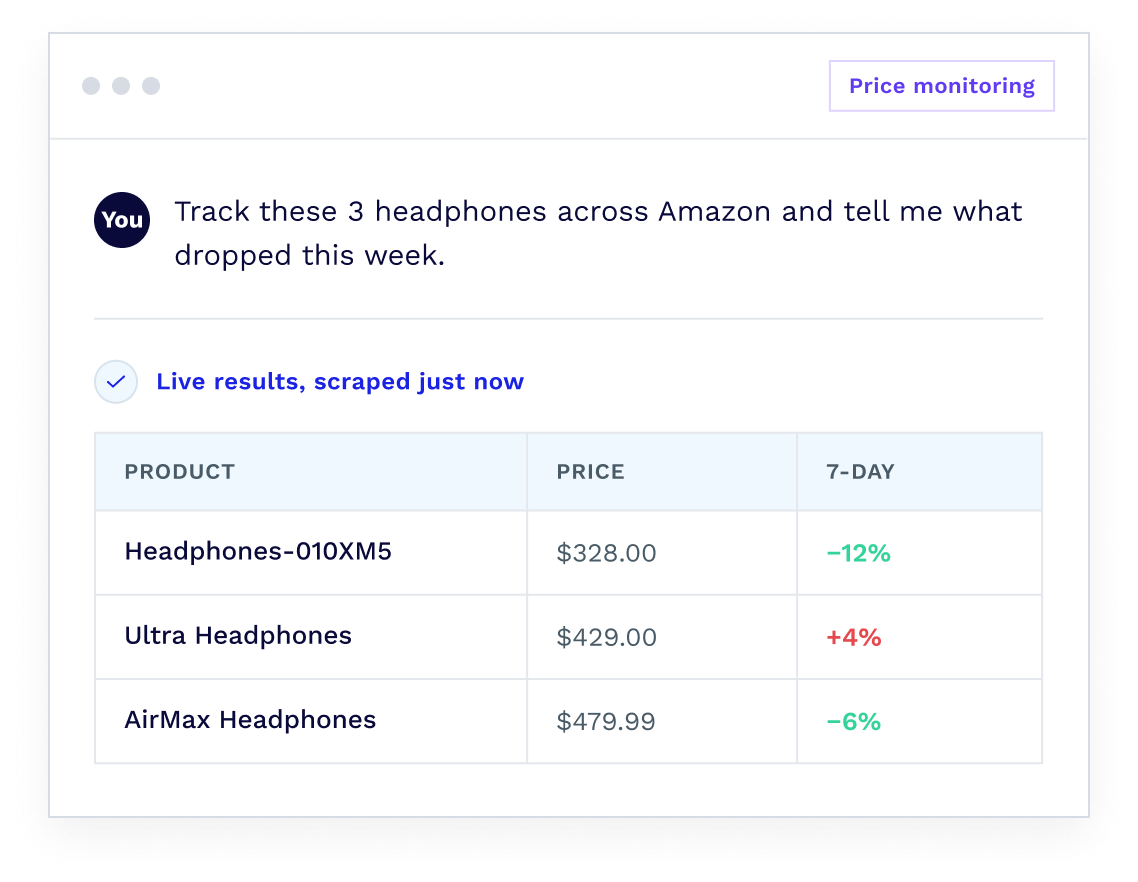
ScraperAPI handles the web scraping infrastructure behind automated workflows, including proxy rotation, JavaScript rendering, geotargeting, retries, and bot detection. This lets teams pull reliable web data on a schedule, through a trigger, or directly inside tools like Claude, n8n, MCP clients, CLI workflows, LangChain, and LlamaIndex.