



What is a Dataset?
A dataset is a collection of related data organized in a structured manner. It can take various forms, such as tabular data – with columns representing different variables and rows representing individual records. In other cases, a data set may consist of documents or files.
Essentially, a dataset brings together pieces of information that are grouped together based on their relationship or purpose. It allows for efficient management and access, enabling us to analyze and work with the data individually or collectively.
Think of a data set as a container holding valuable information, like a virtual filing cabinet or a database. It provides a structured framework that helps us store, organize, and make sense of the data.
Public vs. Private Datasets
A public dataset is a collection of information that is available to anyone who wants to access it. It can be used for research, analysis, or any other purpose. Researchers and data scientists often use public datasets to develop new algorithms and models.
A good example of public datasets is those shared by Kaggle.
(These are available for everyone to download and use as they please.)
On the other hand, a private dataset is a collection of information that is only available to a specific group of people or organizations. Companies and organizations often use private datasets to store sensitive information that they do not want to share with the public.
Something to keep in mind is that not because a dataset is paid means it is private. This is an important distinction because access to data can give a business a clear advantage over the competition.
For example, if many businesses buy the same datasets from the same provider, the difference in outcomes would come down to the skill of the analysts and how fast they can act on the insights.
However, when businesses create their own datasets from alternative sources, they can access a wealth of unique insights no other organization or business can.
How to Build a Dataset
Any machine learning (ML) or data analysis project requires information, and there are many ways professionals and businesses can gather it:
- Surveys and Questionnaires – People fill out forms providing the necessary information researchers need.
- Publicly Available Data – Some governments and institutions provide public datasets you can download and use in your projects.
- Transactional Data – Things like sales records provide a lot of useful information businesses can use to better understand the demand for products and services, specific details about their audiences, and more.
- Data APIs – Some websites, data providers, and applications provide open-source and paid APIs that allow us to retrieve information from their databases.
However, in a lot of cases, the data we need is scattered across the web with no direct access to it via APIs or structured formats – a few examples are product data, public social media conversations and posts, forums, etc.
In those cases, the only solution is using web scraping to access, gather and format the data into usable datasets.
Building a Dataset with Web Scraping
Web scraping is the process of programmatically extracting publicly available web data from websites and online platforms. This allows us to have access to millions of data points we can later use to build applications, draw insights to make business decisions, and more.
In other words, we can easily build our own private, structured datasets using web scraping.
For this tutorial, we’ll be using the following five technologies:
- Python
- Requests – to make our HTTP requests
- ScraperAPI – to avoid IP bans and bypass anti-scraping mechanisms
- BeautifulSoup – to parse the HTML response
- Pandas – to build our DataFrame
Note: In Python, a DataFrame is a structure that fits our dataset definition.
Our objective is to scrape book data from https://books.toscrape.com/index.html and build a DataFrame with the name, price, description, stock availability, universal product number (UPC), and category.
TL;DR – Full Code
For those in a hurry or experience, here’s the full codebase that we’re building in this tutorial.
import requests
from bs4 import BeautifulSoup
import pandas as pd
scraperapi = 'https://api.scraperapi.com?api_key=YOUR_API_KEY&url='
all_books = []
for x in range(1, 5):
response = requests.get(scraperapi + f'https://books.toscrape.com/catalogue/page-{x}.html')
soup = BeautifulSoup(response.content, 'html.parser')
onpage_books = soup.find_all('li', class_='col-xs-6')
for books in onpage_books:
r = requests.get(scraperapi + 'https://books.toscrape.com/catalogue/' + books.find('a')['href'])
s = BeautifulSoup(r.content, 'html.parser')
all_books.append({
'Name': s.find('h1').text,
'Description': s.select('p')[3].text,
'Price': s.find('p', class_='price_color').text,
'Category': s.find('ul', class_='breadcrumb').select('li')[2].text.strip(),
'Availability': s.select_one('p.availability').text.strip(),
'UPC': s.find('table').find_all('tr')[0].find('td').text
})
df = pd.DataFrame(all_books)
df.to_csv('book_data.csv', index=False)
Before running the script, create a free ScraperAPI account and add your API key to the script within the scraperapi variable.
1. Creating our scraping plan
After getting a clear objective, the next step is navigating to the website to plan how we’ll get the data out.
