



What You Need to Know Before Scraping in Node.js
Scraped data is not equal and you should draw a clear line between what you can and must not scrape. So what are the things you can’t do?
- Avoid reselling personal information for commercial purposes. It is against the ethics and standards set by the GDPR and California Consumer Privacy Act
- Do not scrape company’s data if there are provisions to APIs, as it is always advised to use them instead of scraping web data
- Ensure you are permitted to scrape only relevant endpoints from the user-agent page. To know the right endpoints allowed, check their website robots.txt file, like this: https://amazon.com/robots.txt
The Best Node.js Web Scraping Tools and Libraries
As already mentioned, whatever you want to scrape from the web, these libraries will do the job and meet your data collection needs.
Before writing a line of code, you need to consider the following prerequisites:
- Have Node.js installed on your local machine, which comes included with the package manager npm
- Have a basic, at minimum, understanding of JavaScript
- Knowledge of using the DevTools in the browser to inspect sites’ elements
Done? Now, let’s move to the overview of available tools and libraries you can use for web scraping.
1. Axios and Cheerio
Axios is a promise-based HTTP client developers utilize to send requests from client browsers and Node.js applications, with the page content received as the response.
Thanks to its simplicity, Axios is one of the easiest implementations to fetch HTML code from a web page in JavaScript projects.
On the other hand, Cheerio is a dependency package that parses markup into DOM-like objects, offering an API with methods for traversing and manipulating the code’s data structure. The implementation of Cheerio is reminiscent of jQuery.
To use it, install the package into an initialized project using the following command:
npm install cheerio axios
Copy-paste this code into the entry point file:
const express = require('express');
const axios = require('axios');
const cheerio = require('cheerio');
const app = express();
const PORT = process.env.PORT || 3000;
const website = 'https://news.sky.com';
try {
axios(website).then((res) => {
const data = res.data;
const $ = cheerio.load(data);
let content = [];
$('.sdc-site-tile__headline', data).each(function () {
