



XML Path Language (XPath) is a query language and a major element of the XSLT standard. It uses a path-like syntax (called path expressions) to identify and navigate nodes in an XML and XML-like document.
In web scraping, we can take advantage of XPath to find and select elements from the DOM tree of virtually any HTML document, allowing us to create more powerful parsers in our scripts.
By the end of this guide, you’ll have a solid grasp of XPath expressions and how to use them in your scripts to scrape complex websites.
Understanding XPath Syntax
Writing XPath expressions is quite simple because it uses a structure we are all well versed in. You can imagine these path expressions like the ones we use in standard file systems.
There’s a root folder, and inside it has several directories, which could also contain more folders. XPath uses the relationship between these elements to traverse the tree and find the elements we’re targeting.
For example, we can use the expression //div to select all the div elements or write //div/p to target all paragraphs inside the divs. We can do this because of the nesting nature of HTML.
Using XPath to Find Elements With Chrome Dev Tools
Let’s use an example to paint a clearer picture. Navigate to https://quotes.toscrape.com/ and inspect the page.
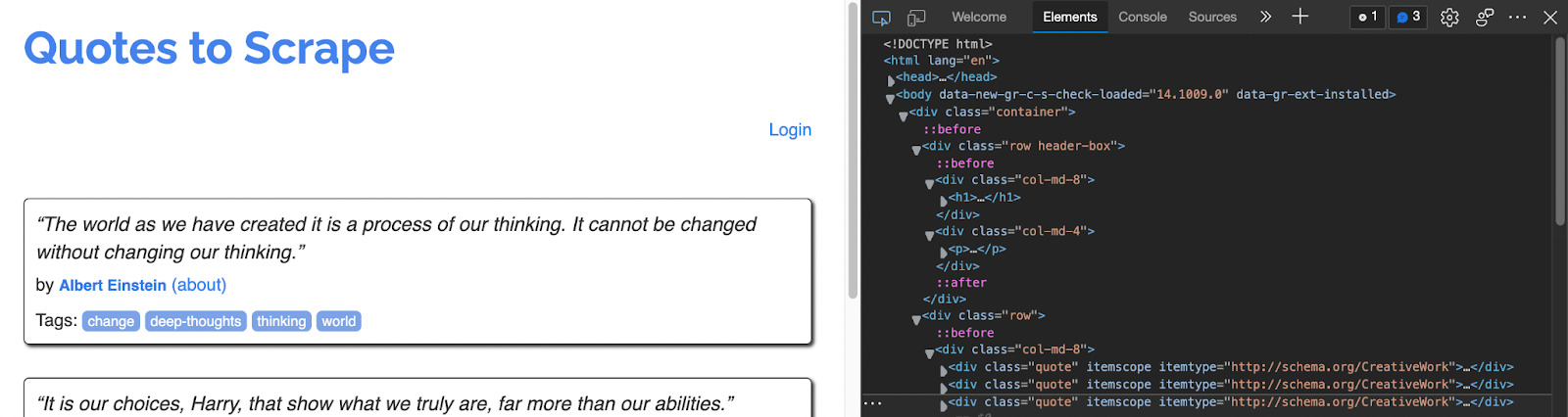
Now we’ll be able to see the HTML of the website and pick an element using our XPath expressions. If we want to scrape all the quotes displayed on the page, all we need to do is to press cmd + f to initiate a search and write our expression.
Note: This is a great exercise to test your expressions before spending time on your code editor and without putting any stress on the site’s server.

