



In this guide, we’ll show you how to extract data from Macy’s product pages using Python and BeautifulSoup to get the data and ScraperAPI to bypass Macy’s anti-scraping mechanisms.
TL; DR: Full Macy’s Product Data Scraper
For those in a hurry, here’s the full script we’ll build in this tutorial:
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "API_KEY"
url = "https://www.macys.com/shop/featured/christmas%20sweaters"
payload = {"api_key": API_KEY, "url": url}
r = requests.get("https://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
# Find all product containers
product_containers = soup.find_all("div", class_="productThumbnail")
# List to hold the scraped data
product_data_list = []
# Iterate through each product container
for product_container in product_containers:
# Extract brand
brand_element = product_container.select_one(".productBrand")
brand_name = brand_element.text.strip() if brand_element else None
# Extract price
price_element = product_container.select_one(".prices .regular")
price = price_element.text.strip() if price_element else None
# Extract description
description_element = product_container.select_one(
".productDescription .productDescLink"
)
description = description_element["title"].strip() if description_element else None
# Extract rating
rating_element = product_container.select_one(".stars")
rating = rating_element["aria-label"] if rating_element else None
# Extract image URL
image_element = product_container.find("img", class_="thumbnailImage")
image_url = (
image_element["src"] if image_element and "src" in image_element.attrs else None
)
# Extract product URL
product_url_element = product_container.select_one(".productDescription a")
product_url = product_url_element["href"] if product_url_element else None
product_data = {
"Product Brand Name": brand_name,
"Price": price,
"Description": description,
"Rating": rating,
"Image URL": image_url,
"Product URL": product_url,
}
# Append the product data to the list
product_data_list.append(product_data)
print("Product Data successfully scraped, Saving Output...")
# Save the data to an Json file
output_file = "Macy_product_results.json"
with open(output_file, "w", encoding="utf-8") as json_file:
json.dump(product_data_list, json_file, indent=2)
print(f"Scraped data has been saved to {output_file}")
Note: Don’t forget to substitute API_KEY in the code with your actual ScraperAPI API key before running the script. If you don’t have one, create a free ScraperAPI account</a > to receive 5,000 API credits.
Ready to get started? Read on to discover how we’ve built this Macy’s scraper step-by-step
Scraping Macy’s Product Data
In keeping with the Christmas spirit, in this tutorial, we’ll scrape data from “christmas sweaters” search results, collecting the following data from Macy’s:
- Product Name
- Price
- Description
- Rating
- Images
- Product URL
We will also integrate ScraperAPI into our scraping process to bypass any anti-bot measures and handle our IP rotation for us.
That said, let’s get started!
Prerequisites
Here are the prerequisites for this project:
- Python Environment – version 3.8 or above, preferably
- JSON
- Requests
- BeautifulSoup
- Lxml libraries
To install these libraries, you can use the following command:
pip install requests beautifulsoup4 lxml
Note: if you find this tutorial hard to understand, please check our scraping with Python beginners guide</a > to go over the basics.
With those installed, run the following commands to set up your project structure:
mkdir macys-scraper
cd macys-scraper
Step 1: Set Up the Project
To get started, create a new macy-scraper.py file and import the necessary libraries at the top:
import requests
from bs4 import BeautifulSoup
import json
To get the data from Macy’s, we need to send a get() request through ScraperAPI – otherwise, Macy’s would quickly detect our scraper and block our IP address.
ScraperAPI is designed to bypass these challenges, handling IP rotation and ensuring that your scraping process runs smoothly without interruptions, even for the most difficult-to-scrape ecommerce sites</a >.
Using ScraperAPI is straightforward. All you need to do is send the URL of the webpage you want to scrape, along with your API key.
