



It’s easy for enterprise businesses to dip into their pockets when it comes to data collection. They have budgets to employ various methods for analyzing data points, allowing them to make more accurate decisions. In turn, they create an unfair advantage for others.
However, data is not exclusive to big corporations; it’s a mindset that needs to change. Any small business can use web scraping to scale their data collection efforts and benefit from the same advantages. (In fact, web scraping can help you lower your costs by optimizing your decision-making and automating repetitive, time-consuming tasks.)
So, to help you get started, here are five use cases to help you grow your business (including code snippets!) without burning your budget:
1. Brand Monitoring and Online Reputation Management
It’s important to know how your audience feels about your brand, product and services. Understanding this can help you shift the conversation by addressing weak points or things that don’t work.
Monitoring online conversations happening around your brand can also help you inform what direction to take (like new products to launch or features to add) at any given time or even prevent possible PR disasters, allowing your team to be active instead of just reactive.
Doing this would require your team to constantly scroll through social media, websites, forums, and aggregators to gather the conversations happening, and as you can imagine, no matter the size of your team, this is an impossible task to do manually without allocating a big chunk of your marketing or PR budget into it. Instead, you can use a web scraper to crawl the platforms these conversations are taking place in, like forums and social media, and automate the process.
By scraping this data, you can analyze the conversations around your industry and brand, to understand whether the sentiment shared is positive or negative and find interesting insights from your customers.
Sample Script: Scrape Twitter Data with Python
Although there are many sources you can scrape, here’s a simple yet powerful Python script to retrieve Twitter data to a CSV file:
</p>
import snscrape.modules.twitter as sntwitter
import pandas as pd
hashtag = ‘scraperapi’
limit = 10
tweets = []
for tweet in sntwitter.TwitterHashtagScraper(hashtag).get_items():
if len(tweets) == limit:
break
else:
tweets.append([tweet.date, tweet.user.username, tweet.rawContentcontent])
df = pd.DataFrame(tweets, columns=[‘Date’, ‘User’, ‘Tweet’])
df.to_csv(‘scraped-tweets.csv’, index=False, encoding=‘utf-8’)
<p>Using this script, you’ll be able to collect data from any Twitter hashtag. More specifically, you can collect the date, user name, and content of every tweet within the hashtag results and get everything exported as a CSV file. For this example, we searched for #scraperapi and set the limit to 10. Here’s the resulting CSV file:
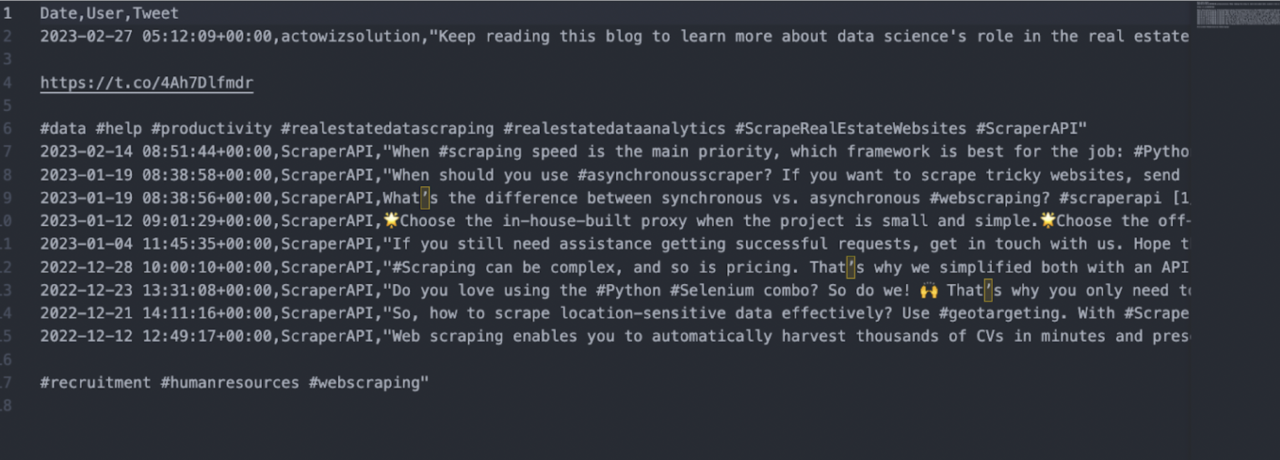
Some considerations when using the script:
- You can change the hashtag you want to scrape by changing the word within the >hashtag> variable
- Don’t add a pound symbol to the hashtag, or it won’t work
- You can change the number of returned tweets by changing the number in the limit variable
- You’ll need to have Python and the Requests library installed on your machine
If you’re not sure how to set it up or want to learn to scrape advanced queries and hashtags, view our tutorial on how to scrape Twitter data.
