


Looking for a guide to automate your web scraping? You’ve come to the right place.
Scraping web data manually can be tedious and time-consuming, especially when working with dynamic sites. What if you could automate these tasks and build large datasets effortlessly? With Python and the DataPipeline, you can simplify the entire process, saving time and increasing efficiency.
In this article, you’ll learn how to:
- Automate web scraping tasks using Python and DataPipeline endpoints.
- Collect product information from Amazon automatically.
- Submit a dynamic list of products to streamline your scraping workflow.
- Use the Datapipeline visual interface to manage and monitor your scraping projects without coding.
- Use Webhooks to receive and process data seamlessly.
Let’s get started!
Automate Web Scraping with Python and DataPipeline Endpoints
ScraperAPI’s DataPipeline Endpoints make automating web scraping through API requests easy—no manual setup is required. With just a few calls, you can create and manage scraping projects, schedule recurring jobs, and retrieve structured data effortlessly.
With DataPipeline Endpoints, you can:
- Create and manage scraping projects programmatically
- Schedule jobs to run automatically at set intervals
- Customize scraping settings like notifications and output formats
- Retrieve results quickly from the ScraperAPI dashboard or via webhooks
In this example, we’ll use DataPipeline Endpoints to create an automated web scraping workflow with Python. You’ll learn how to set up a scraping project, submit product data, enable scheduling, and retrieve structured Amazon product data results.
Step 1: Setting Up Your Environment
Before making requests to the DataPipeline endpoint, let’s ensure everything is ready to go. If you haven’t already, sign up for a ScraperAPI account and grab your API key from the dashboard. You’ll also need the requests library, which you can install with:
pip install requests
Once that’s done, set up your API key and define the necessary settings for making API requests:
import requests
import json
API_KEY = "YOUR_API_KEY" # Your personal API key from ScraperAPI
BASE_URL = "https://datapipeline.scraperapi.com/api" # The base URL for all DataPipeline requests
HEADERS = {"Content-Type": "application/json"} # Ensures we send JSON data in our requests
Here’s what’s happening in this setup:
requestsandjsonimports – These libraries allow us to send API requests and handle JSON responses.API_KEY– This is your unique key that authorizes you to use ScraperAPI’s services.BASE_URL– This is the DataPipeline API endpoint, where we will send all requests related to project creation, job management, and data retrieval. We will build every request we make using this URL.HEADERS– This tells the API that we’re sending data in JSON format, which is required for all requests.
With this setup, we’re ready to create a DataPipeline project and start automating web scraping!
Step 2: Creating a Web Scraping Project
Now that our environment is set up, the next step is to create a DataPipeline project. A project defines what data will be scraped, how often the scraper will run, and how the results will be stored.
To do this, we’ll send a request to the DataPipeline project creation endpoint, providing details about the project.
Defining the Project Name and Type
Every project needs a name for identification and a structured data endpoint (projectType), which tells ScraperAPI what kind of data we’re scraping. We’ll set the projectType to "amazon_product" to use the Amazon Product details SDE.
project_data = {
"name": "Amazon Product Scraper", # A descriptive name for the project
"projectType": "amazon_product" # Uses the structured data endpoint for Amazon products
}
ScraperAPI provides different structured data endpoints depending on what you’re scraping. For example, you’d use "google_search" instead if you were scraping Google search results. This ensures that the API returns clean, structured data rather than raw HTML.
Check out the documentation for more details on structured data endpoints.
Adding Input Data (What to Scrape)
Since we’re scraping Amazon product details, we must provide a list of ASINs (Amazon Standard Identification Numbers). These will tell the scraper which products to extract data from.
project_data["projectInput"] = {
"type": "list", # Input type is a list of identifiers
"list": ["B0CHJ5LJZG", "B08N5WRWNW", "B0B3F2X1S2"] # ASINs of the products to scrape
}
Instead of a static list, you can also provide input dynamically using a webhook input, which allows the scraper to pull ASINs from an external URL. This is useful for projects where the input changes frequently.
Here’s how you could do that:
project_data["projectInput"] = {"type": "webhook_input", "url": "<https://the.url.where.your.list.is>" }
Enabling Automated Scheduling
To keep the scraper running automatically, we enable scheduling and define how often it should run.
project_data["schedulingEnabled"] = True # Enable automatic rescheduling
project_data["scrapingInterval"] = "daily" # Options: hourly, daily, weekly, monthly
project_data["scheduledAt"] = "now" # Start immediately and repeat at the specified interval
If you need the scraper to run more or less frequently, you can adjust scrapingInterval. For example, setting it to "hourly" will make it run every hour, while "weekly" will schedule it to run once per week. If you need more control over timing, you can also use cron expressions for precise scheduling.
Setting Up Notifications
To track the scraper’s status, we can configure email notifications to alert us when a job succeeds or fails.
project_data["notificationConfig"] = {
"notifyOnSuccess": "daily", # Receive a success notification once a day
"notifyOnFailure": "with_every_run" # Get notified immediately if a job fails
}
If you prefer fewer notifications, you can set "notifyOnSuccess" to "weekly" or "never".
Changing the Output Format
By default, the scraped data is returned in JSON format, but if you prefer to download it as a CSV file, you can specify this in the apiParams field:
project_data["apiParams"] = {
"outputFormat": "csv" # Set output format to CSV instead of JSON
}
This is useful if you plan to work with the data in spreadsheet software or need it in a tabular format.
Optional: Sending Scraped Data to a Webhook
The scraped data is stored in the ScraperAPI dashboard, where you can manually download it. However, you can set up a webhook output if you want the results sent directly to your system. This allows the scraper to send the structured data to a specified URL once the job is complete.
project_data["webhookOutput"] = {
"url": "https://your-webhook-url.com", # Your endpoint for receiving data
"webhookEncoding": "application/json" # Ensures the data is sent in JSON format
}
This is useful to automatically process or store the data in a database, trigger an event in your system, or integrate it with other applications.
Now that we’ve defined all the project settings, we’ll send a request to the DataPipeline project creation endpoint to create the project.
import requests
import json
API_KEY = "YOUR_API_KEY"
BASE_URL = "https://datapipeline.scraperapi.com/api"
HEADERS = {"Content-Type": "application/json"}
project_url = f"{BASE_URL}/projects?api_key={API_KEY}"
