


Are you looking for how to scrape job postings with Python in 2026? In this guide, we will walk you through where to scrape job postings, how to do it, and what to do with the collected data.
As of September 2024, the U.S. had over 7.4 million job openings, with most job seekers searching online. It’s no surprise that automation solutions continue to emerge at a rapid pace.
Clearly, job scraping is quickly becoming one of the hottest trends in today’s recruitment market. Job websites are a great resource for recruitment and HR departments as scraping job data can help you find the best candidates, understand the job market, and improve your recruitment strategies.
Let’s get started!
Where to Scrape Job Postings From?
At its core, job scraping is all about using automated tools to gather job postings from different online places like websites, job boards, and company career pages.
Companies distribute job postings on various platforms, including their own website, and with job scraping, you can easily get hiring information such as job title, job description, location, and compensation.
Let us quickly explore some of these sources:
- Job Boards: Job boards are websites where employers directly post job ads for individuals to review and apply. Specialized job boards may only include postings for certain types of work or jobs within a specific industry, such as technology roles, healthcare positions, or creative careers. For example, Bitcoiner Jobs is a job board for the Bitcoin ecosystem.
- Job Aggregators: These platforms consolidate job postings from multiple sources. They collect and store job opportunities from job boards, career pages, and other online sources in a searchable database. Thus, they act as an all-in-one solution for job seekers who want to browse multiple listings without visiting multiple sites. Popular job aggregators include Indeed and SimplyHired.
- Career Pages: Career pages are sections of a company’s website listing job openings within that organization. These pages often include detailed descriptions and application instructions. Also, they reflect the company’s branding, culture, and hiring needs. Large corporations like Amazon and Microsoft have well-developed career pages that attract a wide range of talent for various positions.
- Job Search Engines: Job search engines are similar to traditional search engines like Google but specialize in finding and indexing job postings. They scrape the web, index job listings from various online sources, and store links to the job postings. A good example of this is Google for Jobs.
- Social Media Platforms: Social media platforms are online spaces where users connect, share content, and engage with communities. These sites blend structured job posts with unstructured social content, requiring careful filtering during scraping. Popular social media platforms include LinkedIn and X (formerly Twitter).
What is Job Posting Data?
Job posting data refers to all the information presented in job listings or advertisements that employers publish to attract potential employees. This data typically includes the following:
- Company Information These include details such as industry, company size, and location. Employers often highlight achievements, goals, and values to help applicants understand the organization they may join.
- Core Position Details: Tasks, specific duties, objectives, and Hybrid/remote policies for the role. Job titles and descriptions usually outline what the position entails and what is expected of the candidate if hired.
- Requirements & Qualifications: These include qualifications, degree requirements, experience, skills, and any certifications needed for the job. These criteria help both employers and job seekers determine whether a candidate is a good fit.
- Compensation & Benefits: These include salary ranges, bonus structures, stock options, benefits, and perks offered to the potential employee. Transparent compensation details build trust and manage expectations.
- Application Information: Instructions on how and when to apply, including required documents, deadlines, and contact details. Applicants need clear guidelines to submit complete and timely applications.
By systematically scraping and analyzing this job posting data, companies and job seekers can uncover valuable insights into hiring trends, emerging skill demands, and competitor strategies.
How to Collect and Store Job Postings in 2026
After identifying what job posting data to scrape and where to find it, the next step is to collect the data for ourselves. To demonstrate this, we will scrape job posting data from a popular job board – Monster.com.
Monster.com is one of the top sites for job seekers and employers in the United States. It attracts over 5.6 million visitors monthly and hosts thousands of active job listings across various industries. By scraping Monster.com, you can get tons of job data to use for analytics, market monitoring, or to build a custom job search tool.
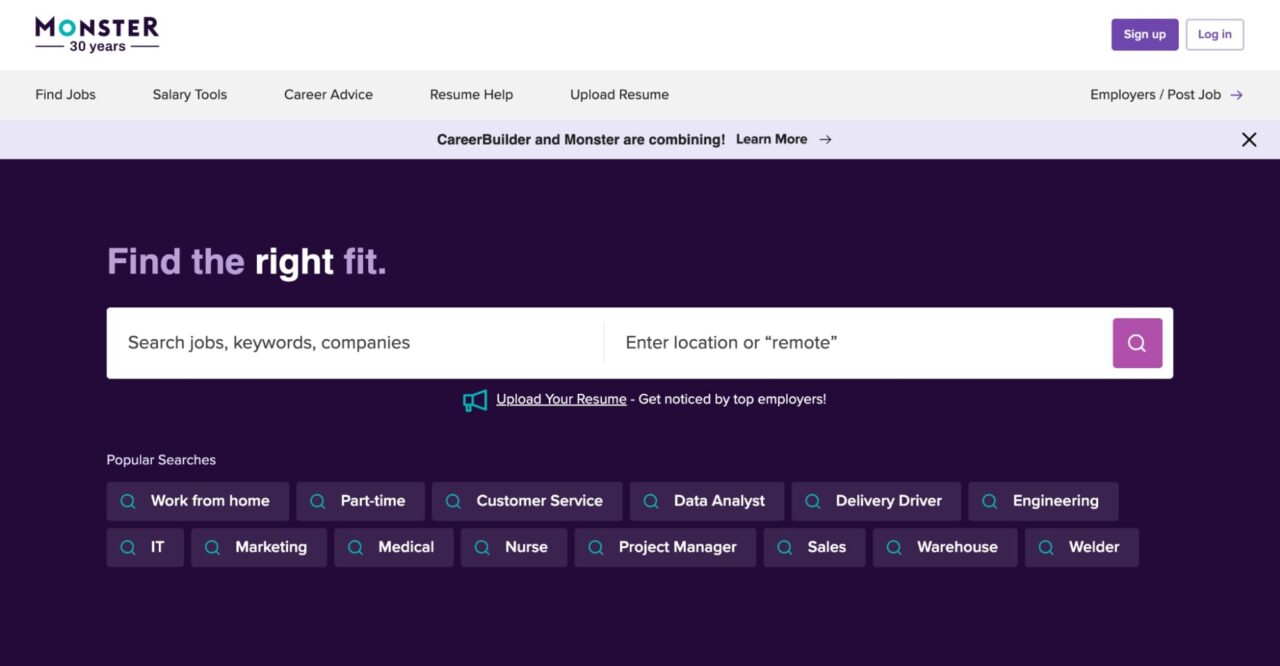
A quick DNS lookup using Wappalyzer reveals that Datadome, a top-tier bot protection provider, protects Monster.com. This means that regular Python requests will not be sufficient for us to obtain any meaningful job posting data. Furthermore, Monster.com uses dynamic content loading and scroll-based pagination.
