

Real estate professionals, investors, and researchers need vast amounts of structured property data to make informed decisions, but manually collecting this information would be painfully slow and inefficient.
In this tutorial, we will walk through how to automate Redfin data extraction using Python and ScraperAPI’s Structured Data Endpoints (SDEs). You’ll learn to programmatically collect:
- Property listings (both for sale and rent)
- Detailed home information (price history, features, taxes)
- Agent profiles (performance metrics, specialties, contact details)
By the end of this article, you’ll be able to build your own dataset for market analysis, investment research, or competitive benchmarking, avoiding manual data entry.
Let’s dive in.
TL;DR: Scrape Redfin Data without Interruptions
Redfin property data is quite valuable, and so, it uses advanced anti-scraping mechanisms to block scrapers from accessing the website:
- Complex CAPTCHA and JavaScript challenges
- Behavior analysis and browser fingerprinting
- Rate limiting and IP block
ScraperAPI automatically bypasses all of these challenges without any extra setup from your end, letting you collect Redfin data in clean JSON or CSV format.See it for yourself; create a free ScraperAPI account and add your api_key before running the code below:
import requests
import json
payload = {
'api_key': 'YOUR_API_KEY',
'url': 'https://www.redfin.com/MD/Baltimore/Domain-Brewers-Hill/apartment/45425151',
'country': 'us'
}
response = requests.get('https://api.scraperapi.com/structured/redfin/forrent', params=payload)
data = response.json()
with open('redfin-rent-page.json', 'w') as f:
json.dump(data, f)
Want to test our API at scale? Contact our sales team to get a custom trial, which includes:
- Personalized onboarding
- Custom scraping credits and concurrent thread limits
- Dedicated support Slack channel
And a dedicated account manager to ensure successful integration with your infrastructure.
Why Scrape Redfin.com?
Redfin provides comprehensive property data that’s valuable for:
- Real estate market analysis and trend identification
- Investment opportunity evaluation
- Comparative market analysis for pricing strategies
- Neighborhood and school district research
- Rental yield calculations
- Historical sales and price change tracking
Redfin Data Fields to Scrape
- Basic property details (address, price, beds, baths, square footage)
- Property features and amenities
- Historical price changes and days on market
- Neighborhood information and school ratings
- Agent and brokerage details
- Property tax history
- Sale and rental history
- Comparable properties in the area
Project Requirements
Before diving into the integration, ensure you have the following:
- A ScraperAPI Account: Sign up on the ScraperAPI website to get your API key. ScraperAPI simplifies the extraction process by taking care of JavaScript rendering, CAPTCHA solving, and proxy rotation. Joining a seven-day trial will grant you 5,000 free API credits, which you can use whenever you’re ready.
- A Python Environment: Make sure you have Python (version 3.7+ recommended) installed on your system. You’ll also need the following libraries:
requests: For making HTTP requests to ScraperAPI.python-dotenv: to load your credentials from your .env file and manage your API key securely.
matplotlib: to visualize your data.
You can install them with this pip command:
pip install requests python-dotenv matplotlib
- An IDE or Code Editor: For creating and executing your Python scripts, like Visual Studio Code, PyCharm, or Jupyter Notebook.
How to Scrape Redfin Property Pages with ScraperAPI
While search results provide basic information, individual property pages contain much more detailed data. Redfin offers two different types of property pages, one for properties for sale and another for rental properties. These pages have different structures and layouts, so ScraperAPI provides separate endpoints for each type.
