



Whether you’re an investor tracking your portfolio or a firm researching new opportunities, web scraping stock market price data gives you access to real-time stock prices, historical trends, and critical financial insights. Platforms like Yahoo Finance, Google Finance, Investing.com, and Bloomberg make it possible to gather reliable stock price data at scale.
In this beginner-friendly tutorial, we’ll show you how to build a web scraping tool using Python, BeautifulSoup, and requests to extract stock price data. You’ll also learn how to organize and store this data in a CSV file for further analysis. Let’s get started.
How to Build a Stock Market Pricing Data Scraper
For this exercise, we’ll be scraping investing.com to extract up-to-date stock prices from Microsoft, Coca-Cola, and Nike, and storing it in a CSV file. We’ll also show you how to protect your web-scraping bot from being blocked by anti-scraping mechanisms and techniques using ScraperAPI.
Note: The script will work to scrape stock market data even without ScraperAPI, but will be crucial for scaling your project later.
Although we’ll be walking you through every step of the stock market data extraction process, having some knowledge of the Beautiful Soup library beforehand is helpful. If you’re totally new to this library, check out our beautiful soup tutorial for beginners. It’s packed with tips and tricks, and goes over the basics you need to know to scrape almost anything.
With that out of the way, let’s jump into the Python stock scraper code so you can learn how to scrape stock market data.
1. Setting Up Our Stock Market Web Scraping Project
To begin, we’ll create a folder named “scraper-stock-project”, and open it from VScode (you can use any text editor you’d like). Next, we’ll open a new terminal and install our two main dependencies for this project:
- pip3 install bs4
- pip3 install requests
After that, we’ll create a new file named “stockData-scraper.py” and import our dependencies to it.
</p>
<pre>import requests
from bs4 import BeautifulSoup</pre>
<p>With Requests, we’ll be able to send an HTTP request to download the HTML file which is then passed on to BeautifulSoup for parsing. So let’s test it by sending a request to Nike’s stock page:
</p>
<pre>url = 'https://www.investing.com/equities/nike'
page = requests.get(url)