Note: Datadome can be really tricky to bypass. Luckily, ScraperAPI is always three moves ahead. Check out our guide on how to bypass Datadome protected sites.
To overcome this, we’ll use Selenium, which automates browsers in a way that mimics human interactions. Selenium handles dynamic content loading and scroll-based pagination by executing JavaScript and interacting with page elements like a real user.
For enhanced reliability, we will integrate ScraperAPI, which manages proxy rotation and headless browser instances, as Selenium cannot bypass complex anti-bot systems on its ownIf you are new to Selenium or need a refresher, we have a quick start guide to help you get up to speed. Otherwise, follow along with the article. Let’s jump right into it!
Step 1: Setting Up Web Scraping for Job Boards
Before we start scraping any job postings, you need to set up your development environment. Here’s what you’ll need to get started with the project:
1. ScraperAPI
First, you will need a ScraperAPI account. Simply head over to our signup page to get started with 5,000 free API credits on the house.
ScraperAPI is a fully managed scraping service. With it, you can collect data from any public website using a web scraping API without worrying about proxies, headless browsers, or CAPTCHA. After signing up, head over to the dashboard to retrieve your API key and keep it handy for later use.
2 . Python Installation
To install Python, download the installer, run it, and follow the installation wizard.
Note: If you are new to Python or web scraping, check out our simple guide on web scraping with Python. You’ll also need an IDE. PyCharm Community Edition or Visual Studio Code with the Python extension are great choices. Open your terminal and execute the following commands to create a folder for your project:
mkdir monster-scraper
cd monster-scraper
Step 2: Install the scraping libraries
1. Selenium Wire
As mentioned earlier, Selenium is great, but it can’t bypass complex anti-bot systems on its own. To do this, we can add a proxy to our Selenium scraper. But Selenium does not natively support authenticated proxies, so enter Selenium Wire.
Selenium Wire extends Selenium to access the browser’s requests and allows you to change them as desired. It makes it easier to set up proxies, allowing your requests to appear as if they come from different IP addresses. You can install Selenium Wire using pip:
pip install blinker==1.7.0 selenium-wire setuptools
Note: Selenium Wire depends on blinker version 1.7.0 and setuptools. Ensure you install these dependencies for smooth operation.
You’ll also need ChromeDriver or another compatible WebDriver that matches your browser version. Alternatively, you can install webdriver-manager to handle this automatically:
pip install webdriver-manager
Using Selenium Wire with ScraperAPI, you can automate job posting searches while minimizing the risk of being blocked. ScraperAPI handles tasks like IP rotation and CAPTCHA solving, which are necessary for bypassing DataDome’s tight security measures.
2. BeautifulSoup
BeautifulSoup is used to parse HTML and XML documents. It will help us parse job data efficiently once the page resource has loaded. To install Beautifulsoup, run the following command:
pip install beautifulsoup4
3. Undetected Chromedriver
Undetected Chromedriver helps you avoid detection by web security measures such as DataDome. Install it using the following command:
pip install undetected-chromedriver
Optional – Use a Virtual Environment:
It is recommended to create a Python virtual environment to ensure that the proper versions of each package are installed without conflicts:
python -m venv job_scraping_env
To activate the virtual environment:
./job_scraping_env/bin/activate # For Linux and macOS
job_scraping_env\Scripts\activate # For Windows
Browser Requirements
Ensure that you have a recent version of Google Chrome installed, as undetected Chromedriver works best with it.
Step 3: Understanding Monster’s URLs and Page Structure
Open Monster and search for jobs you are interested in. In this example, you will see how to scrape remote job postings for Data analysts in Arizona.
Here is what the target page looks like in the browser as of this writing:
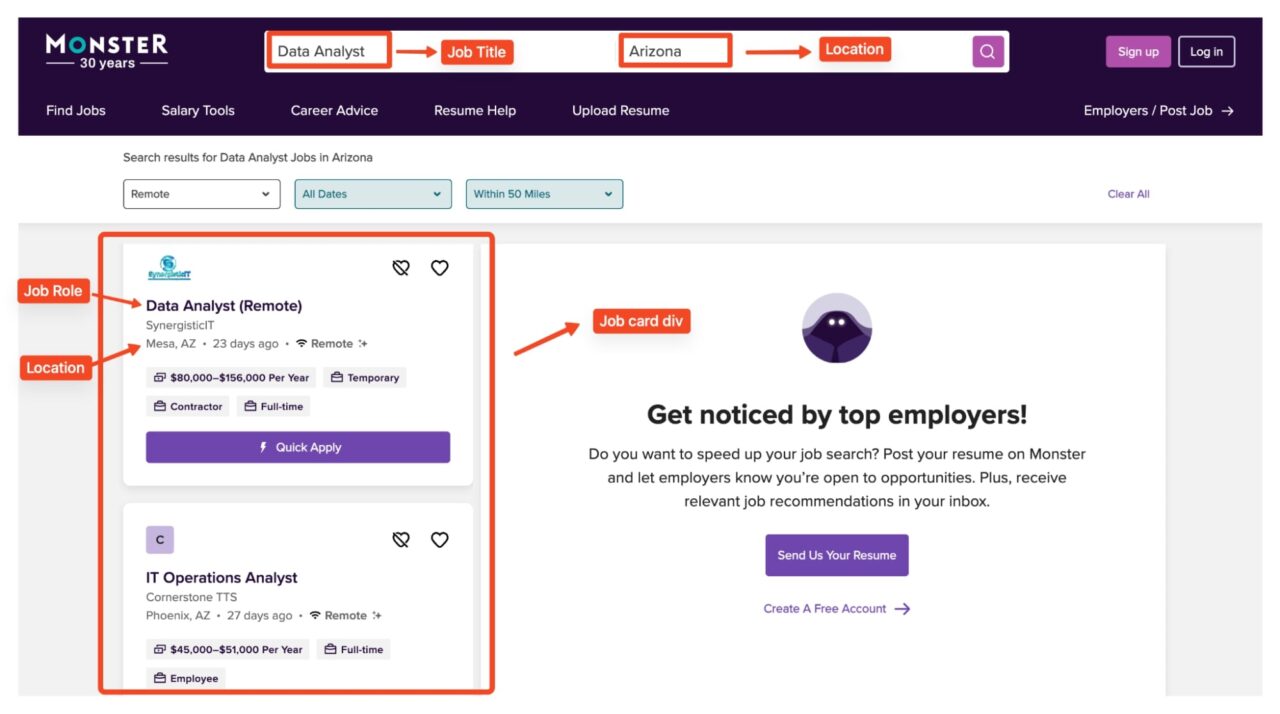
Specifically, this is what the URL of the target page looks like:
https://www.monster.com/jobs/search?q=data+analyst&where=Arizona&page=1&rd=50&so=m.s.sh
Monster’s URLs often contain one or more of the following query parameters:
- q: The job title or keyword
- where: The location
- page: Page number of the search results
- so: Sorting order
Adjusting these parameters lets you target different roles, locations, or result pages. Once you have defined your query, keep the URL handy.
