


Want to learn how to scrape Yelp for business data and reviews? Scraping Yelp allows you to research market trends, identify top-rated businesses, and uncover customers’ thoughts. However, web scraping Yelp comes with challenges, including CAPTCHAs, IP bans, and dynamically loaded content, making extracting information difficult.
In this web scraping tutorial, I’ll guide you through scraping https://www.yelp.com step by step using Python, ScraperAPI, and BeautifulSoup4. You’ll learn how to:
- Scrape Yelp search results, extracting business names, links, and addresses.
- Extract Yelp business details, including business names, star ratings, review counts, and addresses.
- Scrape Yelp reviews while handling pagination and dynamically loaded content using CSS selectors.
- Avoid detection by mimicking actual user behavior and working around bot protection.
- Save Yelp data to a CSV file or JSON dataset for easy analysis.
By the end, you’ll have a fully functional Yelp data scraper capable of gathering insights at scale!
How to Scrape Yelp Using Python: Step-by-Step Tutorial
Scraping Yelp requires the right tools and strategies to bypass anti-scraping protections while extracting valuable business data.
In this section, we’ll go step by step, starting with scraping search results to gather business names, addresses, and links. Then, we’ll extract business details like ratings and review counts from individual pages. Finally, we’ll tackle scraping customer reviews, handling pagination, and dynamically loaded content to collect honest customer feedback.
Ready? Let’s get started!
Project Requirements for Scraping Yelp Data
Before we begin, make sure you have Python installed. Then, install the required Python libraries:
pip install requests BeautifulSoup4 pandas
What Do These Libraries Do?
requests: Handles HTTP requests to fetch Yelp search results, Yelp reviews, and business pages.BeautifulSoup4: Parses HTML content and extracts relevant business information.pandas: Saves scraped data into a CSV file for structured analysis.
Step 1: Set Up ScraperAPI
Yelp blocks scrapers that send too many requests too quickly. Instead of making direct requests, we’ll use ScraperAPI, which rotates proxies, avoids rate limits, and handles JavaScript rendering for dynamic content.
Sign up at ScraperAPI and get your API key. Then, store it in a variable:
API_KEY = "YOUR_API_KEY"
BASE_URL = f"https://api.scraperapi.com/?api_key={API_KEY}&url="
Any request we send to Yelp.com will be routed through ScraperAPI, preventing IP bans and avoiding detection.
Step 2: Scrape Yelp Search Results
To scrape Yelp’s search results, we must first understand how the search page is structured. Open Yelp in your browser, type in “pizza” as the search term and “New York, NY” as the location, and then hit enter. Right-click to inspect the page and open Developer Tools (F12 → Elements tab).
We can see that each business name appears inside an <h3> tag with the class "y-css-14xwok2". If we expand that <h3>, an <a> tag inside holds the business name and a link to its page. This is exactly what we need to extract.
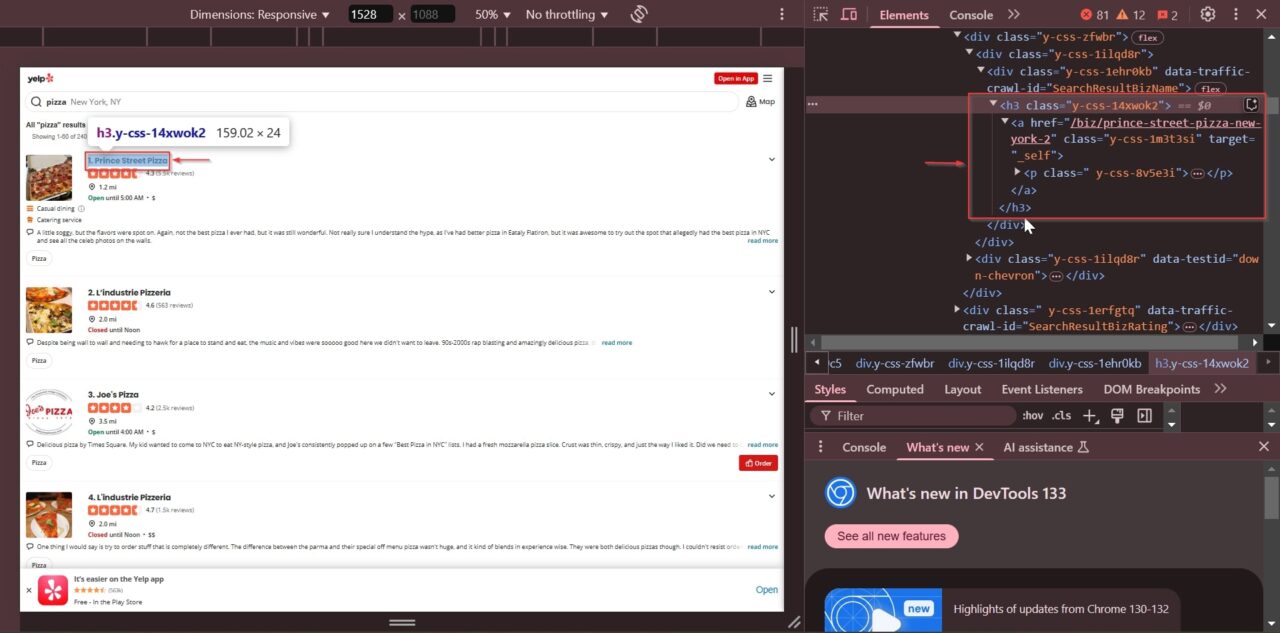
So our plan is simple:
- Load Yelp’s search page for a given business type and location.