The website itself is a combination of paginated pages, category pages, and book pages. To get detailed information for each book, we’ll have to navigate to each of those book pages and extract the elements.
However, if we click on any of these books, you’ll notice there’s no way to predict what the URL will be – besides using the name of the book as part of the URL:
https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html

That said, upon a closer look, in the paginated series, the site displays 20 books from a total of 1000 books, and if we click on the next button at the bottom of the page, the URL changes to:
https://books.toscrape.com/catalogue/page-2.html
And the number just keeps increasing with each next page:
In other words, by programmatically increasing the number in the URL, we’re able to navigate to the paginated series.
With this information, we can now write our plan down:
- We’ll navigate through the paginated series and gather all books’ URLs
- Then, we can send a request to download each individual book page’s HTML and gather the details we’re interested in
- Lastly, we’ll format all this information into a DataFrame we can use directly or export it into another format if we’d like
Let’s now translate all of this into code!
2. Setting Up Our Project
Let’s create a new project directory and a book_scraper.py file inside. Then, import all our dependencies at the top of the file.
import requests #pip install requests
from bs4 import BeautifulSoup #pip install beautifulsoup4
import pandas as pd #pip install pandas
Note: If you don’t have any of these packages installed, just use the pip command next to it in the code snippet above.
We’ll also need to have access to a ScraperAPI key. Just create a free ScraperAPI account, and you’ll find your key on your dashboard.
Instead of sending all requests from our machine, we’ll send them through ScraperAPI servers. This way, ScraperAPI will smartly rotate our IP between requests and choose the right HTTP headers to ensure a near 100% success rate.
This is important because most websites would quickly identify your scraper and ban your IP, blocking any traffic coming from your machine – potentially forever.
Although there are many ways to do this, we’ll use a quite simple one today. From your dashboard, copy the Sample API Code and paste it into a variable called scraperapi – but deleting the value within the url parameter:
scraperapi = 'https://api.scraperapi.com?api_key=YOUR_API_KEY&url='
This way, we can add scraperapi to our get requests and concatenate it with the target URL. Just to keep it clean.
3. Testing our requests
The first thing to do is test one important hypothesis: if we change the number in https://books.toscrape.com/catalogue/page-2.html to a 1, can we get the homepage? This is critical because it is going to be our initial request.
Two ways we can test this:
1. We change it directly on the address bar on our browser (which works)
2. Send a request through our script (which also works)
response = requests.get('https://books.toscrape.com/catalogue/page-1.html')
print(response.status_code)
It print a 200 status code.
For one last test, let’s add ScraperAPI to the mixed:
response = requests.get(scraperapi + 'https://books.toscrape.com/catalogue/page-1.html')
It returns a 200 status code. Perfect!
4. Navigating through the paginated series
To change the number within our URL, we need to set a range through a range() function and then use an f-string to add the variable to our URL string in the proper place.
for x in range(1, 6):
response = requests.get(scraperapi + f'https://books.toscrape.com/catalogue/page-{x}.html')
Note: The first number in the range specified the initial count (we have to specify it’s 1 because the count starts at 0 by default), and the second the last number of the rage – in this case, the rage will be from 1 to 6 without including 6.
We’re using such a short range to limit our request to five and ensure it is working. Let’s run it with the following print() statement for visual feedback.
print('this is request number ' + str(x) + '. Status code: ' + str(response.status_code))
Result:
this is request number 1. Status code: 200
this is request number 2. Status code: 200
this is request number 3. Status code: 200
this is request number 4. Status code: 200
this is request number 5. Status code: 200
5. Parsing the HTML response
Before we can extract any element, we first need to process the returned HTML with BeautifulSoup and turn it into a parse tree.
soup = BeautifulSoup(response.content, 'html.parser')
This way, we can now use HTML tags and CSS selectors to pick specific elements within the parse tree. But what element first? Well, if we take a look at the page, each book is inside a card-like element.

With that premise in mind, we should be able to find the right element to target in order to store all of them into a single variable.
