The following guide on web scraping with JavaScript and Node.js will enable you to scrape virtually any page. Node.js is a fast-growing, easy-to-use runtime environment made for JavaScript, which makes it perfect for web scraping JavaScript efficiently and with a low barrier to entry.
Web scraping JavaScript has a number of advantages. Because it’s one of the most widely used and supported programming languages, JavaScript scraping allows developers to scrape a wide variety of websites.
Plus, JavaScript’s native database structure is JSON, which is the most commonly used database structure across all APIs.
Today, we’re going to learn how to build a JavaScript web scraper and make it find a specific string of data on both static and dynamic pages.
If you read through to the end of our guide, in addition to showing you how to build a web scraper from scratch, we’ll teach you a simple trick to go around most major roadblocks you’ll encounter when scraping websites at scale.
Pre-requisites: What You Need to Know About Web Scraping JavaScript
This tutorial is for junior developers, so we’ll cover all the basics you need to understand to build your first JavaScript web scraper.
However, to get the most out of our guide, we would recommend that you:
- Have experience with JavaScript (or at least familiarity with it)
- Have basic knowledge of web page structure
- Know how to use DevTools to extract selectors of elements (we’ll show you either way)
Note: While JavaScript Scraping is relatively straightforward, if you’ve never used JavaScript before, check out the w3bschool JavaScript tutorial, or for a more in-depth course, go through freeCodeCamp’s Javascript course.
Of course, web scraping comes with its own challenges, but don’t worry. At the end of this article, we’ll show you a quick solution that’ll make your scraper run smoothly and hassle-free.
Knowing how to create a web scraper from scratch is an essential step on your learning journey to becoming a master scraper, so let’s get started.
How to Build a JavaScript Web Scraper for Static Pages
Web scraping can be broken down into two basic steps:
- Fetching the HTML source code and
- Parsing the data to collect the information we need.
We’ll explore how to do each of these by gathering the price of an organic sheet set from Turmerry’s website.
Step 1: Install Node.js on Your Computer
To begin, go to https://nodejs.org/en/download/ to download Node.js and follow the prompts until it’s all done. A Node.js scraper allows us to take advantage of JavaScript web scraping libraries like Cheerio- more on that shortly.
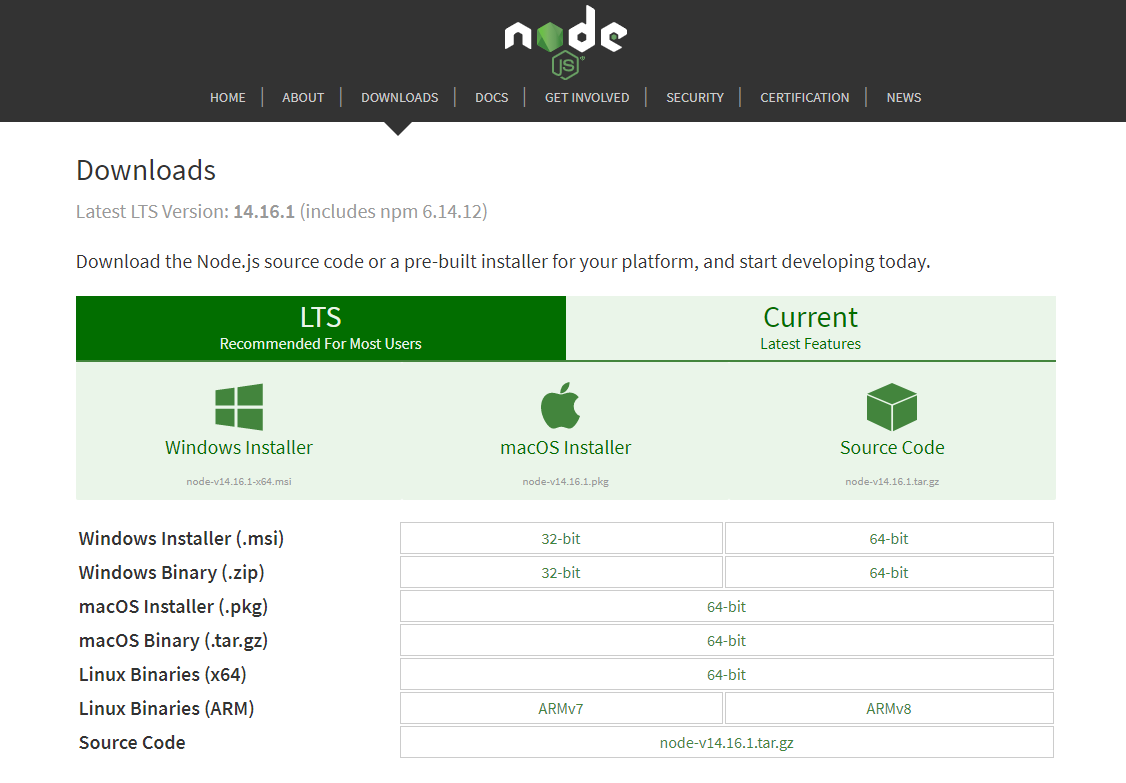
The download includes npm, which is a package manager for Node.js. Npm will let us install the rest of the dependencies we need for our web scraper.
