


Want to learn how to scrape Google search results without getting blocked? You’re in the right place. Google’s search engine results pages (SERPs) are packed with valuable data for SEO tracking, market research, and competitive analysis. Whether you’re monitoring keyword rankings, analyzing search trends, or gathering insights for content optimization, scraping Google search data will help you get ahead.
However, scraping Google isn’t as simple as extracting data from a typical website. Google has strict anti-scraping measures in place, including CAPTCHAs, IP rate limits, and bot-detection systems designed to block automated requests. Traditional web scrapers often struggle to overcome these obstacles, resulting in incomplete data or outright bans.
In this article, you will learn how to scrape Google search results using Python, covering:
- The key challenges of Google search scraping and how to bypass them
- A step-by-step guide to using ScraperAPI for fast, scalable, and reliable scraping
- Alternative methods, including Selenium for browser-based scraping
- Practical ways to use Google SERP data for SEO, market research, and analytics
Ready? Let’s get started!
What Is a Google SERP and How Does It Work?
Whenever you search for something on Google, the results appear on a Search Engine Results Page (SERP). Google SERPs aren’t just a list of blue links; they contain a mix of organic results, paid ads, featured snippets, and other search elements that Google dynamically adjusts based on relevance, location, and user intent.
Key Elements of a Google SERP
Google SERPs include multiple sections, each designed to provide different types of information:
- Organic search results: The organic results are the traditional blue-link listings ranked by Google’s search ranking algorithms, which search engine optimization (SEO) practices aim to influence. These rankings depend on factors such as page content relevance (including keywords), backlinks, and page authority. If you’re scraping Google results, extracting title tags, meta descriptions, and URLs from organic results can help track keyword rankings and optimize your SEO strategy.
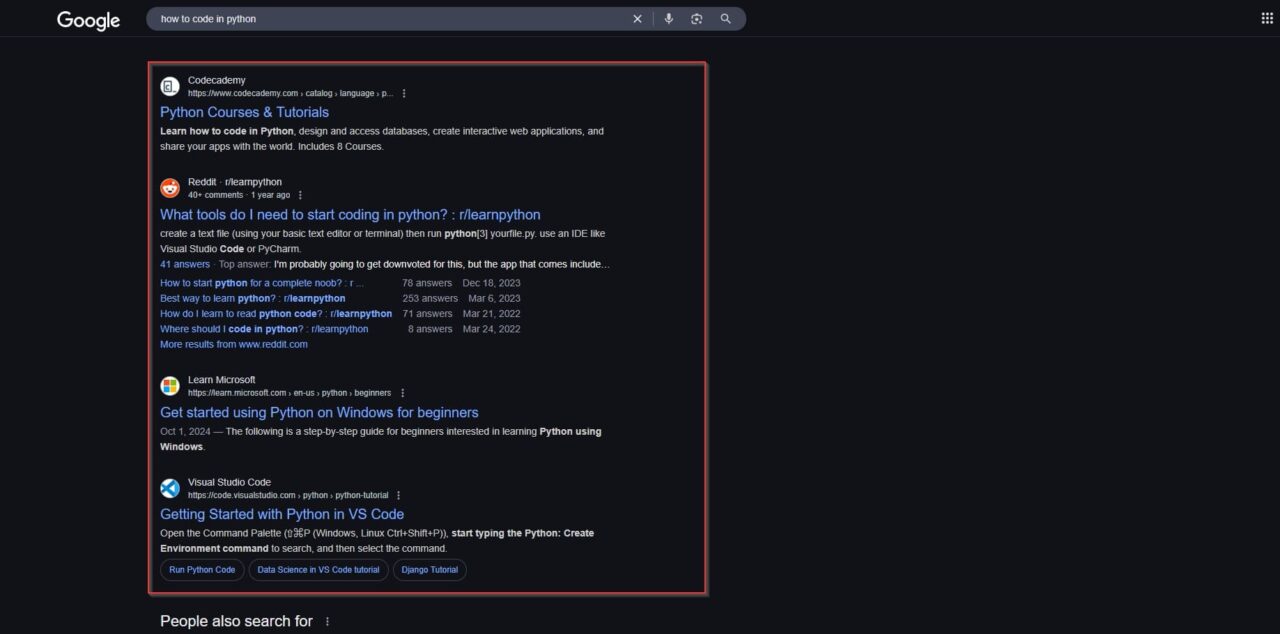
- Featured snippets: Featured snippets appear above organic results and provide a direct answer to a search query. They often include text, lists, or tables extracted from high-ranking web pages. Extracting these snippets from Google search results allows you to parse direct answers for a given search query.
