



What’s Unstructured Data?
Unstructured data, on the other hand, is like a jumble of information without any set order or organization. It can be messy, like text documents, social media posts, audio recordings, images, and other data that don’t follow a specific structure or pattern, making it tricky to classify or analyze using regular methods.
Here are a few examples of unstructured data:
- Text documents – such as emails, articles, reports, or free-form notes that lack a predefined structure or formatting.
- Social media data – content from social media platforms like Twitter, including user-generated posts, comments, and messages, don’t have a standardized structure.
- Video – analyzing video content often involves video processing techniques to extract relevant information.
Although converting unstructured data into structured data can be beneficial for analysis, it is not always necessary. Thanks to advancements in natural language processing and machine learning, we’re now able to analyze unstructured data directly.
That said, it does require higher data analysis knowledge and more sophisticated infrastructure to draw conclusions from unstructured data –like machine learning models–, which is not always available for small to medium size businesses.
So structuring unstructured data through techniques like text parsing or entity extraction can provide additional insights and improve the efficiency of analysis.
Benefits of Unstructured Data
Analyzing unstructured data is definitely harder, but it doesn’t mean it can’t provide valuable benefits. In fact, as we mentioned earlier, most alternative data is unstructured, and it’s our job to format or process this information to get what we need to move our projects forward.
Here are some of the benefits of unstructured data:
- It is easily available – the web is an ocean of unstructured data, so there’s no shortage of it.
- It provides rich insights – unstructured data provides a wealth of untapped information that can offer deeper insights into customer preferences, sentiment analysis, market trends, and emerging patterns.
- It helps you gain a competitive advantage – unlike structured data, unstructured data brings as much value as organizations are able to extract from it, enabling organizations to discover hidden patterns, market trends, or customer sentiments only available to them.
- It enhances decision-making – by considering a wider range of information, businesses can make more informed choices, mitigate risks, and identify new opportunities.
What is an Example of Unstructured Data in Web Scraping?
When we send a request to a server asking for a web page, the response is usually a long string of HTML that’s pretty incomprehensible and filled with irrelevant information.
<!DOCTYPE html>\n<html lang="en">\n<head>\n\t<meta charset="UTF-8">\n\t<title>Quotes to Scrape</title>\n <link rel="stylesheet" href="/static/bootstrap.min.css">\n <link rel="stylesheet" href="/static/main.css">\n</head>\n<body>\n <div class="container">\n <div class="row header-box">\n <div class="col-md-8">\n <h1>\n <a href="/" style="text-decoration: none">Quotes to Scrape</a>\n </h1>\n </div>\n <div class="col-md-4">\n <p>\n \n <a href="/login">Login</a>\n \n </p>\n </div>\n </div>\n \n\n<div class="row">\n <div class="col-md-8">\n\n <div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">\xe2\x80\x9cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\xe2\x80\x9d</span>\n <span>by …</body>\n</html>
Note: This is what we get by printing https://quotes.toscrape.com HTML response.
In order to work with this response and extract the information we want, we’ll have to parse the HTML string and turn it into a parse tree, allowing us to navigate through the nodes and pick specific elements.
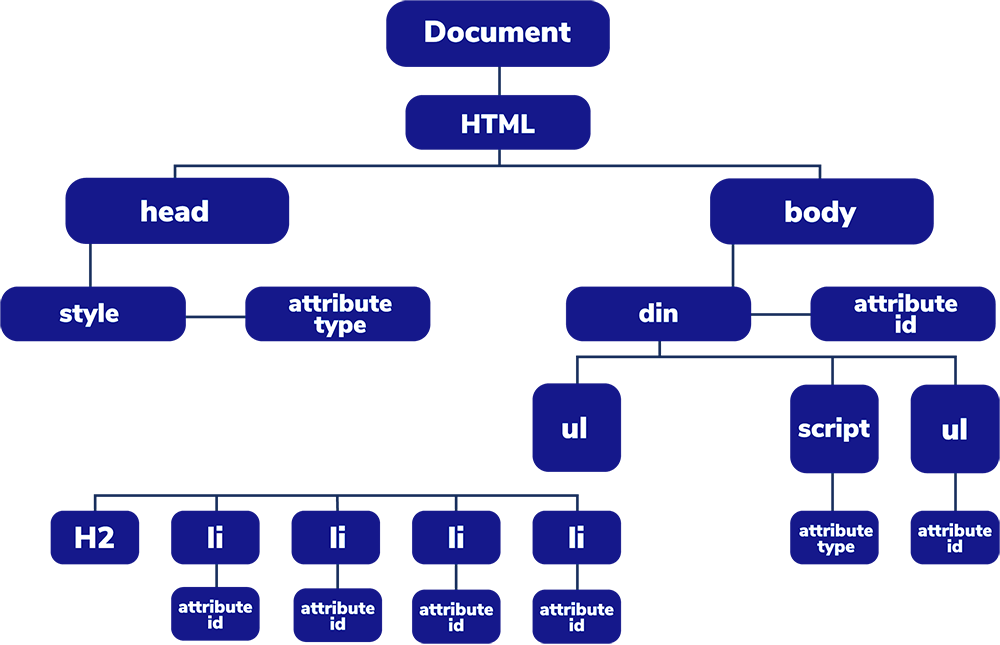
Of course, there are many forms of unstructured data, each representing a different challenge for both extracting the relevant data points and analyzing them efficiently and accurately.
That said, ScraperAPI makes the first task much easier!
How to Turn Unstructured Data Into Structured Data While Scraping in two steps
There are many reasons we scrape the web, so the format of the information should match the goal we’re trying to achieve.