Familiarize yourself with the page structure.
Before we get started writing any code, there is another crucial step. Scraping data from a site involves selecting HTML elements and extracting data from them.
Finding a way to get the desired data from the DOM is not always easy. Let us look at the page structure of our target site.
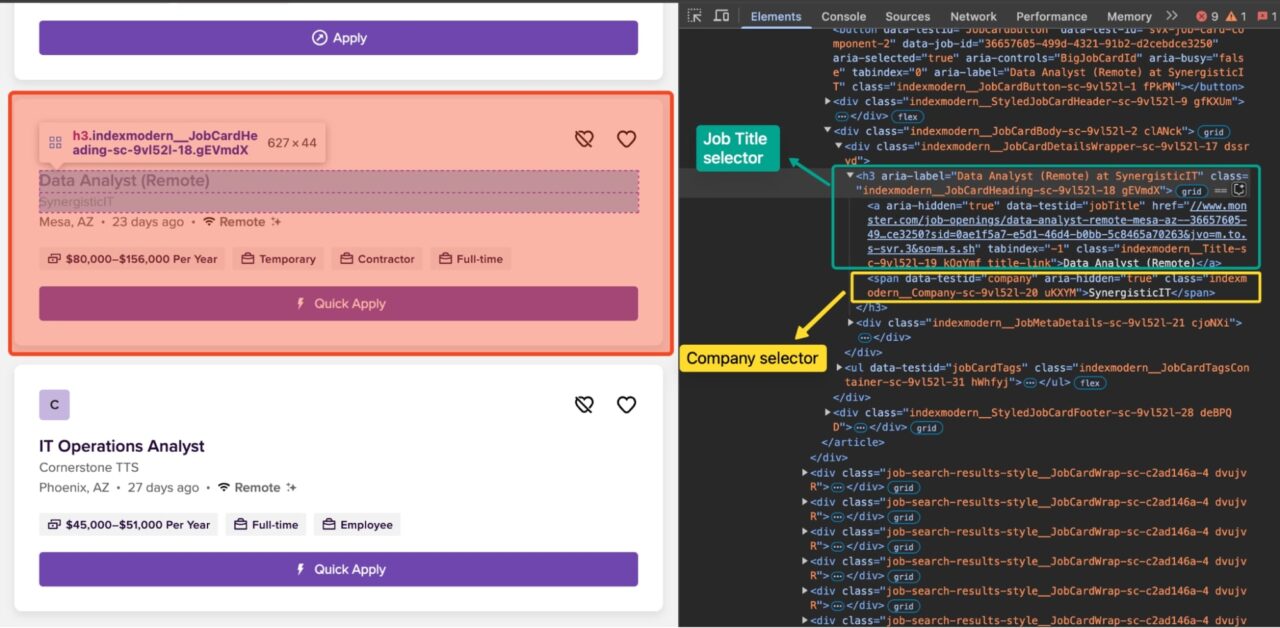
After the Monster job search page loads, right-click on any element and select the “Inspect” option to open the Developer Tools in your browser. You can also use the following keyboard shortcuts:
- Windows:
F12orControl + Shift + I - macOS:
Command + Option + I
Within the Developer Tools, observe that many elements containing valuable data have CSS classes such as:
indexmodern__JobCardHeading-sc-9vl52l-18- i
ndexmodern__Location-sc-9vl52l-22 indexmodern__Company-sc-9vl52l-20 uKXYM
Since these appear to be randomly generated at compile time, you should not rely on them for scraping. Instead, you should base the selection logic on unique HTML attributes like :
data-testid="JobCard”data-testid="jobDetailLocation”data-testid="company"
These identifiers may be more reliable than randomly generated class names. Keep inspecting the target site and familiarize yourself with its DOM structure until you feel ready to move on to writing your scraper code.
Step 4: Importing Libraries and Defining Variables
Open your project folder and create a Python file, such as monster_job_scraper.py. In this file, import the following libraries:
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import json
from time import sleep
Next, create two variables to store your API key and the target URL:
APIKEY = "YOUR_SCRAPERAPI_KEY"
monster_url = "https://www.monster.com/jobs/search?q=data+analyst&where=Arizona&page=1&rd=50&so=m.s.sh"
Note: I highly recommend you use an environment variable to manage the API key so you do not accidentally commit it to version control.
Step 5: Initializing the Browser Instance
The basic idea here is to control a web browser with Selenium. To do so, you need to create and configure a Chrome driver instance so Selenium can talk to Chrome.
We will use undetected-chromedriver to help avoid anti-bot detection. Below is the function that handles this initialization:
def init_driver(api_key, headless=True):
proxy_url = f"https://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001"
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
if headless:
options.add_argument("--headless")
# Selenium Wire proxy configuration
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
# Initialize undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
return driver
Once the driver is initialized, you can open the job list URL using driver.get(). We added the --disable-blink-features=AutomationControlled flag to reduce automation detection and headless=True to run the scraper in the background without displaying a visible browser window. You can change this to False for debugging if needed.