2. Price Intelligence
A crucial part of your business strategy is your products’ pricing.
A great pricing strategy ensures you’re optimizing your products’ value and bringing your profit margins up without hurting your sales or alienating your customers. To optimize your pricing, you need more than just the raw cost of your operations. You need to understand market shifts and your competitors’ pricing models, so you can create a strategy that guarantees competitiveness. However, collecting enough data (in terms of amount and variety) to draw any meaningful conclusions would be too intense for your team to handle.
Instead, you can use web scraping to automatically retrieve this information from, to name a couple, marketplaces and competitors’ pricing pages. To get started, and if you’re in the ecommerce niche, we recommend starting with two of the biggest sources of product data:
Amazon and Google Shopping.
By retrieving pricing data from these platforms, you can pull out insights on how much the average customer is paying for similar products, how much your competitors are charging, and even the common prices resellers set. Furthermore, collecting product data periodically will allow you to build a historical dataset you can then analyze to spot pricing trends and shifts before your competitors and even set automated systems to dynamically change your pricing.
Sample Script: Scrape Product Data from Google Shopping
Here’s a ready-to-use script you can use to gather pricing information from Google Shopping within a specific search query:
</p>
import requests
import json
products = []
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘query’: ‘gps+tracker’
}
response = requests.get(‘https://api.scraperapi.com/structured/google/shopping’, params=payload)
product_data = response.json()
for product in product_data[“shopping_results”]:
products.append({
‘Product Name’: product[“title”],
‘Price’: product[“price”],
‘URL’: product[“link”],
})
with open(‘prices.json’, ‘w’, encoding=‘utf-8’) as file:
json.dump(products, file, ensure_ascii=False, indent=4)
<p>In this example, we scraped the query “GPS tracker” and extracted the name, price, and URL of every product within the search results. After running the script, the end result will be a JSON file with 60 products:
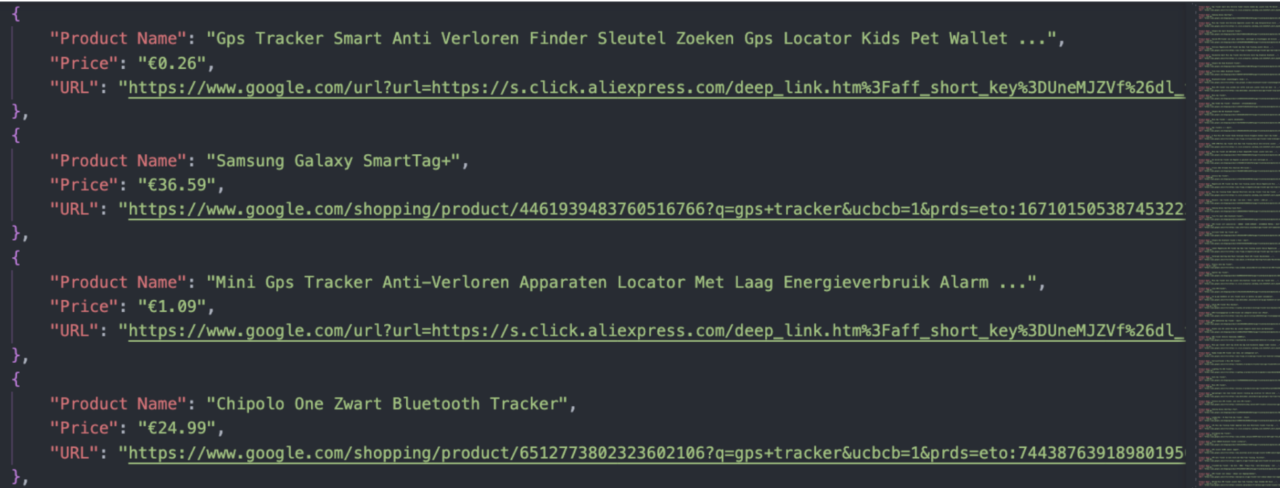
Some considerations when using the script:
- To simplify the code, we’re using ScraperAPI’s Goolge Shopping endpoint, which takes care of most technical complexities for us, so we can just focus on the queries we want to extract data from
- You need to create a free ScraperAPI account to have access to your API key – it’ll provide you with 5,000 free API credits so you don’t need to commit to a paid plan to use this script
- Add your API key in the api_key parameter
- Change the keyword you want to scrape within the query parameter, but notice you’ll need to change spaces for a plus symbol
- This script will always create a new file or overwrite any existing one with the same name, there are two quick solutions to change this behavior if you want to
- Change the name “with open(‘[file_name].json’, ‘w’, encoding=’utf-8′) as file:” to create a new file, or
- Change the “w” parameter to an “a” so the script knows to append the data to the file of the same name “with open(‘prices.json’, ‘a’, encoding=’utf-8′) as file:”
To further your knowledge, here’s a complete tutorial on scraping Amazon product data (including prices and images) you can follow.