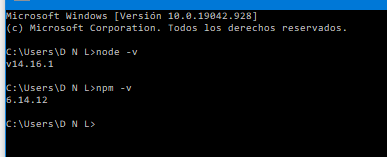
After it’s done installing, go to your terminal and type node -v and npm -v to verify everything is working properly.
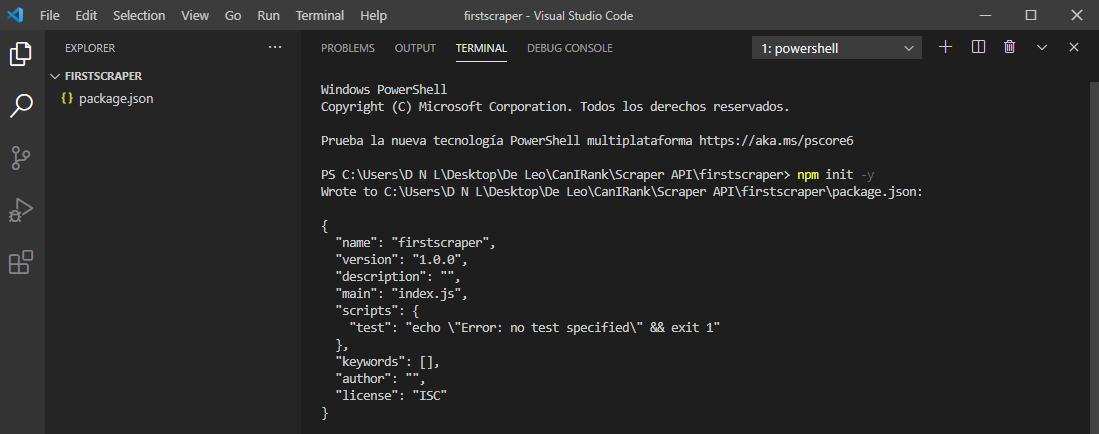
Step 2: Get Your Workspace Ready
After Node.js is installed, create a new folder called “firstscraper” and type npm init -y to initialize a package.json file.
Then we’ll install our dependencies by running npm install axios cheerio puppeteer and waiting a few minutes for it to install.
* Installing puppeteer will take a little longer as it needs to download chromium as well.
Axios is a promise-based HTTP client for Node.js that allows us to send a request to a server and receive a response. In simple terms, we’ll use Axios to fetch the HTML code of the web page.
On the other hand, Cheerio is a jquery implementation for Node.js that makes it easier to select, edit, and view DOM elements.
We’ll talk more about the last library, puppeteer, when scraping dynamic pages later in this article.
Step 3: Fetch the HTML Code Using Axios
With everything ready, click on “new file”, name it scraperapi.js, and type the following function to fetch the HTML of the product page we want to collect data from:
</p>
const axios = require('axios');
const url = 'https://www.turmerry.com/collections/organic-cotton-sheet-sets/products/percale-natural-color-organic-sheet-sets';
axios(url)
.then(response => {
const html = response.data;
console.log(html);
})
.catch(console.error);
<p>We use const axios = require('axios') to declare Axios in our project and add const url and give it the URL of the page we want to fetch.