- Find all
<h3>tags that store the top 10 business names. - Extract the business name and link from the
<a>tag inside. - Return everything in a structured format.
Since we already set up ScraperAPI, we can request Yelp’s search page using the search term and location.
import requests
from bs4 import BeautifulSoup
def scrape_yelp_search(query, location):
"""Fetch Yelp search results page."""
url = f"https://www.yelp.com/search?find_desc={query}&find_loc={location}"
response = requests.get(BASE_URL + url, params={"premium": "true"})
Here’s what’s happening:
- We format the search URL by inserting the
query(e.g., “pizza”) andlocation(e.g., “New York”). - Instead of making a direct request to Yelp, we send it through ScraperAPI.
- We add
params={"premium": "true"}to enable JavaScript rendering (necessary for some parts of Yelp’s content).
Once we get the response, we must parse the HTML and locate the business names.
soup = BeautifulSoup(response.text, "html.parser")
businesses = soup.find_all("h3", class_="y-css-14xwok2")
This does two things:
- Loads the HTML into BeautifulSoup, which helps us navigate and extract data easily.
- Finds all
<h3>tags with the class"y-css-14xwok2", which store business names.
Now, let’s extract that information:
search_results = []
for biz in businesses:
name = biz.text.strip() # Extract business name
link = biz.find("a")["href"] if biz.find("a") else None # Extract business link
full_link = f"https://www.yelp.com{link}" if link else "N/A" # Convert to full URL
search_results.append({"name": name, "link": full_link})
Here’s how this works:
biz.text.strip()retrieves the text inside the<h3>tag and removes any extra spaces.biz.find("a")locates the first anchor tag, and["href"]extracts its href attribute, which contains the relative link.- Yelp stores links as relative paths (e.g., /biz/pizza-hut-new-york). We concatenate it with “https://www.yelp.com“ to create a full URL.
- We store each business as a dictionary with
"name"and"link", then add them tosearch_resultsfor structured output
Now, we simply return the extracted data:
return search_results
And just like that, we’ve successfully scraped business names and links from Yelp’s search page!
Let’s see our scraper in action by searching for pizza places in New York.
results = scrape_yelp_search("pizza", "New+York")
print(results)
If everything works correctly, the output should look something like this:
[
{"name": "Prince Street Pizza", "link": "https://www.yelp.com/biz/prince-street-pizza-new-york-2"},
{"name": "Joe's Pizza", "link": "https://www.yelp.com/biz/joes-pizza-new-york"},
]
Now we have a list of businesses, and their links are pulled directly from Yelp!
Step 3: Scrape Business Details from Yelp
Now that we have the business names and links from Step 2, we need to extract more details from each business page.