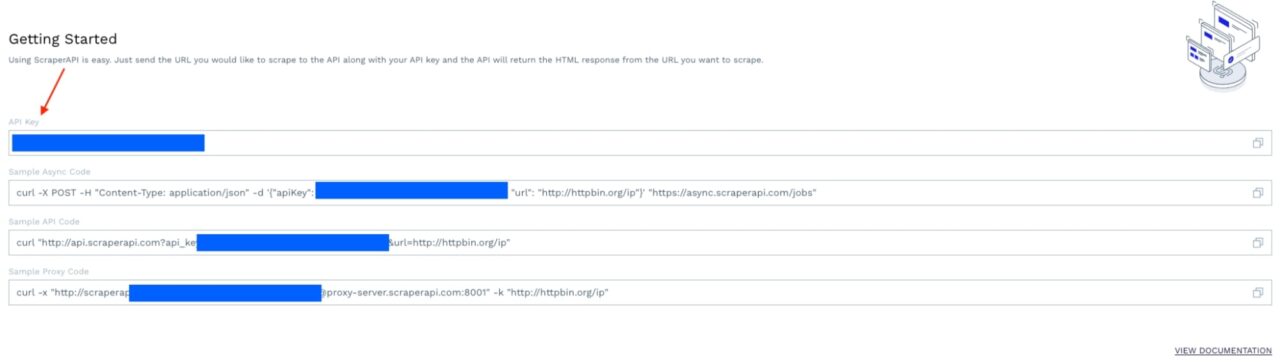
Note: Don’t have an API key? Create a ScraperAPI account to start your 7-day free trial.
Now that you have your API key, let’s add our first two variables:
API_KEY = "API_KEY"
url = "https://www.macys.com/shop/featured/christmas%20sweaters"
Step 2: Make a Request to The URL
To construct this request, we’ll write a payload to pass it alongside ScraperAPI’s standard endpoint</a >, using the Requests</a > library:
payload = {"api_key": API_KEY, "url": url}
r = requests.get("https://api.scraperapi.com", params=payload)
html_response = r.text
The payload is a dictionary that contains our API key and the URL we want to scrape. We use the requests.get() function to send a GET request to ScraperAPI. The request returns the HTML content of the search result, which is stored in the html_response variable.
