



In this tutorial, we’ll use Python’s Requests and BeautifulSoup to collect Etsy product data with a simple script.
TL;DR: Full Code
For those in a hurry, here’s the complete code snippet:
import requests
from bs4 import BeautifulSoup
import pandas as pd
etsy_products = []
for x in range(1, 251):
response = requests.get(
f'https://api.scraperapi.com?api_key=Your_API_Key&url=https://www.etsy.com/c/clothing/boys-clothing/costumes?ref=pagination&explicit=1&page={x}')
soup = BeautifulSoup(response.content, 'html.parser')
products = soup.select('li.wt-show-md.wt-show-lg')
for product in products:
product_name = product.select_one(
'h3.v2-listing-card__title').text.strip()
product_price = product.select_one('span.currency-value').text
product_url = product.select_one(
'li.wt-list-unstyled div.js-merch-stash-check-listing a.listing-link')['href']
etsy_products.append({
'name': product_name,
'price': product_price,
'URL': product_url
})
df = pd.DataFrame(etsy_products)
df.to_csv('etsy-products.csv', index=False)
Note: You’ll need to add your API key to the api_key= parameter in the request for it to work. Create a free ScraperAPI account to get 5,000 API credits to get started.
Follow along to see how we wrote this script from scratch.
Step-by-Step Guide to Building an Etsy Scraper
For this tutorial, we will scrape Etsy’s costumes section for boys using Requests and BeautifulSoup, and get the name, price, and URL of every product.
Let’s install our dependencies using the following command:
pip install requests beautifulsoup4
Once those are installed, create a new directory for your project and, within it, an etsy-scraper.py file.
Step 1: Download Etsy’s HTML for Parsing
Without HTML, there is no parsing. With that in mind, let’s send an HTTP request to the server and store the response in a page variable.
import requests
from bs4 import BeautifulSoup
response = requests.get(
'https://www.etsy.com/c/clothing/boys-clothing/costumes?ref=pagination&explicit=1&page=1')
Notice that we’re using a different category page’s URL version.
If you navigate to the website manually, you’ll see that this is the original version of the URL:
https://www.etsy.com/c/clothing/boys-clothing/costumes?ref=catnav-10923
However, when we navigate through the pagination – which we’ll definitely want to do to scrape all pages from this category – we’ll need to give access to each page to our script.
To make it more visual, here’s what the second URL of the pagination looks like:
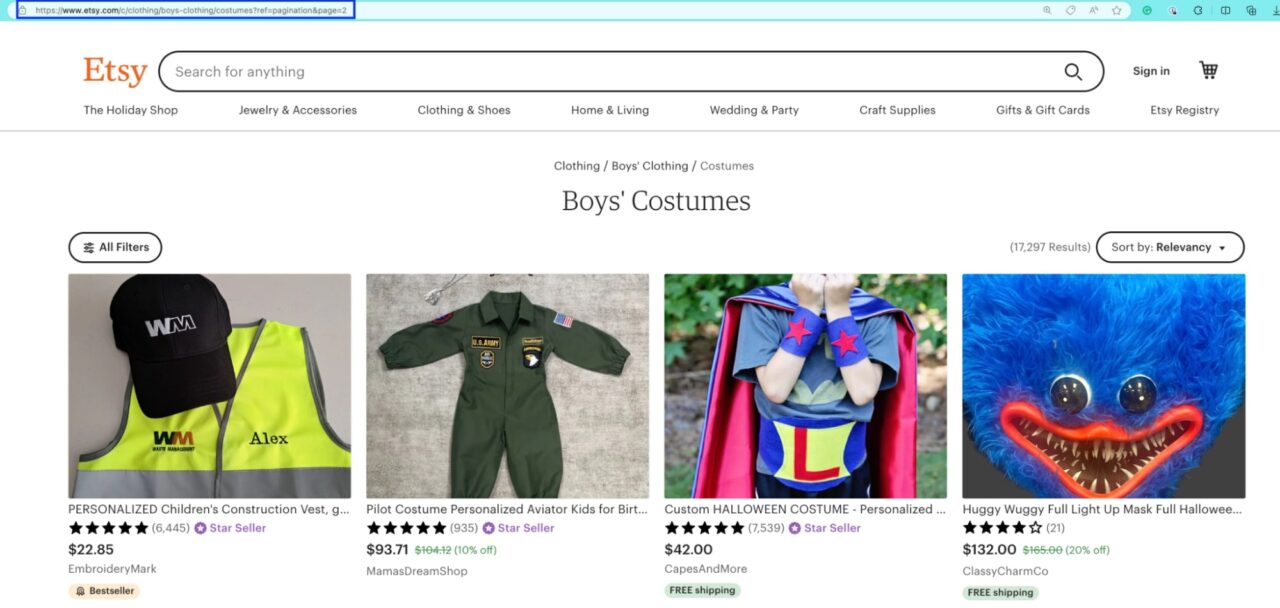
https://www.etsy.com/c/clothing/boys-clothing/costumes?ref=pagination&page=2
Therefore, we can access page 1 simply by changing the ‘page’ parameter within the URL.
