


Realtor.com is the second-largest real estate platform in the United States for individuals and businesses to buy, rent, and sell properties and for analysts to gather a lot of property data that can be used to examine future trends in any locality.
However, collecting this information manually is not only inefficient but impossible. Listings change too fast, and new properties are added daily, so the best way to approach this is web scraping.
In this article, we’ll walk you through a step-by-step guide on scraping Realtor.com data using Python (to write our script) and ScraperAPI’s standard API to avoid getting blocked.
TL;DR: Full Realtor.com Scraper
For those in a hurry, here’s the full script we’ll build in this tutorial:
import requests
from bs4 import BeautifulSoup
import json
output_data = []
base_url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA/show-newest-listings/sby-6"
API_KEY = "API_KEY"
def scrape_listing(num_pages):
for page in range(1, num_pages + 1):
# To scrape page 1
if page == 1:
url = f"{base_url}"
else:
url = (
f"{base_url}/pg-{page}" # Adjust the URL structure based on the website
)
print(f"Scraping data from page {page}... {url}")
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("https://api.scraperapi.com", params=payload)
html_response = r.text
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# scraping individual page
listings = soup.select("div[class^='BasePropertyCard_propertyCardWrap__']")
print("Listings found!")
for listing in listings:
price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts[0] if address_parts else "nil"
township = address_parts[1] if len(address_parts) > 1 else "nil"
property_url_elements = listing.select("a[class^='LinkComponent_anchor__']")
property_url = "nil" # Default value if property_url_elements is empty
for element in property_url_elements:
property_url = "https://www.realtor.com" + element["href"]
break
beds = listing.find(
"li",
class_="PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0",
)
beds = (
beds.find("span", {"data-testid": "meta-value"}).text.strip()
if beds
else "nil"
)
baths = listing.find(
"li",
class_="PropertyBathMetastyles__StyledPropertyBathMeta-rui__sc-67m6bo-0",
)
baths = baths.find("span").text.strip() if baths else "nil"
sqft = listing.find(
"li",
class_="PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0",
)
sqft = (
sqft.find("span", {"data-testid": "screen-reader-value"}).text.strip()
if sqft
else "nil"
)
plot_size = listing.find(
"li",
class_="PropertyLotSizeMetastyles__StyledPropertyLotSizeMeta-rui__sc-1cz4zco-0",
)
plot_size = (
plot_size.find(
"span", {"data-testid": "screen-reader-value"}
).text.strip()
if plot_size
else "nil"
)
property_data = {
"price": price,
"address": address,
"township": township,
"url": property_url,
"beds": beds,
"baths": baths,
"square_footage": sqft,
"plot_size": plot_size,
}
output_data.append(property_data)
num_pages = 5 # Set the desired number of pages
# Scrape data from multiple pages
scrape_listing(num_pages)
# our property count
output_data.append({"num_hits": len(output_data)})
# Write the output to a JSON file
with open("Realtor_data.json", "w") as json_file:
json.dump(output_data, json_file, indent=2)
print("Output written to output.json")
Note: Substitute API_KEY in the code with your actual API key before running the script.
Want to learn how we built it? Keep reading for a step-by-step explanation.
Scraping Realtor.com’s Product Data
Before you begin the scraping, defining what specific information you aim to extract from the webpage is essential. For this tutorial, we’ll focus on the following details:
- Property Selling Price
- Property Address
- Property Listing URL
- Number of Beds and baths
- Property Square footage
- Plot size
Prerequisites
The main prerequisites for this tutorial are Python, Requests, BeautifulSoup, and Lxml libraries. Run this command to install accordingly.
pip install beautifulsoup4 requests lxml
Step 1: Setting Up Your Project
Note: Before starting, make sure to sign up for a free ScraperAPI account to obtain your API key.
First, we import the necessary Python libraries at the top of our .py file.
import requests
from bs4 import BeautifulSoup
import json
Then, we initialize the variables we’ll use throughout our script.
output_data = []
base_url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA/show-newest-listings/sby-6"
API_KEY = "YOUR_API_KEY"
output_datastores the database_urlis the URL of the Realtor.com page we want to scrape – at least the initial URL – which you can get by navigating to the site and performing a searchAPI_KEYwill hold our ScraperAPI key as a string
Step 2: Define Your Scraping Function
We define a function, scrape_listing(), which takes the number of pages to scrape as an argument, allowing us to scrape multiple pages.
def scrape_listing(num_pages):
for page in range(1, num_pages + 1):
# To scrape page 1
if page == 1:
url = f"{base_url}"
else:
url = f"{base_url}/pg-{page}" # Adjust the URL structure based on the website
print(f"Scraping data from page {page}... {url}")
payload = {"api_key": API_KEY, "url": url}
# Make a request to the ScraperAPI
r = requests.get("https://api.scraperapi.com", params=payload)
html_response = r.text
soup = BeautifulSoup(html_response, "lxml")
We loop over each page, construct the URL for the page, make a GET request to ScraperAPI, and conjure a BeautifulSoup object for each page.
Note: We need to send our requests through ScraperAPI to avoid getting our IP banned, allowing us to collect data on a large scale.
Step 3: Parse HTML Response
By parsing the HTML response using BeautifulSoup, we can turn the raw HTML into a parsed tree we can navigate using CSS selectors.
If we inspect the page, we can see that each listing is wrapped inside a card (div) with the BasePropertyCard_propertyCardWrap__ class.
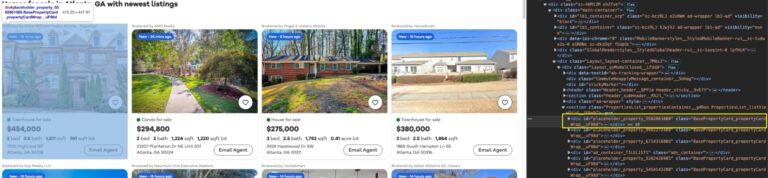
Using this class, we can now store all property listings into a listing variable.
# Parse the HTML response using BeautifulSoup
soup = BeautifulSoup(html_response, "lxml")
# scraping individual page
listings = soup.select("div[class^='BasePropertyCard_propertyCardWrap__']")
print("Listings found!")
We’ll print a success message to the console to get some feedback as our code runs.
Step 4: Extract Property Data
For each listing found, we’ll extract the property data such as price, address, URL, number of bedrooms, bathrooms, square footage, and lot size.
To extract the prices of each listing, we use the selector div[class^='card-price']. This selector targets the div elements whose class starts with card-price. These divs contain the price of the property.

