



Why Should You Track Keyword Rankings?
Keyword tracking can be helpful in many situations:
- Discover if your SEO campaign is working
- Spot ranking changes quickly
- Keep an eye on your competitors’ rankings
- Learn who your competitors are for specific keywords
However, collecting this data is only possible with proper tooling.
Extracting data from Google, and other search engines, requires advanced anti-scraping techniques to avoid getting your IP banned from ever using their site again – which, could you imagine not being able to use Google ever again from your machine?
That’s why services like Keyword.com use ScraperAPI to bypass CAPTCHAs and anti-scraping mechanisms and help them collect localized search data from 30+ countries across the globe.
In this tutorial, we’ll do the same and use a free ScraperAPI account to streamline the process and start getting keyword data in minutes.
1. Setting Up Your Project
First, we need to create a new directory/folder for our project (we called ours rank_tracker), open it on VScode or your favorite editor, and create a new Python file (we named it rank_scraper.py).
For this project to work, we’ll use three main tools:
- Requests – pip install requests
- Pandas – pip install pandas
- Openpyxl – pip install openpyxl
- ScraperAPI – create a free account to generate your API key
Once we have everything installed and our API key at hand, we can start by importing our dependencies to the project:
</p>
import requests
import pandas as pd
<p>To simplify things, we’ll use ScraperAPI’s Google Search endpoint to send our requests and retrieve structured JSON data from the SERPs.
This will prevent our IP from being banned, help us get accurate data, and reduce development time significantly.
2. Understanding Google Search Endpoint
ScraperAPI is an advanced web scraping tool that uses machine learning and years of statistical analysis to choose the right combination of headers and IP addresses to get a successful response from your target website.
It also comes with a set of features to automate most complexities involved in data collection like IP rotation, CAPTCHA handling, and extracting localized data.
Lucky for us, when it comes to Google Search, ScraperAPI provides a simple endpoint we can use to retrieve structured JSON data, simplifying the entire process even further:
</p>
https://api.scraperapi.com/structured/google/search
<p>To use the endpoint, we need to send a get() request alongside a couple of parameters:
'api_key'– paired with your unique API key'query'– which is the keyword you want to extract data from
Although those are the only required parameters, we can be more specific with our request by passing other parameters like:
'country'– you can use any code within this country code list to tell ScraperAPI to send your request from a specific location'tld'– to specify the domain’s TLD you want to use (like google.com vs. google.ca)'num'– determines the number of results returned per request
A Quick Look Into the Google Search Endpoint Response
Let’s send our initial request for the query “how to write a book” and see what the tool brings back:
</p>
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘country’: ‘us’,
‘query’: ‘how to write a book’
}
response = requests.get(
‘https://api.scraperapi.com/structured/google/search’,
params=payload
)
print(response.text)
<p>Here’s what the raw response looks like:
Note: You can see a full JSON response example here.
As you can see, it brings back all SERP elements in JSON format, making it much easier to find and extract the information we’re interested in.
At the time, we’re solely interested in organic results, so let’s see what’s inside:
</p>
“organic_results”: [
{
“position”: 7,
“title”: “How to Write a Book (with Tactics from Bestsellers)”,
“tags”: “Feb 7, 2023 —”,
“snippet”: “Feb 7, 2023 — 1. Start with an idea that you love; 2. Research by reading books by other writers; 3. Outline the story; 4. Plan the opening sentence …”,
“highlighs”: [
“books”,
“story”
],
“link”: “https://blog.reedsy.com/how-to-write-a-book/”,
“displayed_link”: “https://blog.reedsy.com › how-to-write-a-book”
},
<p>Inside “organic_results”, there’s a list of JSON objects containing the information for every search result found on the page in the order they appear on the SERP.
However, if that’s true, why does it say it’s in position 7? Well, that’s because ScraperAPI takes into consideration other search elements like ads and people also ask boxes when assigning the position.
For example, in this case, the element in position 1 is an ad:
</p>
“answer_box”: {
“position”: 1,
“link”: “https://www.masterclass.com/articles/how-to-write-a-book”
}
<p>One more thing to notice before we move on. When the num parameter isn’t set, the Google Search endpoint will default to Google’s ten search results per page configuration.
Now that we know where every element we want to extract is stored, it’s time to extract them.