If we take a closer look, we can see that all quotes are wrapped inside a div with the class quote, with the text itself inside a span element with the class text, so let’s follow that structure to write our path:
 XPath:
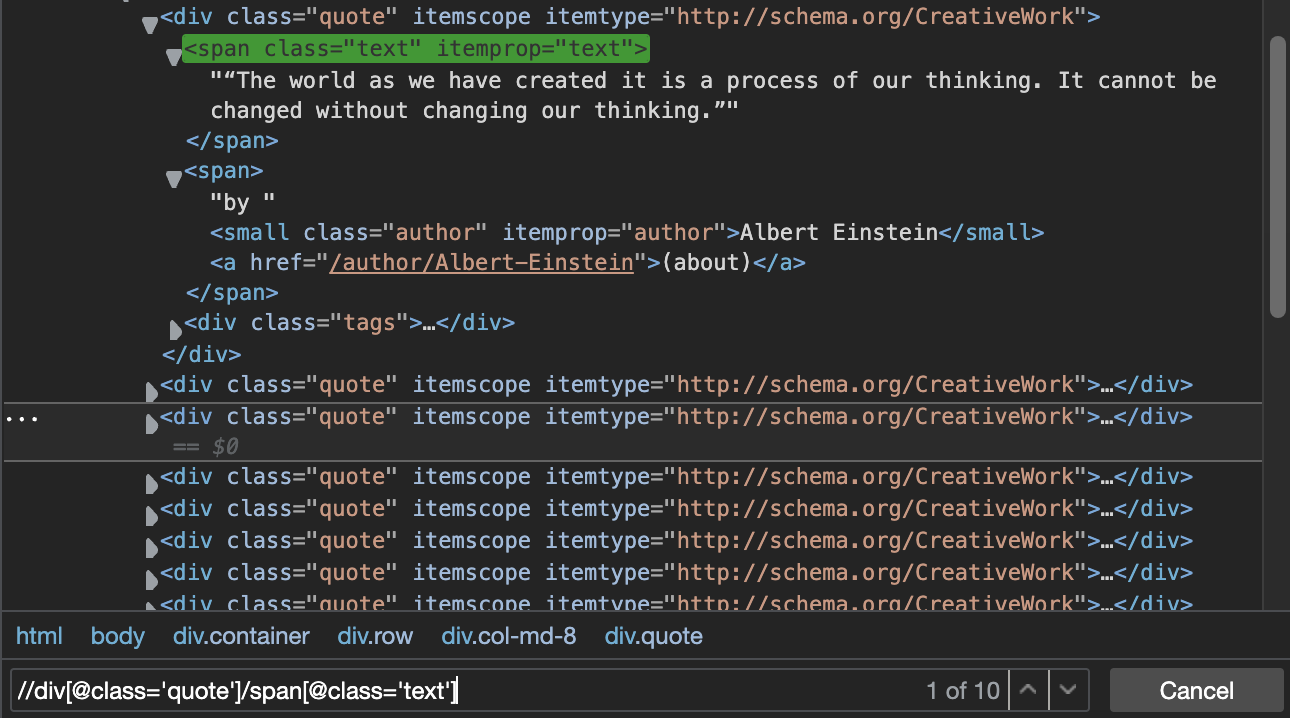
XPath: //div[@class=’quote’]/span[@class=’text’]
It highlighted the first element that matches our search, and also tell us that it’s the first of 10 elements, which perfectly matches the number of quotes on the page.
Note: It would also work fine with //span[@class='text'] because there’s only one span using that class. We want to be as descriptive as possible because, in most cases, we’ll be using XPath on websites with a messier structure.
Did you notice we’re using the elements’ attributes to locate them? XPath allows us to move in any direction and almost any way through the node tree. We can target classes, IDs, and the relationship between elements.
For the previous example, we can write our path like this: //div[@class='quote']/span[1]; and still, locate the element. This last expression would translate into finding all the divs with the class quote and picking the first span element.
Now, to summarize everything we’ve learned so far, here’s the structure of the XPath syntax:
- Tagname – which is the name of the HTML element itself. Think of divs, H1s, etc.
- Attribute – which can be IDs, classes, and any other property of the HTML element we’re trying to locate.
- Value – which is the value stored in the attribute of the HTML element.
If you’re still having a hard time with this syntax, a great place to start is understanding what data parsing is and how it works. In this article, we go deeper into the DOM and its structure, which in return will make everything about XPath click better.