const title = $(this).text();
const url = $(this).find('a').attr('href');
content.push({
title,
url,
});
app.get('/', (req, res) => {
res.json(content);
});
});
});
} catch (error) {
console.log(error, error.message)
}
app.listen(PORT, () => {
console.log(`server is running on PORT:${PORT}`);
});
In the provided example code:
- The Node.js framework Express is employed to exhibit the responses from Axios and Cheerio through the home route endpoint (“/”) using the GET method
- The response data from Axios is retrieved and loaded into Cheerio
- Cheerio then conducts a search on the website, selecting elements within the document
- It iterates through these elements, compiling the content into an array of objects that showcase the page’s title and URL
The anticipated outcome is as follows:
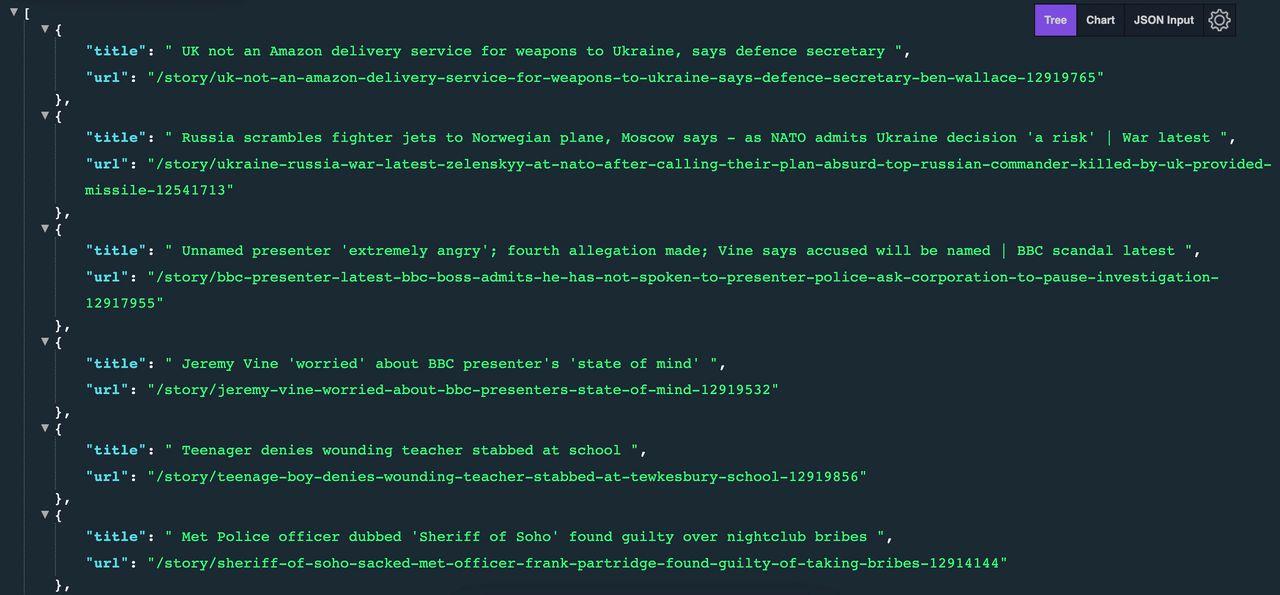
If you’d like to learn more about using Axios and Cheerio to collect web data, check our LinkedIn scraper tutorial with Node.js.
2. Puppeteer
Puppeteer, a headless version of Chrome or Chromium, represents a Node.js library employed programmatically through the CLI (command-line interface) or directly within a Node.js environment.
It emulates the actions of a real user, encompassing activities such as scrolling, clicking, generating screenshots, facilitating automated testing, and more.
To install Puppeteer within your project directory, use the following command:
npm install puppeteer
For the purpose of this tutorial, we will use the freeCodeCamp website to extract its blog title using Puppeteer.
Proceed by copying and pasting the provided code:
index.js
const puppeteer = require("puppeteer");
async function run() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://www.freecodecamp.org/news/tag/blog/");
// Get all blog title
const titles = await page.evaluate(() =>
Array.from(document.querySelectorAll(".post-feed .post-card"), (e) => ({
blog: e.querySelector(".post-card-content .post-card-title a").innerText,
}))
);
console.log(titles);
await browser.close();
}
run();
The rendered page queries all the H2 titles using the querySelectorAll method and displays the results as an object.
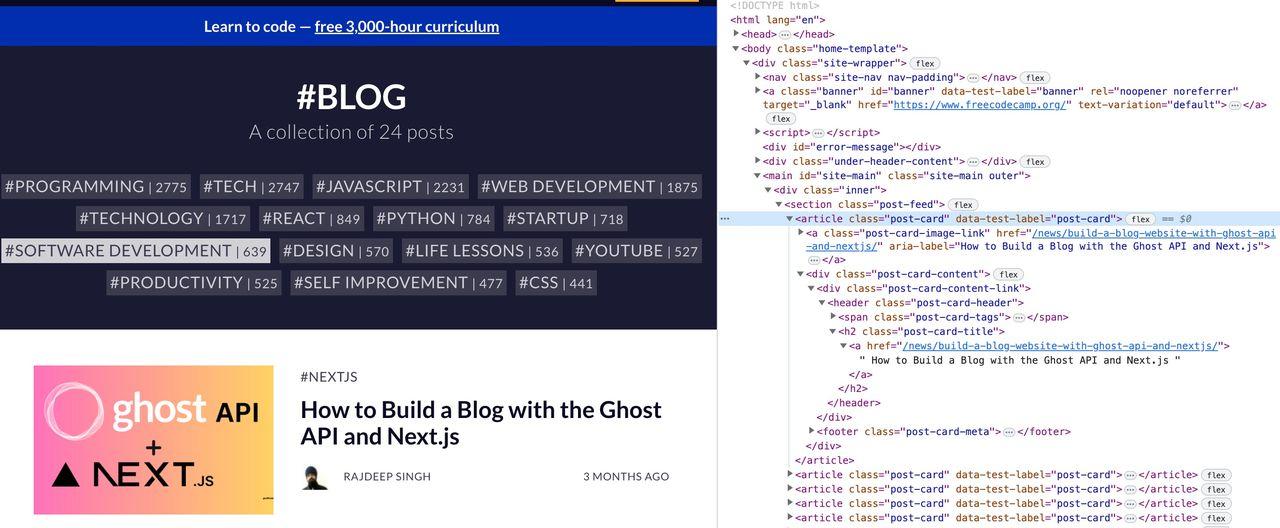
The result of running this script in the terminal looks like this:

The drawback of using Puppeteer is the slow performance and the time it takes on complex web pages.