Dealing with Monster’s anti-scraping measures
Monster is protected by DataDome, which employs various techniques to prevent bots from accessing its job data. For example, when interacting with the job cards, you can be served a hot plate of CAPTCHA anytime:
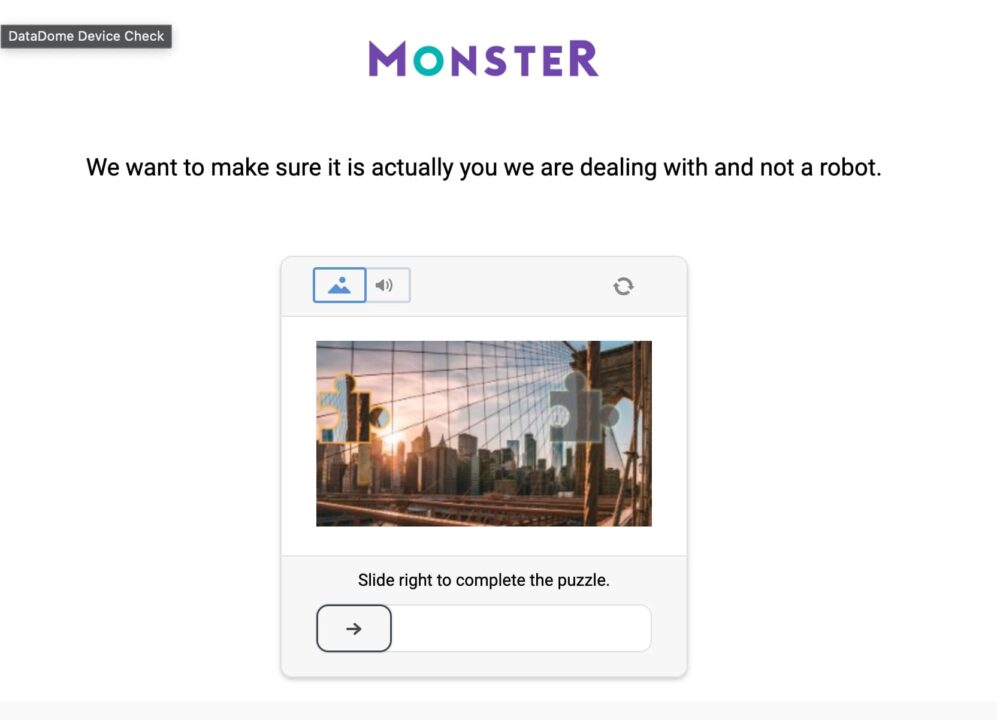
This popup blocks interaction and can halt your Selenium script if handled incorrectly. Solving DataDome’s CAPTCHAs from Selenium is very challenging, so scraping Monster is not that easy after all.
Fortunately, you can avoid them by introducing ScraperAPI in your script.
proxy_url=f"https://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001"
We will use ScraperAPI in proxy mode, which has the same functionality and performance as sending requests to the API endpoint. This addition will handle rotating proxies, captcha solving, and geolocation, giving our script some much-needed robustness.
Step 6: Extracting Job Data from Monster.com
Next, we want to load the target URL in our driver and wait for the page to render fully. We will use selenium to locate the job cards on the page and wait for them to load fully, ensuring that the relevant HTML elements are loaded before proceeding.
def fetch_page_source(driver, url, wait_time=10):
print(f"Fetching URL: {url}")
driver.get(url)
print("Waiting for page to load and bypass possible CAPTCHA...")
sleep(wait_time)
try:
# Wait for the container that holds the job postings
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, "JobCardGrid"))
)
except:
print("Could not locate JobCardGrid; potential CAPTCHA or block.")
return None
page_source = driver.page_source
# Give a short extra wait to ensure all elements are fully loaded
sleep(5)
return BeautifulSoup(page_source, 'lxml')
We parse the page source with BeautifulSoup for easier HTML extraction later.
Step 7: Extracting Job Data from Monster.com
Once we have the page’s HTML, we can locate specific job elements and extract data such as job title, company, location, salary, etc.
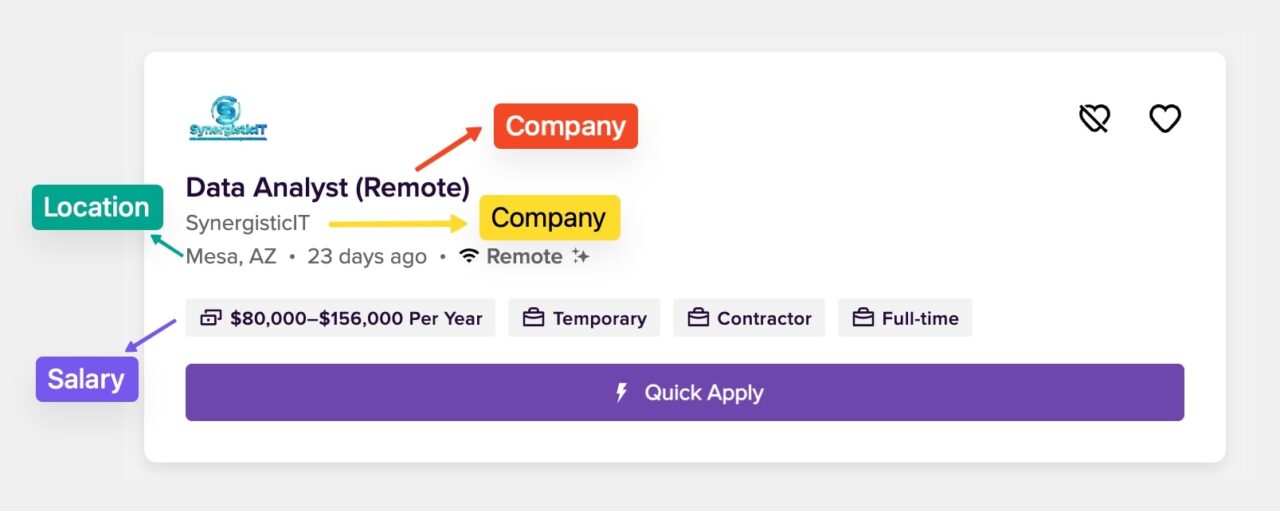
Note that page structures can change, so always verify that the HTML tags and attributes match what you see in the browser.