Sale vs. Rental Property Pages
Sale property pages have the following information:
- Payment Calculator
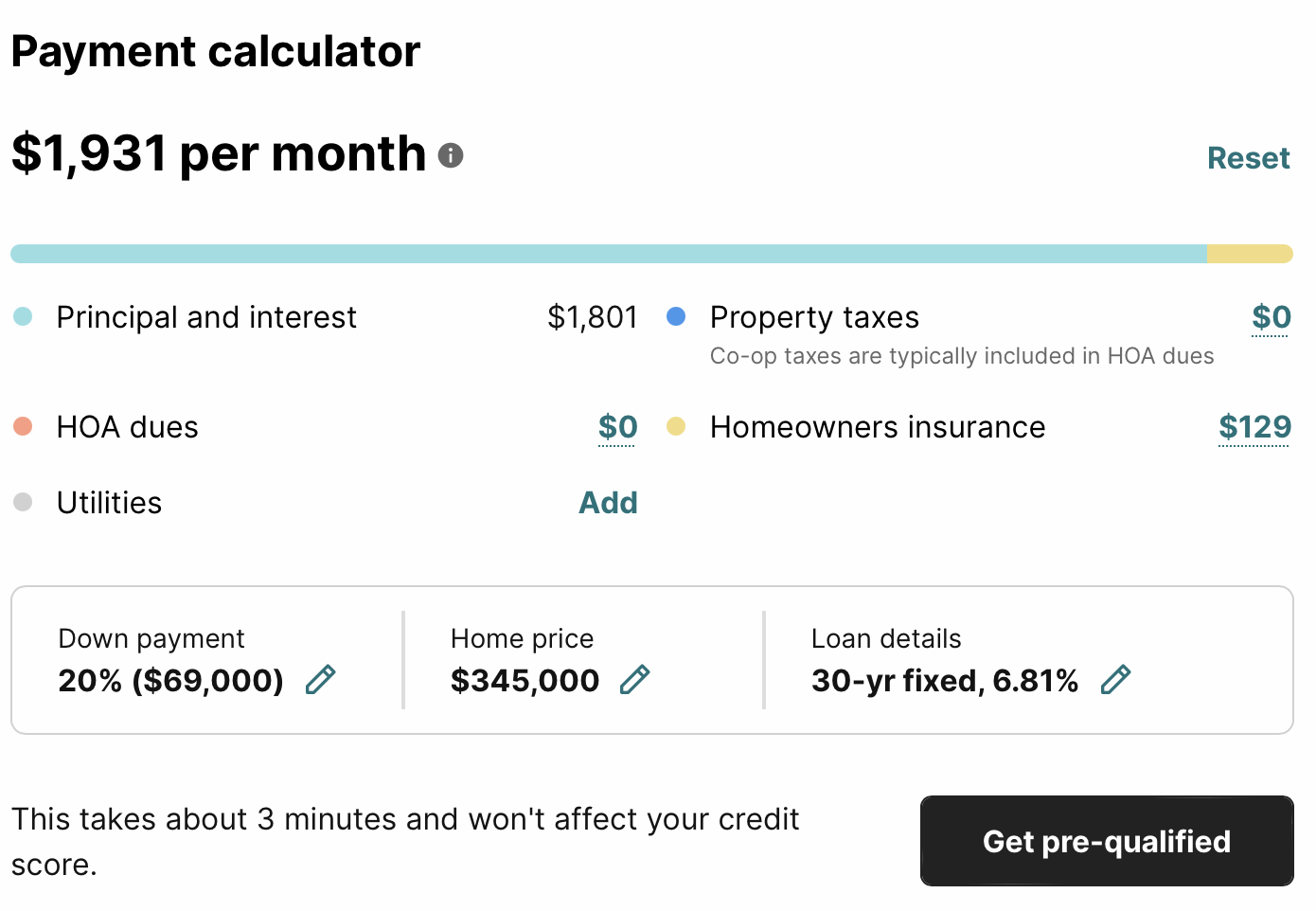
- Property features
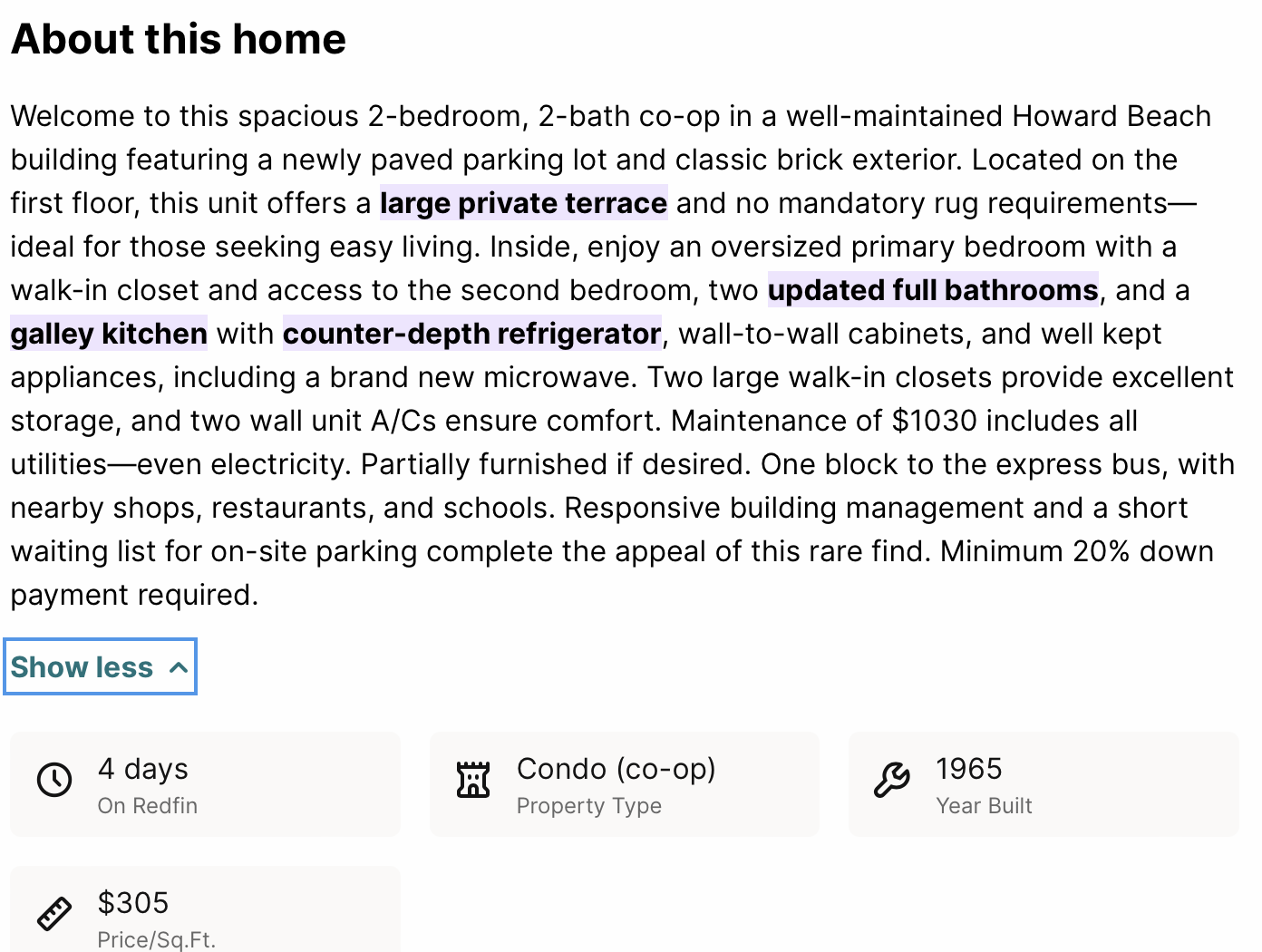
- Agent Details

Rental property pages have the following information:
- Monthly rent

- Pet policies

- Amenities

Let’s look at how to scrape both types of pages.
Setting up the environment
First of all, create a .env file in the root directory of your project. Here, you will store your credentials (in this case, your API key), ensuring that they are not made public by mistake. Make sure to add this file to your .gitignore file to avoid pushing sensitive data to version control.
You can create the .env file by running:
touch .env
In it, define your API key:
SCRAPERAPI_KEY= "YOUR_API_KEY" # Replace with your actual ScraperAPI key
Now we can import them into our Python file:
# Load environment variables from .env file
load_dotenv()
SCRAPERAPI_KEY = os.getenv('SCRAPERAPI_KEY')
We will use this setup across all of our examples.