We’ll go deeper into that later in this tutorial, but for now, let’s try to get some data out of this first page.
Step 2: Finding CSS Properties to Target
There are two common ways to define the CSS selectors we’ll need to extract the product’s name, price, and URL.
The first way is to manually go to the page itself and use the Inspector Tool. You can open it with CTRL + Shift + C on Windows or CMD + Shift + C on Mac.
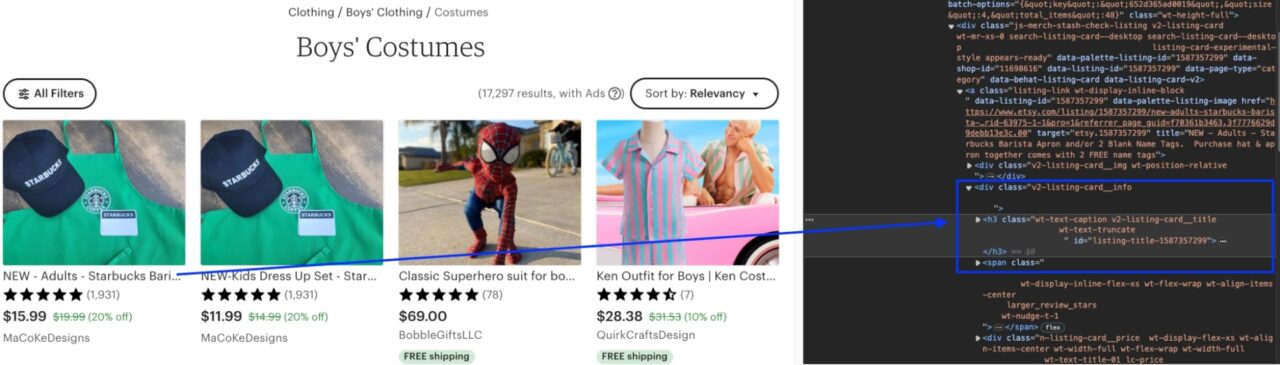
Or we can use a tool like SelectorGadget to select the correct CSS class for the element we want to scrape.
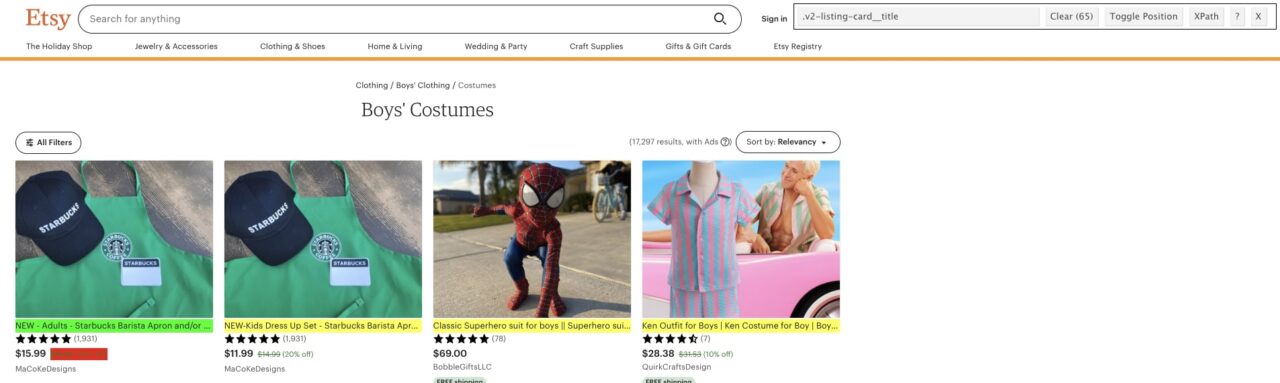
After some testing, we’ve determined that there are 64 product listings per page, and these are the CSS classes for each element:
- Product name:
.v2-listing-card__title - Product price:
.lc-price .lc-price .currency-value - Product URL:
li.wt-list-unstyled div.js-merch-stash-check-listing a.listing-link
Note: Technically, on the page above are 65 elements. That’s because while testing the scraper, the page adds a recently viewed section.