print(page.status_code)</pre>
<p>By printing the status code of the page variable (which is our request), we’ll know for sure whether or not we can scrape the page. The code we’re looking for is a 200, meaning it was a successful request.

Success! Before moving on, we’ll pass the response stored in page to Beautiful Soup for parsing:
</p>
<pre>soup = BeautifulSoup(page.text, 'html.parser')</pre>
<p>You can use any parser you want, but we’re going with html.parser because it’s the one we like.
Related Resource: What is Data Parsing in Web Scraping? [Code Snippets Inside]
2. Inspect the Website’s HTML Structure (Investing.com)
Before we start scraping, let’s open https://www.investing.com/equities/nike in our browser to get more familiar with the website.
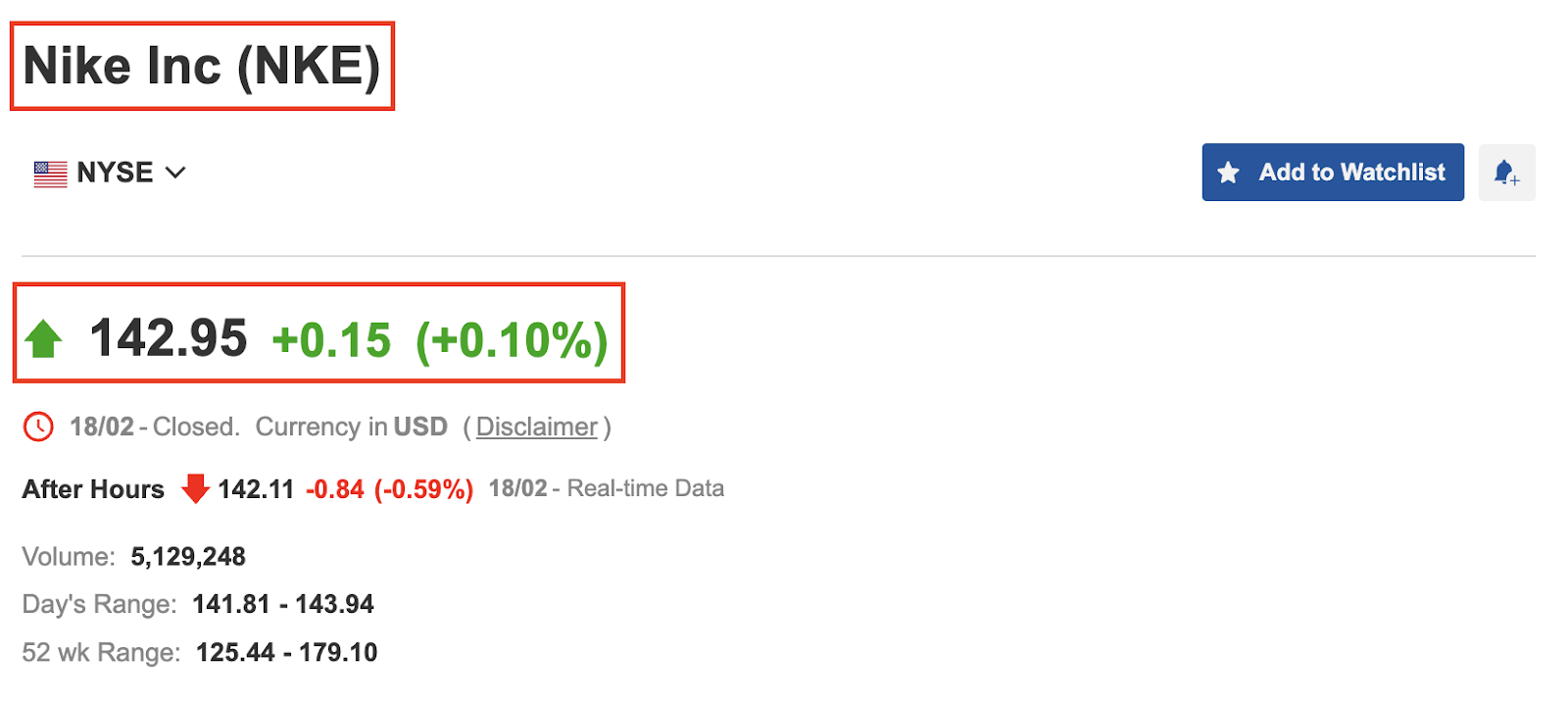
As you can see in the screenshot above, the page displays the company’s name, stock symbol, price, and price change. At this point, we have three questions to answer:
- Is the data being injected with JavaScript?
- What attribute can we use to select the elements?
- Are these attributes consistent throughout all pages?
Check for JavaScript
There are several ways to verify if some script is injecting a piece of data, but the easiest way is to right-click, View Page Source.
It looks like there isn’t any JavaScript that could potentially interfere with our scraper. Next we’ll do the W same for the rest of the information. We didn’t find any additional JavaScript we’re good to go.
Note: Checking for JavaScript is important because Requests can’t execute JavaScript or interact with the website, so if the information is behind a script, we would have to use other tools to extract it, like Selenium.
Picking the CSS Selectors
Now let’s inspect the HTML of the site to identify the attributes we can use to select the elements.

Extracting the company’s name and the stock symbol will be a breeze. We just need to target the H1 tag with class ‘text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2’.
However, the price, price change, and percentage change are separated into different spans.
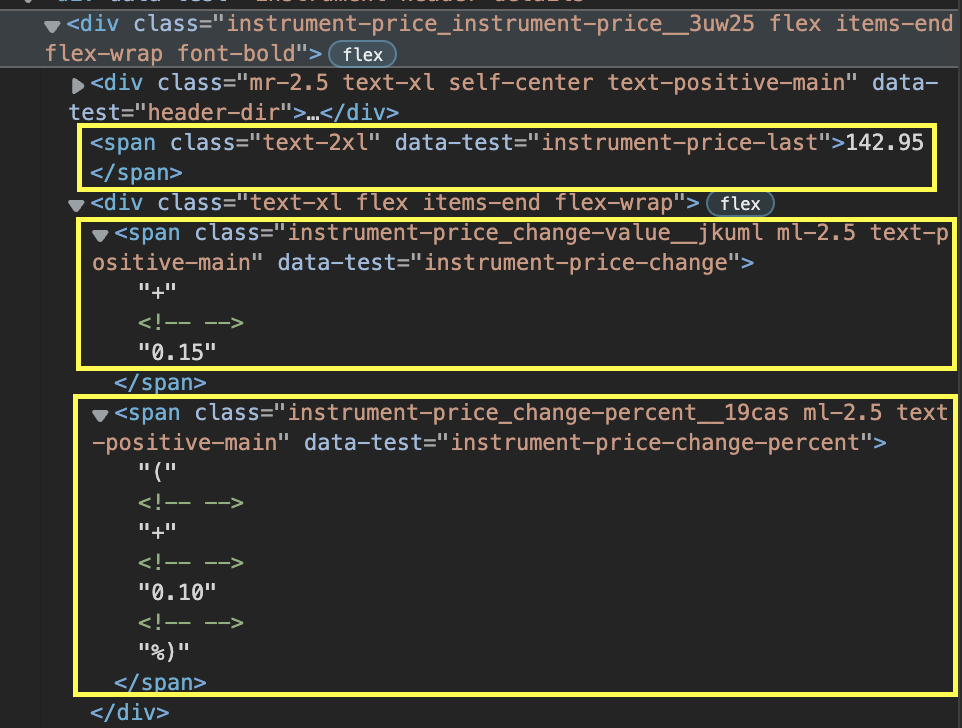
What’s more, depending on whether the change is positive or negative, the class of the element changes, so even if we select each span by using their class attribute, there will still be instances when it won’t work.