Scraping Redfin sale property details
To scrape property-for-sale information from Redfin, we are going to use the ScraperAPI Redfin Sales SDE. This lets us pull structured data from Redfin without dealing with JavaScript rendering, anti-bot blocks, or endless HTML parsing.
Instead of scraping raw pages, you’ll get back ready-to-use sale property details, pricing, address, beds, baths, square footage, and more in JSON.
It’s faster, more reliable, and it works really well for building real estate tools, dashboards, or market analysis scripts.
import requests
import json
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
SCRAPERAPI_KEY = os.getenv('SCRAPERAPI_KEY')
SCRAPERAPI_SALE_ENDPOINT = "https://api.scraperapi.com/structured/redfin/forsale"
TARGET_URL = "https://www.redfin.com/NY/Howard-Beach/15140-88th-St-11414/unit-1G/home/57020499"
def fetch_sale_properties():
"""Fetch property data using ScraperAPI SDE."""
try:
response = requests.get(SCRAPERAPI_SALE_ENDPOINT, params={
'api_key': SCRAPERAPI_KEY,
'url': TARGET_URL,
'country_code': 'US'
})
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Failed to fetch properties: {e}")
return None
def scrape_sale_properties():
"""Scrape specific property fields and save them to a JSON file."""
print(f"Fetching properties from {TARGET_URL} using ScraperAPI SDE...")
data = fetch_sale_properties()
if not data:
print("No property data found.")
return
filtered_data = {
"type": data.get("type", "N/A"),
"price": data.get("price", "N/A"),
"sq_ft": data.get("sq_ft", "N/A"),
"beds": data.get("beds", "N/A"),
"baths": data.get("baths", "N/A"),
"description": data.get("description", "N/A"),
"address": data.get("address", "N/A"),
"active": data.get("active", "N/A"),
"agent": data.get("agents", [{}])[0].get("name", "N/A")
}
with open("filtered_redfin_sales_page.json", "w", encoding="utf-8") as f:
json.dump(filtered_data, f, indent=4)
print("Scraping completed. Filtered data saved to filtered_redfin_sales_page.json.")
if __name__ == "__main__":
scrape_sale_properties()
The code uses ScraperAPI’s structured data endpoint to collect key details from a Redfin property listing. It filters the response to include only useful data points such as:
- Property type
- Price
- Square footage
- Number of bedrooms and bathrooms
- A short description
- Full address
- Listing status (active or not)
- The agent’s name
The `fetch_properties()` function handles the request to ScraperAPI and retrieves the JSON response. The `scrape_properties()` function then extracts just the needed fields and saves them to a file named `filtered_redfin_sales_page.json`.
Your data should look like this: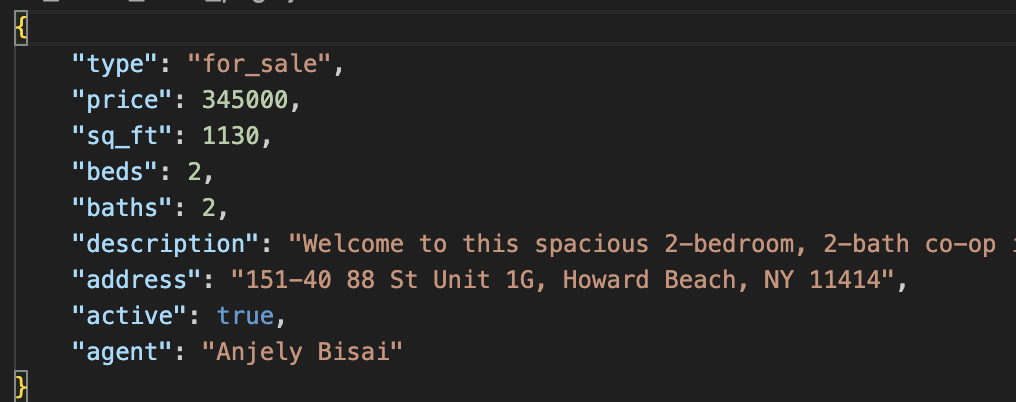
Scrape Redfin for Rent Properties
Just like we did for Redfin property-for-sale, you can easily extract property-for-rent details using the ScraperAPI-Redfin-Rent SDE. With this simple API call, you have access to all property information, such as price, pet policies, schools in the area, etc.