We first need to understand how Yelp structures its business pages to do this. Clicking on a business link from our search results takes us to a page like this:
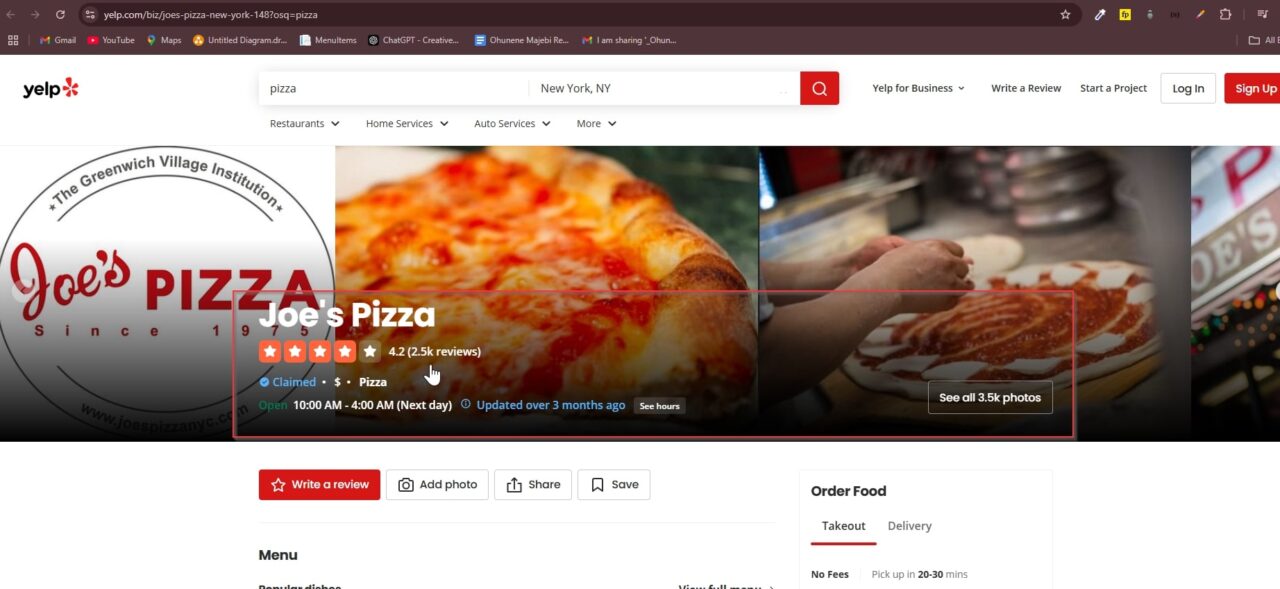
If we inspect the page using Developer Tools (F12 → Elements tab), we find that:
- The business name is inside an
<h1>tag. - The rating is inside a
<span>tag with the class"y-css-1jz061g". - The review count is inside an
<a>tag with the class"y-css-1x1e1r2". - The address is inside an
<address>tag.
These elements contain the structured data we need to extract.
Fetching the Business Page
Since we know Yelp blocks scrapers, we’ll send our requests through ScraperAPI again to avoid detection.
def scrape_yelp_business(biz_url, max_retries=5):
"""Scrape details from a Yelp business page with retries."""
for attempt in range(max_retries):
try:
response = requests.get(BASE_URL + biz_url, timeout=30, params={"premium": "true"}) # Increased timeout
- We send a request to Yelp using ScraperAPI.
- We set a 30-second timeout to handle slow-loading pages.
- If the request fails, we retry up to five times before giving up.
If Yelp responds successfully, we move on to extracting the details.
Extracting Business Information
Once we have the page content, we use BeautifulSoup to parse the HTML and extract the business details.
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
business_data = {
"name": soup.find("h1").text.strip() if soup.find("h1") else "N/A",
"rating": soup.find("span", class_="y-css-1jz061g").text.strip() if soup.find("span", class_="y-css-1jz061g") else "N/A",
"review_count": soup.find("a", class_="y-css-1x1e1r2").text.strip() if soup.find("a", class_="y-css-1x1e1r2") else "N/A",
"address": soup.find("address").text.strip() if soup.find("address") else "N/A",
}
return business_data
- We find each element by searching for its corresponding tag and class using
soup.find(). - We strip any extra spaces from the extracted text.
- To prevent errors, we return
"N/A"if an element is missing.
Web scraping involves sending multiple requests, and sometimes, they fail due to slow responses, network issues, or website restrictions. We need to make sure our scraper doesn’t stop when this happens.
except requests.exceptions.ReadTimeout:
print(f"Timeout on attempt {attempt + 1}. Retrying…")
time.sleep(2 ** attempt) # Exponential backoff (2s, 4s, 8s, etc.)
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
- If the request times out, we retry with an increasing delay (2s → 4s → 8s).
- If another request error occurs, we log the error and move on.
Even after multiple retries, some pages will still fail due to bans or broken links. Instead of stopping the process, we log the failure and move on to the next business.
print("Failed to fetch business page after retries.")
return None
This ensures that a few failed requests don’t stop us from collecting as much data as possible.
Before scraping multiple businesses, we should test our function on a single page to confirm it works.
biz_info = scrape_yelp_business("https://www.yelp.com/biz/prince-street-pizza-new-york-2")
print(biz_info)
If everything is working correctly, we should see structured data like this:
{
"name": "Prince Street Pizza",
"rating": "4.5",
"review_count": "3,456 reviews",
"address": "27 Prince St, New York, NY 10012"
}
Now that we know our function works, we can apply it to multiple businesses from our search results.
results = scrape_yelp_search("pizza", "New York")
detailed_results = []
for biz in results[2:]:
print(f"Scraping: {biz['name']}")
business_info = scrape_yelp_business(biz["link"])
if business_info:
detailed_results.append(business_info)
sleep_time = random.uniform(3, 7) # Random delay between requests
print(f"Sleeping for {sleep_time:.2f} seconds before next request...")
time.sleep(sleep_time)
Code Breakdown:
- We loop through the businesses from our search results, ignoring the first three, which are usually ads.