If you’re following along, you might wonder how we got the properties for the product URL. That’s where things get tricky.
Using SelectorGadget for Logic Testing
Not every website is built the same way, so there’s no way to get the CSS properties directly from SelectorGadget, because the product’s URL is not in a particular element every time.
For example, the product’s URL tends to be inside the same element as the product’s name on many websites. That’s not the case for Etsy, though.
However, there’s another way we can use SelectorGadget to find CSS elements like URLs: testing the properties.
With SelectorGadget open, we first found the highest-level element for the product cards themselves.
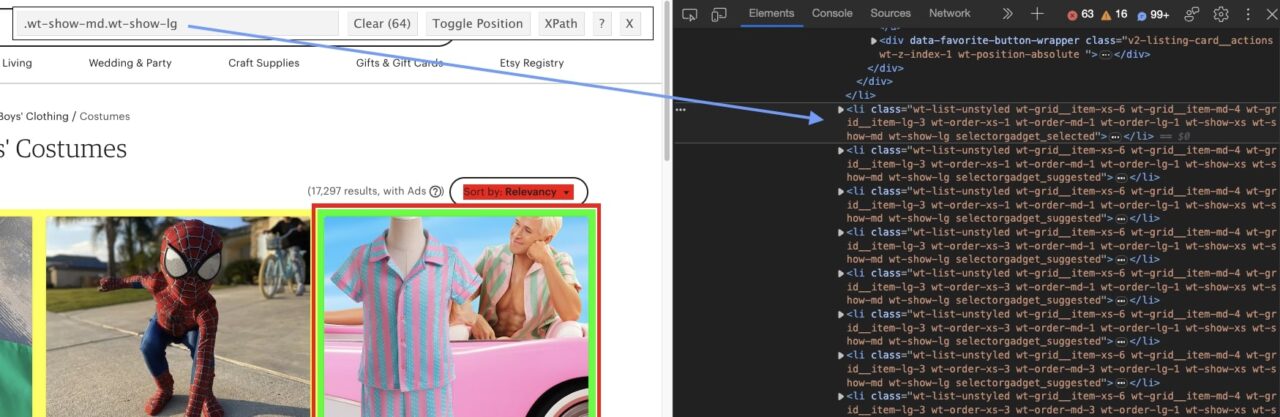
Inside the li element, we want to find the main div where the product’s URL is contained.
