
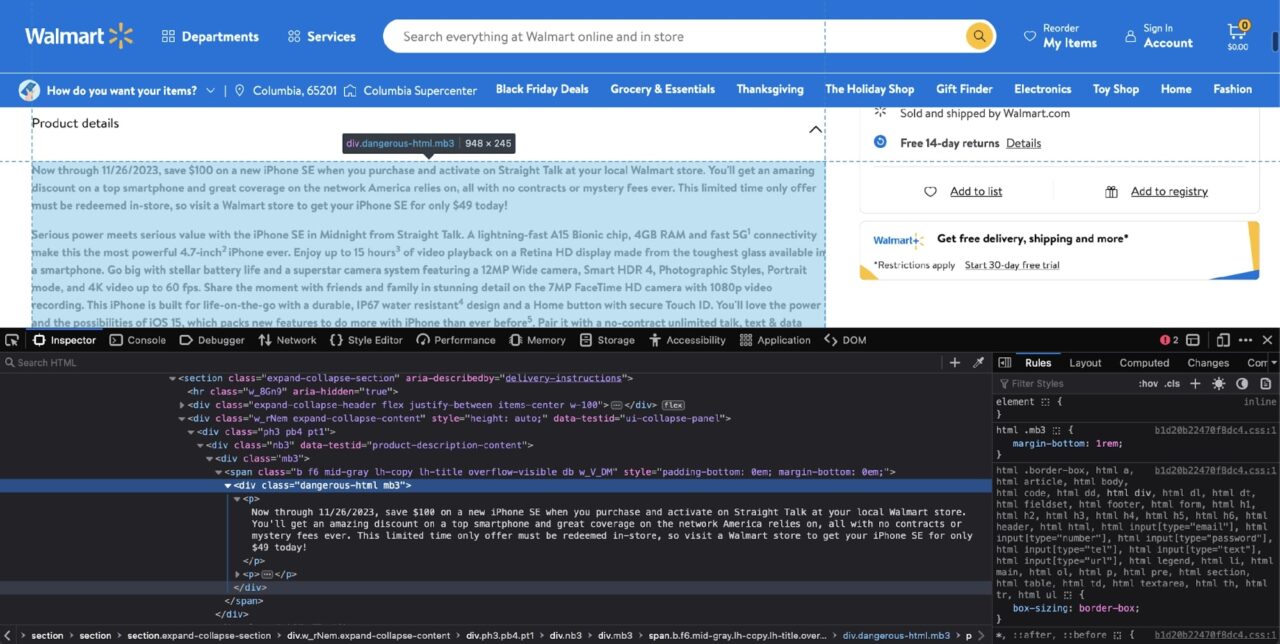
At first glance, it seems to be a simple case of div filtering with the dangerous-html class filter:
soup.find("div", class_="dangerous-html")
However, this doesn’t return any matching tags! What sorcery is this?
As it turns out, Walmart uses the NextJS framework for its website, and this tag is being populated by NextJS on the client side.
There are usually two possible scenarios when BeautifulSoup doesn’t return a matching tag:
- One scenario is that the information is loaded via an AJAX request after the initial page load
- The second scenario is that the information is already somewhere in the HTML document, but it is being populated in its final destination by some JavaScript
The second scenario is that the information is already somewhere in the HTML document, but it is being populated in its final destination by some JavaScript.