- We call
scrape_yelp_business()for each one. - We store the results in
detailed_results. - We add a random delay (3-7 seconds) between requests to avoid detection.
After scraping, we need to store the data in a structured format:
import pandas as pd
def save_to_csv(data, filename="yelp_business_data.csv"):
"""Save scraped data to a CSV file."""
if not data:
print("No data to save.")
return
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
print(f"Data saved to {filename}")
Now, we save the results by running:
save_to_csv(detailed_results)
This generates a CSV file containing business names, ratings, review counts, and addresses.
Step 4: Scrape Yelp Reviews
Now that we can extract business details, let’s move on to scraping Yelp reviews. Yelp reviews contain direct customer feedback, making them valuable for sentiment analysis, competitor research, and understanding customer expectations.
However, scraping reviews is more complex than extracting business details because:
- Reviews are dynamically loaded – Yelp uses JavaScript to load more reviews as the user scrolls.
- Pagination is required – Yelp displays reviews across multiple pages, accessible through the
startparameter (&start=10, &start=20for subsequent pages). - Anti-scraping protections exist – Making too many requests quickly can trigger blocks.
To work around these challenges, we’ll use ScraperAPI’s Render Instruction Set to ensure JavaScript executes properly and include scrolling and pagination logic to our function.
Understanding Yelp’s Review Structure
Each review on a Yelp business page is stored inside a <li> tag with the class y-css-1sqelp2:
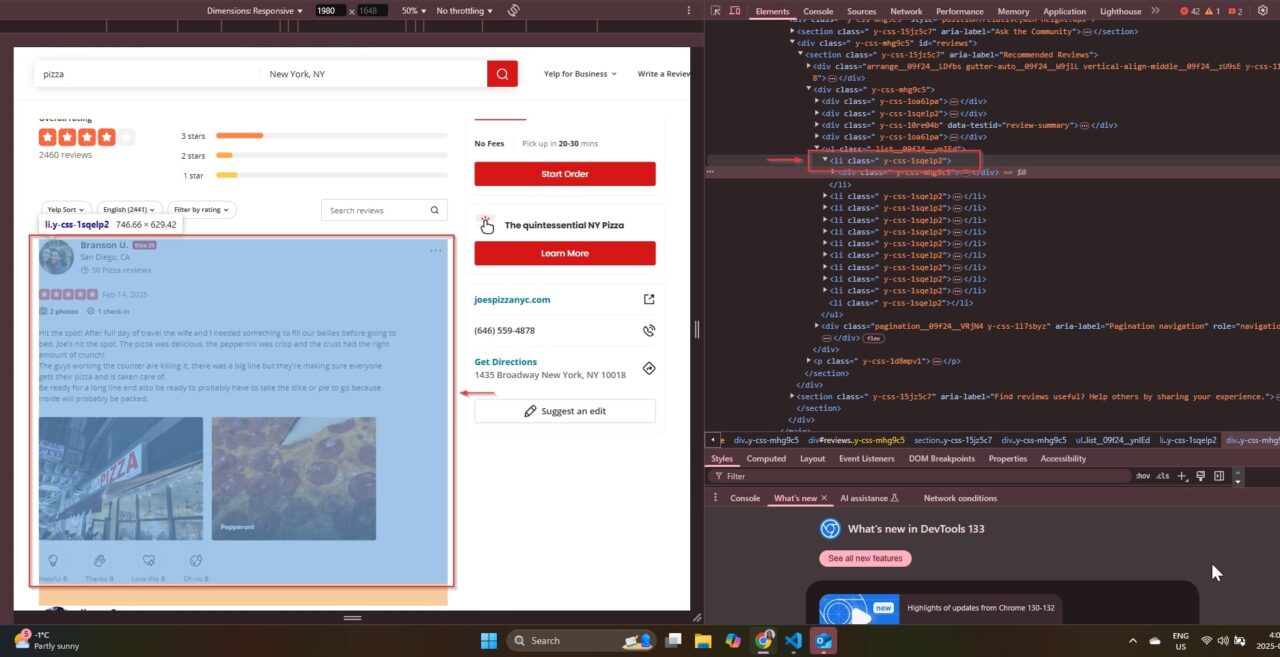
Within this element, the actual review text is found inside a <p> tag with the class comment__09f24__D0cxf y-css-1wfz87z:
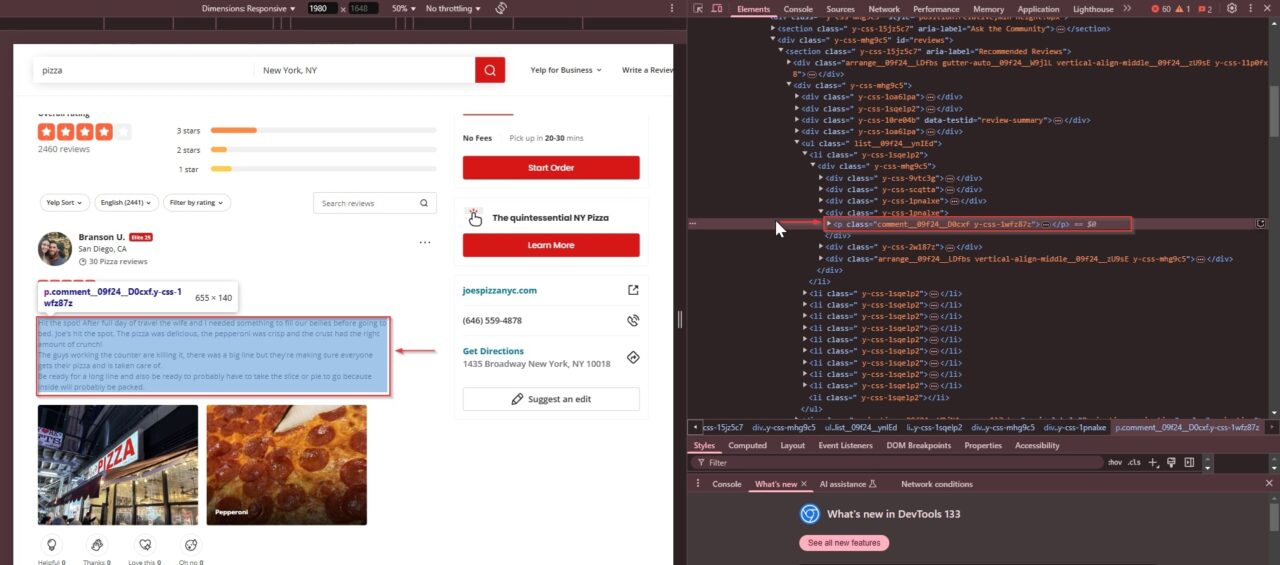
Now, we know where all our data is located. Let’s get to scraping!
Fetching the Business Reviews
Since reviews are loaded dynamically, we need to wait for them to appear and then scroll to the bottom of the page to trigger additional reviews. ScraperAPI allows us to define custom instructions for this.
Let’s start by defining our function:
import json
import time
import requests
from bs4 import BeautifulSoup
def scrape_yelp_reviews(biz_url, max_retries=5):
"""Scrape the first few customer reviews from a Yelp business page with retry on error 500."""
reviews = []
page_number = 0
Here, we:
- Initialize an empty list (