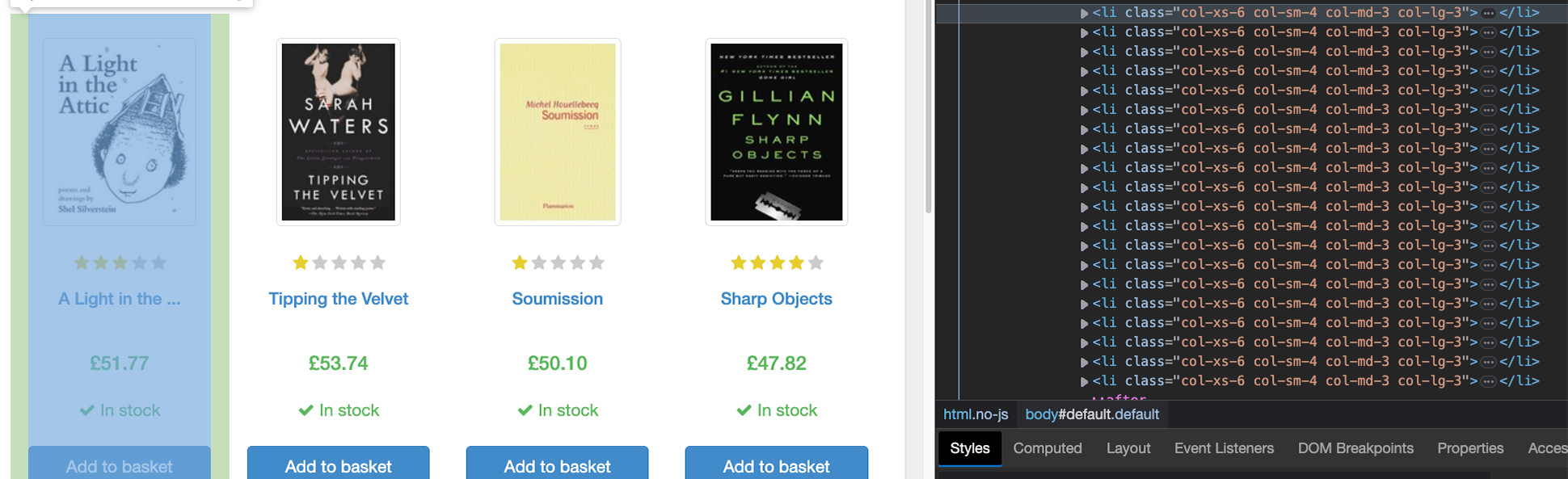
Bingo! Each element is represented as a <li> tag with a unique CSS class we can easily target using the .find_all() method.
onpage_books = soup.find_all('li', class_='col-xs-6')
As we said before, each page has 20 books, so let’s print the length of onpage_books to ensure we’re getting them all.
print(len(onpage_books))

We got them!
6. Grabbing all book URLs
If we follow our code so far, this is what’s happening:
- A request is sent
- The response (raw HTML) is parsed
- The entire list of books within the page is stored into a single variable
- Next request is sent, and the loop continues
So what’s the next logical step? Grabbing the URL for each book.
In the HTML, we can see that the URL to the book is inside a <a> tag within the href attribute.

So let’s target that element and print its value to see what we get – also, set range(1, 2) so we can test all of this with only one page.
for book in onpage_books:
book_url = book.find('a')['href']
print(book_url)
Note: In this for loop, we’re assigning each element inside onpage_books (every book card listed) to the variable book and then looking inside it for the <a> tag.
a-light-in-the-attic_1000/index.html
tipping-the-velvet_999/index.html
soumission_998/index.html
sharp-objects_997/index.html
sapiens-a-brief-history-of-humankind_996/index.html
the-requiem-red_995/index.html
the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
the-black-maria_991/index.html
starving-hearts-triangular-trade-trilogy-1_990/index.html
shakespeares-sonnets_989/index.html
set-me-free_988/index.html
scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
rip-it-up-and-start-again_986/index.html
our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
olio_984/index.html
mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
libertarianism-for-beginners_982/index.html
its-only-the-himalayas_981/index.html
Although it is returning the value within the href attribute, the URL isn’t complete, but don’t worry. We’ll fix that in the next step.
7. Sending individual requests and parsing each book URL
Even though we’re not getting the entire URL, we’re getting the most important part: the slug.
To send a request to each book URL, all we need to do is add the missing part:
https://books.toscrape.com/catalogue/
… and we can do that right inside our get() request:
r = requests.get(scraperapi + 'https://books.toscrape.com/catalogue/' + books.find('a')['href'])
Our scraper is now requesting each book’s HTML file, so just like before, we must parse it with BeautifulSoup:
s = BeautifulSoup(r.content, 'html.parser')
Inside s, we now have the parse tree representing the book page.