Axios will send a request to the server and bring a response we’ll store in const html so we can then call it and print it on the console.
After running the scraper using node scraperapi.js in the terminal, it will pull a long and unreadable string of HTML.
Now, let’s introduce cheerio to parse the HTML and only get the information we are interested in.
Step 4: Select the Elements You Want to Collect
Before we actually add cheerio to our project, we need to identify the elements we want to extract from the HTML.
To do this, we’ll use our browser’s dev tools.
First, we’ll open Turmerry’s product page and press Ctrl + shift + c to open the inspector tool.
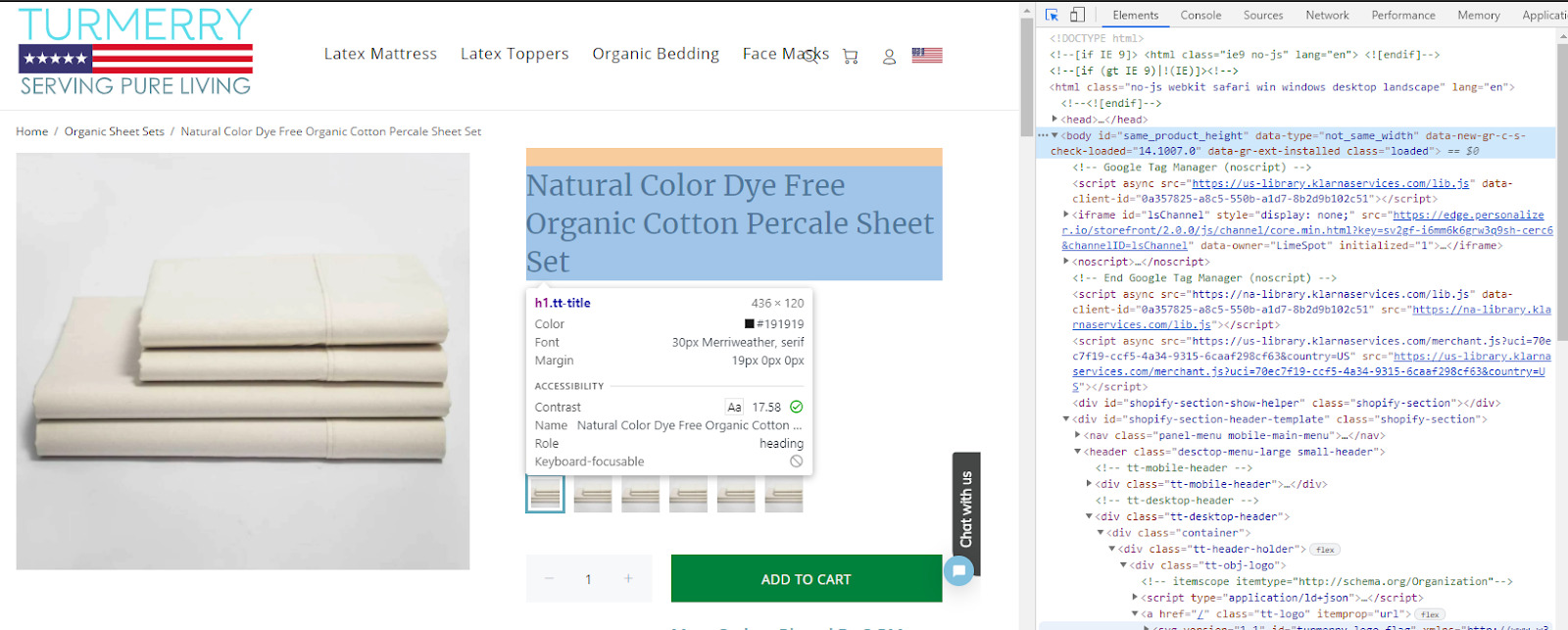
There are two different prices on the page. In some cases, you might want to get both prices, but for this example, we want to collect the price they are really selling it for.

When clicking on the $99.00 price, the tool will take you to the corresponding line of code where you can get the element class.