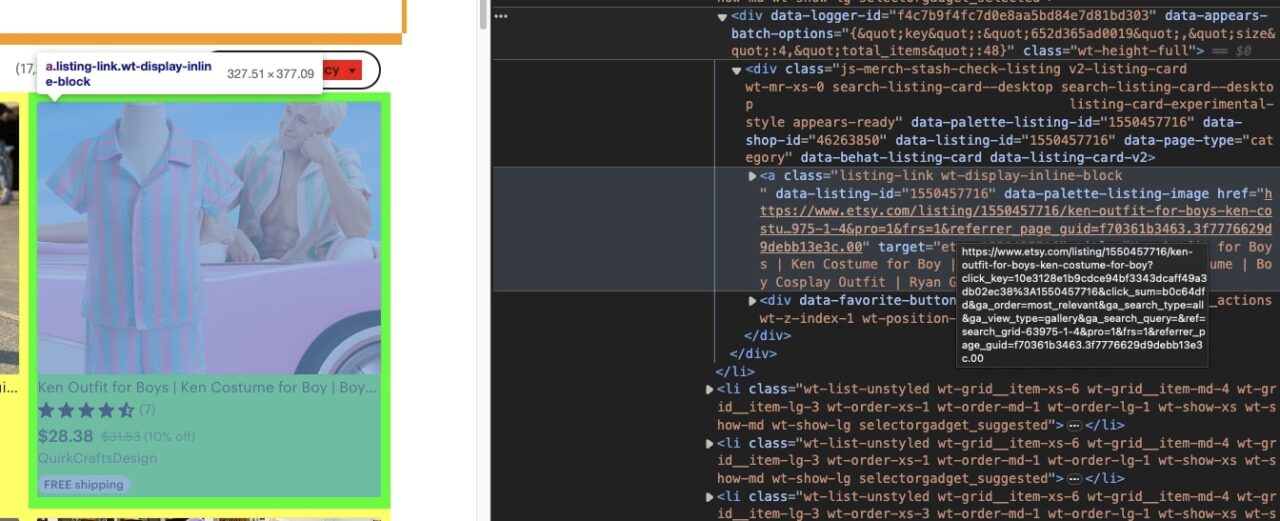
Next, we know we want to target the a tag within that div to find the URL. We used SelectorGadget to verify that we were picking 64 elements to verify that our logic was correct.
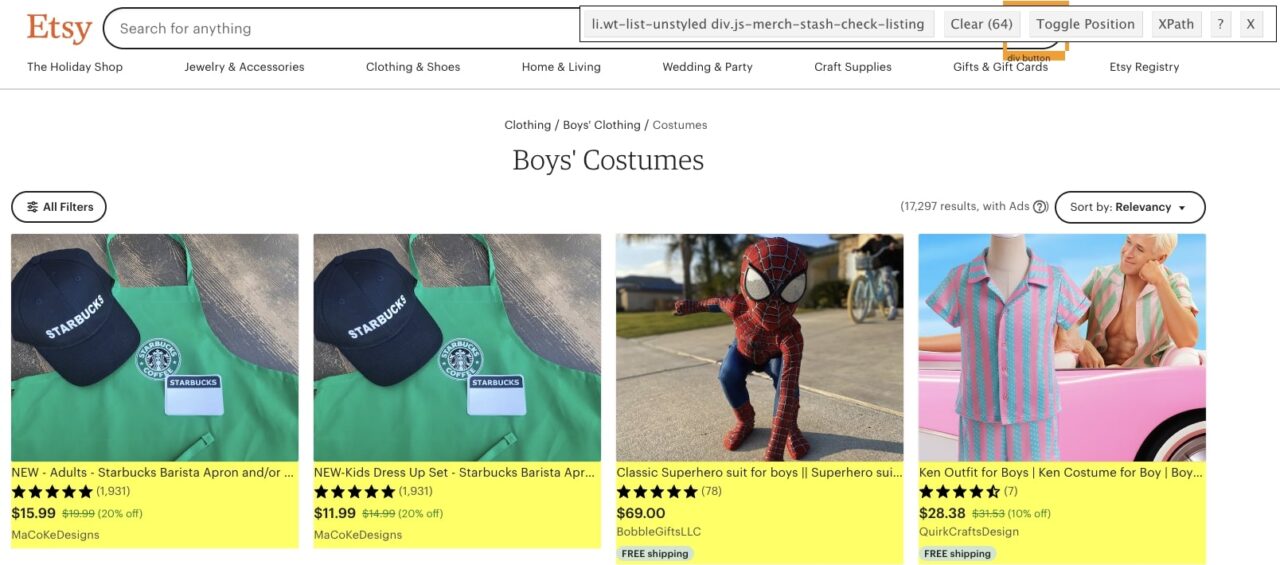
That’s why it’s so important to understand how web pages are structured when web scraping.
Tip: You can use our CSS selectors cheat sheet to learn more about CSS selectors and to help you speed up scraper development time.
Now that we know how to select each element to get the data we want, let’s test our script.
Step 3: Testing Our Parsing Script
For this test, we want to run the whole script to extract the names of the 64 products on the page.
Here’s where BeautifulSoup will come in handy, allowing us to parse the raw HTML and pick specific elements based on CSS selectors.
To get started, pass response through BS4:
soup = BeautifulSoup(response.content, 'html.parser')
In order to get the name of every product, we first need to get all the listings on the page (so we can loop through them) into a single variable:
products = soup.select('li.wt-show-md.wt-show-lg')
products contains all the li elements and the information within them.