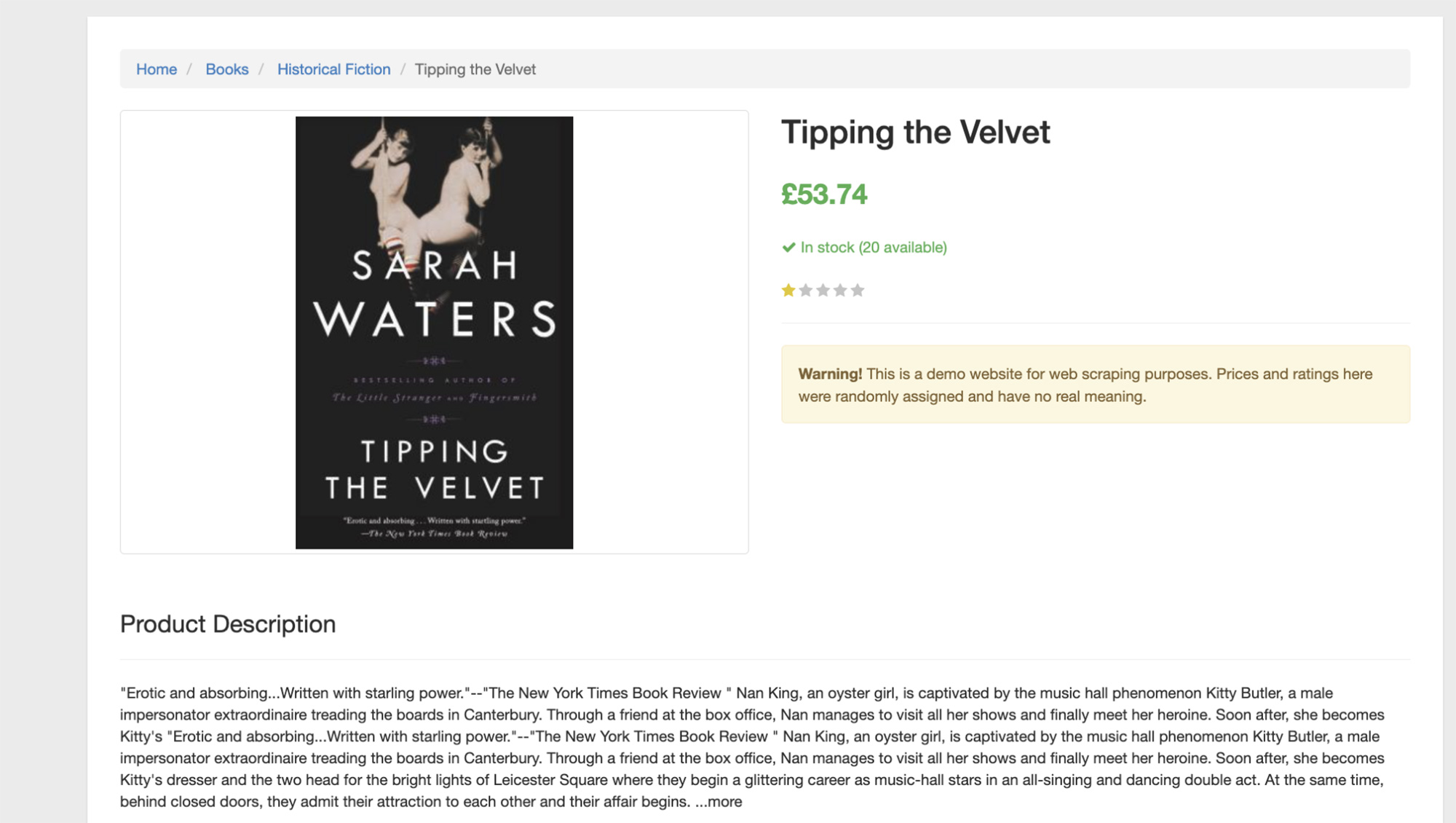
To run another test and ensure we’re in the right place, let’s print the title of the book, which is the only <h1> tag on the page.
title = s.find('h1').text
print(title)
A Light in the Attic
Tipping the Velvet
Soumission
Sharp Objects
Sapiens: A Brief History of Humankind
The Requiem Red
The Dirty Little Secrets of Getting Your Dream Job
The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics
The Black Maria
Starving Hearts (Triangular Trade Trilogy, #1)
Shakespeare's Sonnets
Set Me Free
Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)
Rip it Up and Start Again
Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Olio
Mesaerion: The Best Science Fiction Stories 1800-1849
Libertarianism for Beginners
It's Only the Himalayas
It worked! We are now accessing all book titles programmatically.