To learn more about ecommerce scraping, check our guide on extracting product data from Etsy and eBay web scraping basics.
3. B2B Lead Generation
Leads are the heart of your operations, but creating a system to guarantee a constant isn’t as easy as others might think.
For B2B companies, generating a constant flow of new prospects to offer your services and products is as vital as air to a person.
Without proper planning and modern tooling, this process can become a high expenditure, easily breaking your business. After all, lead generation directly impacts your customer acquisition costs.
You probably already know where we’re going with it, right?
Web scraping can be used to collect B2B leads at a much lower cost and on a larger scale. Creating your own lead pipelines will ensure lower CACs and allow your sales team to do what they do best: sell! You can gather companies’ data from open directories and public platforms from all over the web, so it’s more about setting clear criteria for where and what kind of information you’re collecting. No more worrying about whether or not you’ll find good prospects.
Some platforms you can look into, to begin with, are:
- Clutch
- G2
- Google maps
- DnB
- Glassdoor
But you can also search niche-specific platforms for the kind of leads you’re looking for.
Sample Script: Scrape Glassdoor Company Data
As an example, here’s a script that retrieves the top-ranked companies within Glassdoor’s education category:
</p>
import requests
from bs4 import BeautifulSoup
import json
companies_data = []
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘render’: ‘true’,
‘url’: ‘https://www.glassdoor.com/Explore/browse-companies.htm?overall_rating_low=3.5&page=1§or=10009&filterType=RATING_OVERALL’
}
response = requests.get(‘https://api.scraperapi.com’, params=payload)
soup = BeautifulSoup(response.content, ‘html.parser’)
company_cards = soup.select(‘div[data-test=”employer-card-single”]’)
for company in company_cards:
company_name = company.find(‘h2’, attrs={‘data-test’: ’employer-short-name’}).text
company_size = company.find(‘span’, attrs={‘data-test’: ’employer-size’}).text
industry = company.find(‘span’, attrs={‘data-test’: ’employer-industry’}).text
description = company.find(‘p’, class_=‘css-1sj9xzx’).text
companies_data.append({
‘Company’: company_name,
‘Size’: company_size,
‘Industry’: industry,
‘Description’: description
})
with open(‘companies.json’, ‘w’, encoding=‘utf-8’) as file:
json.dump(companies_data, file, ensure_ascii=False, indent=4)
<p>Unlike our two previous examples, Glassdoor requires a more custom-made script. We wrote this one using Python’s Requests and BeautifulSoup libraries to extract the name, size, industry, and description of each company. (We’re also using ScraperAPI’s endpoint to bypass Glassdoor’s anti-scraping and avoid getting our IP blocked.)