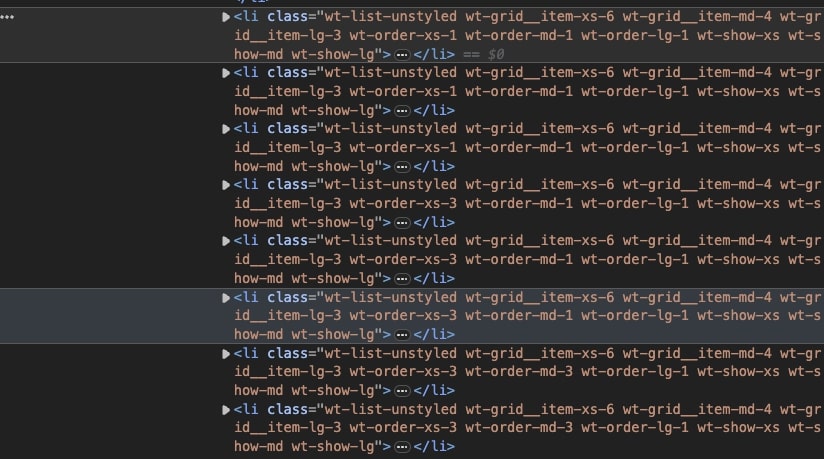
By creating a loop, we can extract all the information we want from them.
Now, let’s use the selector we chose earlier to extract each product’s name and print() them to the console.
for product in products:
product_name = product.select_one('h3.v2-listing-card__title').text
print(product_name)
Here’s what we get:
There’s a problem: the script is picking a lot of whitespace, which will add noise information to our dataset. A quick fix for this is to add .strip().
product_name = product.select_one('h3.v2-listing-card__title').text.strip()
Now all unnecessary whitespaces are removed from the strings:
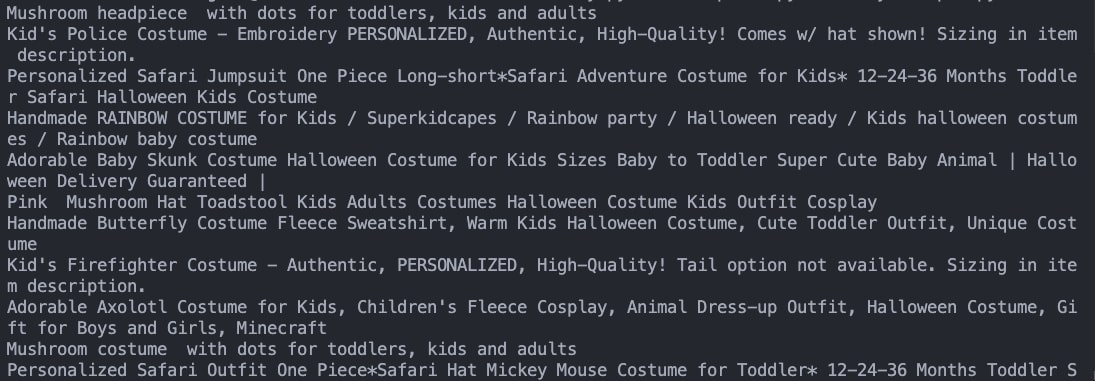
Sweet, 64 clean product names extracted in just a couple of seconds!
Step 4: Get the Rest of the Elements Using the Same Logic
Alright, now that we know our script is working, let’s scrape the price and URL of each of these elements on the page.