Step 3: Parse the HTML
Parsing the HTML with BeautifulSoup</a > allows us to work with a simpler, nested BeautifulSoup data structure rather than raw HTML, making navigating the page’s structure easier.
soup = BeautifulSoup(html_response, "lxml")
However, before navigating the parsed tree, we must understand how to target our desired elements.
Step 4: Understanding Macy’s Site Structure
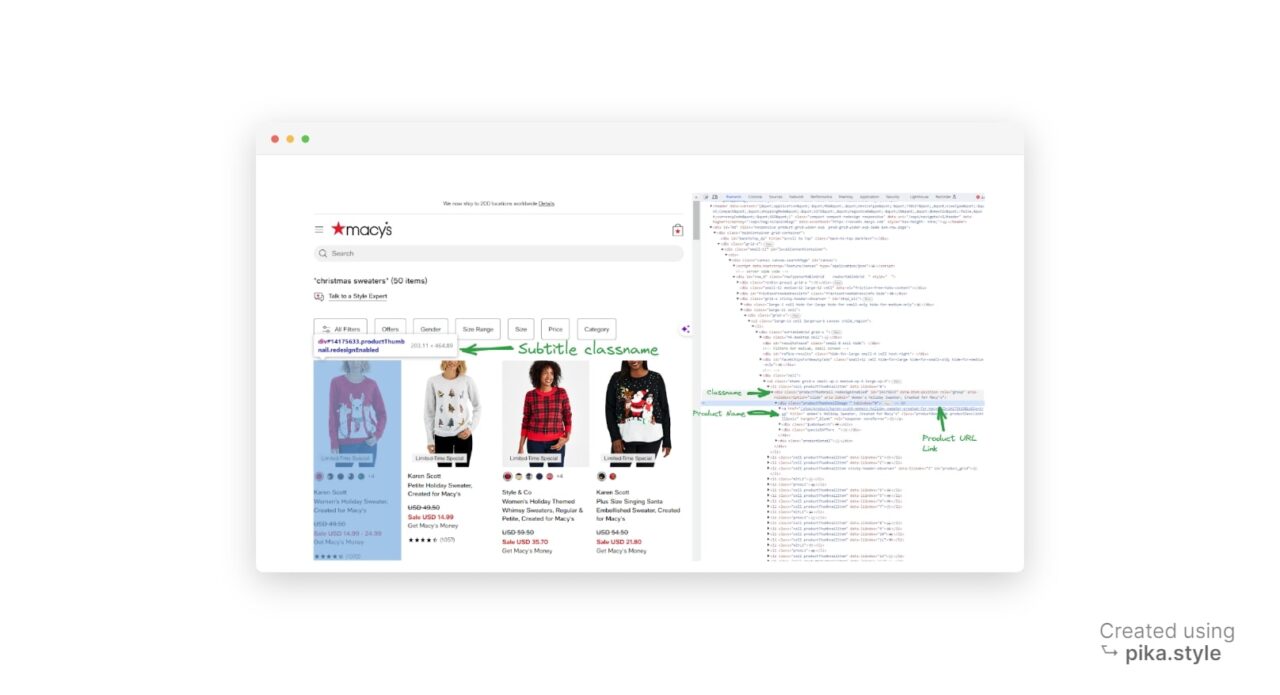
When searching for our target query, Macy’s website will return results similar to the one shown below:
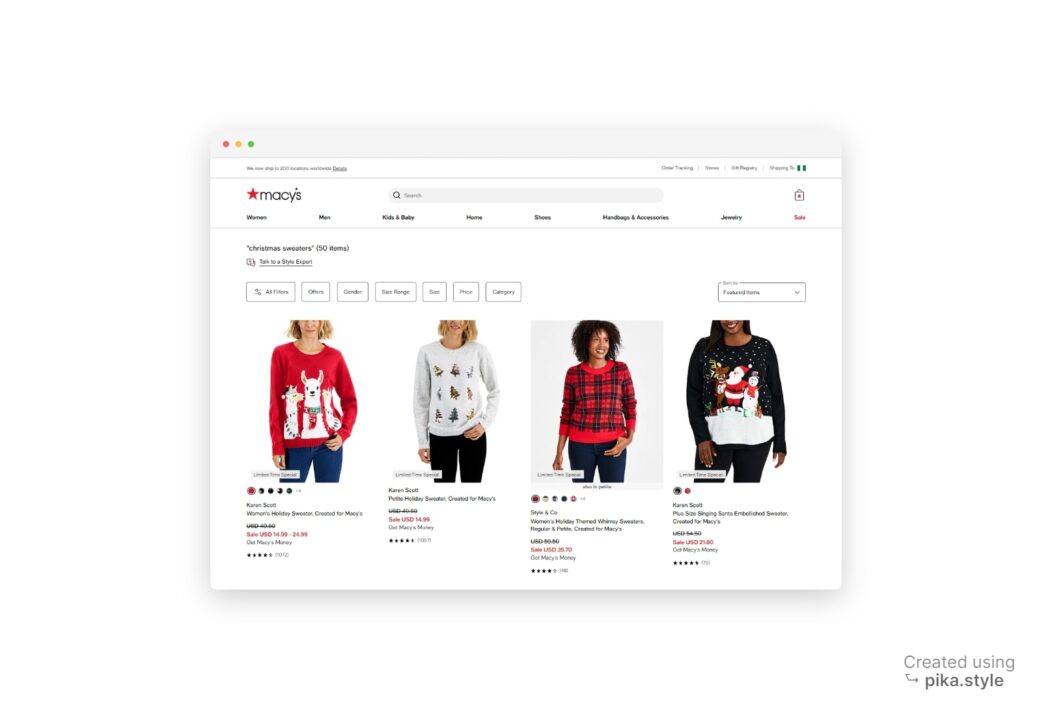
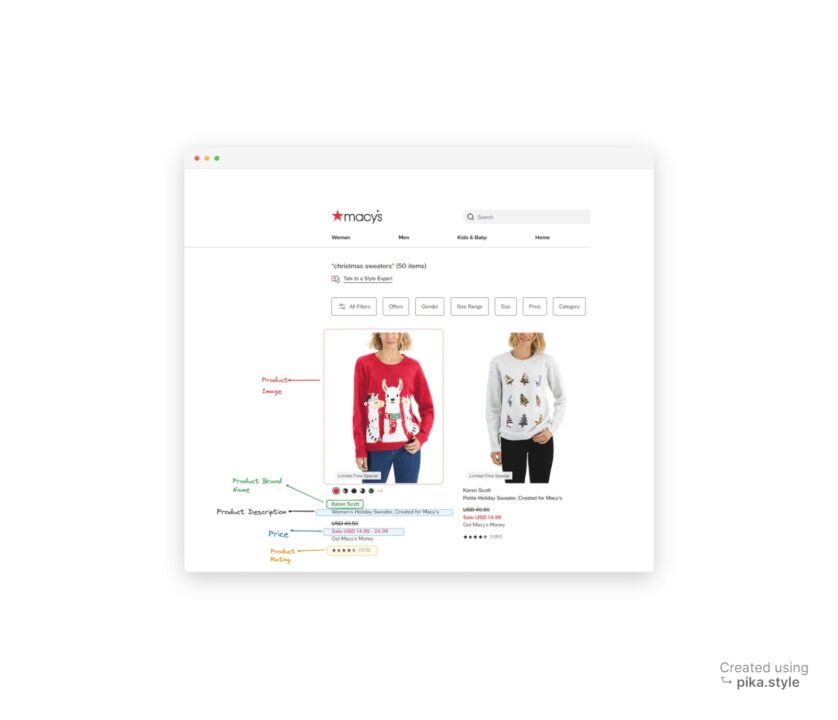
All products listed under “Christmas sweaters” can be extracted, including their brand names, prices, descriptions, ratings, images, and product links, as seen in the annotated screenshot below.