Using ScraperAPI SDE makes your task simple and faster, and gives you accurate and reliable data:
import requests
import json
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
SCRAPERAPI_KEY = os.getenv('SCRAPERAPI_KEY')
SCRAPERAPI_RENT_ENDPOINT = "https://api.scraperapi.com/structured/redfin/forrent"
TARGET_URL = "https://www.redfin.com/NY/Astoria/2718-Ditmars-Blvd-11105/home/20946748"
def fetch_rent_property():
"""Fetch property data using ScraperAPI."""
try:
response = requests.get(SCRAPERAPI_RENT_ENDPOINT, params={
'api_key': SCRAPERAPI_KEY,
'url': TARGET_URL,
'country_code': 'US'
})
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
return None
def scrape_rent_property():
"""Extract and save specific property fields."""
data = fetch_rent_property()
if not data:
print("No data returned.")
return
filtered_data = {
"name": data.get('name', 'N/A'),
"type": data.get('type', 'N/A'),
"map_url": data.get('map_url', 'N/A'),
"bed_max": data.get('bed_max', 'N/A'),
"bath_max": data.get('bath_max', 'N/A'),
"price_max": data.get('price_max', 'N/A'),
"description": data.get('description', 'N/A'),
"address": f"{data.get('address', {}).get('street_line', '')}, "
f"{data.get('address', {}).get('city', '')}, "
f"{data.get('address', {}).get('state', '')} {data.get('address', {}).get('zip', '')}"
}
with open("Filtered_redfin_rent_page.json", "w", encoding="utf-8") as f:
json.dump(filtered_data, f, indent=4)
print("Filtered data saved to Filtered_redfin_rent_page.json.")
if __name__ == "__main__":
scrape_rent_property()
The code above uses ScraperAPI’s Redfin rental SDE to extract property details from a specific Redfin rental listing. It sends a `GET` request with the API key, Redfin listing URL, and country code. With the help of ScraperAPI’s SDE, it returns structured JSON data. No need for extra parsing libraries like BeautifulSoup.
The `fetch_properties()` function handles the API request and returns the response if successful. The `scrape_properties()` function then filters key data points such as the property’s name, type, number of beds and baths, price, map URL, description, and full address. Finally, it saves the cleaned data to a file named `Filtered_redfin_rent_page.json`.
Your data should look like this:

How to Scrape Redfin.com Search Results
If your goal is to retrieve all listings from a Redfin search, ScraperAPI can simplify the process with its Redfin Search SDE:
import requests
import json
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
SCRAPERAPI_KEY = os.getenv('SCRAPERAPI_KEY')
payload = {'api_key': SCRAPERAPI_KEY,
'url': 'https://www.redfin.com/city/30749/NY/New-York/apartments-for-rent', 'country_code': 'US'}
r = requests.get('https://api.scraperapi.com/structured/redfin/search', params=payload)
data = r.json()
with open('redfin-search-rent-page.json', 'w') as f:
json.dump (data,
f)
The code uses ScraperAPI’s SDE to search and scrape all rental listings from a Redfin search page.
- It sends a
`GET`request to the ScraperAPI Redfin search endpoint, which is designed to return structured property listings. - The payload includes an API key, the target Redfin URL for apartments for rent in New York City, and an optional
country_codeparameter set to'US'. - The response (
`r`) is parsed as JSON and saved to a local file named'redfin-search-rent-page.json'using the`json.dump()`method.
These listings can be seen below.