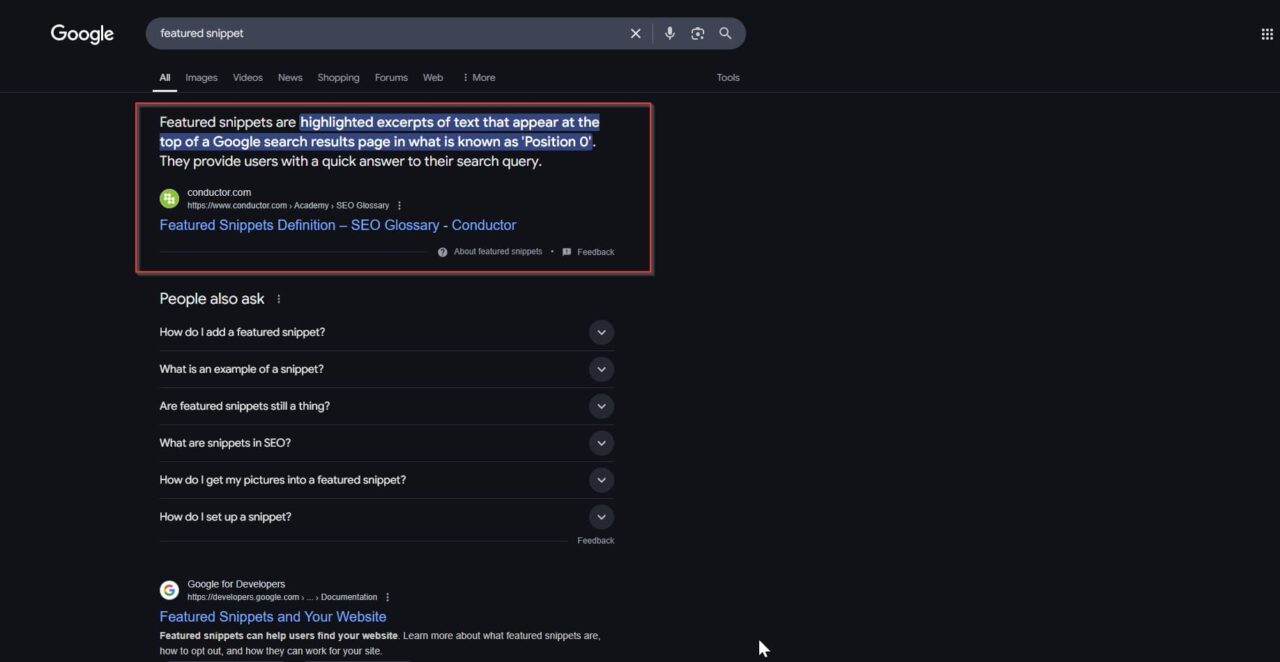
- People Also Ask (PAA) boxes: The People Also Ask (PAA) section contains expandable questions related to the topic. Clicking on one reveals an answer along with additional related queries. Extracting PAA data can help identify common search queries, optimize content strategy, and discover new SEO opportunities. It’s important to note that PAA boxes are dynamic, meaning they can change depending on the specific user’s intent or query.