8. Picking the rest of the elements
In order to construct a DataFrame quickly and well-structured, we need to create an empty array – after our scraperapi variable – and store all the book data in it.
all_books = []
But we still have to inspect the page and get the rest of the selectors.
- To get the description, we could target the
<p>element wrapping it.

However, there are many more <p> tags inside the HTML without any unique class. So what do we do in these cases?
Thanks to the consistent web structure, we can actually take all <p> elements and then choose the right one from the index like so:

To translate this into Python, we can use the select() method instead of find_all(), just for simplicity’s sake.
s.select('p')[3].text
- For the price, we actually have a clear class we can target:
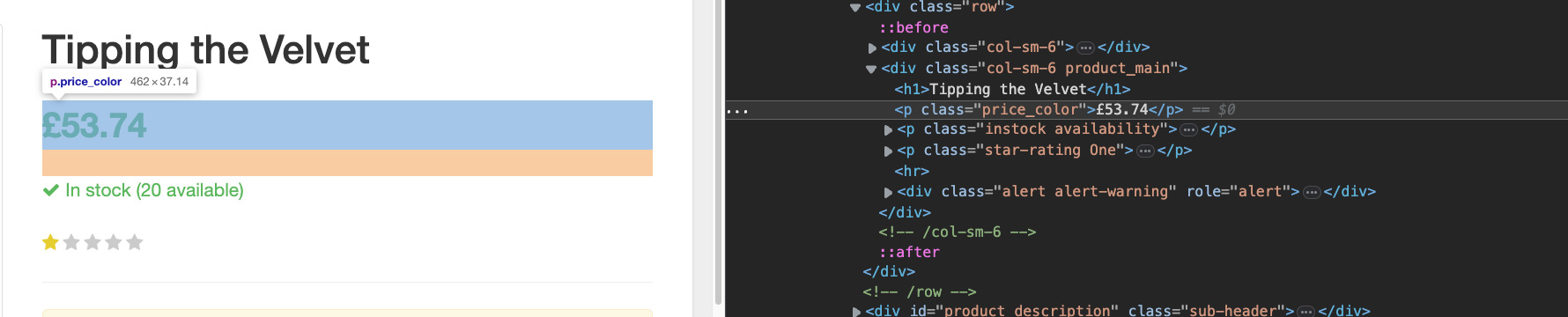
s.find('p', class_='price_color')
- The category is served within the
<ul>with class breadcrumb. However, the<li>tags inside don’t have any class to differentiate themselves.

To handle this, we can do a similar trick we did with the description. First, we get the list using the find() method – which selects the first element it finds – and then we can select() all <li> elements, picking the right one from the index.
s.find('ul', class_='breadcrumb').select('li')[2].text.strip()
Note: Adding the strip() method of the end will clean the string (text) from the white space inside it.
- The availability is quite simple because it has a unique class.
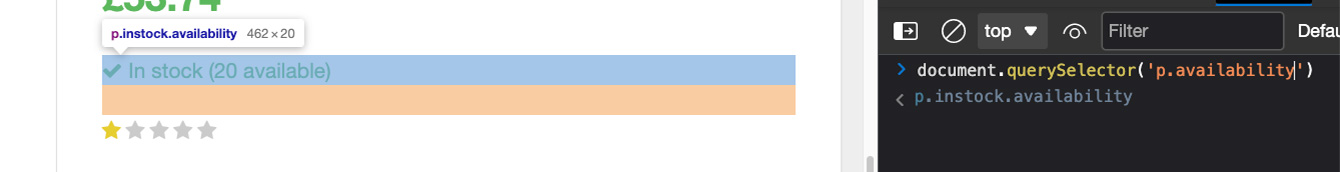
s.select_one('p.availability').text.strip()
- The UPC requires a little tricky logic because the information is inside a table. So first, we have to
find()the table and thenfind_all()the<tr>elements – which represent the rows. This is important because we need the list of rows to pick the first one using the index [0]. Lastly, we canfind()the<td>tag inside the selected row.