product_price = product.select_one('span.currency-value').text

product_url = product.select_one('li.wt-list-unstyled div.js-merch-stash-check-listing a.listing-link')['href']
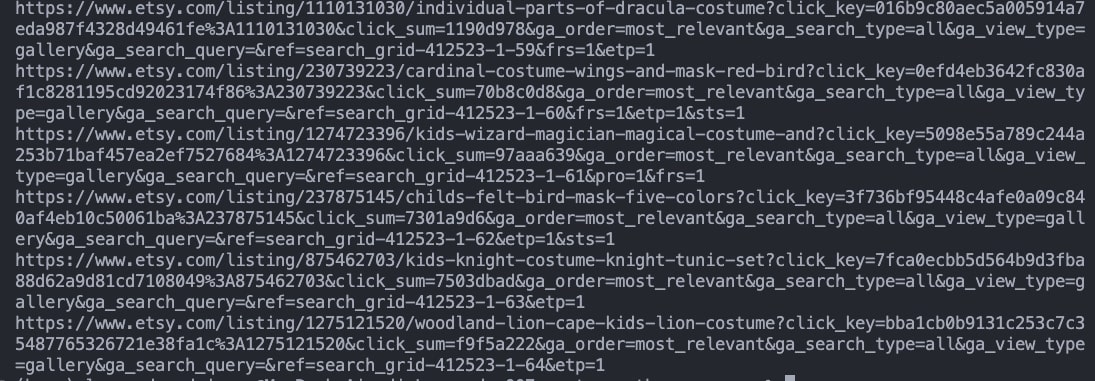
In the case of attributes, instead of using the .text() method, we tell BS4 to extract the value inside the attribute selected – in this case, href.
Step 5: Sending Our Data to a CSV
Alright, so far, our scraper is working perfectly. However, logging the data into our console might not be the best way to handle it. Let’s create a data frame and export it as a CSV file to organize our data for later analysis.
To do this, we’ll need to make a couple of changes.
1. Import Pandas to your project and create an empty array where we’ll store all the data we’re scraping.
import pandas as pd
etsy_products = []
2. Append the extracted data to the array using the .append() method within your for loop.
etsy_products.append({
'name': product_name,
'price': product_price,
'URL': product_url
})
If you print() this etsy_products, this is what you get now:
{
"name":"Mushroom headpiece with dots for toddlers, kids and adults",
"price":"23.10",
"URL":"https://www.etsy.com/listing/741760095/mushroom-headpiece-with-dots-for?click_key=4a9ed56076feafe16426315e47a781c619b7f987%3A741760095&click_sum=22169a2c&ga_order=most_relevant&ga_search_type=all&ga_view_type=gallery&ga_search_query=&ref=search_grid-380536-1-1&etp=1&sts=1&referrer_page_guid=f7038e73a27.53aac11d85fd18db9710.00"
},
{
"name":"Personalized Safari Jumpsuit One Piece Long-short*Safari Adventure Costume for Kids* 12-24-36 Months Toddler Safari Halloween Kids Costume",
"price":"84.95",
"URL":"https://www.etsy.com/listing/1185173222/personalized-safari-jumpsuit-one-piece?click_key=249b111b036ffc9d24e0f5495d443c0ae919e00a%3A1185173222&click_sum=4191b104&ga_order=most_relevant&ga_search_type=all&ga_view_type=gallery&ga_search_query=&ref=search_grid-380536-1-2&etp=1&sts=1&referrer_page_guid=f7038e73a27.53aac11d85fd18db9710.00"
}
# ... truncated ...
You can also print the length of the list:
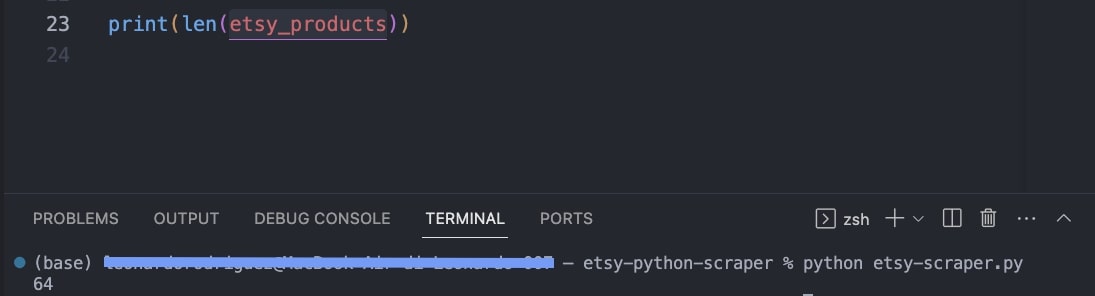
3. Create a data frame using pandas and export it as CSV.
df = pd.DataFrame(etsy_products)
df.to_csv('etsy-products.csv', index=False)
If you run your code, a new CSV file will be generated inside your project’s directory.