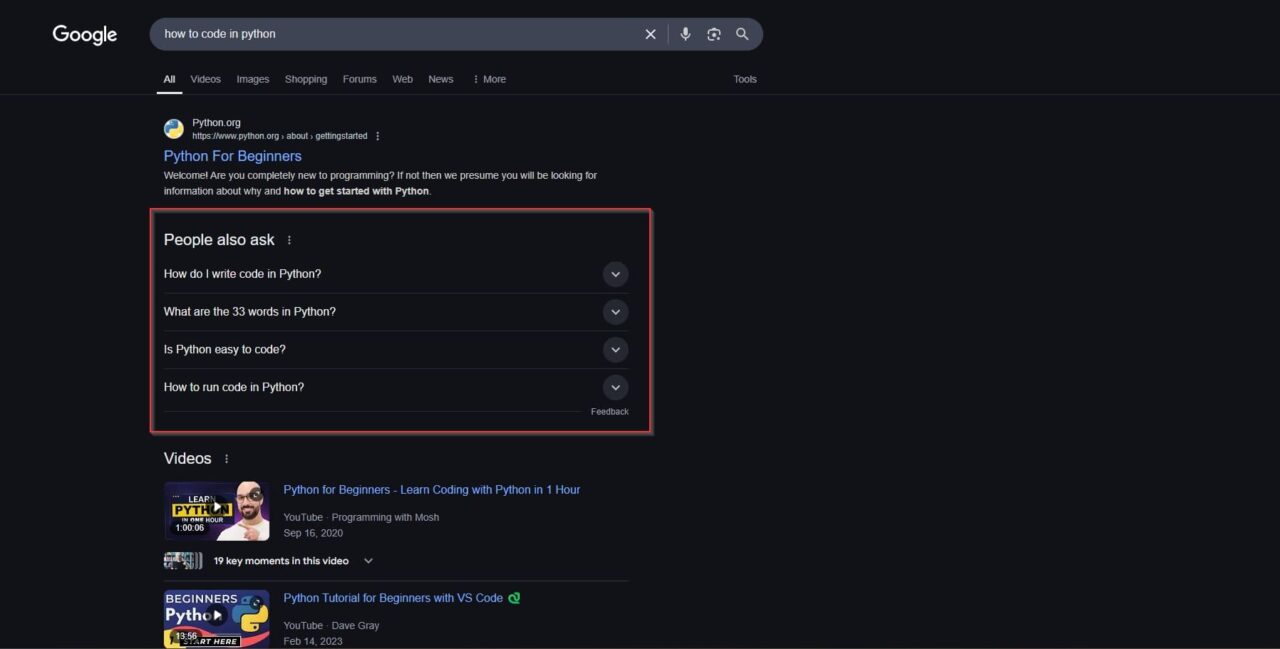
- Image and Video Results: Google SERPs often include image and video carousels, particularly for visual queries. Extracting these results can help analyze which media content ranks for a particular keyword. This is useful for optimizing YouTube SEO and image-based content.

How to Scrape Google Search Results Using Python
Scraping Google search results has always been challenging due to Google’s strict anti-bot measures. Traditional web scraping tools struggle to maintain stable access without frequent interruptions. This is where ScraperAPI provides a seamless solution. Instead of dealing with user agents and proxies and handling Google’s evolving structure, ScraperAPI’s Google Search endpoint delivers structured JSON data with minimal effort.In this tutorial, we’ll scrape data from Google search results for the query “how to code in python 2025” using ScraperAPI’s structured search endpoint. We’ll retrieve organic search results, related questions from Google’s “People Also Ask” section, and YouTube video results, then save the extracted data into CSV files for further analysis.
Step 1: Install Required Packages
For this tutorial, you will need:
Python- Your integrated development environment (IDE) of choice to run your scripts
Before running the script, ensure you have installed the necessary dependencies. These include:
requests: To send HTTP requests to ScraperAPIpandas: To store and manipulate the extracted datapython-dotenv: For safely handling credentials
Run the following command in your terminal or command prompt:
pip install requests pandas python-dotenv
Step 2: Set Up the ScraperAPI Request
First and foremost, we need to define your ScraperAPI key and other search parameters. If you don’t have a ScraperAPI key yet, sign up here and get one for free. After you have created your account, you can find your personal API key on your dashboard
Since we will be using this key in two files and it contains sensitive information, we need to create a file specific to our credentials and then set it safely as an environment variable. This passage is important, so don’t skip it! You don’t want your personal API key to be mistakenly made public.