reviews) to store extracted review texts - Set
page_numberto 0, which we’ll increment as we navigate through review pages - Allow up to
max_retriesin case of failures
Handling Dynamic Review Loading
Since Yelp requires scrolling to load more reviews, we use ScraperAPI’s instruction set to simulate user behavior:
for attempt in range(max_retries):
try:
for i in range(5): # Scroll multiple times to load reviews
instruction_set = json.dumps([
{"type": "wait_for_selector", "selector": {"type": "css", "value": "li.y-css-1sqelp2"}},
{"type": "scroll", "direction": "y", "value": "bottom"},
{"type": "wait", "value": 10} # Wait for new reviews to load
])
Here’s what this does:
- Waits for the first review element to appear (
li.y-css-1sqelp2) - Scrolls down to trigger more reviews
- Waits 10 seconds to give Yelp time to load them before scraping
Once we’ve defined how the scraper should behave, we send a request to ScraperAPI:
headers = {
"x-sapi-api_key": API_KEY,
"x-sapi-render": "true",
"x-sapi-instruction_set": instruction_set
}
# Ensure proper pagination formatting
paginated_url = f"{biz_url}&start={page_number}" if "start=" not in biz_url else biz_url
params = {"url": paginated_url, "render": "true"}
response = requests.get("https://api.scraperapi.com/", params=params, headers=headers)
This does the following:
- Passes ScraperAPI headers, including:
- Our API key for authentication.
- Rendering mode to execute JavaScript
- The instructions set to scroll and wait for the content to load
- Formats the URL to handle pagination (
&start=10, &start=20, etc.). - Sends a request to ScraperAPI to fetch the page
Once the page loads, we parse the HTML using BeautifulSoup and locate the reviews:
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Find all review elements
review_elements = soup.find_all("li", class_="y-css-1sqelp2")
# Extract text from each review
for review in review_elements:
review_text = review.find("p", class_="comment__09f24__D0cxf y-css-1wfz87z")
reviews.append(review_text.text.strip() if review_text else "N/A")
Here’s what this does:
- Finds all review containers (
li.y-css-1sqelp2) - Extracts review text from the
<p>tag inside each review - Adds the extracted text to
reviews, handling missing content gracefully
Since Yelp paginates reviews, we need to increment the page number and continue scraping:
page_number += 10
time.sleep(2) # Prevent rate limiting
Each page contains 10 reviews, so we increase page_number by 10 before moving to the next request.