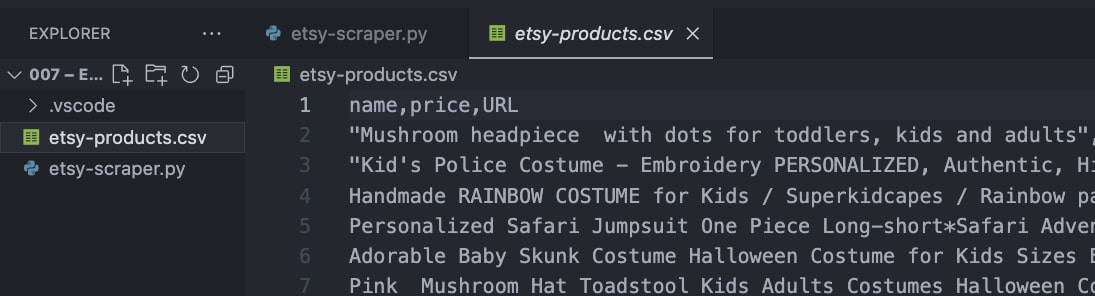
Congratulations, you just scraped Etsy!
Collecting Etsy Product Data at Scale
Now that we’ve tested our scraper on one page, we’re ready to scale things by letting it move to other pages and extract the same data.
For this to work, we’ll have to:
- Create a for loop to navigate through the pagination
- Send our requests using ScraperAPI to avoid getting blocked
1. Looping Through the Pagination
A few things to consider when writing a for loop:
- Analyze the URL of the paginated pages to determine how many of them are there – in our example category, there are 250 pages in total.
- Take a look at how numbers are increasing – in our case, the pagination increases by one in the URL with each page.
With these two things in mind, we can build the loop.
for x in range(1, 251):
response = requests.get(f'https://www.etsy.com/c/clothing/boys-clothing/costumes?ref=pagination&explicit=1&page={x}')
We’re setting the loop to start in 1 until it hits (but not including) 251. In other words, the x variable within the URL will be replaced by 1, all the way to 251 when the script will stop – it won’t send a request to “251”.
However, it won’t take too long for Etsy to block our scraper. For it to work, let’s integrate ScraperAPI into the script.
2. Using ScraperAPI for Scalability
Etsy uses several methods to keep scripts from accessing and extracting too many pages in a short amount of time. To avoid these measures, we would have to create a function that:
- Changes our IP address
- Have access to a pool of IP addresses for our script to rotate between
- Create some way to deal with CAPTCHAs
- Set the correct headers
Just to name a few.
The good news is that we can automate all of this using ScraperAPI.
All we need to do is create a free ScraperAPI account to get access to our API key.

Then, we’ll make a little adjustment to our code:
for x in range(1, 251):
response = requests.get(f'https://api.scraperapi.com?api_key=Your_API_Key&url=https://www.etsy.com/c/clothing/boys-clothing/costumes?ref=pagination&explicit=1&page={x}')
Our request will now go through https://api.scraperapi.com, passing our API key and target URL as parameters.
Note: Remember to substitute Your_API_Key with the actual key.
Put the rest of the code inside the loop and run it. You’re now scraping the entire category!
Wrapping Up
To summarize:
- The script will send a request through ScraperAPI to Etsy
- ScraperAPI will use machine learning and statistical analysis to bypass all anti-bot mechanisms and return the raw HTML
- The script will then download the HTML and parse it using BeautifulSoup
- From the soup object, it’ll create a list with all the listings on the page
- Then, it’ll loop through the listings to extract name, price, and product URL
- Next, the script will append all this data together (as an item) to the
etsy_products array - Once this is done for all the products within the page, the script will send the next request until hitting 251
The result is a CSV file filled with Etsy product data.
Of course, you can select more elements from the page (like the seller’s name and stars), and change the category URL to collect data from other categories.
If you want to learn how to scrape other websites and build scrapers in different languages, here are a few of our top resources to keep improving your craft:
- How To Scrape Amazon Product Data
- Scrape Data from Google Search Using Python and Scrapy [Step by Step Guide]
- Build a Python Web Scraper Step by Step Using Beautiful Soup
- Web Scraping Best Practices: ScraperAPI Cheat Sheet
Until next time, happy scraping!