However, in 95% of the cases, businesses and analysts collecting data from the web would prefer to work directly with a structured data set instead of having to do it manually, especially when handling complex sites like Amazon, Google, and Twitter at a large scale.
For this example, we’ll be using ScraperAPI’s Twitter Search Endpoint to extract Twitter data in a structured JSON format with a simple API call.
Note: We’ll be using Python and Requests, but ScraperAPI supports any programming language.
1. Set Up Your Project
First, create a new directory for your project and open it from your favorite code editor (we’ll be using VScode). Then, create a new twitter_scraper.py file and import Requests.
import requests
Note: If you don’t have Requests installed, open the terminal and enter pip install requests.
Now, to use ScraperAPI, you don’t need to install anything else. Instead, you’ll send your requests through our endpoints, and ScraperAPI will process your request.
response = requests.get('https://api.scraperapi.com/structured/twitter/search')
It will smartly choose and rotate your IP and headers – protecting your real IP address from getting banned from your target website – and handle CAPTCHAs and any other anti-scraping mechanism you might encounter – automating the whole “accessing of the data” process.
However, when using our Structured Data Endpoints, ScraperAPI will also turn the entire raw unstructured response into an easy-to-use JSON format, allowing you to extract all relevant information with ease, so you can focus on getting the insights you need to push your business forward.
We want to provide a few extra details for this particular endpoint (Twitter Search Endpoint):
-
- The query we want to extract data from (
query) – you can imagine this as using Twitter’s own search functionality. - Our unique API key (
api_key) – you can get this key by creating a free ScraperAPI account. You’ll find it on your dashboard.
- The query we want to extract data from (
- The max number of tweets we want to gather (
num) - The period of time we want the tweets from (
time_period)
We’ll pass this context as parameters within a payload and then add it as params=payload in our get() request. Here’s the final logic:
import requests
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'data science',
'num': '100',
'time_period': '1w'
}
response = requests.get(
'https://api.scraperapi.com/structured/twitter/search', params=payload)
print(response.content)
2. Send Your Request and Get the Data
Running this simple code will return Twitter search data in a JSON format you can easily export or manipulate to get only the data points you need. No parsing or extra processing required and your scrapers won’t get blocked at any point.
Here’s a quick look at one of the tweets returned:
"query":"data science",
"tweets":[
{
"tweet_id":"372350993255518208",
"user":"BigDataBorat",
"title":"Data Science is statistics on a Mac",
"text":"Data Science is statistics on a Mac. Javier Nogales \\xc2\\xb7 @fjnogales. \\xc2\\xb7. Aug 27, 2013. +100 \\xe2\\x80\\x9c. @BigDataBorat. : Data Science is statistics on a Mac.\\xe2\\x80\\x9d.",
"link":"https://twitter.com/BigDataBorat/status/372350993255518208",
"scraperapi_tweet_link":"http://api.scraperapi.com/structured/twitter/tweet?user=BigDataBorat&id=372350993255518208",
"scraperapi_user_tweets_link":"http://api.scraperapi.com/structured/twitter/tweets?user=BigDataBorat",
"scraperapi_user_replies_link":"http://api.scraperapi.com/structured/twitter/replies?user=BigDataBorat"
},
A couple of nuances to know about:
- The ScraperAPI’s Twitter Search Endpoint returns both tweets and profiles found on the search.
- The num parameter determines the maximum number of tweets and profiles combined that’ll be returned by the tool, so the exact number of tweets will be around 70 – 75 tweets per 100 items returned.
- You can use the
date_range_startanddate_range_endto be more specific in terms of time – format: YYYY-MM-DD. - You can get more granular data for each tweet by using our
https://api.scraperapi.com/structured/twitter/tweetendpoint – it’ll require your API key and the ID of the Tweet you want data from.
As you can see, using ScraperAPI is both easy and powerful, saving you hundreds of hours in data cleaning and lowering your data collection cost by automating the most technical part of the process.
If you are ready to start collecting data at scale and turn raw, messy HTML into well-structured data you can use right away, sign up for free to ScraperAPI and get 5,000 API credits to test everything we have to offer.
Need more than 10,000,000 API Credits with all premium features, premium support, and an account manager? Contact sales, and we’ll show you how ScraperAPI can help you push your business and applications forward!
Frequently Asked Questions
Is Twitter Data Structured or Unstructured Data?
Twitter data is mostly unstructured. It includes user-generated content like tweets, comments, and messages, which don’t follow any set format, making it hard to extract accurate, consistent data from the platform and requiring techniques like natural language processing to extract insights. However, you can turn unstructured Twitter data into ready-to-use structured JSON data with ScraperAPI.
Is CSV Structured or Unstructured Data?
CSV (Comma-Separated Values) data is considered structured data. It follows a specific format where each row represents a record, and commas separate the values within each row.
Is HTML Structured or Unstructured Data?
HTML (Hypertext Markup Language) data is considered semi-structured data as it uses predetermined tags to define elements (like <p> tags defining paragraphs). However, for web scraping, HTML is hardly usable in its raw form, requiring a parsing process and clear data extraction rules to make it easier to analyze.
Is Video Structured or Unstructured Data?
Video data is typically considered unstructured data. Videos consist of a sequence of frames that capture visual and auditory information, often without a predefined structure or format. To draw insights from video data, you need to use techniques such as video processing, optical character recognition, speech recognition, content-based indexing, etc.
Is PDF Structured or Unstructured Data?
PDFs are typically considered semi-structured data because they can contain structured elements such as headings, paragraphs, and tables. However, the overall structure is not as rigid as structured data formats like databases or spreadsheets. PDFs often require specific parsing and extraction techniques to retrieve information, making them closer to semi-structured or partially structured data.