Handling Errors and Retries
Yelp may return errors or block requests. We handle timeouts, 500 errors, and other request failures like this:
elif response.status_code == 500:
print(f"Error 500 on attempt {attempt + 1}. Retrying in {2 * attempt} seconds...")
time.sleep(2 * attempt) # Exponential backoff
continue
else:
print(f"HTTP {response.status_code}: {response.text[:500]}") # Print first 500 characters of error
return None
except requests.exceptions.ReadTimeout:
print(f"Timeout on attempt {attempt + 1}. Retrying in {2 ** attempt} seconds...")
time.sleep(2 ** attempt)
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
This ensures:
- If the server returns a
500error, we retry with exponential backoff (2s → 4s → 8s). - If the request completely fails, we print the error and move on.
If all attempts fail:
print("Failed to fetch reviews after multiple retries.")
return None
Now, let’s scrape reviews for multiple businesses from Step 2:
detailed_reviews = {}
for biz in results[:10]: # Limit to top 10 businesses
print(f"Scraping reviews for: {biz['name']}")
business_reviews = scrape_yelp_reviews(biz["link"])
if business_reviews:
detailed_reviews[biz["name"]] = business_reviews
time.sleep(3) # Add delay to avoid being blocked
# Print the extracted reviews
for biz, reviews in detailed_reviews.items():
print(f"\n{biz} Reviews:")
for review in reviews:
print(f"- {review}")
Here, we:
- Loop through the top 10 businesses.
- Scrape their reviews using our function.
- Store results in a dictionary, with business names as keys and their reviews as values.
- Add a delay between requests to prevent blocking
Step 5: Run Your Yelp Scraper
Now that you’ve built functions to scrape search results, business details, and reviews, it’s time to bring everything together. This is where you run the complete scraper, automatically collecting and saving Yelp data.
try:
# Step 1: Get search results and save to CSV
print("Scraping search results...")
search_results = scrape_yelp_search("pizza", "New+York")
save_to_csv(search_results, "search_results.csv")
print("Search results saved.")
# Step 2: Get business details for each result and save to CSV
print("Scraping business details...")
business_details = []
for result in search_results:
biz_data = scrape_yelp_business(result["link"])
if biz_data:
business_details.append(biz_data)
save_to_csv(business_details, "business_details.csv")
print("Business details saved.")
# Step 3: Get reviews for each business and save to CSV
print("Scraping reviews...")
all_reviews = []
for result in search_results:
reviews = scrape_yelp_reviews(result["link"])
if reviews:
for review in reviews:
all_reviews.append({"business": result["name"], "review": review})
save_to_csv(all_reviews, "reviews.csv")
print("Reviews saved.")
except Exception as e:
print(f"An error occurred: {e}")
print("Scraping process completed.")
Code Breakdown:
Now, let’s go through what this part of the script is doing step by step:
- Scraping Search Results:
- Calls
scrape_yelp_search()to fetch businesses from Yelp’s search page - Extracts business names, links, and addresses
- Saves everything into
search_results.csv, creating a structured dataset for the next steps - Loops through each business link in
search_results.csv
- Calls
- Extracting Business Details:
- Calls
scrape_yelp_business()to visit the business page and extract:- Star ratings
- Review counts
- Other business details
- Calls
- Scraping Customer Reviews:
- Stores this structured data in
business_details.csvfor later analysis - Iterates through each business and calls
scrape_yelp_reviews() - Collects multiple reviews per business, handling pagination if needed
- Stores the extracted reviews in
reviews.csv, with each review linked to the business name for easy reference
- Stores this structured data in
- Error Handling:
- Catches unexpected errors so the script doesn’t crash
- If a request fails or a business page is unavailable, the script logs the issue and continues running instead of stopping entirely
This script automates the entire scraping process, giving you a complete dataset of business details, customer reviews, and ratings in just a few runs!
How to Turn Yelp Pages into LLM-Ready Data
Large language models (LLMs) are great at extracting insights—but only when the input is structured, readable, and rich in context. Yelp listings are a goldmine of information: business names, categories, locations, ratings, and even patterns in customer reviews. But to unlock that value, the data needs to be presented in a format LLMs can work with.
Instead of feeding raw HTML, we can use ScraperAPI’s output_format=markdown to get clean, readable text that mirrors what a human would see. This makes it easier for models like Gemini to identify the most relevant businesses, surface trends, and even generate summaries across categories.
In this section, we’ll walk through how to use ScraperAPI to get structured Yelp data in Markdown format, and then feed that directly into Gemini for summary.