When to Use XPath vs. CSS for Web Scraping
If you’ve readen any of our Beautiful Soup tutorials or Cheerio guides, you’ve noticed by now that we tend to use CSS in pretty much every project. However, it’s all due to practicality.
In real-life projects, things will be a little more complicated, and understanding both will provide you with more tools to face any challenge.
So let’s talk about the differences between XPath and CSS selectors to understand when you should use one over the other.
Advantages of CSS for Web Scraping
CSS selectors tend to be easier to write and read than XPath selectors, making them more beginner-friendly for both learning and implementation.
For comparison, here’s how we would select a paragraph with the class easy:
- XPAth:
//p[@class=”easy”] - CSS:
p.easy
Another thing to have in mind is that when working with a website that’s structured with unique IDs and very distinct classes, using CSS would be the best bet because picking elements based on CSS selectors is more reliable.
One change to the DOM and our XPath will break, making our script very susceptible. But classes and IDs very rarely change, so you’ll be able to pick up the element no matter if its position gets altered.
Although it might be very opinionated, we consider CSS as our first option for a project, and we only move to XPath if we can’t find an efficient way to use CSS.
Recommended: The Ultimate CSS Selectors Cheat Sheet for Web Scraping
Advantages of XPath for Web Scraping
Unlike CSS, XPath can traverse the DOM tree up and down, giving you more flexibility when working with less structured websites. This opens many opportunities to interact with the DOM that CSS doesn’t.
An easy example is imagining that you need to pick a specific parent div from a document with 15 different divs without any class, ID, or attribute. We won’t be able to use CSS effectively because there are no good targets to handle.
However, with XPath, we can target a child element of the div we need to select and go up from there.
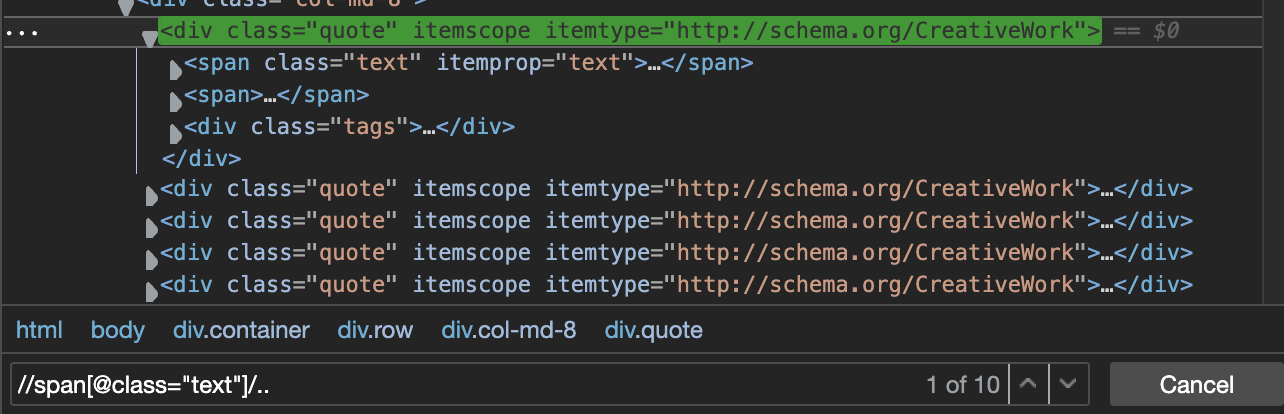
With //span[@class=”text”]/.. we’re making a path to find the span element with the class text and then move to the parent element of that specific span, effectively moving up the DOM.
Another great use of XPath selectors/expressions is when trying to find a by matching its text – something that can’t be done with CSS – using the contains function.
 XPath:
XPath: //*[contains(text(), ‘world’)]
In the example above, our XPath expression matches two elements because both the quote and the tag have the word “world” in them. Although we won’t probably use this function too often in web scraping, it’s a great tool in niche situations.
If you want to learn more about the differences between these two, we recommend Exadel’s guide on picking selectors for automation.
Although it’s not directly related to web scraping, there’s a lot of value in learning about automation concepts.