Understanding the HTML layout of a page is very important. However, thanks to Developer Tools, a feature available in most popular web browsers, you don’t need to be an HTML expert.
To access Developer Tools, you can right-click on the webpage and select “Inspect” or use the shortcut “CTRL+SHIFT+I” for Windows users or “Option + ⌘ + I” on Mac. This will open the source code of the webpage we’re targeting.
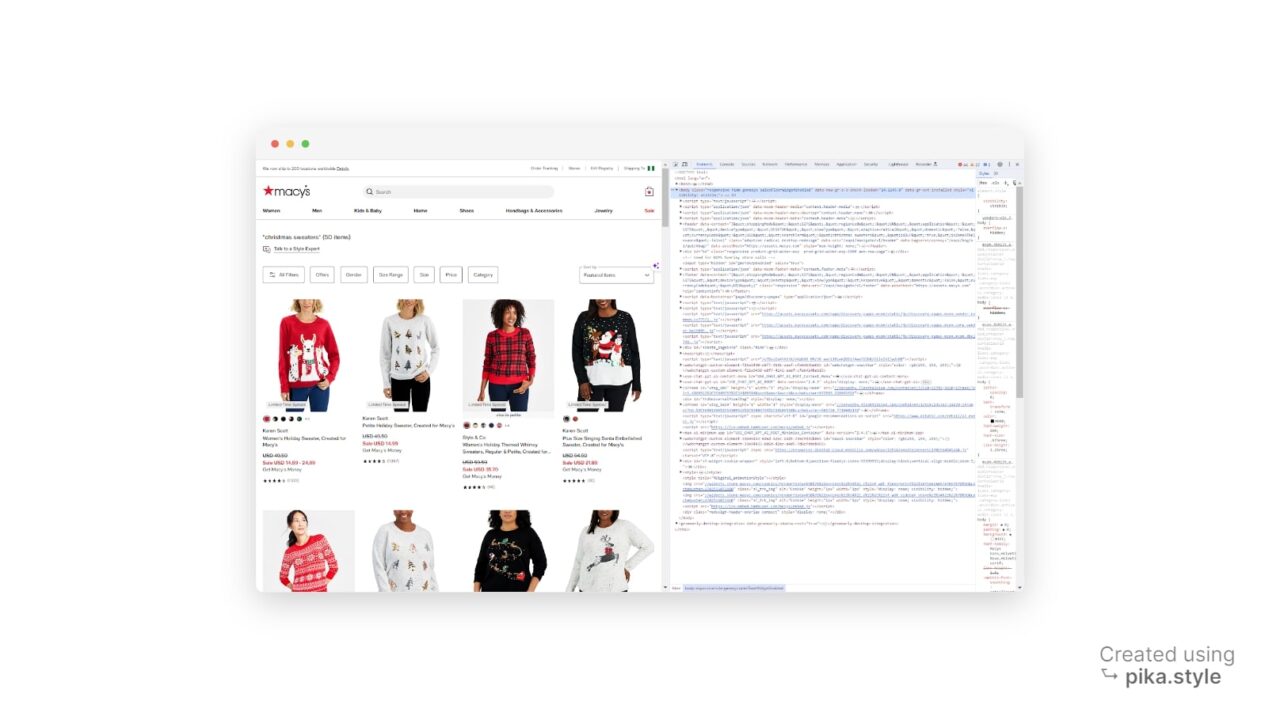
As seen above, all the products are listed as elements, so we need to collect all these listings.
To scrape an HTML element, we need an identifier associated with it. This could be the “id” of the element, any class name, or any other HTML attribute of the element. In our case, we’ll use the class name as the identifier.