response = requests.post(project_url, headers=HEADERS, data=json.dumps(project_data))
project_response = response.json()
if response.status_code == 201:
PROJECT_ID = project_response["id"]
print(f"Project created successfully with ID: {PROJECT_ID}")
else:
print(f"Error: {project_response}")
After running the script, the API will return a JSON response confirming that the project has been created successfully. It will look something like this:
{
"id": 196293,
"name": "Amazon Product Scraper",
"schedulingEnabled": true,
"scrapingInterval": "daily",
"createdAt": "2025-01-30T01:06:53.296Z",
"scheduledAt": "2025-01-30T01:06:53.296Z",
"projectType": "amazon_product",
"projectInput": {
"type": "list",
"list": ["B0CHJ5LJZG", "B08N5WRWNW", "B0B3F2X1S2"]
},
"notificationConfig": {
"notifyOnSuccess": "daily",
"notifyOnFailure": "with_every_run"
}
}
Here’s what this response means:
id– The unique identifier for the project. ThisPROJECT_IDis essential because we’ll use it to manage and monitor the project later.name– The name we assigned to the project when creating it.schedulingEnabled– Confirms that automatic scheduling is turned on.scrapingInterval– Shows how often the scraper will run (dailyin this case).createdAtandscheduledAt– The timestamps for when the project was created and scheduled to start running.projectType– Confirms that we are using the"amazon_product"structured data endpoint.projectInput– Lists the ASINs that will be scraped.notificationConfig– Displays our notification settings so we know when a job succeeds or fails.
If you added a webhook output, the scraped data will automatically be sent to the specified URL once the job completes. Otherwise, you can download the results from your ScraperAPI dashboard.
The scraper is now fully set up and scheduled to run automatically!
Step 3: Managing and Monitoring Your Scraping Project
Now that we’ve created a DataPipeline project, the next step is to manage and monitor it. Since DataPipeline Endpoints handle scheduling automatically, there’s no need to trigger scraping jobs manually. Instead, we can use the API to retrieve project status, monitor job activity, and make adjustments when necessary.
Retrieving Project Details
To check the current status of a project, we can send a GET request to the DataPipeline project details endpoint. This provides valuable information, including the project type, scheduling settings, and input data.
import requests
import json
project_details_url = f"{BASE_URL}/projects/{PROJECT_ID}?api_key={API_KEY}"
response = requests.get(project_details_url, headers=HEADERS)
if response.status_code == 200:
print("Project details:", json.dumps(response.json(), indent=4))
else:
print(f"Error: {response.json()}")
A successful response will return a JSON object containing the project’s configuration. Here’s an example output:
{
"id": 196293,
"name": "Amazon Product Scraper",
"schedulingEnabled": true,
"scrapingInterval": "daily",
"createdAt": "2025-01-30T01:06:53.296Z",
"scheduledAt": "2025-01-30T01:06:53.296Z",
"projectType": "amazon_product",
"projectInput": {
"type": "list",
"list": ["B0CHJ5LJZG", "B08N5WRWNW", "B0B3F2X1S2"]
},
"notificationConfig": {
"notifyOnSuccess": "daily",
"notifyOnFailure": "with_every_run"
},
"apiParams": {
"outputFormat": "csv"
}
}
This response confirms that the project runs daily, using the Amazon Structured Data Endpoint, and results are stored in CSV format.
Viewing Active Jobs in a Project
Each time the DataPipeline runs a scheduled job, it processes the input data and collects the requested information. We can retrieve a list of jobs associated with a project to monitor ongoing and completed jobs by sending a request to the job details endpoint.
jobs_url = f"{BASE_URL}/projects/{PROJECT_ID}/jobs?api_key={API_KEY}"
response = requests.get(jobs_url, headers=HEADERS)
if response.status_code == 200:
jobs = response.json()
print("Active and completed jobs:", json.dumps(jobs, indent=4))
else:
print(f"Error: {response.json()}")
This request returns a list of all jobs linked to the project, including job IDs, status, and timestamps.
Rescheduling the Project’s Next Run Date
If you need to change when the project runs next, you can update its scheduled time by sending a PATCH request. This allows you to delay or reschedule the next execution without modifying the entire project configuration.
reschedule_url = f"{BASE_URL}/projects/{PROJECT_ID}?api_key={API_KEY}"
payload = {
"scheduledAt": "2025-02-01T12:00:00Z" # Set the next run time in ISO 8601 format
}
response = requests.patch(reschedule_url, headers=HEADERS, data=json.dumps(payload))
if response.status_code == 200:
print("Project rescheduled successfully.")
else:
print(f"Error: {response.json()}")
Canceling a Running Job
If a job is no longer needed or was started by mistake, we can cancel it using the job ID by sending a DELETE request. This is useful if the input data changes or we need to pause scraping.
JOB_ID = "your_job_id_here"
cancel_job_url = f"{BASE_URL}/projects/{PROJECT_ID}/jobs/{JOB_ID}"
response = requests.delete(cancel_job_url, headers=HEADERS, params={"api_key": API_KEY})
if response.status_code == 200:
print("Job canceled successfully.")
else:
print(f"Error: {response.json()}")
Once a job is canceled, it will stop processing, and no results will be collected for that run.
Step 4: Accessing Scraped Data
Once your scraping job is completed, the extracted data is stored and ready for retrieval. DataPipeline Endpoints provide two ways to access your results:
- Downloading Results from the Dashboard
All scraped data is stored in your ScraperAPI dashboard, where you can download it in JSON or CSV format.
To access your data:
- Log in to your ScraperAPI dashboard.
- Go to the DataPipeline section.
- Select your project.
- Download the results in your preferred format.
This method works well if you want to review or process the data manually.
- Receiving Data Automatically via Webhook
If your scraper is set up with the following webhook configuration:
project_data["webhookOutput"] = {
"url": "https://your-webhook-url.com",
"webhookEncoding": "application/json"
}
The scraped data will be sent directly to "https://your-webhook-url.com" in JSON format.
With DataPipeline Endpoints, your web scraping project runs automatically, collects structured data, and stores it for easy retrieval. You can modify project settings, adjust the scraping schedule, or integrate results into your system using webhooks. The entire process is designed to scale, allowing you to focus on analyzing data rather than managing scrapers.
Automate Web Scraping in a Couple of Clicks [No-Code Approach]
If you want to automate web scraping without writing custom scripts, the Visual Interface for DataPipeline makes it easy. Unlike DataPipeline Endpoints, which offer complete API control for deep integration, the Visual Interface provides a low-code solution that lets you build and manage scrapers visually—without dealing with proxies, CAPTCHAs, or session management.
With the Visual Interface, you can run large-scale web scraping operations without worrying about infrastructure, reducing the need for dedicated engineering resources and lowering costs. Whether configuring scrapers manually or setting up automated workflows, everything is designed for efficiency and scalability.