The good news is that we have a little trick to get it out. Because Beautiful Soup returns a parsed tree, we can now navigate the tree and pick the element we want, even though we don’t have the exact CSS class.
What we’ll do in this scenario is go up in the hierarchy and find a parent div we can exploit. Then we can use find_all(‘span’) to make a list of all the elements containing the span tag – which we know our target data uses. And because it’s a list, we can now easily navigate it and pick those we need.
So here are our targets:
</p>
<pre>company = soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')[0].text
change = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')[2].text</pre>
<p>Now for a test run:
</p>
<pre>print('Loading: ', url)
print(company, price, change)</pre>
<p>And here’s the result:

3. Scrape Multiple Financial Stock Data
Now that our parser is working, let’s scale this up and scrape several stocks. After all, a script for tracking just one stock data is likely not going to be very useful.
We can make our scraper parse and scrape several pages by creating a list of URLs and looping through them to output the data.
</p>
<pre>urls = [
'https://www.investing.com/equities/nike',
'https://www.investing.com/equities/coca-cola-co',
'https://www.investing.com/equities/microsoft-corp',
]
for url in urls:
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
company = soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')[0].text
change = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')[2].text
print('Loading: ', url)
print(company, price, change)</pre>
<p>Here’s the result after running it:
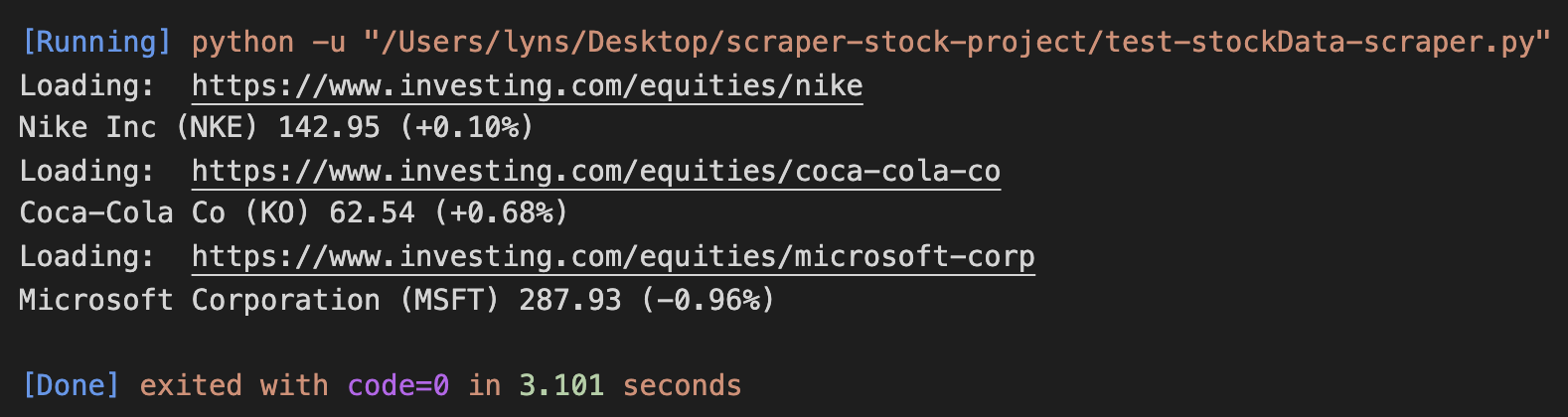
Awesome, it works across the board!
We can keep adding more and more pages to the list but eventually, we’ll hit a big roadblock: anti-scraping techniques.
4. Integrating ScraperAPI’s Web Scraping Tools to Handle IP Rotation and CAPCHAs
Not every website likes to be scraped, and for a good reason. When scraping a website, we need to have in mind that we are sending traffic to it, and if we’re not careful, we could be limiting the bandwidth the website has for real visitors, or even increasing hosting costs for the owner. That said, as long as we respect web scraping best practices, we won’t have any problems with our projects, and we won’t cause the sites we’re scraping any issues.
However, it’s hard for businesses to differentiate between ethical scrapers and those that will break their sites. For this reason, most servers will be equipped with different systems like
- Browser behavior profiling
- CAPTCHAs
- Monitoring the number of requests from an IP address in a time period
These measures are designed to recognize bots, and block them from accessing the website for days, weeks, or even forever.
Instead of handling all of these scenarios individually, we’ll just add two lines of code to make our requests go through ScraperAPI’s servers and get everything automated for us.