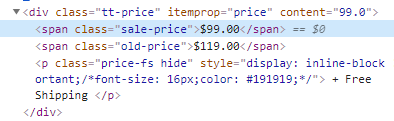
The retail price has a sale-price class applied. Now that we have this information, we can go ahead and add cheerio to our file.
Step 5: Parse the HTML Using Cheerio
First thing’s first, add const cheerio = require('cheerio') to the top of your file to import our library into the project and then pass the HTML document to Cheerio using const $ = cheerio.load(html).
After loading the HTML, we’ll use the price’s CSS class using const salePrice = $('.sale-price').text() to store the text containing the class within salePrice.
Once you update your code, it should look something like this:
</p>
const axios = require('axios');
const cheerio = require('cheerio')
const url = 'https://www.turmerry.com/collections/organic-cotton-sheet-sets/products/percale-natural-color-organic-sheet-sets';
axios(url)
.then(response => {
const html = response.data;
const $ = cheerio.load(html)
const salePrice = $('.sale-price').text()
console.log(salePrice);
})
.catch(console.error);
<p>After running your program, it will print the content tagged as .sale-price to the console:
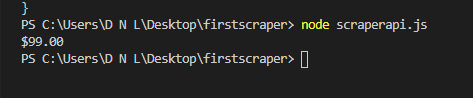
If we provide more URLs, we’ll be able to collect all selling prices for all products in a fraction of the time it would take us to do it by hand.
Note: Web scraping using cheerio has many additional uses- if you’d like to dive deeper into this library, check out cheerio’s documentation.
Scraping Dynamic Pages? Here’s What to Do
When you navigate to a dynamic page, your browser will need to render JavaScript scripts to access the content before displaying it for you. This might not be an issue for us, but it is for our scraper.
Axios, and any HTTP client for that matter, will not wait for the JavaScript to execute before returning a response. So if we use our scraper as it is right now, we won’t really get anything.
Here’s where Puppeteer will come in handy.
In simple terms, Puppeteer is a node.js library that allows you to control a headless chromium-browser directly from your terminal. You are able to do pretty much anything you can imagine, like scrolling down, clicking, taking screenshots, and more.
If the content you want to scrape won’t load until you execute a script by clicking on a button, you can script these actions using Puppeteer and make the data available for your scraper to take.
For this example, let’s say that you want to create new content around web scraping with JavaScript and thought to scrape the r/webscraping subreddit for ideas by collecting the titles of the posts.

If we inspect this subreddit, we’ll notice a few things right away: first, classes are randomly generated, so there’s no sense in us trying to latch on to them. Second, the titles are tagged as H3, but they are wrapped between anchor tags with a div between the tag and the h3.
Let’s create a new JS file, name it scraperapi2.js, and add const puppeteer = require('puppeteer') to import the library into the project. Then, add the following code:
</p>
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
let scraped_headlines = [];(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
}
<p>First, we’re using let scraped_headlines = [ ] to declare where our data will be stored. Then, we write an async function to enable us to use the await operator.
Note: although you could build a scraper using .then( ) callbacks, it will just limit your scraper’s scalability and make it harder to scrape more than one page at a time.
After that’s set, we’re telling Puppeteer to launch the browser, wait (await) for the browser to be launched, and then open a new page.
Now, let’s open a try statement and use the next block of code to tell the browser to which URL to go to and for Puppeteer to get the HTML code after it renders:
</p>
try {
await page.goto('https://www.reddit.com/r/webscraping/', {timeout: 180000});
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
<p>We are already familiar with the next step. Because we got the HTML document, we’ll need to send it to Cheerio so we can use our CSS selectors and get the content we need:
</p>
try {
await page.goto('https://www.reddit.com/r/webscraping/', {timeout: 180000});
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
let $ = cheerio.load(bodyHTML);
let article_headlines = $('a[href*="/r/webscraping/comments"] > div')
article_headlines.each((index, element) => {
title = $(element).find('h3').text()
scraped_headlines.push({
'title': title
})
});
}
<p>In this case, we added 'a[href*="/r/webscraping/comments"] > div’ in the first selector to tell our scraper where to look for the data, before asking it to return the text within the H3 tag with title = $(element).find('h3').text().