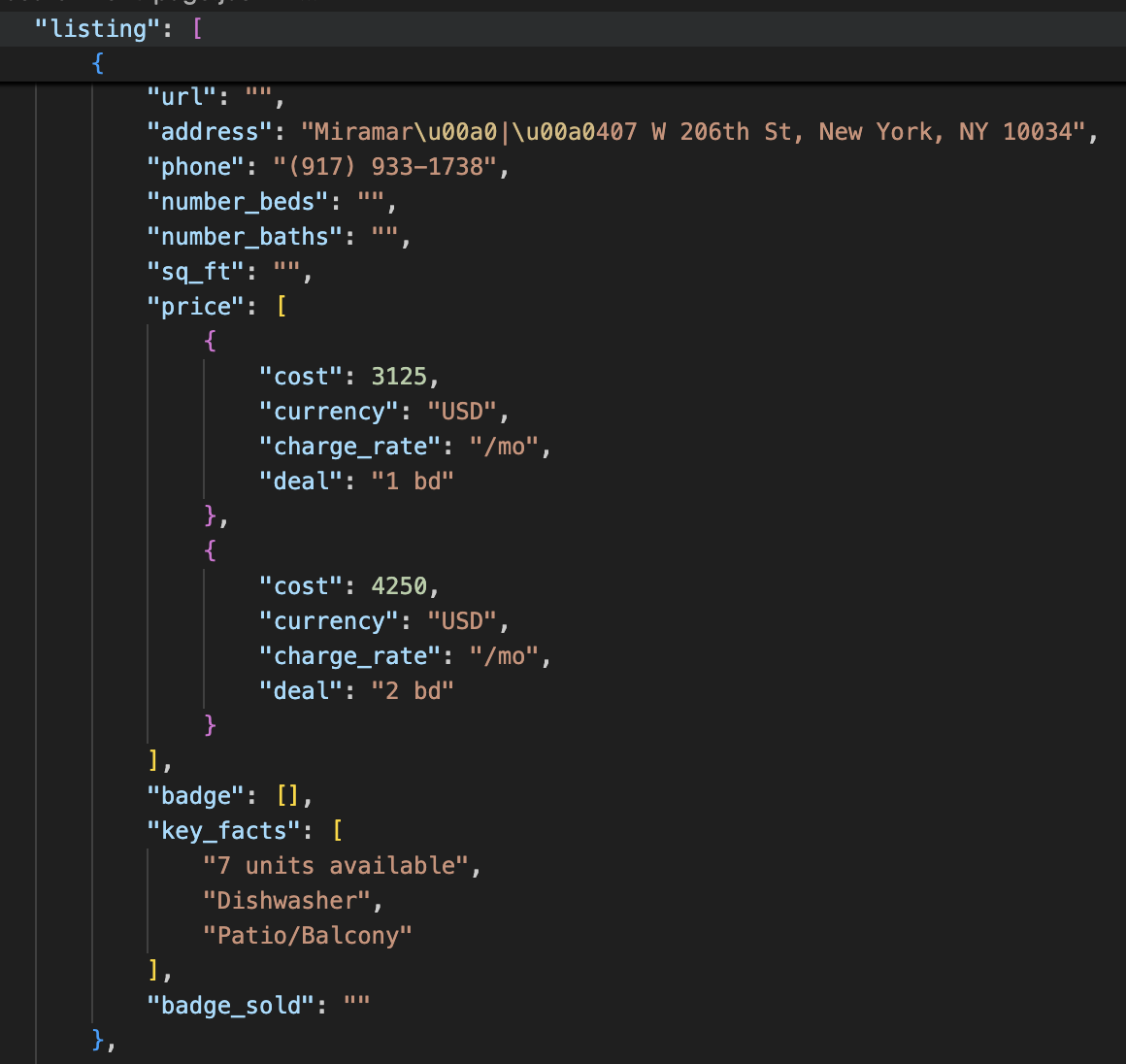
Note: As of the time this article was written, the search SDE is currently not able to extract URLs of each individual listing, but this is soon coming.