Step 1: Get Your API Keys
Before proceeding, ensure you have a ScraperAPI key and a Google Gemini API key. If you already have them, you can skip ahead. Otherwise:
- Get your ScraperAPI Key: Sign up here for a free API key with 5,000 API credits.
- Get your Gemini API Key:
- Visit Google AI Studio
- Sign in with your Google account
- Click Create API Key and follow the prompts.
Step 2: Scrape Yelp Listings in Markdown Format
We’ll use ScraperAPI to request the Yelp search results page, but instead of parsing HTML, we set the output_format to “markdown“. This gives us a cleaner version of the page—more readable and structured, which is exactly what LLMs need.
import requests
API_KEY = "YOUR_SCRAPERAPI_KEY"
url = "https://www.yelp.com/search?find_desc=Pizza&find_loc=New+York%2C+NY%2C+United+States"
payload = {
"api_key": API_KEY,
"output_format": "markdown",
"url": url
}
response = requests.get("https://api.scraperapi.com", params=payload)
markdown_data = response.text
print(markdown_data)
The response is returned as Markdown—essentially a plain text snapshot of what a user would see on the page. It includes business names, categories, locations, and often review counts and ratings.
You should get a similar output:
* [](/biz/prince-street-pizza-new-york-2?osq=Pizza)
### 1. [Prince Street Pizza](/biz/prince-street-pizza-new-york-2?osq=Pizza)
4.3 (5.5k reviews)
Nolita$Loading...
Casual dining
Catering service
"this place comes in right behind them and is otherwise an excellent choice for delicious pizza." [more](/biz/prince-street-pizza-new-york-2?hrid=qIfFieWi9DmARf8Ero%5FLOw&osq=Pizza)
[Pizza](/search?find%5Fdesc=Pizza&find%5Floc=New+York%2C+NY)
* [](/biz/l-industrie-pizzeria-new-york?osq=Pizza)
### 2. [L'industrie Pizzeria](/biz/l-industrie-pizzeria-new-york?osq=Pizza)
4.6 (629 reviews)
West VillageLoading...
"Delicious delicious pizza wooooow! I had this multiple times during my week-long trip to New York..." [more](/biz/l-industrie-pizzeria-new-york?hrid=3XgCcLp70sfj9arm64xSxA&osq=Pizza)
[Pizza](/search?find%5Fdesc=Pizza&find%5Floc=New+York%2C+NY)
* [](/biz/joes-pizza-new-york-148?osq=Pizza)....
ScraperAPI supports both “text” and “markdown” formats, so you can experiment with each depending on your use case. In this case, we found that the Markdown output gave Gemini more context to work with—it picked up business names, categories, and ratings more reliably. Try both and see which works best for your prompts.
Step 3: Summarise the Listings with Gemini
Once we have our structured Markdown data from Yelp, we can pass it directly into a large language model to generate summaries. We’ll be using Google’s gemini for this example.
Start by installing the Gemini SDK if you haven’t already:
pip install google-generativeai
Next, configure the model and pass in your prompt. In this case, we’ll ask Gemini to extract and summarise key details from the listings.
import google.generativeai as genai
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel(model_name="gemini-2.0-flash")
prompt = f"""
Below is a snippet of a Yelp search results page for pizza in New York City.
Your task is to extract and summarize the top 3 restaurants. For each, include:
- Restaurant Name
- Rating and Number of Reviews
- Address
- Standout Features or Offerings
- Why it might be popular
Here is the data:
{markdown_data}
"""
response = model.generate_content(prompt)
print(response.text)
You can tweak the prompt depending on what insights you want—maybe filter for specific cuisines, rank by rating, or group by neighbourhood. Because the input is already in a structured format, you don’t need to clean it again—just update the prompt.
Here’s an example of the output you might get from Gemini after running the script:
Here's a summary of the top 3 pizza restaurants in New York City based on the Yelp search results you provided:
1. **L'industrie Pizzeria**
* **Rating and Number of Reviews:** 4.6 stars (629 reviews)
* **Address:** West Village
* **Standout Features or Offerings:** Delicious pizza.
* **Why it might be popular:** Known for its delicious pizza.
2. **Prince Street Pizza**
* **Rating and Number of Reviews:** 4.3 stars (5.5k reviews)
* **Address:** Nolita
* **Standout Features or Offerings:** Casual dining, catering service.
* **Why it might be popular:** Excellent choice for delicious pizza, catering services.
3. **Juliana's**
* **Rating and Number of Reviews:** 4.4 stars (2.9k reviews)
* **Address:** DUMBO
* **Standout Features or Offerings:** Fresh ingredients, delicious pizza, and top-notch service.
* **Why it might be popular:** Known for the high-quality ingredients and service, making it a top-rated pizza experience.