3. Extracting Organic Search Data
Unlike when working with HTML, we don’t need to parse the response with a tool like Beautiful Soup. Instead, we’ll store the JSON data into a variable and then select all search results (which are in the “organic_results” field):
</p>
response = requests.get(‘https://api.scraperapi.com/structured/google/search’, params=payload)
search_data = response.json()
results = search_data[“organic_results”]
print(results)
<p>Now we’ve narrowed down everything to only the organic results:
</p>
[
{
“position”:7,
“title”:“How to Write a Book: 21 Crystal-Clear Steps to Success”,
“tags”:“Apr 22, 2022 —”,
“snippet”:“Apr 22, 2022 — Write a Book Outline; Write One Chapter at a Time; Speak Your Book; Avoid Writer’s Block; Don’t Edit While You Write; Push Past The “Messy”\\xa0…”,
“highlighs”:[
“Write a Book”
],
“link”:“https://self-publishingschool.com/how-to-write-a-book/”,
“displayed_link”:“https://self-publishingschool.com › how-to-write-a-book”
},
{
“position”:8,
“title”:“How to Write a Book: Complete Step-by-Step Guide – 2023”,
“tags”:“Mar 2, 2022 —”,
“snippet”:“Mar 2, 2022 — A step-by-step guide can help new authors overcome the intimidating parts of writing a book, allowing them to stay focused and maximize\\xa0…”,
“highlighs”:[
“writing a book”
],
“link”:“https://www.masterclass.com/articles/how-to-write-a-book”,
“displayed_link”:“https://www.masterclass.com › articles › how-to-write-…”
},
{
“position”:9,
“title”:“23 Steps to Writing a Book Successfully, as a New Author”,
“snippet”:“This is the most comprehensive online guide to writing a non-fiction book. Read on Scribe to learn more about the well-tested steps we use.”,
“highlighs”:[
“writing”,
“book”
],
“link”:“https://scribemedia.com/how-to-write-book/”,
“displayed_link”:“https://scribemedia.com › Blog › Book Writing”
},
.
.
.
<p>Like with any other list, we can loop through every object and extract specific data points from each. For our example, let’s extract every result’s position, title, and URL and print them to the console:
</p>
for result in results:
position = result[“position”]
title = result[“title”]
url = result[“link”]
print(‘Page is in position: ‘ + str(position) + ” / Title: “ + title + ” / and URL: “ + url)
<p>Here’s what we got back:
</p>
Page is in position: 10 / Title: How to Write a Book (with Tactics from Bestsellers) / and URL: https://blog.reedsy.com/how-to-write-a-book/
Page is in position: 11 / Title: How to Write a Book: 21 Crystal-Clear Steps to Success / and URL: https://self-publishingschool.com/how-to-write-a-book/
Page is in position: 12 / Title: 23 Steps to Writing a Book Successfully, as a New Author / and URL: https://scribemedia.com/how-to-write-book/
Page is in position: 13 / Title: How to Write a Book: 15 Steps (with Pictures) / and URL: https://www.wikihow.com/Write-a-Book
Page is in position: 14 / Title: How to Write a Book From Start to Finish: A Proven Guide / and URL: https://jerryjenkins.com/how-to-write-a-book/
Page is in position: 15 / Title: How to Write a Book in 2023: The Ultimate Guide for Authors / and URL: https://kindlepreneur.com/how-to-write-a-book/
Page is in position: 16 / Title: How to Write a Book in 12 Simple Steps [Free … / and URL: https://selfpublishing.com/how-to-write-a-book/
Page is in position: 17 / Title: How to Write a Book: The Ultimate Guide / and URL: https://www.briantracy.com/blog/writing/how-to-write-a-book/
Page is in position: 18 / Title: It’s National Novel Writing Month. Here’s how to write a book / and URL: https://www.npr.org/2020/04/27/845797464/if-youve-always-wanted-to-write-a-book-here-s-how
<p>5. Storing the Data Within an Array
So we know we can get the data. Now it’s time to organize it into an array we can then use to export everything into a spreadsheet.
First, we have to create an empty array before the payload:
</p>
keyword_rankings = []
<p>Then, use the .append() function inside our for loop so every set of data points (position, title, and URL) gets written into the array as a single item and print the array to the console:
</p>
for result in results:
keyword_rankings.append({
‘position’: result[“position”],
‘title’: result[“title”],
‘url’: result[“link”]
})
print(keyword_rankings)
<p>Here’s how the result looks:
</p>
{
“position”: 7,
“title”: “How to Write a Book: 21 Crystal-Clear Steps to Success”,
“url”: “https://self-publishingschool.com/how-to-write-a-book/”
},
{
“position”: 8,
“title”: “23 Steps to Writing a Book Successfully, as a New Author”,
“url”: “https://scribemedia.com/how-to-write-book/”
},
<p>6. Exporting the Top 100 Ranking Pages Into a Spreadsheet
As mentioned before, the Google Search endpoint defaults to ten results, but it can show more results if we pass the num parameter with a higher number in the request. This parameter tops at 100, as that’s the maximum number of results Google search can show in a single request.