Collect Agent Profiles from Redfin
While property for sale or rent information is necessary when it comes to real estate, agent information is very important to analyze performance.
To effortlessly get Redfin agent information, ScraperAPI has provided a Redfin Agent SDE.
In this section, I’ll show you how to extract agent information from Redfin using Python and ScraperAPI’s specialized Agent Details API.
import requests
import json
import time
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
SCRAPERAPI_KEY = os.getenv('SCRAPERAPI_KEY')
SCRAPERAPI_AGENT_ENDPOINT = "https://api.scraperapi.com/structured/redfin/agent"
TARGET_URL = "https://www.redfin.com/real-estate-agents/ian-rubinstein"
REQUEST_DELAY = 2
def fetch_agents_data():
"""Fetch agent data using ScraperAPI SDE and save specific fields."""
print(f"Fetching agent data from {TARGET_URL} using ScraperAPI SDE...")
payload = {
'api_key': SCRAPERAPI_KEY,
'url': TARGET_URL
}
try:
response = requests.get(SCRAPERAPI_AGENT_ENDPOINT, params=payload)
response.raise_for_status()
data = response.json()
filtered_data = {
"name": data.get("name", ""),
"type": data.get("type", ""),
"license_number": data.get("license_number", ""),
"contact": data.get("contact", ""),
"about": data.get("about", ""),
"agent_areas": data.get("agent_areas", [])
}
with open('filtered_redfin_agent.json', 'w') as f:
json.dump(filtered_data, f, indent=4)
print("Filtered agent data saved to 'filtered_redfin_agent.json'")
return filtered_data
except requests.exceptions.RequestException as e:
print(f"Failed to fetch agent data: {e}")
return None
finally:
time.sleep(REQUEST_DELAY)
if __name__ == "__main__":
agent_data = fetch_agents_data()
if agent_data:
print("Agent data fetched and filtered successfully.")
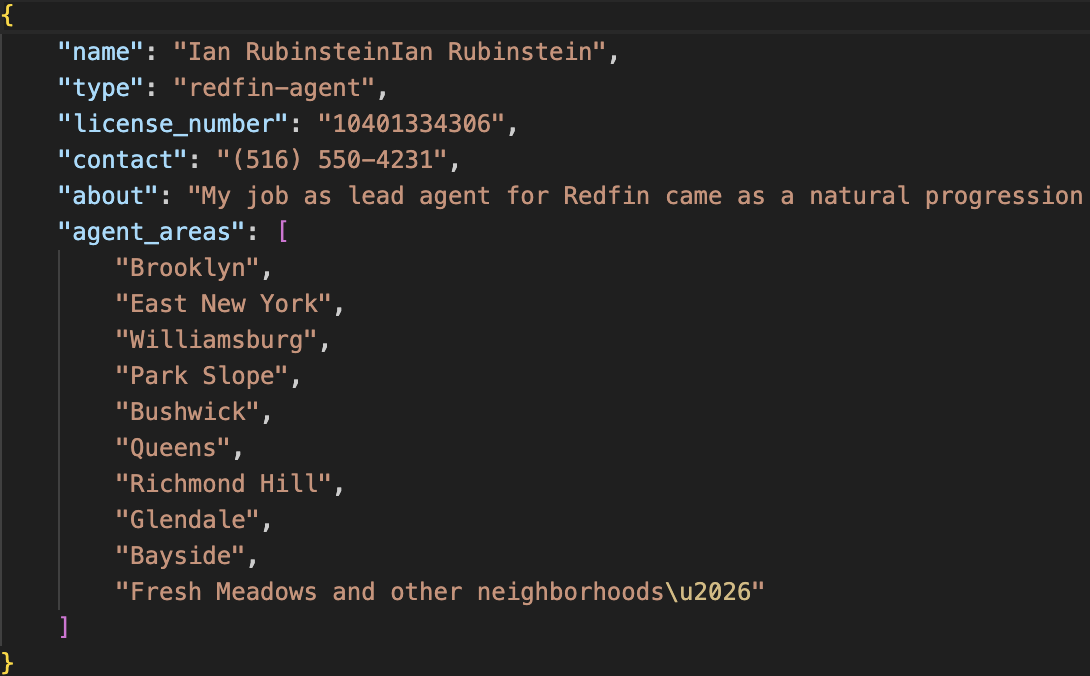
Here’s a breakdown of the script:
- It sends a
`Get`request with the API key and target URL, then processes the JSON response. - Next, it extracts key data points such as the agent’s name, type, license number, contact info, biography, and areas they serve, filtering out unnecessary details.