To get started, simply create a free ScraperAPI account. This gives you access to DataPipeline and 5,000 API credits to start scraping. Plus, if you need any assistance, ScraperAPI’s support team is always happy to help.
Setting Up Our First DataPipeline Project
To show you how DataPipeline works, I’ll walk you through automating an Amazon product data scraping project from scratch.
For this project, I’ll use the Amazon Products scraper, which relies on ASIN numbers (Amazon Standard Identification Numbers) to identify products. No worries; DataPipeline handles proxy requests, retries, and other technical challenges behind the scenes using ScraperAPI’s infrastructure.
Let’s get started!
Step 1: Create a New Amazon Project
First, I’ll log in to my ScraperAPI account and navigate to the dashboard. Then I’ll click the “Create a new DataPipeline project” option.
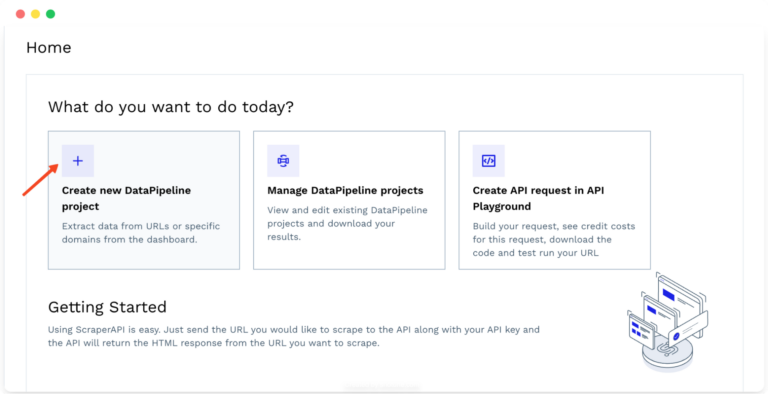
This opens a new window where you can name your project and choose a template. Select the “Amazon Product Pages” template to get started.
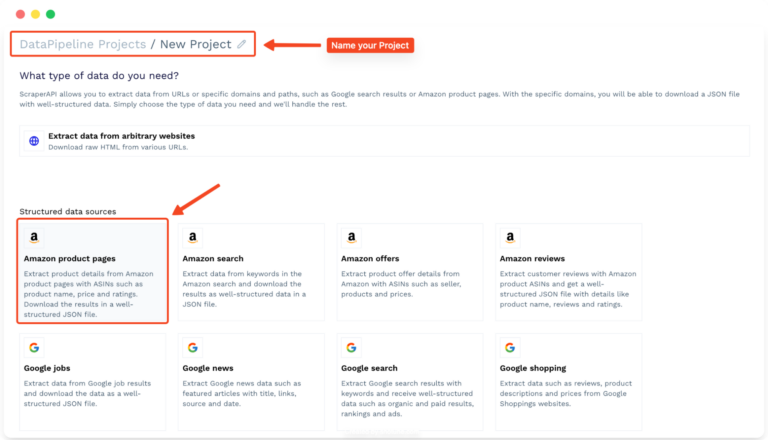
Step 2: Provide Input Data
Next, provide a list of ASINs for the products you want to scrape data from. With DataPipeline, you can scrape up to 10,000 items per project.