First, let’s create a free ScraperAPI account to access our API key and 5000 free API credits for our project.
Now we’re ready to add to our loop a new params variable to store our key and target URL and use urlencode to construct the URL we’ll use to send the request inside the page variable.
</p>
<pre> params = {'api_key': 'YOUR_API_KEY', 'url': url}
page = requests.get('http://api.scraperapi.com/', params=urlencode(params))</pre>
<p>Oh! And we can’t forget to add our new dependency to the top of the file:
</p>
<pre>from urllib.parse import urlencode</pre>
<p>Every request will now be sent through ScraperAPI, which will automatically rotate our IP after every request, handle CAPCHAs, and use machine learning and statistical analysis to set the best headers to ensure success.
Quick Tip: ScraperAPI also allows us to scrape a dynamic site by setting ‘render’: true as a parameter in our params variable. ScraperAPI will render the page before sending back the response.
5. Store The Extracted Stock Prices and Financial Data In a CSV File
To store your data in an easy-to-use CSV file, simply add these three lines between your URL list and your loop:
</p>
<pre>file = open('stockprices.csv', 'w')
writer = csv.writer(file)
writer.writerow(['Company', 'Price', 'Change'])=</pre>
<p>This will create a new CSV file and pass it to our writer (set in the writer variable) to add the first row with our headers.
It’s essential to add it outside of the loop, or it will rewrite the file after scraping each page, basically erasing previous data and giving us a CSV file with only the data from the last URL from our list.
In addition, we’ll need to add another line to our loop to write the scraped data:
</p>
<pre>writer.writerow([company.encode('utf-8'), price.encode('utf-8'), change.encode('utf-8')])</pre>
<p>And one more outside the loop to close the file:
</p>
<pre>file.close()</pre>
<p>6. Finished Python Stock Scraper: Stock Market Data Web Scraper Script
You’ve made it! You can now use this script with your own API key and add as many stocks as you want to scrape:
</p>
<pre>#dependencies
import requests
from bs4 import BeautifulSoup
import csv
from urllib.parse import urlencode
#list of URLs
urls = [
'https://www.investing.com/equities/nike',
'https://www.investing.com/equities/coca-cola-co',
'https://www.investing.com/equities/microsoft-corp',
]
#starting our CSV file
file = open('stockprices.csv', 'w')
writer = csv.writer(file)
writer.writerow(['Company', 'Price', 'Change'])
#looping through our list
for url in urls:
#sending our request through ScraperAPI
params = {'api_key': 'YOUR_API_KEY', 'url': url}
page = requests.get('http://api.scraperapi.com/', params=urlencode(params))
#our parser
soup = BeautifulSoup(page.text, 'html.parser')
company = soup.find('h1', {'class': 'text-2xl font-semibold instrument-header_title__GTWDv mobile:mb-2'}).text
price = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')[0].text
change = soup.find('div', {'class': 'instrument-price_instrument-price__3uw25 flex items-end flex-wrap font-bold'}).find_all('span')[2].text
#printing to have some visual feedback
print('Loading :', url)
print(company, price, change)
#writing the data into our CSV file
writer.writerow([company.encode('utf-8'), price.encode('utf-8'), change.encode('utf-8')])
file.close()</pre>
<p>When Is The Best Time to Scrape Stock Prices and Data?
To get the latest stock price data, you should consider the best time to run your stock scraper—especially if you’re analyzing patterns or making decisions around stock trading or planning to extract finance data from Yahoo and similar platforms.
For example, if you’re scraping data from NYC’s stock exchange, it closes at 5 pm EST on Fridays and opens on Monday at 9:30 am. So there’s no point in running your scraper over the weekend. It also closes at 4 pm so that you won’t see any changes in the price after that.

Another variable to keep in mind is how often you need to update the data. The most volatile times for the stock exchange are opening and closing times. So it might be enough to run your script at 9:30 am, at 11 am, and at 4:30 pm to see how the stocks closed. Monday’s opening is also crucial to monitor as many trades occur during this time.
Unlike other markets like Forex, the stock market typically doesn’t make too many crazy swings. That said, oftentimes news and business decisions can heavily impact stock prices – take Meta shares crash or the rise of GameStop share price as examples – so reading the news related to the stocks you are scraping is vital.
Easily Schedule Web Scraping Stock Market Pricing Data with ScraperAPI’s
We hope this tutorial helped you build your own stock market data scraper or at least point you in the right direction.
If you’re looking for an automated data scraping solution, ScraperAPI’s DataPipeline is a great option. It makes scheduling your stock market data scraping projects easy, so you don’t have to worry about different time zones. Simply set your desired scheduling time, and ScraperAPI’s web scraping tool will automatically run, delivering the latest financial data in structured JSON format right to you. Sign up here to start with a 7-day free trial.
Until next time, happy scraping!