Since we will be using this key in two files and it contains sensitive information, we need to create a file specific to our credentials and then set it safely as an environment variable. This passage is important, so don’t skip it! You don’t want your personal API key to be mistakenly made public.In the root directory of your project, create a .env file to store your environment variables. You should also add this file to your .gitignore file to prevent sensitive data from being pushed to version control. Create it by running:
touch .env
In it, define your API key:
SCRAPERAPI_KEY= "YOUR_API_KEY" # Replace with your actual ScraperAPI key
Create a file in your project folder and call it config.py. In this file, load the environment variable. You can also set your parameters in your actual scraper, but having them in your configuration will make it easier to use them across files.
import os
from dotenv import load_dotenv
# Load environment variables from the .env file
load_dotenv()
# Access the API key from the environment variable
API_KEY = os.getenv("SCRAPERAPI_KEY")
# Search parameters
search_query = "how to code in python 2025"
search_country = "us"
pages_to_scrape = 5 # Number of pages to scrape
API_KEY:Your unique ScraperAPI key, loaded from your environmentsearch_query: The Google search term (e.g., “how to code in python 2025”)search_country: The country for localized search results (e.g., “us” for the United States)pages_to_scrape: Number of pages to scrape (each page contains multiple results)
After doing that, in a new Python file (let’s call it scraper.py), import the necessary Python libraries and your configurations:
import requests
import json
import pandas as pd
import time
from config import API_KEY, search_query, search_country, pages_to_scrape
Step 3: Define the Scraping Function
Now, let’s create a function to scrape Google search results using ScraperAPI.
Below you can see it in its entirety, but we will break it down in later sections for better handling and understanding:
def scrape_google_search(query, country="us", num_pages=3):
"""Scrapes Google search results using ScraperAPI's structured data endpoint."""
search_results = []
related_questions = []
video_results = []
for page in range(num_pages):
payload = {
"api_key": API_KEY,
"country": country,
"query": query,
"page": page + 1
}
try:
response = requests.get("https://api.scraperapi.com/structured/google/search", params=payload)
if response.status_code == 200:
serp = response.json()
for result in serp.get("organic_results", []):
search_results.append({
"Title": result.get("title", "N/A"),
"URL": result.get("link", "N/A"),
"Snippet": result.get("snippet", "N/A"),
"Rank": result.get("position", "N/A"),
"Domain": result.get("displayed_link", "N/A"),
})
for question in serp.get("related_questions", []):
related_questions.append({
"Question": question.get("question", "N/A"),
"Position": question.get("position", "N/A"),
})
for video in serp.get("videos", []):
video_results.append({
"Video Title": video.get("title", "N/A"),
"Video URL": video.get("link", "N/A"),
"Channel": video.get("channel", "N/A"),
"Duration": video.get("duration", "N/A"),
})
print(f"Scraped page {page + 1} successfully.")
else:
print(f"Error {response.status_code}: {response.text}")
break
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
break
time.sleep(2) # Pause to prevent rate limiting
# Save organic search results
if search_results:
df = pd.DataFrame(search_results)
df.to_csv("google_search_results.csv", index=False)
print("Data saved to google_search_results.csv")
# Save related questions
if related_questions:
df_questions = pd.DataFrame(related_questions)
df_questions.to_csv("google_related_questions.csv", index=False)
print("Related questions saved to google_related_questions.csv")
# Save YouTube video results
if video_results:
df_videos = pd.DataFrame(video_results)
df_videos.to_csv("google_videos.csv", index=False)
print("Video results saved to google_videos.csv")
print("Scraping complete.")
# Call your function so that the scraping is triggered. We will pass it the variables that we have imported from our config file
scrape_google_search(search_query, country=search_country, num_pages=pages_to_scrape)
Let’s now break down each part of our function to highlight each step of the process. First off, let’s create the core of the function, which defines variables to store results and launches the request:
def scrape_google_search(query, country="us", num_pages=3):
"""Scrapes Google search results using ScraperAPI's structured data endpoint."""
search_results = []
related_questions = []
video_results = []
for page in range(num_pages):
payload = {
"api_key": API_KEY,
"country": country,
"query": query,
"page": page + 1
}
try:
response = requests.get("https://api.scraperapi.com/structured/google/search", params=payload)
if response.status_code == 200:
serp = response.json()
How This Function Works:
- Creates empty lists (
search_results, related_questions, andvideo_results) to store extracted data. - Loops through
num_pages, making an API request for each page of search results. - Sends a request to ScraperAPI with:
api_key→ Your API key for authenticationcountry→ The targeted countryquery→ The search termpage→ The current page number
- Checks if the response status is 200 (OK) before processing the data.