Now, we can build a function parse_monster_jobs() that processes the raw HTML and returns a list of job postings. A single Monster search page involves several job openings. So, you need an array to keep track of the jobs scraped from the page:
jobs_data = []
You must have noticed that Monster structures its job postings using article elements with the data-testid=”JobCard” attribute. Let’s create our parsing function to extract each piece of information.
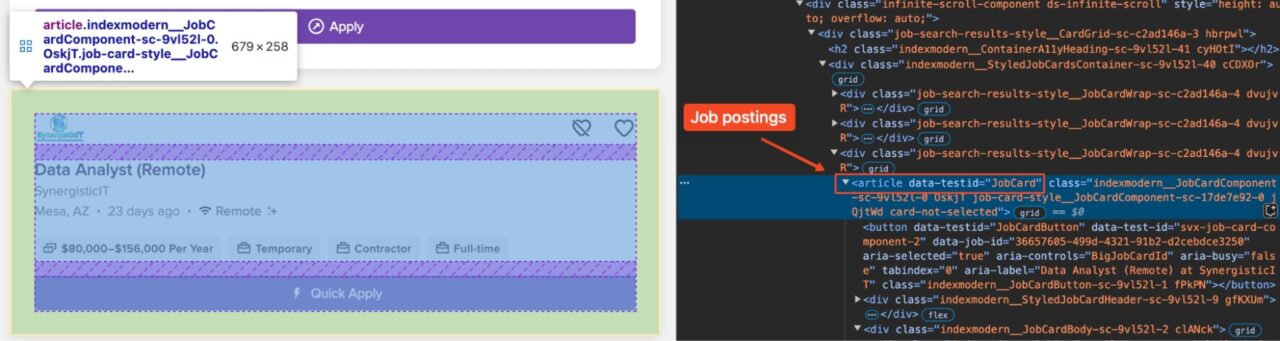
First, create the base function:
def parse_monster_jobs(soup):
jobs_data = []
if soup is None:
return []
# Find the container elements for each job posting
job_articles = soup.find_all("article", {"data-testid": "JobCard"})
Here, soup.find_all("article", {"data-testid": "JobCard"}) locates each job card on the page. The results will be stored in job_articles, and we will iterate over them to extract the individual attributes.
Extracting the Job Title
A clear job title sets the stage for any role by giving immediate context about the position’s focus. To locate the job titles, we can consistently find an anchor tag with a data-testid="jobTitle" attribute from the job article.
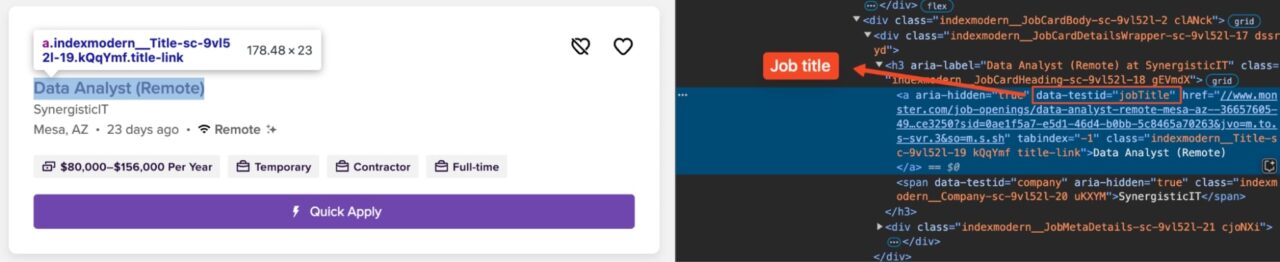
Why this selector? Monster designates its job title links with a data-testid="jobTitle" attribute, making it easier to target reliably than dynamically generated class names. This gives you the Job Title for each posting:
title_tag = article.find("a", {"data-testid": "jobTitle"})
job_title = title_tag.get_text(strip=True) if title_tag else "N/A"
We use BeautifulSoup’s .find method to:
- If this tag exists, extract its text using
get_text(strip=True). - If it does not exist, default to “
N/A“.
Company Name
Similarly, if we search for a span with a data-testid="company" attribute, we find the company names on each listing:
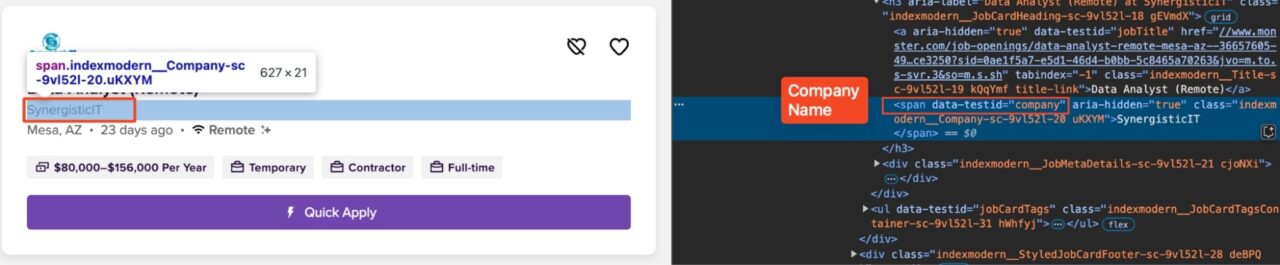
We can extract the company names like so:
company_tag = article.find("span", {"data-testid": "company"})
company_name = company_tag.get_text(strip=True) if company_tag else "N/A"
Job Location
The job location can be just as important as the role itself. Monster lists both exclusively remote positions and location-specific roles. To find the Job Location, look for a span with data-testid="jobDetailLocation":
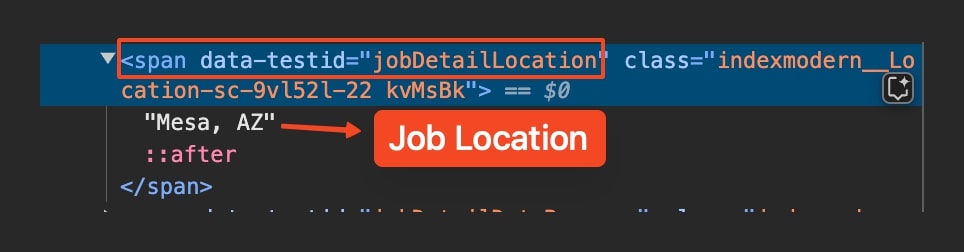
Translating that to code:
location_tag = article.find("span", {"data-testid": "jobDetailLocation"})
job_location = location_tag.get_text(strip=True) if location_tag else "N/A"
Knowing the location (or if the job is remote) can help filter positions by geographic preference.