s.find('table').find_all('tr')[0].find('td').text
9. Appending the data to our array
Previously, we added an empty array at the top of our file. It’s time to use it.
all_books.append({
'Name': s.find('h1').text,
'Description': s.select('p')[3].text,
'Price': s.find('p', class_='price_color').text,
'Category': s.find('ul', class_='breadcrumb').select('li')[2].text.strip(),
'Availability': s.select_one('p.availability').text.strip(),
'UPC': s.find('table').find_all('tr')[0].find('td').text
})
We’re basically giving a structure to our data, so every set of name, description, etc. is now a single item within the array. If we print it, we’ll get items like this:
{
"Name": "A Light in the Attic",
"Description": "It's hard to imagine a world without A Light in the Attic. This now-classic collection of poetry and drawings from Shel Silverstein celebrates its 20th anniversary with this special edition. Silverstein's humorous and creative verse can amuse the dowdiest of readers. Lemon-faced adults and fidgety kids sit still and read these rhythmic words and laugh and smile and love th It's hard to imagine a world without A Light in the Attic. This now-classic collection of poetry and drawings from Shel Silverstein celebrates its 20th anniversary with this special edition. Silverstein's humorous and creative verse can amuse the dowdiest of readers. Lemon-faced adults and fidgety kids sit still and read these rhythmic words and laugh and smile and love that Silverstein. Need proof of his genius? RockabyeRockabye baby, in the treetopDon't you know a treetopIs no safe place to rock?And who put you up there,And your cradle, too?Baby, I think someone down here'sGot it in for you. Shel, you never sounded so good. ...more",
"Price": "£51.77",
"Category": "Poetry",
"Availability": "In stock (22 available)",
"UPC": "a897fe39b1053632"
}
10. Creating a DataFrame out of the array
Here comes the easiest part. Thanks to Pandas, transforming our array into a DataFrame is as simple as:
df = pd.DataFrame(all_books)