DataPipeline offers flexible options for providing this input data:
- Manually enter the ASINs directly into the provided text box (one per line) – like I did in the screenshot above
- Upload a CSV file containing the list of ASINs
- Use a Webhook to feed the ASINs to DataPipeline
How to Get ASINs
If you’re not sure how to get ASINs, check out this blog post for a detailed guide on scraping Amazon ASINs at scale.
If you’re already familiar with ScraperAPI’s Structured Data Endpoints, you can use the following code to quickly retrieve a list of ASINs for a given search query:
import requests
import json
asins = []
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'Airpods',
'country': 'us',
}
response = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
earphones = response.json()
all_products = earphones['results']
for product in all_products:
if product['asin'] != None:
asins.append(product['asin'])
else:
print('not found')
with open('asins.json', 'w') as f:
json.dump(asins, f)
Make sure you replace 'YOUR_API_KEY' with your actual ScraperAPI API key. This code will fetch search results for “Airpods,” extract the ASINs from the structured data, and save them to an asins.json file.
Note: You can also use DataPipeline to gather ASIN numbers automatically using the Amazon Search template.
Step 3: Customize Parameters
DataPipeline allows for customization to improve the accuracy and relevance of your scraped data. You can select different parameters and additional options depending on the specific data points you need.

For example, you can specify the country from which you want your requests to come (geotargeting) and the TLD (top-level domain) that you want DataPipeline to target.
Step 4: Select Output Format
Next, I’ll decide how I want to receive the scraped data. DataPipeline allows two options:
- Download the extracted data directly to your device
- Deliver the data to a webhook URL, automating your workflow by integrating the data with other applications or services.

You can also choose the format you want to receive the scraped data. DataPipeline supports both JSON and CSV formats for available templates. For arbitrary URLs, it’ll return HTML.
JSON is a great option if you need structured data that’s easy to parse and work within programming languages. On the other hand, CSV is a suitable choice if you need a more spreadsheet-friendly format for analysis or reporting.

Step 5: Schedule Scraping Frequency
Next, I’ll determine how often I want DataPipeline to execute my scraping job. I can opt for a one-time scrape if I only need the data once.
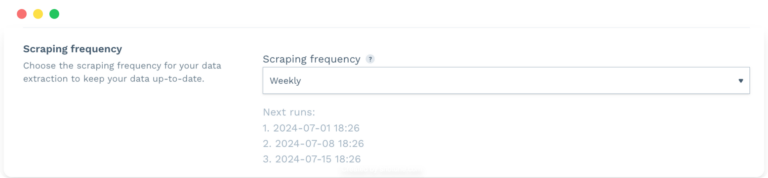
If I need to keep the data up-to-date, I can schedule the scraper to run at regular intervals – daily, weekly, or at a custom frequency that suits my needs. This greatly appealed to me as it relieved me of most of the data mining tasks.

Step 6: Set Notification Preferences
ScraperAPI will email you notifications about the progress and completion status of your scraping jobs. You can configure your notification preferences to receive alerts about successful job completions, any errors encountered, or other relevant updates.