If you search for the product description in the Inspect tab, you will quickly find out that the product description is stored in a script tag as well:
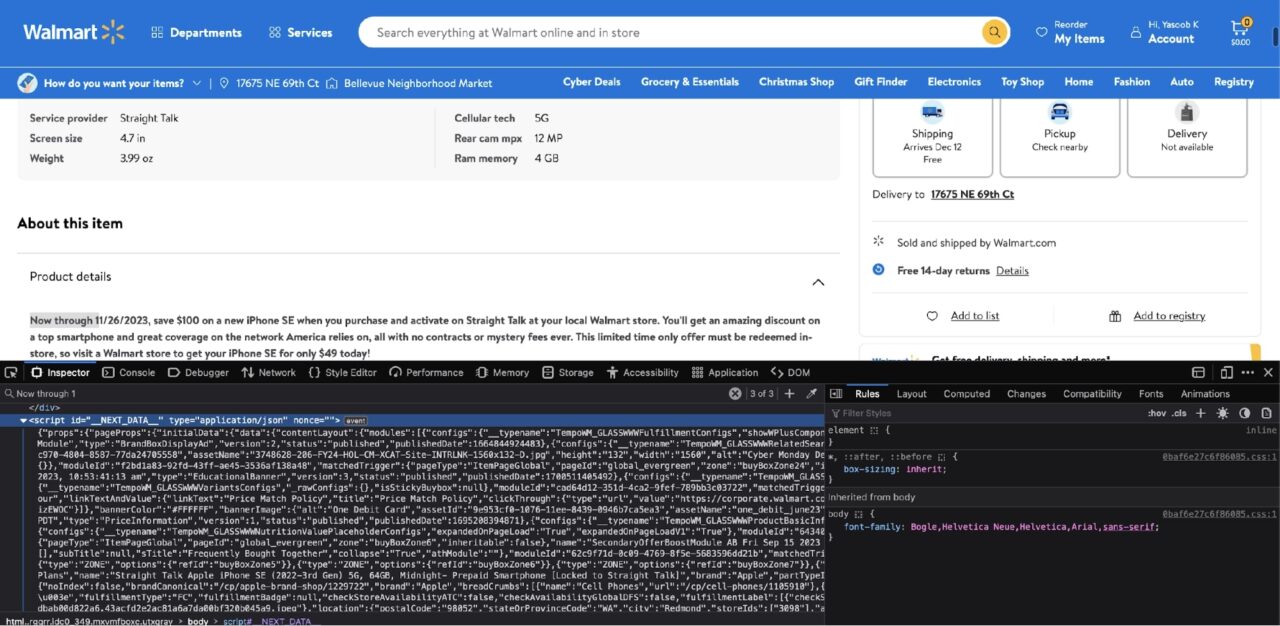
This script tag contains the data used by the NextJS framework to populate the UI with relevant information. This is nothing more than a big JSON string. You can filter for this script tag using BeautifulSoup, load the nested data using the json library, and then access the relevant information using the appropriate keys.
Here is what the parsed JSON data looks like:
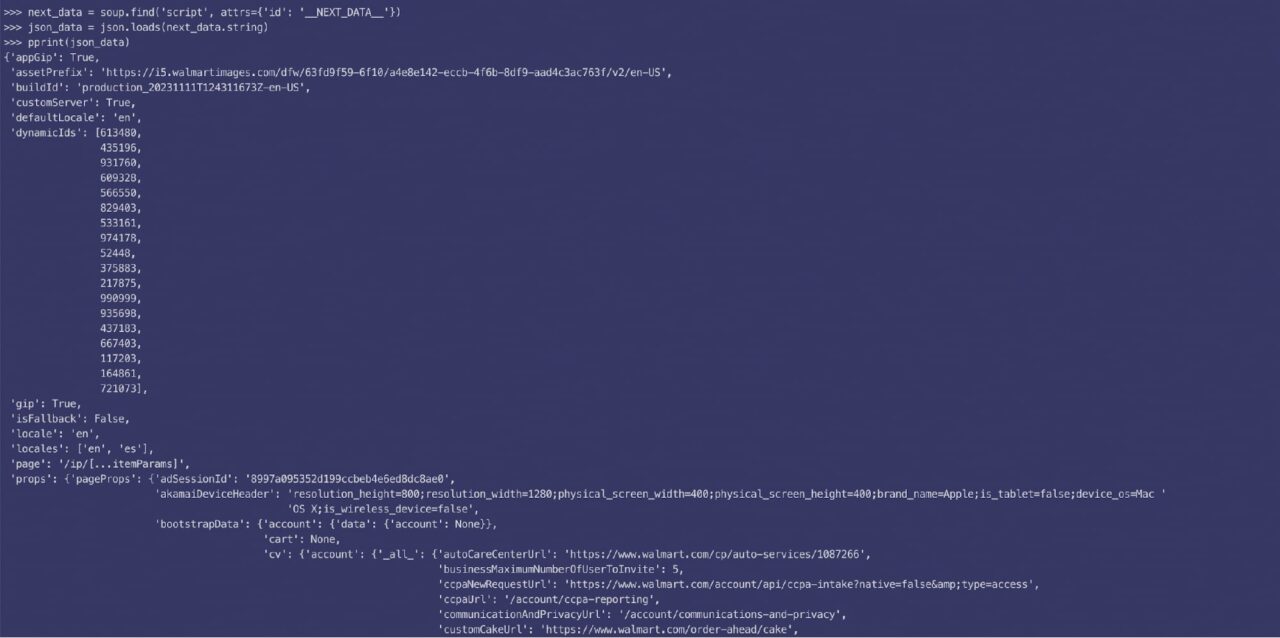
As it turns out, the description is split into two parts (short & long), and this code will give you the required data:
next_data = soup.find("script", {"id": "__NEXT_DATA__"})
parsed_json = json.loads(next_data.string)
short_description = parsed_json["props"]["pageProps"]["initialData"]["data"]["product"][
"shortDescription"
]
long_description = parsed_json["props"]["pageProps"]["initialData"]["data"]["idml"][
"longDescription"
]
There is one more issue. The extracted description is itself a mixture of HTML tags. For instance, here is the short description nested in p tags:
>>> print(description_1)
<p>Now through 11/26/2023, save $100 on a new iPhone SE when you purchase and activate on Straight Talk at your local Walmart store. You’ll get an amazing discount on a top smartphone and great coverage on the network America relies on, all with no contracts or mystery fees ever. This limited time only offer must be redeemed in-store, so visit a Walmart store to get your iPhone SE for only $49 today! </p> <p>Serious power meets serious value with the iPhone SE in Midnight from Straight Talk. A lightning-fast A15 Bionic chip, 4GB RAM and fast 5G<sup>1</sup> connectivity make this the most powerful 4.7-inch<sup>2 </sup>iPhone ever. Enjoy up to 15 hours<sup>3</sup> of video playback on a Retina HD display made from the toughest glass available in a smartphone. Go big with stellar battery life and a superstar camera system featuring a 12MP Wide camera, Smart HDR 4, Photographic Styles, Portrait mode, and 4K video up to 60 fps. Share the moment with friends and family in stunning detail on the 7MP FaceTime HD camera with 1080p video recording. This iPhone is built for life-on-the-go with a durable, IP67 water resistant<sup>4</sup> design and a Home button with secure Touch ID. You’ll love