If you want to get all results available for a query, then you can use the start parameter to create a loop for the tool to iterate through Google’s pagination. Taking 10 as the base number of results per page, you can begin at zero and increase the start parameter by ten on every loop.
For example:
- start = 0 – page 1
- start = 10 – page 2
- start = 20 – page 3
In our case, we’ll follow a common trait of keyword research tool and just scrape the top 100 pages of the given keyword. To do so, let’s set num to 100 within the payload.
</p>
payload = {
‘api_key’: ‘5bc85449d28e162fb0416d6c5b4ac5b0’,
‘country’: ‘us’,
‘num’: 100,
‘query’: ‘how to write a book’
}
<p>From there, we can use Pandas to turn our array into a data frame and export it as XLSX file with a simple method:
</p>
df = pd.DataFrame(keyword_rankings)
df.to_excel(“keyword_rankings.xlsx”)
<p>Note: You can change the name of the file to be whatever you want or even add a path so the file is stored in the folder of your choosing. Also, if it gives you an error, try pip install openpyxl and retry.
The data frame will take the key name (position, title, url) and use them as the headings of the spreadsheet. The final result will look like this:
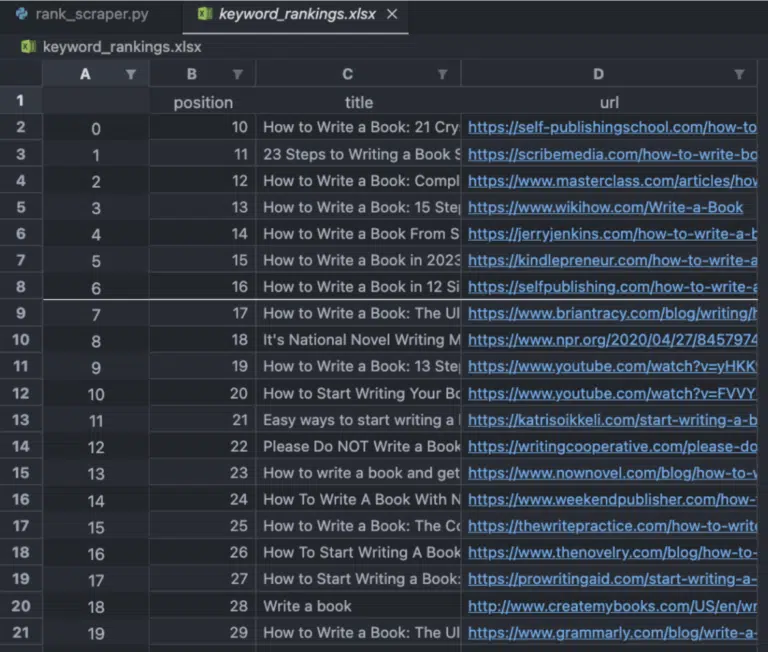
And there you go, 100 keyword rankings into a spreadsheet in just a couple of seconds!
Wrapping Up
As promise, here’s the full code you can start using right now:
</p>
import requests
import pandas as pd
keyword_rankings = []
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘country’: ‘us’,
‘num’: 100,
‘query’: ‘how to write a book’
}
response = requests.get(‘https://api.scraperapi.com/structured/google/search’, params=payload)
response.raise_for_status()
if response.status_code != 204:
search_data = response.json()
results = search_data[“organic_results”]
for result in results:
keyword_rankings.append({
‘position’: result[“position”],
‘title’: result[“title”],
‘url’: result[“link”]
})
df = pd.DataFrame(keyword_rankings)
df.to_excel(“keyword_rankings.xlsx”)
<p>Just change the keyword and name of the file, and you can track as many keywords as you want. You could also dynamically write the file’s name based on the keyword targeted and loop through a list of keywords to gather all the data with one script.
Remember, with your free account, you get up to 5000 free API credits to try all of ScraperAPI’s functionality for free for the first seven days. But if you’re serious about using data to grow your business, you can choose the plan that better suits your needs.
We hope this tutorial was helpful and can help you get started in your data collection journey.
Until next time, happy scraping!