If we print it out, here’s what we get:
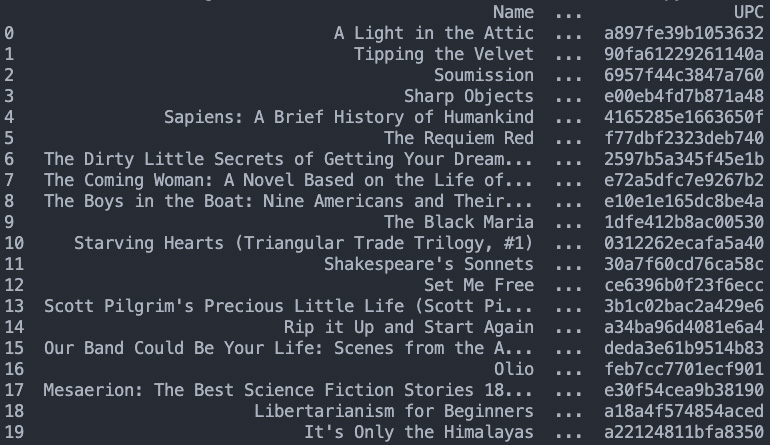
This dataset is ready for further analysis or even exported into other formats like a CSV file:
df.to_csv('book_data.csv')
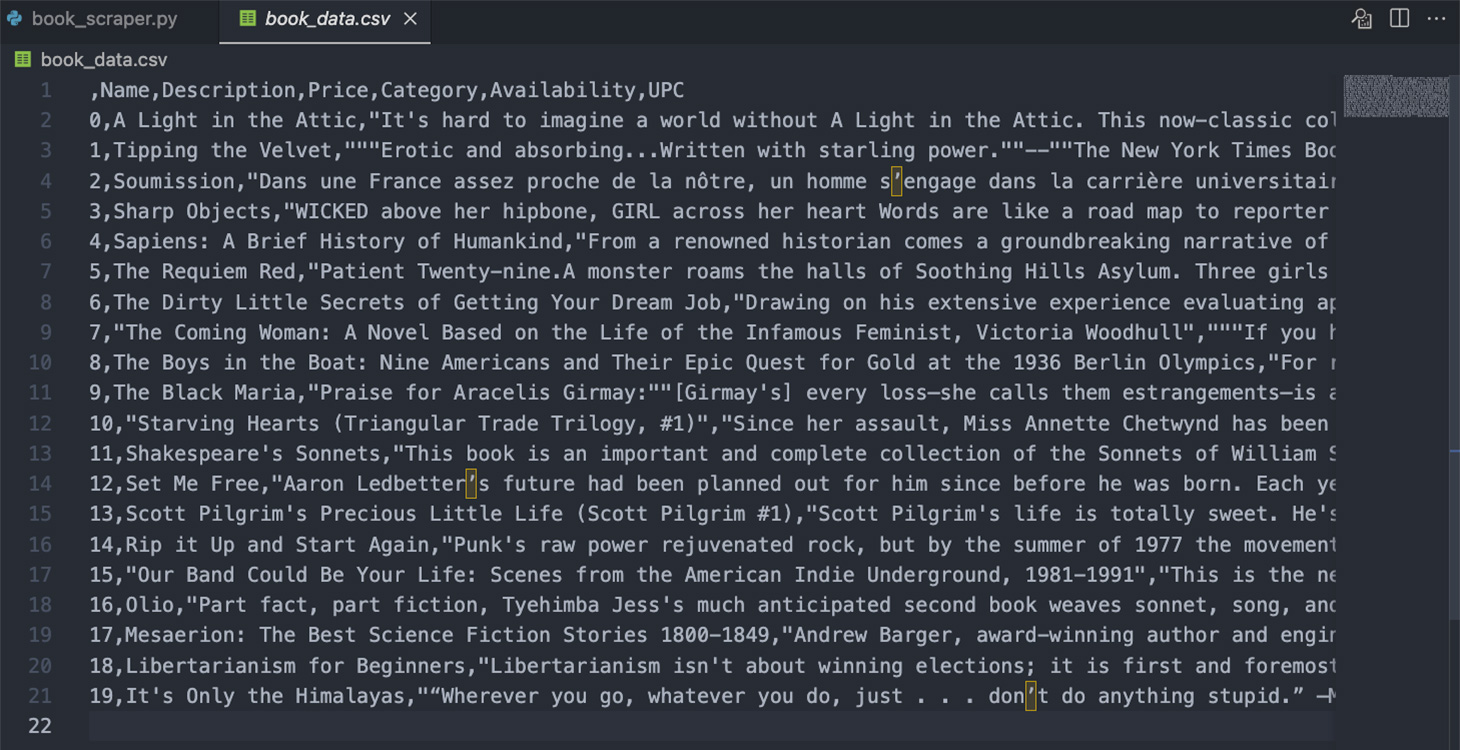
Note: You can remove the index by setting:
df.to_csv('book_data.csv', index=False)
Before moving on, here are a few ideas you could try using this dataset and put your web scraping skills into practice:
- Determine which category has the most expensive books, giving you a potential clue on what niche is more profitable as a writer or bookseller.
- Extract the number of rate stars and see if there’s any correlation between price and ratings.
- Or run a tone analysis and see if highly rated books use a particular tone of voice in their description.
- Create a list of out-of-stock books – which you can use to automate printing or ordering more.
- Create a book recommendation system based on book price and rating.
Wrapping Up
Congratulations, you can now set range (1, 51) to get the data from 1000 books in just a couple of seconds and format all that information into a structured dataset. Every variable is labeled (headers) and can be analyzed in relation to others.
However, to gather all 1000 books, your scraper will need to send 50 requests to navigate the paginated pages and 1k requests to gather all books’ details. Without ScraperAPI taking care of all technical complexity in the background, a similar script would get blocked after just a couple of requests.
Using ScraperAPI will open a sea of possibilities and allow you to gather accurate data consistently, no matter how complex or advanced the site’s anti-scraping mechanisms are.
Just imagine how comprehensive this dataset can be using ScraperAPI’s Amazon Endpoint to scrape millions of book pages from Amazon.
If you want to try ScraperAPI for yourself – and if you haven’t done so already – create a free ScraperAPI account and enjoy 5,000 free API credits so you can get scraping in seconds.
Happy scraping!