the power and the possibilities of iOS 15, which packs new features to do more with iPhone than ever before<sup>5</sup>. Pair it with a no-contract unlimited talk, text & data plan from Straight Talk to keep you connected for less on America’s most reliable 5G† Network. Find the Apple iPhone SE (3rd Generation) in Midnight and Straight Talk plans online or in-store at your local Walmart.</p>
Lucky for you, the fix is simple. You can load the descriptions in new BeautifulSoup objects and then ask BeautifulSoup to extract the readable text from the HTML:
short_description_text = BeautifulSoup(description_1, 'lxml').text
long_description_text = BeautifulSoup(description_2, 'lxml').text
If you try printing short_description_text now, you will see that BeautifulSoup conveniently stripped out all the HTML tags and returned only the readable text:
>>> print(short_description_text)
Now through 11/26/2023, save $100 on a new iPhone SE when you purchase and activate on Straight Talk at your local Walmart store. You’ll get an amazing discount on a top smartphone and great coverage on the network America relies on, all with no contracts or mystery fees ever. This limited time only offer must be redeemed in-store, so visit a Walmart store to get your iPhone SE for only $49 today! Serious power meets serious value with the iPhone SE in Midnight from Straight Talk. A lightning-fast A15 Bionic chip, 4GB RAM and fast 5G1 connectivity make this the most powerful 4.7-inch2 iPhone ever. Enjoy up to 15 hours3 of video playback on a Retina HD display made from the toughest glass available in a smartphone. Go big with stellar battery life and a superstar camera system featuring a 12MP Wide camera, Smart HDR 4, Photographic Styles, Portrait mode, and 4K video up to 60 fps. Share the moment with friends and family in stunning detail on the 7MP FaceTime HD camera with 1080p video recording. This iPhone is built for life-on-the-go with a durable, IP67 water resistant4 design and a Home button with secure Touch ID. You’ll love the power and the possibilities of iOS 15, which packs new features to do more with iPhone than ever before5. Pair it with a no-contract unlimited talk, text & data plan from Straight Talk to keep you connected for less on America’s most reliable 5G† Network. Find the Apple iPhone SE (3rd Generation) in Midnight and Straight Talk plans online or in-store at your local Walmart.