Date Posted
How recently a position was posted can provide insight into urgency, competitiveness, and the likelihood that it’s still active.

Monster generally displays the date or time range since the job was posted. You can find it under a span with data-testid="jobDetailDateRecency":
date_tag = article.find("span", {"data-testid": "jobDetailDateRecency"})
date_posted = date_tag.get_text(strip=True) if date_tag else "N/A"
Having the Date Posted helps you track new openings or remove outdated listings from your dataset.
Short Job Description
Many job listings show a summary of the role, which helps job seekers quickly gauge if they meet the skill requirements or find the role appealing. So, similarly, we find a paragraph with data-testid="SingleDescription" attribute:
desc_tag = article.find("p", {"data-testid": "SingleDescription"}) job_description = desc_tag.get_text(strip=True) if desc_tag else "N/A"
Storing this Job Description can be helpful if you plan on performing keyword analysis or natural language processing on the roles.
Extracting the Salary
Money talks, making compensation a crucial factor in any job decision. Capturing it can give you an edge when analyzing market trends or building comparison tools.
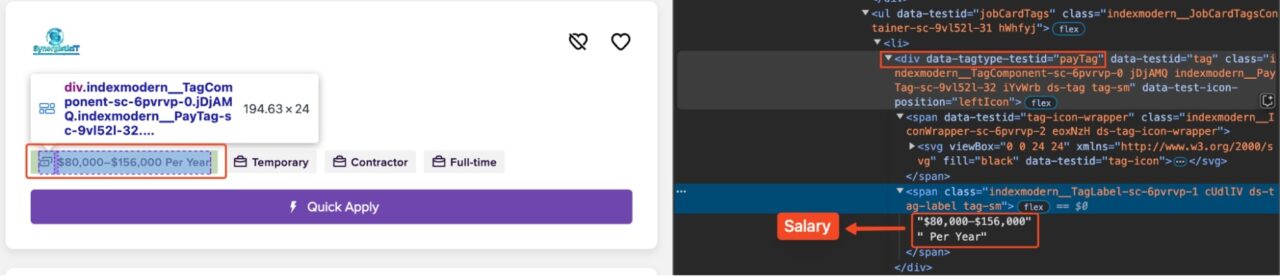
Some listings may include salary information in a div with data-tagtype-testid="payTag":
salary_div = article.find("div", {"data-tagtype-testid": "payTag"})
if salary_div:
salary_text = salary_div.find('span', class_='indexmodern__TagLabel-sc-6pvrvp-1').text
salary = ' '.join(salary_text.split()).replace(' Per Year', '')
else:
salary = "N/A"
Clean the raw text by removing extra spaces or unwanted phrases.
Job Link
To explore the full posting or apply, you need the exact URL of the listing. You can retrieve the hyperlink pointing to the full job listing by looking for the href attribute in the same title anchor:
if title_tag and title_tag.has_attr("href"):
job_link = f"https:{title_tag['href']}"
else:
job_link = "N/A"
Capturing a direct link to the posting allows you to revisit or share the full job description later.
- Monster often uses relative links that start with
//.Prefix them withhttps:for a valid URL. - Default to “
N/A” if a link is missing or inaccessible.
Storing the Job Link allows you to revisit or share the original posting.
Appending the Collected Fields
After extracting each attribute, we create a dictionary for the job posting and add it to our jobs_data list:
jobs_data.append({
"title": job_title,
"company": company_name,
"location": job_location,
"date_posted": date_posted,
"description": job_description,
"salary": salary,
"job_link": job_link
})
Finally, return the jobs_data list at the end of the function. This structure allows easy conversion to JSON/CSV for analysis. Once your loop finishes, return jobs_data so you can use it elsewhere in your script:
return jobs_data
All code for step #7 can be found in the following code block:
def parse_monster_jobs(soup):
if soup is None:
return []
job_articles = soup.find_all("article", {"data-testid": "JobCard"})
jobs_data = []
for article in job_articles:
# Job title
title_tag = article.find("a", {"data-testid": "jobTitle"})
job_title = title_tag.get_text(strip=True) if title_tag else "N/A"
# Company name
company_tag = article.find("span", {"data-testid": "company"})
company_name = company_tag.get_text(strip=True) if company_tag else "N/A"
# Location
location_tag = article.find("span", {"data-testid": "jobDetailLocation"})
job_location = location_tag.get_text(strip=True) if location_tag else "N/A"
# Date posted
date_tag = article.find("span", {"data-testid": "jobDetailDateRecency"})
date_posted = date_tag.get_text(strip=True) if date_tag else "N/A"
# Short job description
desc_tag = article.find("p", {"data-testid": "SingleDescription"})
job_description = desc_tag.get_text(strip=True) if desc_tag else "N/A"
# Conditionally extract salary
salary_div = article.find("div", {"data-tagtype-testid": "payTag"})
if salary_div:
salary_text = salary_div.find('span', class_='indexmodern__TagLabel-sc-6pvrvp-1').text
salary = ' '.join(salary_text.split()).replace(' Per Year', '')
else:
salary = "N/A"
# Job link
if title_tag and title_tag.has_attr("href"):
job_link = f"https:{title_tag['href']}"
else:
job_link = "N/A"
jobs_data.append({
"title": job_title,
"company": company_name,
"location": job_location,
"date_posted": date_posted,
"description": job_description,
"salary": salary,
"job_link": job_link
})
return jobs_data
Always inspect the elements in your browser to confirm that these tags and attributes match what you see in the HTML.