Lastly, we use the push() method to add the word “title:” before every data string. This makes it easier to read.
After updating your code, it should look like this:
</p>
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
let scraped_headlines = [];
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
await page.goto('https://www.reddit.com/r/webscraping/', {timeout: 180000});
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
let $ = cheerio.load(bodyHTML);
let article_headlines = $('a[href*="/r/webscraping/comments"] > div')
article_headlines.each((index, element) => {
title = $(element).find('h3').text()
scraped_headlines.push({
'title': title
})
});
}
catch(err) {
console.log(err);
}
await browser.close();
console.log(scraped_headlines)
})();
<p>You can now test your code using node scraperapi2.js. It should return all the H3 titles it can find on the rendered page:
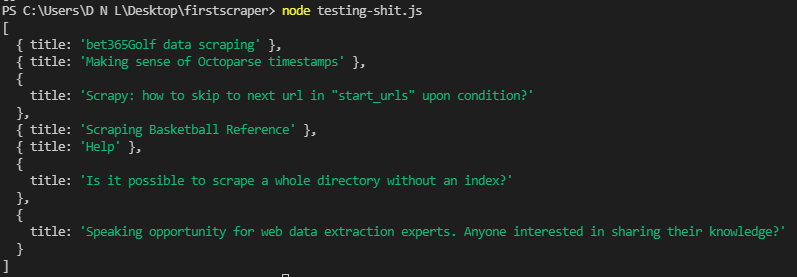
Note: For a more in-depth look at this library, here’s Puppeteer’s documentation.
Using ScraperAPI for Faster Data Scraping
As you’ve seen in this tutorial, building a web scraper is a straightforward project with a lot of potential. The real problem with homemade scrapers however, is scalability.
One of the challenges you’ll be facing is handling- for example – CAPTCHAs. While running your program, your IP address can get identified as a fraudulent user, getting your IP banned.
If you run your scraper on a server hosted in a data center, you’re even more likely to be blocked instantly. Why? Because datacenter IPs are less trusted, getting your requests flagged as “non-person requests.”
All these roadblocks make web scraping so challenging and are why we developed an API that can handle all of them automatically: from rotating IP addresses, handling CAPTCHAs, and rendering JavaScript, ScraperAPI handles everything with a single API call.
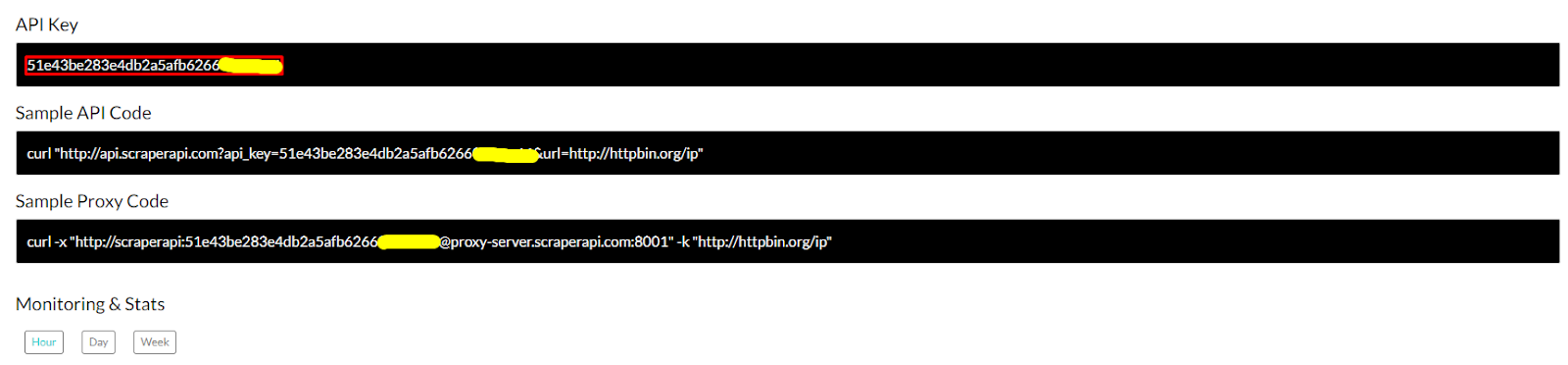
To learn how to integrate ScraperAPI with our scrapers, we’ll need to create a new ScraperAPI account – you’ll get 1000 free API credits right off the bat, so you have more than enough for trying the API out.