This feature allows me to monitor my scraping projects without constantly checking the dashboard – which always saves a couple of minutes of work per day.
Step 7: Run Your Amazon Scraper
Once you’re ready, click “Review & Start Scraping.”
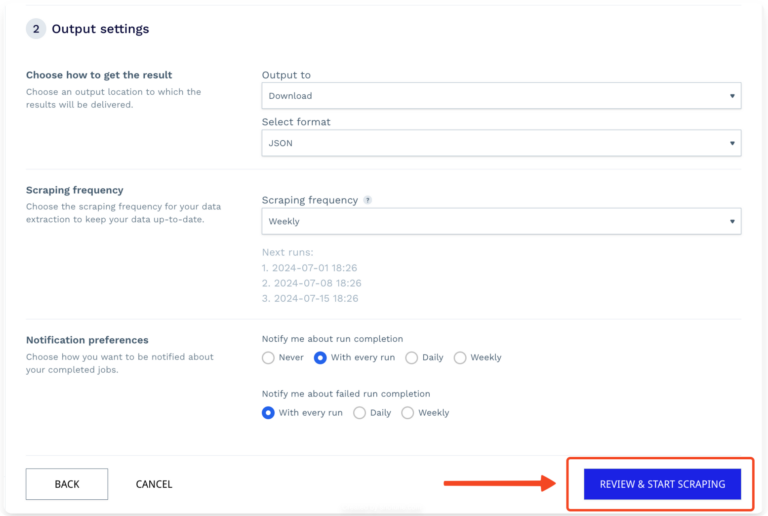
Review your project configuration before clicking on the “START SCRAPING” button. You will see an estimate of the credits that will be used for each run, giving you a transparent view of the cost.

You will then be redirected to the project dashboard.

From this dashboard, you can monitor the progress of your scraper, cancel running jobs if needed, review your configurations, and download the scraped data once the jobs are complete.
Note: Check DataPipelines documentation to learn the full features of the tool.
Automate Data Delivery Through Webhooks
One of the things I love about DataPipeline is the ability to deliver data directly to my applications using Webhooks. This webhook will act as the endpoint where the DataPipeline will send the scraped data, eliminating the need to download and transfer data manually.
Setting Up a Webhook
Before using the webhook functionality in DataPipeline, you must have a webhook URL set up. To make things easier, I’ll show you two options:
- A no-code option – great for testing or for serious projects in its paid version
- Advanced Webhook set up with Flask and Ngrok
No-Code Webhook Setup
A simple solution for quickly getting started with webhooks is to use Webhook.site. When you visit the site, it automatically generates a unique webhook URL. Copy this URL as your webhook endpoint to receive the scraping results.
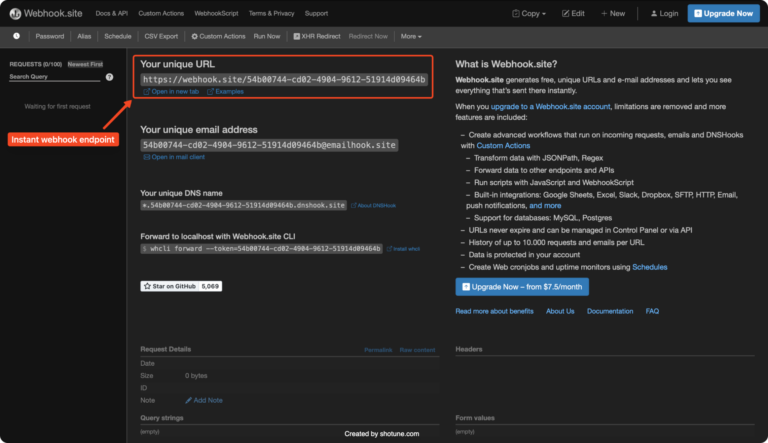
This is a quick and easy way to test and see the incoming data.

However, without a paid plan, Webhook.site only retains the data for 7 days, after which it is discarded.
Setting Up a Webhook Using Flask and Ngrok
While inspecting the content of a webhook payload can be useful (for example, by forwarding the webhook to tools like webhook.site), developers also require the capability to receive incoming webhooks directly in their application.
Here’s how you can do that using Flask</a >, a lightweight web framework for Python, and Ngrok, a tool that exposes local servers to the public internet:
- Install Flask and Ngrok
You can install Flask using pip:
pip install Flask
To install Ngrok
- On Windows (using Chocolatey):
choco install ngrok
- On macOS (using Homebrew):
brew install ngrok
You can download Ngrok directly from the official website for other operating systems.
- Configure your auth token (one-time setup)
To use Ngrok, you need to connect it to your account using an auth token. Get your Authtoken from your Ngrok dashboard</a >.