As a rule of thumb, using a headless browser should be the last method when there’s no other way to access the data.
Want to learn more? In this tutorial we show you how to collect hundreds of hotel prices using Node.js and Puppeteer – with a simple trick to improve success rate to 99.99%.
3. ScraperAPI
ScraperAPI is a tool that deals with proxy rotation, handling CAPTCHAs, IP blocks, and JS rendering. As a result, you can scrape even the most difficult and unpredictable domains at high speed and scale, and by adding more concurrencies to your scrapers, you can scrape pages asynchronously, without getting blocked.
To access the tool, sign up for an account to access your dashboard, where you’ll find your API key and some sample code to test:
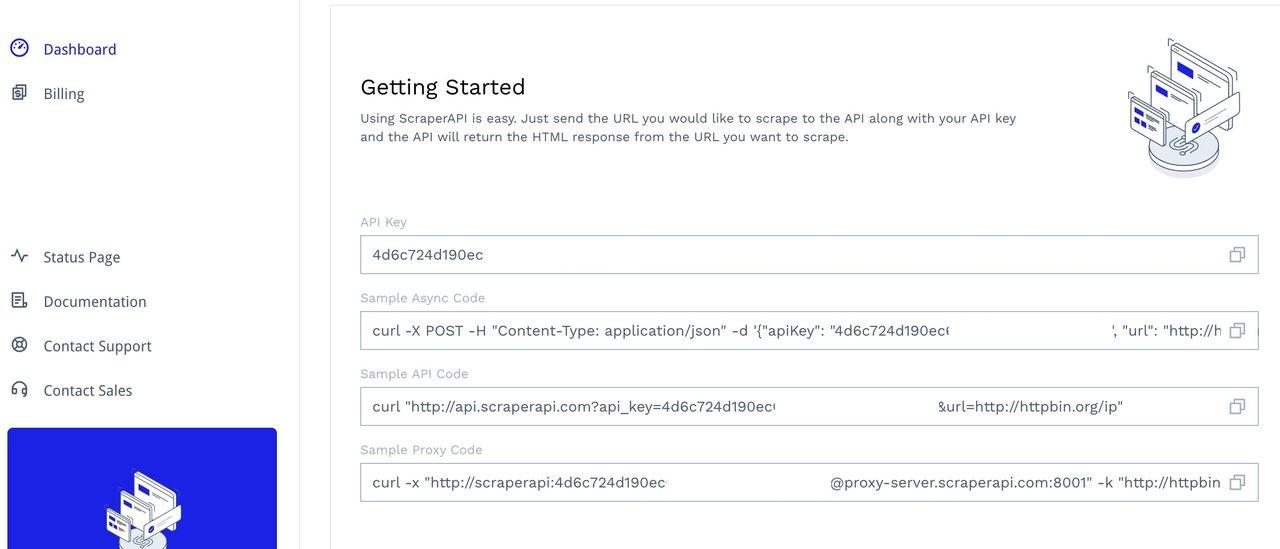
Discover how to integrate and implement ScraperAPI with Axios requests in this guide and the sample code using Puppeteer in Node.js.
Note: It is recommended to set a navigation timeout in your application when hitting endpoints or scraping the websites to get the best success rates and avoid getting blocked on hard-to-scrape domains.
What are the use cases of ScraperAPI and its benefits?
ScraperAPI can address the following challenges:
- Proxy management
- JavaScript rendering
- Browser and CAPTCHA handling
- Downloads in HTML or JSON
- Structured data endpoints (e.g., Amazon and Google scraping)
- Async scraper and concurrent requests
- Low-code scraper (DataPipeline)