Here’s the resulting JSON file:
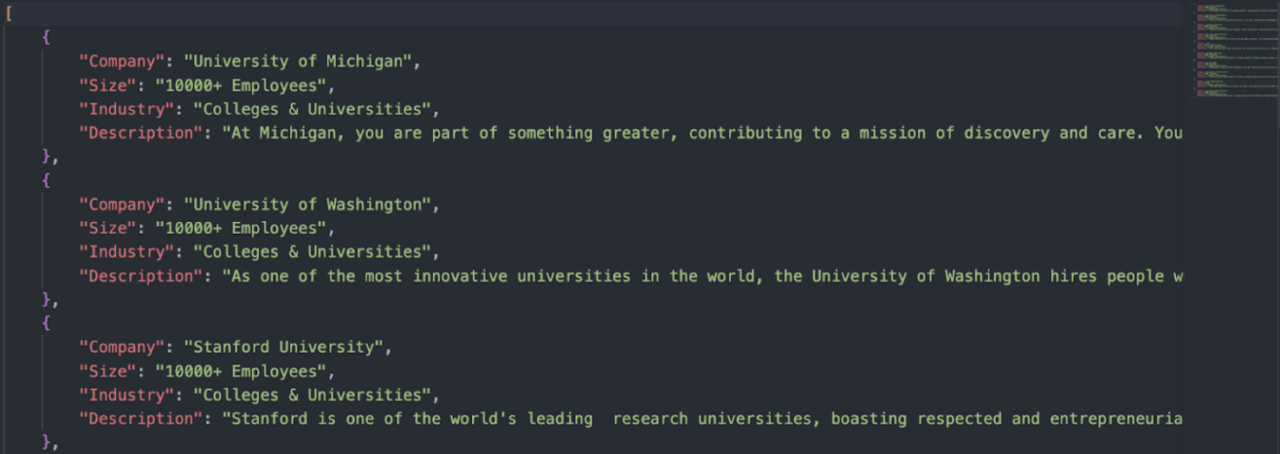
Of course, you can go further and scrape multiple categories and the entire paginated series of that category and build a list of hundreds of companies in just a couple of minutes. To learn the exact steps we followed when building this script and understand how to scale this project for your business, check out our Glassdoor scraping tutorial.
After reading the tutorial, you’ll be able to use this same script to extract data from other categories and set different filtering options to narrow your lead list to the companies you’re interested in.
4. Monitor Your Competitors’ Search Ads
Ads are one of the biggest expenses for marketing, so targeting the right keywords and optimizing the copy of your ads and landing pages is crucial to increase CTR and conversion rates. As with any other investment, collecting relevant data to build fact-based hypotheses can help you invest more securely and optimize the entire process.
In the case of ads, it’s important to understand your competitors’ positioning, where they’re investing, how often they appear on the search engine results pages (SERPs), and their top performing landing pages. This can provide a clear picture for your ads team, who can use this data to optimize your campaigns, reduce costs and improve ROI.
Sample Script: Extract Ad Data from Google Search Results
This time, we’re using ScraperAPI’s Google Search endpoint to extract the ads on the SERPs of our target keyword:
</p>
import requests
import json
all_ads = []
payload = {
‘api_key’: ‘YOUR_API_KEY’,
‘country’: “us”,
‘query’: ‘web+hosting’
}
response = requests.get(‘https://api.scraperapi.com/structured/google/search’, params=payload)
results = response.json()
for ad in results[“ads”]:
all_ads.append({
‘Title’: ad[“title”],
‘Description’: ad[“description”],
‘Landing’: ad[“link”]
})
with open(‘search_ads.json’, ‘w’, encoding=‘utf-8’) as file:
json.dump(all_ads, file, ensure_ascii=False, indent=4)
<p>When running the script, ScraperAPI will extract every ad’s title, description, and URL it finds on the search result page for the target keyword and send the data to a JSON file. Although you could scrape more pages, there are almost no clicks going to those ads, so it’s ok to stick to the ads on page one of every keyword you’re interested in.
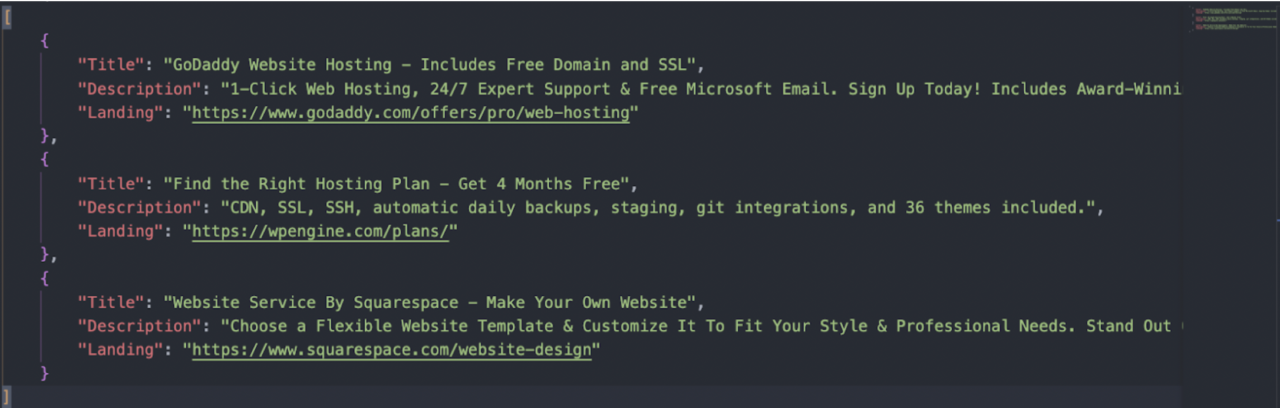
Some considerations when using this script:
- Just like before, you need a ScraperAPI free account and add the API in the api_key parameter within the payload
- Set the keyword you want to target inside the query parameter changing spaces for a plus symbol (+)
- Because ads are location sensitive, change the country value to your location of interest using any of these country codes
- Change the name of the file or set it to append (‘a’) to avoid losing previous data
To learn more, check our guide on scraping competitors’ data to improve your ad campaigns and how web scraping can improve marketing decision making.