Step 8: Saving the Data to JSON
After extracting the job data, we can store it in JSON format. This makes integrating with databases, analytics pipelines, or custom web applications easier.
def save_jobs_to_json(jobs_data, filename="monster_jobs.json"):
if len(jobs_data) > 1:
with open(filename, "w", encoding="utf-8") as json_file:
json.dump(jobs_data, json_file, indent=4, ensure_ascii=False)
print(f"Saved job posting(s) to '{filename}'")
The indent=4 argument makes your JSON file more readable, and ensure_ascii=False ensures that any special characters or accents are preserved.
Step 9: Putting It All Together
Finally, we combine all steps in the main() function. This is where we initialize the driver, scrape Monster.com, parse job postings, and save the results to a JSON file.
def main():
# 1. Initialize the driver
driver = init_driver(api_key=APIKEY, headless=False)
# 2. Get the BeautifulSoup object for the requested page
soup = fetch_page_source(driver, monster_url, wait_time=20)
# 3. Parse job postings
job_list = parse_monster_jobs(soup)
# 4. Save results to JSON
save_jobs_to_json(job_list)
# 5. Close the browser
driver.quit()
print("Scraping session complete.")
if __name__ == "__main__":
main()
How this works:
- We call
init_driver()with our ScraperAPI key, instructing it to run in non-headless mode (headless=False) so you can observe the browser. - We then fetch the page source for the
monster_url. - The returned HTML is fed
to parse_monster_jobs(),which extracts all relevant job information. - We store that information in a JSON file using
save_jobs_to_json(). - Finally,
driver.quit()closes the browser session and ends the script.
After running the code, you should see a monster_jobs.json file saved in your working directory. Here’s what the job data looks like once you open the file:
[
{
"title": "Data Analyst (Remote)",
"company": "SynergisticIT",
"location": "Mesa, AZ",
"date_posted": "18 days ago",
"description": "We at Synergisticit understand the problem of the mismatch between employer's requirements and Employee skills and that's why since 2010 we have helped 1000's of candidates get jobs at technology clients like apple, google, Paypal, western union, Client, visa, walmart labs etc to name a few. Jobseekers need to self-evaluate if they have the requisite skills to meet client requirements and needs as Clients now post covid can also hire remote workers which increases even more competition for jobseekers.",
"salary": "$80,000-$156,000",
"job_link": "https://www.monster.com/job-openings/data-analyst-remote-mesa-az--36657605-499d-4321-91b2-d2cebdce3250?sid=6553c8f8-238b-4941-a7bd-c125d9f5d5fb&jvo=p.to.s-svr.1&so=p.h.p&hidesmr=1"
},
{
"title": "Business Systems Analyst ( Banking Regulatory Reporting ) - REMOTE",
"company": "System One",
"location": "Phoenix, AZ",
"date_posted": "3 days ago",
"description": "For immediate consideration, please connect with me on LinkedIn at https://www.linkedin.com/in/dpotapenko and then email your resume, work authorization status, current location, availability, and compensation expectations directly to denis.potapenko@systemone.com - make sure to include the exact job title and job location in your email message. For immediate consideration, please connect with me on LinkedIn at https://www.linkedin.com/in/dpotapenko and then email your resume, work authorization status, current location, availability, and compensation expectations directly to denis.potapenko@systemone.com - make sure to include the exact job title and job location in your email message.",
"salary": "N/A",
"job_link": "https://www.monster.com/job-openings/business-systems-analyst-banking-regulatory-reporting-remote-phoenix-az--fa9ad498-6dd4-44de-86ee-1a998e229fba?sid=6553c8f8-238b-4941-a7bd-c125d9f5d5fb&jvo=p.to.s-svr.2&so=p.h.p&hidesmr=1"
},
{
"title": "IT Operations Analyst",
"company": "Cornerstone TTS",
"location": "Phoenix, AZ",
"date_posted": "22 days ago",
"description": "The Operations Analyst will manage data, track assets, perform quality assurance, and provide critical support for operational activities. CornerStone Technology Talent Services (TTS) is seeking an Operations Analyst to join our team, supporting our Command Center operations.",
"salary": "$45,000-$51,000",
"job_link": "https://www.monster.com/job-openings/it-operations-analyst-phoenix-az--ab4c3c5f-dea0-472e-a46f-931f2f3afc5a?sid=6553c8f8-238b-4941-a7bd-c125d9f5d5fb&jvo=p.to.s-svr.3&so=p.h.p&hidesmr=1"
},
]
Note: Results have been truncated due to space constraints.
Full Code
Here’s the complete code if you want to go straight to scraping:
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import undetected_chromedriver as uc
from bs4 import BeautifulSoup
import json
from time import sleep
APIKEY = "YOUR_SCRAPERAPI_KEY"
monster_url = "https://www.monster.com/jobs/search?q=data+analyst&where=Arizona&page=1&rd=50&so=m.s.sh"
def init_driver(api_key, headless=True):
proxy_url = f"https://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001"
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
if headless:
options.add_argument("--headless")
# Selenium Wire proxy configuration
seleniumwire_options = {
'proxy': {
'http': proxy_url,
'https': proxy_url,
},
'verify_ssl': False,
}
# Initialize undetected Chrome driver with proxy settings
driver = uc.Chrome(options=options, seleniumwire_options=seleniumwire_options)
return driver
def fetch_page_source(driver, url, wait_time=10):
print(f"Fetching URL: {url}")
driver.get(url)
print("Waiting for page to load and bypass possible CAPTCHA...")
sleep(wait_time)
try:
# Wait for the container that holds the job postings
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.ID, "JobCardGrid"))
)
except:
print("Could not locate JobCardGrid; potential CAPTCHA or block.")