After signing up, you’ll get access to your API key and some sample code for you to use as a reference.
Now, let’s integrate ScraperAPI with our Axios scraper:
Integrating ScraperAPI with Axios requests
This is super straightforward. All we need to do is to add our API key as a const and then tell Axios to use our ScraperAPI endpoint:
</p>
let axios = require('axios');
const cheerio = require('cheerio')<
const API_KEY = ''YOUR_API_KEY''
const url = 'https://www.turmerry.com/collections/organic-cotton-sheet-sets/products/percale-natural-color-organic-sheet-sets';
axios('http://api.scraperapi.com/', {
params: {
'url': url,
'api_key': API_KEY,
}})
<p>Now every request will go through ScraperAPI, and it will return with the HTML we can then pass to Cheerio as before.
Also, because it’s fully integrated with our scraper, we can add other parameters to our code to add more functionalities through the API.
An excellent use case for this is scraping a JavaScript site without using a headless browser.
By setting render=true, ScraperAPI will use a headless chromium browser to execute the script and return with the fully loaded HTML.
Here’s the final Axios + Cheerio code:
</p>
let axios = require('axios');
const cheerio = require('cheerio');
const API_KEY = '51e43be283e4db2a5afb6266xxxxxxxx'
const render = 'true'
const url = 'https://www.turmerry.com/collections/organic-cotton-sheet-sets/products/percale-natural-color-organic-sheet-sets';
axios('http://api.scraperapi.com/', {
params: {
'url': url,
'api_key': API_KEY,
'render' : render
}})
.then(response => {
const html = response.data;
const $ = cheerio.load(html)
const salePrice = $('.sale-price').text()
console.log(salePrice);
})
.catch(console.error);
<p>Integrating ScraperAPI with Puppeteer
You’re probably thinking: if I can render JavaScript with ScraperAPI, why would I need a Puppeteer implementation?
The reason is simple. ScraperAPI will execute the JavaScript necessary for the page to load. However, if you need to interact with the page (like to scroll or click a button), you’ll need to use your own headless browser – in this case, Puppeteer.
For this example, we’ll add the following code to set our proxy configuration, right after declaring our dependencies:
</p>
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = 'API_KEY'; // <-- enter your API_Key here
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
<p>Next we set our scraper to use ScraperAPI as a proxy within our async function:
</p>
(async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: [
'--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}'
]
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
<p>After updating your code, it should look like this:
</p>
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
PROXY_USERNAME = 'scraperapi';
PROXY_PASSWORD = '51e43be283e4db2a5afb6266xxxxxxxx';
PROXY_SERVER = 'proxy-server.scraperapi.com';
PROXY_SERVER_PORT = '8001';
let scraped_headlines = []; (async () => {
const browser = await puppeteer.launch({
ignoreHTTPSErrors: true,
args: [
'--proxy-server=http://${PROXY_SERVER}:${PROXY_SERVER_PORT}'
]
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
try {
await page.goto('https://www.reddit.com/r/webscraping/', {timeout: 180000});
let bodyHTML = await page.evaluate(() => document.body.innerHTML);
let $ = cheerio.load(bodyHTML);
let article_headlines = $('a[href*="/r/webscraping/comments"] > div')
article_headlines.each((index, element) => {
title = $(element).find('h3').text()
scraped_headlines.push({
'title': title
})
});
}
catch(err) {
console.log(err);
}
await browser.close();
console.log(scraped_headlines)
})();
<p>And there you go, your API is ready to use!
To get the most out of your account, you can follow this ScraperAPI cheat sheet. There you’ll find the best practices for web scraping using our API along with some of the major challenges you’ll face in more detail.
Also, save this puppeteer integration with ScraperAPI sample code to follow every time you’re building a new project. It will definitely cut some coding time.
We hope you enjoyed this tutorial and that you learned a thing or two from it. If you have any questions, don’t hesitate to contact our support team, they’ll be happy to help.
Happy scraping!