Open your terminal or command prompt and run the following command, replacing $YOUR_AUTHTOKEN with your actual auth token:
ngrok config add-authtoken $YOUR_AUTHTOKEN
- Create a Flask Webhook server
Let’s create a simple Flask application to handle incoming webhook requests. Save the following code in a file named webhook.py
from flask import Flask, request, jsonify
import csv
import io
import zipfile
from werkzeug.utils import secure_filename
app = Flask(__name__)
@app.route('/webhook', methods=['POST'])
def webhook():
content_type = request.headers.get('Content-Type')
if content_type == 'application/json':
data = request.json
print("Received JSON data:", data)
elif content_type == 'text/csv':
data = request.data.decode('utf-8')
csv_reader = csv.reader(io.StringIO(data))
csv_data = [row for row in csv_reader]
print("Received CSV data:", csv_data)
elif content_type.startswith('multipart/form-data'):
files = request.files
for filename, file in files.items():
print(f"Received file: {filename}")
file.save(secure_filename(file.filename))
if filename.endswith('.zip'):
with zipfile.ZipFile(file, 'r') as zip_ref:
zip_ref.extractall('extracted_files')
print(f"Extracted files: {zip_ref.namelist()}")
elif content_type == 'application/zip':
file = request.data
with open('received.zip', 'wb') as f:
f.write(file)
with zipfile.ZipFile(io.BytesIO(file), 'r') as zip_ref:
zip_ref.extractall('extracted_files')
print(f"Extracted files: {zip_ref.namelist()}")
else:
data = request.data.decode('utf-8')
print("Received raw data:", data)
# process the data as needed - eg add to a database/ perform analysis
return jsonify({'status': 'success', 'data': 'Processed data'}), 200
if __name__ == '__main__':
app.run(port=5000)
This code creates a simple Flask application that listens for incoming POST requests on the “/webhook” endpoint. It can handle different content types, such as JSON, CSV, raw data, and ZIP files. It also extracts and saves the received data in the current working directory. The data can be further processed as needed, such as saving it to a database or performing analysis.
- Run the Flask application
You can now run your Flask application:
python webhook.py
- Start Ngrok
Open a new terminal window and start Ngrok to expose your local Flask server:
ngrok http 5000
Ngrok will generate a public URL that forwards requests to your local Flask application. Copy the “Forwarding” URL that Ngrok provides; you’ll use this URL as your webhook endpoint in DataPipeline.
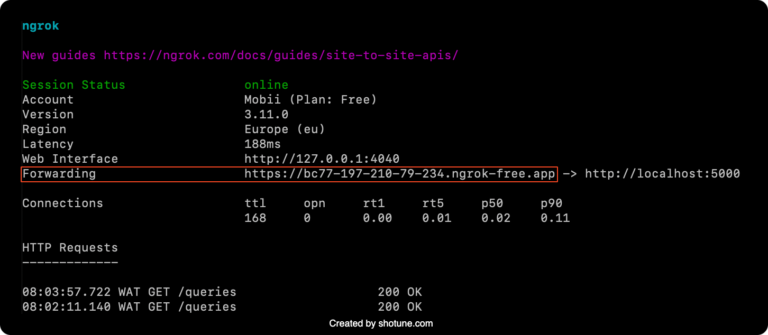
- Add the Webhook to DataPipeline
In your DataPipeline project settings, find the output settings:

Select “Webhook” as your preferred method, paste the webhook URL provided by Ngrok, and attach the “/webhook” endpoint to it.
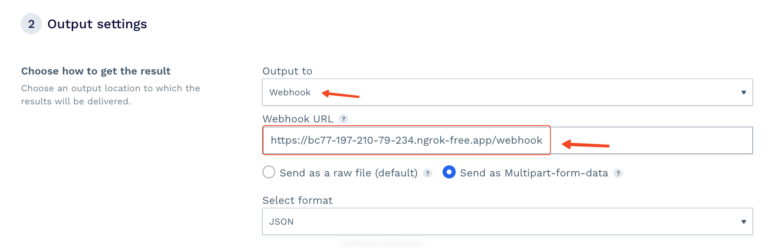
DataPipeline will automatically send the scraped data to your webhook URL.
Received file: result
127.0.0.1 - - [25/Jun/2024 15:32:36] "POST /webhook HTTP/1.1" 200 -
Extracted files: ['job-11814822-result.jsonl']
You can configure your webhook service or server to handle the data as needed, whether saving it to a database, sending notifications, or triggering other automated actions.
[
{
"input": "B0CHJ5LJZG",
"result": {
"name": "Wireless Earbuds, 2024 Wireless Headphones HiFi Stereo Earphones with 4 ENC Noise Canceling Mic, 42Hs Playtime In Ear Earbud, Bluetooth 5.3 Sport Earphones with LED Power Display for Android iOS White",
"product_information": {
"model_name": "A60PW-USM",
"connectivity_technology": "Wireless",
"wireless_communication_technology": "Bluetooth",
"special_feature": "Lightweight, Noise Isolation, Volume-Control, Microphone Feature, Sports & Exercise",
"included_components": "Charging case *1, Type-C Charging Cable*1, User Manual*1, 3 Pairs of Ear Tips(S M L ), Wireless Earbuds*2",
"age_range_description": "Adult",
"material": "Plastic",
"specific_uses_for_product": "Sports & Exercise, Running",
"charging_time": "1.5 Hours",
"compatible_devices": "Compatible devices with Bluetooth 5.3 or earlier, … [TRUNCATED]",
"control_type": "Media Control",
"cable_feature": "Without Cable",
"item_weight": "0.634 ounces",
"control_method": "Touch, Voice",
"number_of_items": "1",
"audio_driver_type": "Dynamic Driver",
"bluetooth_range": "15 Meters",
"bluetooth_version": "5.3",
"carrying_case_battery_charging_time": "1.5 Hours",
"audio_driver_size": "13 Millimeters",
"earpiece_shape": "Rounded Tip",
"manufacturer": "Aoslen",
"package_dimensions": "4.17 x 3.27 x 1.46 inches",
"asin": "B0CHJ5LJZG",
"item_model_number": "A60Pro",
"batteries": "1 Lithium Ion batteries required. (included)",
"customer_reviews": {
"ratings_count": 3154,
"stars": 4.5
},
"best_sellers_rank": [
"#267 in Electronics (See Top 100 in Electronics)",
"#48 in Earbud & In-Ear Headphones"
],
"date_first_available": "September 7, 2023"
},
"brand": "Brand: Aoslen",
"brand_url": "https://www.amazon.com/Aoslen/b/ref=bl_dp_s_web_38765055011?ie=UTF8&node=38765055011&field-lbr_brands_browse-bin=Aoslen",
"full_description": "From the brand Aoslen Wireless Earbuds If you have any questions, … [TRUNCATED]",
"pricing": "$19.99",
"list_price": "$49.99",
"shipping_price": "FREE",
"availability_status": "In Stock",
"is_coupon_exists": false,
"images": [
"https://m.media-amazon.com/images/I/41nBiguTHfL.jpg", [TRUNCATED]
],
"product_category": "Electronics \u203a Headphones, Earbuds & Accessories \u203a Headphones & Earbuds \u203a Earbud Headphones",
"average_rating": 4.5,
"feature_bullets": [
"2024 New Bluetooth 5.3 Technology: Bluetooth in ear headphones equipped with new version of bluetooth 5.3 chip, using better chip and technology. Transmit high quality lossless audio coding, ensure more stable connection, lower latency and lower power consumption during data transmission. With a stable connection distance of up to 15 meters, you can easily control your music and phone at home, in the office and on the go", [TRUNCATED]
],
"total_reviews": 3154,
"model": "A60Pro",
"customization_options": {
"color": [
{
"is_selected": false,
"url": "https://www.amazon.com/dp/B0BVQG2LVW/ref=twister_B0D14MT3VB?_encoding=UTF8&psc=1",
"value": "Black",
"price_string": "$19.99",
"price": 19.99,
"image": "https://m.media-amazon.com/images/I/41cGPiRmLHL.jpg"
}, [TRUNCATED]
]
},
"ships_from": "Amazon",
"sold_by": "Aoslen US",
"aplus_present": true
}
},
]
DataPipeline Endpoints vs. Visual Interface: Which One Should You Use?
By now, you’ve seen both ways to automate web scraping with ScraperAPI—using DataPipeline Endpoints for complete API control and the Visual Interface for a no-code setup. But when should you choose one over the other?
Both options let you scrape websites, extract data, and collect structured results from web pages, but they’re designed for different workflows. Whether you need full automation or just a quick way to pull data, the right choice depends on how often you scrape data, how much control you need, and how you plan to use the results.
Why DataPipeline Endpoints Are the Best Choice
If you want web scraping to fit seamlessly into your workflow, DataPipeline Endpoints give you the most control and flexibility. While the Visual Interface lets you configure scrapers easily, with the DataPipeline Endpoints, you get complete control over how and when your scrapers run without relying on a dashboard. This means you can automate, scale, and integrate web scraping into your existing workflow, making it far more efficient than manual scraping methods.
Here are some of the key features:
- Project management is fully automated, so you can create, update, and even archive scrapers through the API.
- Logging into a dashboard is unnecessary, allowing you to manage large-scale data collection without manual oversight.
- Scrapers can be scheduled and modified programmatically, ensuring they run when needed without any extra steps.
- Data is delivered in structured formats like JSON or CSV, making sending directly to databases, analytics tools, or other applications easy.
- You can manage jobs dynamically, starting, editing, and canceling scrapers on demand.
- Customization options give you complete control, including handling JavaScript-heavy sites, rotating proxies, and using tools like Selenium or Scrapy for advanced scraping needs.
When DataPipeline Endpoints Are the Right Fit
If you need web scraping to fit seamlessly into your workflow, DataPipeline Endpoints are the best way to achieve full automation and integration. Here’s when they make the most sense:
- You need a fully automated scraping system that lets you create, manage, and schedule jobs entirely through API requests.
- You’re managing multiple scraping projects at once and need an efficient way to control them without constantly logging into a dashboard.
- You want a cost-effective solution where you pay per job, ensuring you only spend resources on the extractions you run.
- You need advanced job management capabilities that allow you to modify, archive, or cancel scrapers dynamically.