return None
page_source = driver.page_source
# Give a short extra wait to ensure all elements are fully loaded
sleep(5)
return BeautifulSoup(page_source, 'lxml')
def parse_monster_jobs(soup):
if soup is None:
return []
job_articles = soup.find_all("article", {"data-testid": "JobCard"})
jobs_data = []
for article in job_articles:
# Job title
title_tag = article.find("a", {"data-testid": "jobTitle"})
job_title = title_tag.get_text(strip=True) if title_tag else "N/A"
# Company name
company_tag = article.find("span", {"data-testid": "company"})
company_name = company_tag.get_text(strip=True) if company_tag else "N/A"
# Location
location_tag = article.find("span", {"data-testid": "jobDetailLocation"})
job_location = location_tag.get_text(strip=True) if location_tag else "N/A"
# Date posted
date_tag = article.find("span", {"data-testid": "jobDetailDateRecency"})
date_posted = date_tag.get_text(strip=True) if date_tag else "N/A"
# Short job description
desc_tag = article.find("p", {"data-testid": "SingleDescription"})
job_description = desc_tag.get_text(strip=True) if desc_tag else "N/A"
# Conditionally extract salary
salary_div = article.find("div", {"data-tagtype-testid": "payTag"})
if salary_div:
salary_text = salary_div.find('span', class_='indexmodern__TagLabel-sc-6pvrvp-1').text
salary = ' '.join(salary_text.split()).replace(' Per Year', '')
else:
salary = "N/A"
# Job link
if title_tag and title_tag.has_attr("href"):
# Monster uses relative links starting with //
job_link = f"https:{title_tag['href']}"
else:
job_link = "N/A"
jobs_data.append({
"title": job_title,
"company": company_name,
"location": job_location,
"date_posted": date_posted,
"description": job_description,
"salary": salary,
"job_link": job_link
})
return jobs_data
def save_jobs_to_json(jobs_data, filename="monster_jobs.json"):
if len(jobs_data) > 1:
with open(filename, "w", encoding="utf-8") as json_file:
json.dump(jobs_data, json_file, indent=4, ensure_ascii=False)
print(f"Saved job posting(s) to '{filename}'")
def main():
# 1. Initialize the driver
driver = init_driver(api_key=APIKEY, headless=False)
# 2. Get the BeautifulSoup object for the requested page
soup = fetch_page_source(driver, monster_url, wait_time=20)
# 3. Parse job postings
job_list = parse_monster_jobs(soup)
# 4. Save results to JSON
save_jobs_to_json(job_list)
# 5. Close the browser
driver.quit()
print("Scraping session complete.")
if __name__ == "__main__":
main()
Remember to replace “YOUR_SCRAPERAPI_KEY” with the actual APIKEY on your ScraperAPI dashboard.
Now, you have a fully functional Monster.com job scraper that can bypass DataDome and retrieve live job postings. Feel free to modify the URL parameters for your own job title and location.
Cheers!
What You Can Do with Job Posting Data
Like any other market, the job market is heavily influenced by data. If you are an individual, you can build a job scraper to automate your job hunting or conduct personal research. Organizations, however, stand to gain even more from collecting and analyzing job data. Here are some of the most common ways:
1. Tracking Hiring Trends:
Job scraping provides the data needed to monitor potential shifts in the job market, such as emerging skills or new industries. This information is valuable for market research and forecasting employment needs.
2. Creating Aggregated Job Boards:
Companies and online job boards could use job data scraping to update their sites with the latest job postings from multiple sources. You can create your own job board tailored to specific niches or industries by scraping job postings.
3. Automating Recruitment Processes:
Recruiters can save time by using job scraping to match job postings with candidate profiles, focusing their efforts on engaging with potential candidates rather than manually searching.
4. Competitor Analysis:
Scraping competitor job postings reveals which roles they are hiring for, how much they pay, and where they focus their efforts. This data can help you stay competitive in your own recruitment strategies.
5. Salary and Market Analysis:
Companies can gather salary trends to make informed budgeting decisions, especially when starting a new department or evaluating existing compensation packages. Being aware of industry standards helps prevent undervaluing or overvaluing roles, reducing the risk of missing out on top talent.
Common Challenges in Job Scraping and How to Overcome Them
While job scraping offers numerous benefits, there are also challenges and considerations to take into account:
While job scraping offers numerous benefits, there are also challenges and considerations to take into account:
1. Anti-Bot Measures
Websites like Monster.com often employ advanced protection systems such as DataDome or Cloudflare to detect and block automated scripts. Overcoming these obstacles typically involves using a dedicated scraping service like ScraperAPI, which handles proxy rotation, CAPTCHA solving, and other stealth features.
2. Data Quality and Reliability
Depending on the source, the accuracy and timeliness of job postings can vary. Inaccurate or outdated listings reduce the effectiveness of your scraping efforts. Refresh your data regularly and implement validation checks to ensure you are capturing reliable information.
3. Changing Website Structures
Sites regularly update their layouts, CSS selectors, and anti-scraping mechanisms, which can break your scraper. To mitigate this, monitor your target websites for changes and update your code or workflows accordingly.
4. Data Duplicates
When scraping multiple sites, it is common to encounter duplicate job listings. Implementing deduplication logic or using unique identifiers based on job title, company, and location can help you maintain a clean dataset.
Conclusion
In this guide, you have explored the essentials of job scraping and seen how to build a Python scraper that can retrieve job openings from Monster.com.
Scraping Monster can be tricky as its advanced anti-scraping mechanisms can easily block your script. This is where tools like ScraperAPI step in, automatically handling CAPTCHAs, proxies, automated retries, and more on your behalf.
Register now to start your free trial and see how effortless job scraping can be.
If you’re interested in more job-scraping content, take a look at our other guides:
- How to Build a Google Jobs Scraper with Python and ScraperAPI
- How To Build a Job Scraping Tool for Indeed
- How to Scrape Datadome-Protected Websites with Python
Happy scraping!
FAQ about Job Scraping with ScraperAPI
What is job scraping?
Job scraping is the process of automatically extracting job postings and related details. This includes details such as job titles, descriptions, qualifications, salaries, and company information.
Is scraping job postings legal?
While scraping publicly available job data is generally legal, always ensure compliance with the websites’ terms of service.
To learn more about the legality of web scraping, read our article ‘Is Web Scraping Legal?.’
What tools are best for job scraping?
This largely depends on the website’s structure and security measures. For more straightforward sites, libraries like Requests and BeautifulSoup are often enough. However, for complex or heavily protected sites, Selenium or dedicated services such as ScraperAPI are recommended to handle CAPTCHAs, proxies, and dynamic content.
What is the best job scraping API?
Several APIs specialize in web scraping, each with different features and pricing. However, ScraperAPI stands out due to its ease of use and built-in solutions for rotating proxies, CAPTCHA-solving, and regional targeting.