5. Stock and Financial Monitoring
Small investment firms know how important data is to making high-performing, low-risk investments. Without accurate data, it’s hard to understand and predict market movements. This leads to the loss of big opportunities or, worse, failing to predict and prevent losses.
For SMBs in finance, every setback can potentially take them out of the race, making data collection more essential to your operation. Using web scraping, you can build alternative data pipelines to gather as much data as possible about the companies you’re looking to invest in.
Some of the key data points you can automatically collect consistently, include product data, stock prices, and real-time financial news.
Sample Script: Extract Stock Data from Investing.com
To help you start this journey, here’s an easy-to-use script to collect stock data from Investing.com:
</p>
import requests
from bs4 import BeautifulSoup
import csv
from urllib.parse import urlencode
urls = [
‘https://www.investing.com/equities/nike’,
‘https://www.investing.com/equities/coca-cola-co’,
‘https://www.investing.com/equities/microsoft-corp’,
]
file = open(‘stockprices.csv’, ‘w’)
writer = csv.writer(file)
writer.writerow([‘Company’, ‘Price’, ‘Change’])
for url in urls:
params = {‘api_key’: ‘YOUR_API_KEY’, ‘render’: ‘true’, ‘url’: url}
page = requests.get(‘http://api.scraperapi.com/’, params=urlencode(params))
soup = BeautifulSoup(page.text, ‘html.parser’)
company = soup.find(‘h1’, {‘class’:‘text-2xl font-semibold instrument-header_title__gCaMF mobile:mb-2’}).text
price = soup.find(‘div’, {‘class’: ‘instrument-price_instrument-price__xfgbB flex items-end flex-wrap font-bold’}).select(‘span’)[0].text
change = soup.find(‘div’, {‘class’: ‘instrument-price_instrument-price__xfgbB flex items-end flex-wrap font-bold’}).select(‘span’)[2].text
print(‘Loading :’, url)
print(company, price, change)
writer.writerow([company.encode(‘utf-8’), price.encode(‘utf-8’), change.encode(‘utf-8’)])
file.close()
<p>When running the script, it’ll create a new CSV file with the name, price, and percentage change of every stock you added to the >list. In this example, we collected data for Nike, Coca-Cola, and Microsoft:

A few considerations when using this script:
- Before running it, create a free ScraperAPI account and add your API key in the corresponding parameter
- Navigating to a stock page in Investing.com will generate an URL like https://www.investing.com/equities/amazon-com-inc. Add all URLs you want to monitor to the urls list – there’s no extra configuration needed
- As it is, the script will create a new file every time, but you can modify this behavior, so it creates a new column in an existing file, that way you can start building a historical data set and not just one-time data points
If you’re interested in learning how we built this script, view our stock price scraping guide. You can follow our thought process step-by-step.
Wrapping Up
Instead of having entire teams collecting, cleaning, and analyzing data, web scraping allows you to automate all these time-consuming tasks.
In this article, we just scratched the surface of the sea of opportunities web scraping can open for your business. If you keep your mind open, a scraper can be a powerful tool to empower your decision-making, automate entire processes like data migration and data entry, integrate data sources into a single database or dashboard, and much more.
We hope any of these five scripts can help you get started with web scraping. If you’re completely new, take a look at our blog, it is filled with projects you can learn and draw inspiration from.
Until next time, happy scraping!