Step 4: Extract Search Results
If the API request is successful, we extract three types of data:
- Organic Search Results:
for result in serp.get("organic_results", []):
search_results.append({
"Title": result.get("title", "N/A"),
"URL": result.get("link", "N/A"),
"Snippet": result.get("snippet", "N/A"),
"Rank": result.get("position", "N/A"),
"Domain": result.get("displayed_link", "N/A"),
})
Code Breakdown:
- Extracts the top organic search results from
serp.get("organic_results", []). - For each result, it retrieves:
title: The headline of the search resultlink: The URL of the webpagesnippet: A short description from Google’s result pageposition: The ranking position of the resultdisplayed_link: The domain of the website
- Related Questions (“People Also Ask”):
for question in serp.get("related_questions", []):
related_questions.append({
"Question": question.get("question", "N/A"),
"Position": question.get("position", "N/A"),
})
Code Breakdown:
- Extracts questions from the “People Also Ask” section of Google search results.
- Retrieves:
question: The related question textposition: The question’s ranking position on the page
- YouTube Video Results:
for video in serp.get("videos", []):
video_results.append({
"Video Title": video.get("title", "N/A"),
"Video URL": video.get("link", "N/A"),
"Channel": video.get("channel", "N/A"),
"Duration": video.get("duration", "N/A"),
})
Code Breakdown:
- Extracts YouTube video results appearing in Google search.
- Retrieves:
title: The video’s titlelink: The direct URL to the videochannel: The YouTube channel nameduration: The length of the video
Step 5: Handle Errors and API Rate Limiting
To ensure our script runs smoothly without unexpected failures, we need to handle common errors and manage our request rates effectively:
print(f"Scraped page {page + 1} successfully.")
else:
print(f"Error {response.status_code}: {response.text}")
break
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
break
time.sleep(2) # Pause to prevent rate limiting
Code Breakdown:
- Handles errors by checking
response.status_code.If there’s an error, it prints the message and stops execution.
Introduces a time.sleep(2) delay between requests to avoid triggering ScraperAPI’s rate limits.
Step 6: Save Data to CSV Files
Once the data is collected, we save it as CSV files for analysis:
# Save organic search results
if search_results:
df = pd.DataFrame(search_results)
df.to_csv("google_search_results.csv", index=False)
print("Data saved to google_search_results.csv")
# Save related questions
if related_questions:
df_questions = pd.DataFrame(related_questions)
df_questions.to_csv("google_related_questions.csv", index=False)
print("Related questions saved to google_related_questions.csv")
# Save YouTube video results
if video_results:
df_videos = pd.DataFrame(video_results)
df_videos.to_csv("google_videos.csv", index=False)
print("Video results saved to google_videos.csv")
print("Scraping complete.")
Code Breakdown:
- Checks if data exists before saving to prevent empty files.
- Uses
pandas.DataFrame()to store extracted data. - Exports results to CSV files for further analysis.
Call the function you have just created at the end of your file, and outside of the function (mind indentation!):
# Call your function within your file so that it runs
scrape_google_search(search_query, country=search_country, num_pages=pages_to_scrape)
You can run the script by going to your root folder in your terminal and doing:
python scraper.py
Now you have a functioning Google search scraper, and your data is saved in CSV files and ready for analysis in Google Sheets or Excel. Feel free to explore and refine your search parameters for even better results; you can modify the query, country, or number of pages to tailor the data to your needs!