- It then saves this filtered data to a JSON file named
`filtered_redfin_agent.json`for easy access.
The `fetch_agents_data()` function handles the data fetching, filtering, and saving, with error handling for request failures. A delay ensures the script respects rate limits. When run, the script prints status updates to keep you informed.
Your data should look like this:
Wrapping Up: Analyzing Redfin Property Data
Now that you have collected data from search results, property pages, and agent profiles, you can combine them all together for analysis or analyse each data individually.
Here’s a simple example that visualizes property prices by neighborhood:
import requests
import matplotlib.pyplot as plt
import os
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
SCRAPERAPI_KEY = os.getenv('SCRAPERAPI_KEY')
# Step 1: Fetch the data
payload = {
'api_key': SCRAPERAPI_KEY,
'url': 'https://www.redfin.com/city/30749/NY/New-York/apartments-for-rent',
'country_code': 'US'
}
endpoint = 'https://api.scraperapi.com/structured/redfin/search'
response = requests.get(endpoint, params=payload)
data = response.json()
# Step 2: Extract the first 10 listings
listings = data.get("listing", [])[:10]
# Step 3: Process prices and locations
locations = []
prices = []
for listing in listings:
full_address = listing.get("address", "")
if "|" in full_address:
name, address = [part.strip() for part in full_address.split("|", 1)]
else:
name = full_address.strip()
price_list = listing.get("price", [])
for price_info in price_list:
cost = price_info.get("cost")
if cost:
try:
cost = float(cost)
locations.append(name)
prices.append(cost)
except ValueError:
continue # skip invalid price formats
# Step 4: Visualize - Price vs. Location
plt.figure(figsize=(12, 6))
plt.bar(locations, prices, color='teal')
plt.xlabel('Location (Building Name)', fontsize=12)
plt.ylabel('Monthly Rent ($)', fontsize=12)
plt.title('Rental Prices by Location (Top 10 Listings)', fontsize=14)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.grid(axis='y', linestyle='--', alpha=0.5)
plt.show()
- The code above fetches apartment listings for New York City from Redfin using the ScraperAPI structured endpoint.
- It sends a request with your ScraperAPI key, the Redfin page for NYC rentals, and the country code.
- The response comes in JSON format, and the code focuses on the first 10 listings.
- It extracts the building name from each address and gathers the corresponding prices, ignoring any missing or invalid data.
- Finally, it creates a bar chart using matplotlib, showing rental prices by building for the top 10 listings in New York City.
Here is the final result:
ScraperAPI’s SDEs take away much of the heavy lifting usually involved in web scraping. Instead of wrestling with raw HTML, messy selectors, or fragile parsing rules, SDEs delivers ready-to-use structured JSON data.
If you followed every step, here’s what you should have accomplished with it:
- Extracted structured property listings from both sales and rental pages
- Collected agent details for a deeper view of the market landscape
- Analyzed the data for market trends, price patterns, and investment insights
By automating the entire data pipeline, you transformed what would normally be hours of manual data gathering into a fast, programmatic process. And thanks to the structured format, the scraped data was immediately ready for deeper analysis, visualizations, or integration into other tools.
If you’re serious about real estate research, investment analysis, or building market dashboards, ScraperAPI can save you massive amounts of time and effort. It lets you focus on insights and strategy, not on debugging scrapers or dodging anti-bot systems.
Get started with ScraperAPI today to supercharge your data collection and make your real estate projects smarter, faster, and more scalable.