Step 8: Putting the Data in a Dictionary
Just to make it easy to work with the extracted data, you can store it in a dictionary:
product_info = {
'product_name': product_name,
'rating': rating,
'review_count': review_count,
'price': price,
'all_image_urls': all_image_urls,
'short_description_text': short_description_text,
'long_description_text': long_description_text,
}
The code shared in the TLDR section at the beginning of the tutorial is slightly different as it populates the dictionary as soon as the relevant data is extracted. The code in the rest of the article purposefully doesn’t follow that pattern so that it is easy to understand without the added complexity.
Now you can return this dictionary as part of an API response or dump it into a CSV file. The sky is the limit!
Scraping Walmart Product Pages with ScraperAPI’s SDE
Now that you’ve seen how to scrape Walmart with Python, let’s simplify the process using ScraperAPI’s structured data endpoint to turn Walmart’s product page into JSON data.
Note: If you haven’t already, create a free ScraperAPI account to get your API key and 5,000 API credits to test the tool.
Step 1: Getting the Product ID
The Walmart Product SDE works by sending a get() request to the https://api.scraperapi.com/structured/walmart/product endpoint along with your API key and the product ID you want to scrape data from.
To get this ID, just navigate to the product page you want to collect data from and copy the number at the end of the URL.
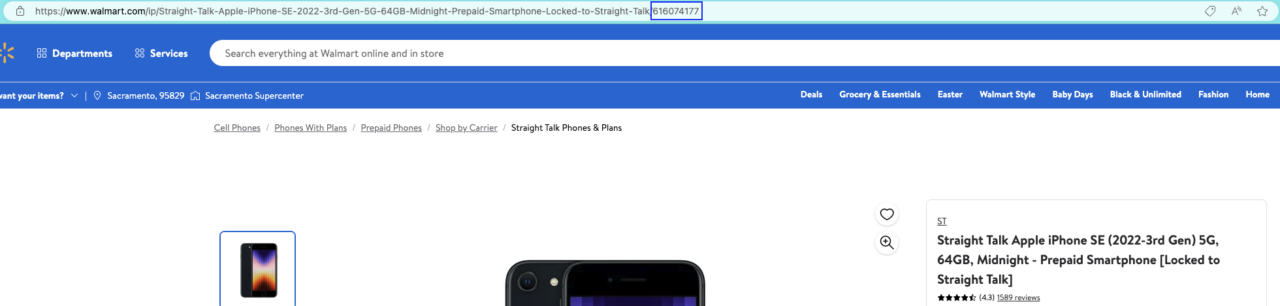
In our case: 616074177.
Quickly build a list of product IDs using our Walmart Search endpoint to turn Walmart search pages into JSON data. You’ll be able to scrape all the products listed in the search results for your targeted query.