- You want to integrate scraping with automation tools like Python scripts or a custom web scraping app.
- You require complete flexibility in handling web data, from extraction to storage and processing, without the constraints of a visual dashboard.
When the Visual Interface Makes Sense
If you don’t need full API automation or just want a quick way to extract data, the Visual Interface provides an intuitive, no-code way to configure scrapers. It offers the same functionality as the API but allows you to manage everything through a user-friendly dashboard.
The Visual Interface is designed to make web scraping simple and accessible, even if you don’t have coding experience. Here’s what it allows you to do:
- Set up scrapers visually using pre-built templates, so you don’t need to manually write a Python script or configure requests.
- Schedule scrapers directly from the dashboard, choosing when and how often they run without using external automation tools.
- Download results in CSV, JSON, or Excel, or send them via webhooks for real-time data processing.
- Monitor and manage scraping jobs from one place, using a centralized dashboard to track active and completed tasks.
- Avoid dealing with technical complexities, such as IP address rotation and authentication, or programming languages like Python or JavaScript.
When the Visual Interface Might Work for You
If you need a simple, no-code way to scrape websites, the Visual Interface is a great option. Here’s when it makes the most sense:
- You only scrape data occasionally and don’t require full API automation or integration.
- You prefer a no-code approach and would rather configure scrapers visually than work with a Python script or automation tools.
- You plan to download and analyze data manually rather than integrating it into a larger data analysis pipeline.
- You’re new to web scraping and want an easy way to experiment before transitioning to a more automated solution.
The Visual Interface is a great way to get started. Still, when you’re ready to scale, automate, and fully integrate scraping into your workflow, DataPipeline Endpoints will save you time and effort.
Which should you choose?
Since both options let you scrape data, schedule jobs, and extract structured results, the key difference is how you manage them.
With the Visual Interface, you must log in and configure scrapers manually. With DataPipeline Endpoints, everything runs in the background, allowing you to automate web data extraction without manual steps.
Many users follow this natural progression:
- Start with the Visual Interface to test and refine your data scraping setup.
- Move to DataPipeline Endpoints when you’re ready to automate your workflow, schedule scrapers, and integrate data directly into your apps.
No matter which approach you choose, ScraperAPI ensures you have a fast, reliable, and scalable way to extract data from the web. If you’re collecting web data regularly or integrating web scraping into your workflow, choosing the API from the start will save you time, reduce manual work, and simplify scaling. The Visual Interface works well if you just need to grab data now and then—but if you want web scraping to run smoothly in the background, DataPipeline Endpoints are the better choice.
Scrape a Dynamic List of Web Pages
DataPipeline’s ability to accept webhooks as input opens up a whole new level of automation for your web scraping projects. Now, you can scrape dynamic lists of URLs, ASINs, product IDs, or even search queries without having to manually update your DataPipeline projects.
Imagine you want to track Google search results for a list of perfume queries that change regularly. Instead of manually updating your project in DataPipeline every time your list changes, you can automate the entire process.
Create a Webhook to Provide Search Queries
Let’s create a webhook endpoint using Flask to provide the DataPipeline with a list of search queries. I’ll store my search queries in a CSV file, but you could easily adapt this to fetch queries from a database or any other dynamic source.
- Create a perfume_queries.csv file
Create a CSV file named perfume_queries.csv and add your list of search queries, one per line (without a header row). For example:
Perfume
Blue de Chanel
Dior Sauvage
Gucci Guilty
Versace Eros
Calvin Klein Euphoria
Marc Jacobs Daisy
Yves Saint Laurent Black Opium
Tom Ford Black Orchid
Initio Oud For Greatness
Paco Rabanne 1 Million
- Create the Flask Webhook:
Create a Python file (e.g., queries_webhook.py) and add the following Flask code:
from flask import Flask, jsonify
import csv
app = Flask(__name__)
def read_queries_from_csv(filepath):
with open(filepath, newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
next(reader) # Skip the header row
queries = [row[0] for row in reader if row] # One query per row
return queries
@app.route('/queries', methods=['GET'])
def provide_queries():
queries = read_queries_from_csv('perfume_queries.csv')
return jsonify(queries)
if __name__ == '__main__':
app.run(debug=True, port=5000)
Here, we define a Flask app with a “route /queries” that reads the search queries from your CSV file and returns them in JSON format.
- Run the Flask App:
Start your Flask application:
python queries_webhook.py
- Expose with Ngrok:
Use Ngrok (as explained in the previous section) to create a publicly accessible URL for your local Flask webhook:
ngrok http 5000
Copy the forwarding URL provided by Ngrok.
Create a Google Search Project in DataPipeline
Go to your DataPipeline dashboard and create a new project using the “Google Search</strong >” template.

Instead of manually entering search terms, paste the Ngrok forwarding URL (that points to your /queries webhook) into the input field in DataPipeline.

DataPipeline will automatically call your webhook, fetch the latest list of search queries, and use them as input for scraping Google Search results. Now, you have a fully automated pipeline where any updates to your perfume_queries.csv file will be reflected in your scraped data without any manual intervention!
Also Read: How to Scrape Google Shopping with Python
DataPipeline takes the hassle out of web scraping, making it easier to gather the data you need at scale. Ready to give it a try? Sign up for a free ScraperAPI account and try DataPipeline today.