Automating Google Search Scraping
Now that you’ve successfully scraped Google search results manually let’s take it a step further by automating the process. With ScraperAPI’s Datapipeline, you can schedule your scraping tasks to run at regular intervals, whether daily, hourly, or weekly. This allows you to collect data continuously without needing to run the script manually.To automate Google search scraping, create a new file (we’ll call it automatic_scraper.py). Here is the code in its entirety:
import requests
import json
from config import API_KEY, DATAPIPELINE_URL
data = {
"name": "Automated Google Search Scraping",
"projectInput": {
"type": "list",
"list": ["how to code in python 2025"]
},
"projectType": "google_search",
"schedulingEnabled": True,
"scheduledAt": "now",
"scrapingInterval": "daily",
"notificationConfig": {
"notifyOnSuccess": "with_every_run",
"notifyOnFailure": "with_every_run"
},
"webhookOutput": {
"url": "http://127.0.0.1:5000/webhook", # Replace if using a webhook
"webhookEncoding": "application/json"
}
}
headers = {'content-type': 'application/json'}
response = requests.post(DATAPIPELINE_URL, headers=headers, data=json.dumps(data)) # Print response
print(response.json())
Let’s break it down. Start by importing the necessary libraries:
import requests
import json
Next, set up authentication by adding yourDatapipeline API URL to your config file, then import it into your automatic_scraper.py file together with your API key. In config, below your API key, add:
DATAPIPELINE_URL = f"https://datapipeline.scraperapi.com/api/projects?api_key={API_KEY}"
And add it to your imports in your automatic_scraper.py file:
from config import API_KEY, DATAPIPELINE_URL
Now, configure the scraping job by specifying:
- The search queries to track
- How often the scraping should run
- Where the results should be stored
Instead of assigning these to variables like we did in our first script, we’ll define them using an in-file JSON object. By default, results are stored in the ScraperAPI dashboard, but they can also be sent to a webhook if specified.
data = {
"name": "Automated Google Search Scraping",
"projectInput": {
"type": "list",
"list": ["how to code in python 2025"]
},
"projectType": "google_search",
"schedulingEnabled": True,
"scheduledAt": "now",
"scrapingInterval": "daily",
"notificationConfig": {
"notifyOnSuccess": "with_every_run",
"notifyOnFailure": "with_every_run"
},
"webhookOutput": {
"url": "http://127.0.0.1:5000/webhook", # Replace if using a webhook
"webhookEncoding": "application/json"
}
}
Breaking Down the JSON Configuration
Each key in this JSON object defines an important part of the automated scraping job:
"name": The name of the scraping project (for organization)."projectInput": The search queries to scrape:"type":"list"indicates that multiple queries can be provided."list": A list of search terms (e.g.,"how to code in python 2025").
"projectType": Defines the structured data endpoint we are using. Since we are using the Google search endpoint, the value is"google_search"."schedulingEnabled":Trueenables automatic scheduling."scheduledAt":"now"starts the scraping immediately (can be set to a specific time)."scrapingInterval": Controls how often the scraping runs:"hourly","daily", or"weekly"are valid options.
"notificationConfig": Defines when notifications are sent:"notifyOnSuccess":"with_every_run"means a notification is sent every time the scraping succeeds."notifyOnFailure":"with_every_run"means an alert is sent every time the scraping fails.
"webhookOutput": (Optional) Sends the results to a webhook instead of just storing them in ScraperAPI’s dashboard:"url"→ The webhook URL where results will be sent."webhookEncoding"→ Defines the format of the data, which is"application/json"in this case.
For more details on how to automate web scraping efficiently, check out this guide: Automated Web Scraping with ScraperAPI.Now that everything is set up, we can build or request at the bottom of the file. This can be sent to ScraperAPI to schedule the scraping job:
headers = {'content-type': 'application/json'}
response = requests.post(DATAPIPELINE_URL, headers=headers, data=json.dumps(data)) # Print response
print(response.json())
Run your script by doing:
python automatic_scraper.py
By automating Google search scraping with ScraperAPI’s Datapipeline, you can collect search data continuously without manually running scripts. Whether you need fresh results daily, hourly, or weekly, this solution saves time while handling large search volumes effortlessly!
Challenges of Scraping Google Search Results
Google’s anti-scraping measures are always evolving, and without the right techniques, your scraper can still get blocked. Here’s a quick recap of the biggest challenges and how to handle them:
1. CAPTCHAs and Bot Detection
Google can detect scrapers and redirect them to a CAPTCHA challenge, making further data extraction impossible. Since you’ve already seen how ScraperAPI’s Render Instruction Set is able to bypass most CAPTCHAs, you know how powerful automated rendering can be for avoiding blocks.
2. IP Bans and Rate Limits
Scraping too many results too quickly from the same IP address will get your requests blocked. The best way to prevent this is by rotating IPs and spreading out your requests. ScraperAPI handles this for you, switching IPs automatically to keep your scraper undetected.