Here’s a snippet to get you started:
import requests import credentials payload = { 'api_key': 'YOUR_API_KEY', 'query': 'iphone', } response = requests.get('https://api.scraperapi.com/structured/walmart/search', params=payload) print(response.text)
Step 2: Turning Walmart Product Page into JSON
Once you have the (list of) product ID(s), create a payload that includes your API key and query.
import requests
payload = {
'api_key': "YOUR_API_KEY",
'product_id': '616074177',
}
Next, send your get() request to the endpoint with your payload as params.
response = requests.get('https://api.scraperapi.com/structured/walmart/product', params=payload)
The endpoint will return the following JSON data:
- Product name
- Short and long description
- Product images
- Product URL
- Product price
- Ratings
- Reviews
- SKU
And more.
Note: Check this Walmart Product endpoint sample response to get familiar with the JSON structure.
Step 3: Getting Specific Product Details
Because the endpoint brings back predictable JSON data, we can now use the key-value pairs to gather specific data points from the product page.
For the sake of simplicity, let’s print() the product’s name, URL, price, and short description.
First, let’s save the JSON response in a variable we’ll name product:
product = response.json()
Then, we’ll use the JSON keypairs to create a dictionary and print the information:
product_details = {
'Name': product['product_name'],
'URL': product['product_url'],
'Price': product['price'],
'Currency': product['price_currency'],
'Short-Des.': product['product_short_description']
}
print(product_details)
Here’s the result:
{
"Name":"Straight Talk Apple iPhone SE (2022-3rd Gen) 5G, 64GB, Midnight - Prepaid Smartphone [Locked to Straight Talk]",
"URL":"https://www.walmart.com/ip/Straight-Talk-Apple-iPhone-SE-2022-3rd-Gen-5G-64GB-Midnight-Prepaid-Smartphone-Locked-to-Straight-Talk/616074177",
"Price":149,
"Currency":"USD",
"Short-Des.":"Serious power meets serious value with the iPhone SE in Midnight from Straight Talk. A lightning-fast A15 Bionic chip, 4GB RAM and fast 5G1 connectivity make this the most powerful 4.7-inch2 iPhone ever. Enjoy up to 15 hours3 of video playback on a Retina HD display made from the toughest glass available in a smartphone. Go big with stellar battery life and a superstar camera system featuring a 12MP Wide camera, Smart HDR 4, Photographic Styles, Portrait mode, and 4K video up to 60 fps. Share the moment with friends and family in stunning detail on the 7MP FaceTime HD camera with 1080p video recording. This iPhone is built for life-on-the-go with a durable, IP67 water resistant4 design and a Home button with secure Touch ID. You'll love the power and the possibilities of iOS 15, which packs new features to do more with iPhone than ever before5. Pair it with a no-contract unlimited talk, text & data plan from Straight Talk to keep you connected for less on America's most reliable 5G† Network. Find the Apple iPhone SE (3rd Generation) in Midnight and Straight Talk plans online or in-store at your local Walmart."
}
Step 4: Exporting the Walmart Product Data into a JSON File
Saving the data into a JSON file is as easy as importing JSON into our project and using the json.dump() function to dump our dictionary into a JSON file.
import json
(rest of the code)
with open('walmart-product.json', 'w') as f:
json.dump(product_details, f)
Now, you should have a new walmart-product.json file inside your project’s folder.

Congratulations, you just scraped your first Walmart product page in minutes!
Wrapping up on how to scrape Walmart data
In this tutorial, you:
- Learned how to scrape data from Walmart’s website using BeautifulSoup, Requests, and Python
- Saw how the Developer Tools make it easy to figure out which BeautifulSoup filters to use to extract the relevant data
- Became familiar with ScraperAPI and observed how it renders all of the anti-bot measures used by Walmart useless with the help of its advanced detection evasion algorithms and a cluster of high-quality proxies
- Used ScraperAPI’s Walmart Product SDE to turn product pages into JSON data
You can use the knowledge gained from this tutorial to build more elaborate Walmart scraping pipelines.
At this point, your imagination is the only limit. If you have any questions or need more information about our different products, please reach out! We would love to help you out.
Until next time, happy scraping!