By combining ScraperAPI and Google Gemini, you’ve just built a smarter way to extract Yelp insights at scale. Instead of scraping raw HTML and trying to make sense of scattered tags, you worked with clean, human-readable Markdown and let the LLM do the heavy lifting.
Why Scrape Yelp and What You Can Do With the Data
Now that we can extract Yelp business details, reviews, and ratings, the next question is: why does this data matter? Yelp is more than just a review site—it’s a constantly updated database of customer experiences, industry trends, and competitive insights.
Scraping Yelp lets you analyze this information at scale. Instead of reading individual reviews manually, you can track patterns, measure customer sentiment, and make data-driven decisions.
Why Scrape Yelp?
- Understand the competition: Track top businesses, analyze their strengths, and see what customers like or dislike.
- Improve business strategy: Reviews highlight common complaints and praises, giving you direct insight into customer expectations.
- Find new leads: Yelp acts as a directory for businesses across industries. Scraping business listings and reviews allows for targeted outreach.
- Optimize for SEO and local search: High-ranking Yelp businesses offer clues about what customers search for. Extracting their keywords and descriptions helps refine your strategy.
- Identify market trends: Analyze review trends over time to see emerging demands, pricing shifts, or changes in customer sentiment.
What Can You Do With This Data?
- Track the best-performing businesses in a specific industry or location.
- Analyze customer sentiment by aggregating and categorizing review content.
- Monitor competitor performance over time and identify areas where they struggle.
- Discover untapped markets by comparing business density, ratings, and demand in different areas.
- Improve marketing efforts using genuine customer feedback to craft better messaging.
Yelp data provides a direct line to customer opinions and industry trends. Whether you’re improving a business, running a market analysis, or optimizing a strategy, scraping Yelp gives you the information you need to make smarter decisions.
Wrapping Up: Best Practices for Scraping Yelp
Scraping Yelp can be challenging, but you can extract valuable business data with the right approach while avoiding blocks and CAPTCHAs. This guide taught you how to fetch Yelp pages, extract key details, handle request failures, and scale the process efficiently.
By using ScraperAPI, you don’t have to worry about IP bans, CAPTCHAs, or dynamically loaded content—those challenges are handled for you. That means you can focus on getting the data you need rather than fighting against Yelp’s restrictions.
To make the most of web scraping Yelp, keep these best practices in mind:
- Respect website policies: Always review Yelp’s Terms of Service and be aware of any legal considerations.
- Monitor request success rates: Track failures and adjust your approach if you notice increased blocks.
- Optimize your parsing logic: Extract only the data you need to improve efficiency and reduce processing time.
- Control request volume: Space out requests and avoid making too many quickly to stay under the radar.
- Store data in a structured format: Use CSV, JSON, or a database to keep your scraped data organized and easy to analyze.
Following these strategies, you can build a scalable and reliable Yelp scraper that runs smoothly without interruptions. ScraperAPI takes care of the most complex parts—now it’s up to you to put the data to work.
Happy scraping!
How to Scrape Yelp: Frequently Asked Questions
Is web scraping Yelp legal?
Yes, but scraping Yelp without permission may violate Yelp’s Terms of Service. While web scraping is legal in some cases, bypassing security measures, ignoring robots.txt, or using the data for commercial purposes could lead to legal consequences. To avoid potential risks, review Yelp’s policies and scrape responsibly.
How do I scrape Yelp without getting blocked?
You need to take a strategic approach to scrape Yelp effectively without getting blocked. Using ScraperAPI can help you avoid IP bans. Introducing random delays between requests makes your scraper behave more like a human user. Limiting request volume prevents detection while rotating user agents and headers make each request appear unique. Monitoring request failures and adjusting your scraping behavior can also help reduce the risk of being blocked.
What are the best tools for scraping Yelp?
The best tools for scraping Yelp depend on the data you need. ScraperAPI is key for bypassing CAPTCHAs, rate limits, and IP bans while requests fetches the page content, and BeautifulSoup parses the HTML for business details and ratings. For JavaScript-heavy pages like reviews, Selenium or Playwright can simulate user interactions. Still, ScraperAPI’s Render Instruction Set is a more efficient option, which automates scrolling, waiting, and pagination without requiring a full browser.
Does Yelp block scrapers?
Yes, Yelp has strong anti-scraping measures in place. It uses rate limiting to block frequent requests from the same IP, serves CAPTCHAs to detect automation, and blacklists IPs that show bot-like behavior. Some content is also loaded dynamically with JavaScript, making it difficult to scrape using simple HTTP requests. To avoid being blocked, using tools like ScraperAPI, limiting request frequency, and randomizing delays between requests can help keep your scraper running.
Are there alternatives to scraping Yelp?
Instead of scraping Yelp, you can use the Yelp API, which provides structured business data with strict usage limits. Other APIs also offer business details and location information without scraping.