XPath is a powerful language needed in many cases so let’s check some common expressions you can use while web scraping.
XPath Cheat Sheet: Common Expressions for Web Scraping
So if you’re into web scraping, here’s a quick cheat sheet you can use in your daily work. Save it to your bookmarks, and enjoy!
Note: You can test every expression in the “example” column on Quotes to Scrape for extra clarity and see what you’re selecting. Except for the ID example because the website doesn’t use IDs, lol.
| You want to: | Syntax | Example |
| Pick elements from anywhere in the DOM with a specific HTML tag | //tagName | //span |
| Pick an element by ID | //tagName[@id=”idValue”] | //div[@id=”main-product”] |
| Pick an element by class | //tagName[@class=”classValue”] | //div[@class=”quote”] |
| Pick the child of an element | //parentName/childName | //div/span |
| Pick the first child of an element | //parentName/childName[1] | //div[@class=”quote”]/span[1] |
| Pick the parent of an element | //childName/.. | //span[@class=”text”]/.. |
| Get the anchor of an element | //tagName/@href | //a/@href |
| Pick an element by matching its text | //tagName | |
| Pick an element that partially matches some text | //tagName[contains(text(), “someText”) | //span[contains(text(), “by”)] |
| Picking the last child of an element or the last element in a list | //parentName/childName[last()] | //div[@class=”quote”]/span[last()] |
These are probably the most common XPath expressions you’ll be using to select elements from an HTML document. However, these are not the only ones, and we encourage you to keep learning.
For example, you can also select elements that doesn’t contain certain text by using the expression //tagName[not(contains(text(), "someText"))]. This could come in handy if the website adds some text to the elements depending on a variable like adding “out of stock” to product titles inside a category page.
We can also use the OR logic when working with a class that changes depending on a variable using //tagName[@class="class1" or @class="class2"]. Telling our scraper to select an element that has one or the other class.
In a previous entry, we were scraping some stock data, but the “price percentage change” class name changed depending on whether the price was increasing or decreasing. Because the change was consistent, we could easily implement the OR logic with XPath and make our scraper extract the value no matter which class the element was using.
 XPath:
XPath: //span[@class="instrument-price_change-percent__19cas ml-2.5 text-positive-main" or @class="instrument-price_change-percent__19cas ml-2.5 text-negative-main"]
XPath Web Scraper Example
Before you go, we want to share with you a script written in Puppeteer, so you can see these XPath selectors in action.
Note: Technologies like Cheerio or Beautiful Soup do not work well – and in some cases at all – with XPath, so we recommend you to use things like Scrapy for Python and Puppeteer for JavaScript whenever you need to use XPath. These are more complicated tools to begin with but you’ll be an expert in no time.
Create a new folder called “xpathproject”, open it in VScode (or your preferred editor), initiate a new Node.js project using npm init -y, and install puppeteer inside – npm install puppeteer.
Next, create a new file with whatever name you’d like (we named it index.js for simplicity) and paste the following code:
</p>
const puppeteer = require('puppeteer');
scrapedText = [];
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://quotes.toscrape.com/');
await page.waitForXPath('//div[@class="quote"]/span[1]');
let elements = await page.$x('//div[@class="quote"]/span[1]');
const elementText = await page.evaluate((...elements) => {
return elements.map(el => el.textContent);
}, ...elements)
scrapedText.push({
'Results': elementText
})
console.log(scrapedText);
await browser.close();
})();
<p>If you don’t have experience with Puppeteer, then check our guide on building web scrapers using Cheerio and Puppeteer. However, if you read this script carefully you’ll see how descriptive it is.
The best part is that you can use any XPath example on the XPath cheat sheet table and replace the expressions in the script and it’ll pull the text of the elements it finds.
It’s important to notice that this web scraper is made for pulling the text inside multiple elements so it might not work to just take the title of the page, for example.
Try different combinations and play a little bit with the script. You’ll soon get the hang of XPath. Until next time, happy scraping!