3. Constantly Changing SERP Layouts
Google frequently updates its SERP structure, which can break scrapers relying on fixed HTML selectors. Instead of manually updating your scraper every time Google changes its layout, you can use ScraperAPI’s rendering capabilities to return fully loaded HTML or DOM snapshots to simplify the process and extract dynamic content using more flexible parsing methods.
4. JavaScript-Rendered Content
Some search elements—like People Also Ask boxes or dynamic snippets—only appear after JavaScript runs. If you used ScraperAPI’s Render Instruction Set in the tutorial, you’ve seen how enabling JavaScript rendering ensures all Google search data is fully loaded before extraction.
5. Geographic Restrictions and Personalized Results
Google tailors search results based on location, meaning the same query can produce different results depending on where the request is coming from. To scrape region-specific data, you need geotargeted proxies. ScraperAPI lets you specify country-based IPs, so you can get results from any location.
The Best Way to Scrape Google Search Results
Google’s defenses against web scraping are strong, but ScraperAPI’s Render Instruction Set makes it easier than ever to scrape search results efficiently. Instead of managing proxies, request headers, and CAPTCHA-solving manually, ScraperAPI automates everything for you—allowing you to focus on extracting real-time search data without interruptions.
If you need even more control, Selenium and Playwright provide a browser-based alternative, but they come with higher complexity and slower execution times. For most users, ScraperAPI remains the fastest and most scalable option for Google search scraping.
Now that you know how to handle Google’s anti-scraping measures, let’s look at what you can do with the data you’ve collected.
Wrapping Up: What You Can Do with Scraped Google Search Data
Now that you’ve successfully scraped Google search results, it’s time to put that data to use. Having direct access to search data gives you insights that would otherwise take hours to gather manually.
1. Track Keyword Rankings More Effectively
Knowing where your website ranks is essential for SEO. Scraped search data helps you:
- Monitor rankings across different keywords and locations.
- Track changes over time to measure the impact of SEO strategies.
- Identify search terms where you can improve and outrank competitors.
2. Analyze Competitor Strategies in Detail
Your competitors are constantly working to gain visibility. Scraping Google search results helps you:
- Identify which web pages and articles rank for your target keywords.
- Analyze featured snippets, People Also Ask boxes, and paid ads to see where competitors are appearing.
- Find gaps in their content strategy and create optimized pages to outperform them.
3. Get Insights Into Google Ads and Paid Search
Running paid search campaigns without competitive data can be costly. Extracting Google Ads data allows you to:
- See which businesses are bidding on your target keywords.
- Analyze ad copy, pricing strategies, and landing pages to refine your own approach.
- Compare paid search results with organic rankings to find cost-effective opportunities.
4. Spot Market Trends and Shifting Consumer Interest
Google search data reveals what people are searching for in real time. Scraping search results allows you to:
- Identify trending topics and growing demand in your industry.
- Track seasonal patterns in search volume to adjust your strategy.
- Extract related searches to understand how users think about your topic.
5. Automate Competitor and Industry Monitoring
Manually checking Google every day is inefficient. Scraping automates the process so you always have fresh insights. You can:
- Keep track of new content published by competitors.
- Monitor brand mentions in search results.
- Stay updated on shifts in rankings for key industry terms.
Having direct access to Google’s search data gives you more control, deeper insights, and a competitive edge. Automating data collection saves time and helps you make smarter, data-driven decisions. Try out ScraperAPI to streamline and automate your Google search scraping!
Yes, scraping publicly available search results is generally legal, but how the data is used matters. Some websites’ terms of service prohibit scraping, so it’s important to review Google’s policies and use the data responsibly.
Yes, Google actively blocks scrapers by using CAPTCHAs, IP bans, and request rate limits. However, ScraperAPI rotates IPs, bypasses CAPTCHAs, and renders JavaScript, making it possible to scrape without getting blocked.
ScraperAPI is the best choice for fast, scalable, and automated scraping with built-in IP rotation and CAPTCHA solving. Selenium and Playwright are useful for browser-based scraping but are slower and more complex. Google’s SERP API provides structured search data but has access restrictions and rate limits.