After inspecting the search results page, we find that each product container is a div element with the class productThumbnail.
We can grab this HTML element by using BeautifulSoup’s find_all() function to find all instances of a div with the class productThumbnail.
product_containers = soup.find_all("div", class_="productThumbnail")
Each of these div elements represents a product container on the webpage.
We can follow the same process to find the class name for each element we want to scrape.
Step 5: Extract the Product Data
To extract the necessary data, we need to iterate through each product container using a for loop and using the select_one() and find() functions, which return the first matching element:
product_data_list = []
for product_container in product_containers:
# Extract brand
brand_element = product_container.select_one(".productBrand")
brand_name = brand_element.text.strip() if brand_element else None
# Extract price
price_element = product_container.select_one(".prices .regular")
price = price_element.text.strip() if price_element else None
# Extract description
description_element = product_container.select_one(".productDescription .productDescLink")
description = description_element["title"].strip() if description_element else None
# Extract rating
rating_element = product_container.select_one(".stars")
rating = rating_element["aria-label"] if rating_element else None
# Extract image URL
image_element = product_container.find("img", class_="thumbnailImage")
image_url = image_element["src"] if image_element and "src" in image_element.attrs else None```
After extracting the data, we create a dictionary and append it to a list named product_data.
product_data = {
"Product Brand Name": brand_name,
"Price": price,
"Description": description,
"Rating": rating,
"Image URL": image_url,
"Product URL": product_url,
}
# Append the product data to the list
product_data_list.append(product_data)
The text.strip() function extracts the element’s text content and removes any leading or trailing whitespace.
Step 6: Write the Results to a JSON File
Finally, we save the scraped data to a JSON file by opening a file in write mode (using ‘w‘ as the second argument to open()) and using the json.dump() function to write the product data list to the file:
output_file = "Macy_product_results.json"
with open(output_file, "w", encoding="utf-8") as json_file:
json.dump(product_data_list, json_file, indent=2)
print(f"Scraped data has been saved to {output_file}")
As feedback, we’re printing a success statement to the console after creating the file.
Congratulations, you just scraped Macy’s product data!
Here’s a preview of the output from the scraper, as seen in the Macy_product_results.json file:
{
"Product Brand Name": "Karen Scott",
"Price": "$49.50",
"Description": "Women's Holiday Sweater, Created for Macy's",
"Rating": "4.4235 out of 5 rating with 1072 reviews",
"Image URL": "https://slimages.macysassets.com/is/image/MCY/products/1/optimized/26374821_fpx.tif?$browse$&wid=224&fmt=jpeg",
"Product URL": "/shop/product/karen-scott-womens-holiday-sweater-created-for-macys?ID=14175633&isDlp=true"
},
{
"Product Brand Name": "Style & Co",
"Price": "$59.50",
"Description": "Women's Holiday Themed Whimsy Sweaters, Regular & Petite, Created for Macy's",
"Rating": "4.2391 out of 5 rating with 46 reviews",
"Image URL": "https://slimages.macysassets.com/is/image/MCY/products/0/optimized/24729680_fpx.tif?$browse$&wid=224&fmt=jpeg",
"Product URL": "/shop/product/style-co-womens-holiday-themed-whimsy-sweaters-regular-petite-created-for-macys?ID=16001406&isDlp=true"
},
{
"Product Brand Name": "Charter Club",
"Price": "$59.50",
"Description": "Holiday Lane Women's Festive Fair Isle Snowflake Sweater, Created for Macy's",
"Rating": "4.8571 out of 5 rating with 7 reviews",
"Image URL": "https://slimages.macysassets.com/is/image/MCY/products/2/optimized/23995392_fpx.tif?$browse$&wid=224&fmt=jpeg",
"Product URL": "/shop/product/holiday-lane-womens-festive-fair-isle-snowflake-sweater-created-for-macys?ID=15889755&isDlp=true"
}, … More JSON Data,
Wrapping Up – How to Scrape Macy’s
In this tutorial, we’ve covered how to:
- Bypass Macy’s anti-scraping mechanisms using ScraperAPI
- Navigate Macy’s website structure using BeautifulSoup
- Extract product listings into a JSON file
Hope you enjoy this guide. Please feel free to use this script in your project. If you have any questions, please reach out to our support team</a >; we’ll be happy to help.
Need more than 3M API credits? Contact our sales team to build the best solution for your project.