price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
To extract the address from the property listings card, we use the selector div[class^='card-address']. These divs contain the address of the property.

full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts[0] if address_parts else "nil"
township = address_parts[1] if len(address_parts) > 1 else "nil"
To extract other property listing details, we walk down a couple of li elements which contain the selectors PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0 and PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0.

The number of beds and baths and the square footage of each listed property can be found in these CSS selectors.
for listing in listings:
price = listing.find("div", class_="card-price")
price = price.get_text(strip=True) if price else "nil"
full_address = listing.find("div", class_="card-address")
full_address = full_address.get_text(strip=True) if full_address else "nil"
address_parts = full_address.split(", ")
address = address_parts[0] if address_parts else "nil"
township = address_parts[1] if len(address_parts) > 1 else "nil"
property_url_elements = listing.select("a[class^='LinkComponent_anchor__']")
property_url = "nil" # Default value if property_url_elements is empty
for element in property_url_elements:
property_url = "https://www.realtor.com" + element["href"]
break
beds = listing.find(
"li",
class_="PropertyBedMetastyles__StyledPropertyBedMeta-rui__a4nnof-0",
)
beds = (
beds.find("span", {"data-testid": "meta-value"}).text.strip()
if beds
else "nil"
)
baths = listing.find(
"li",
class_="PropertyBathMetastyles__StyledPropertyBathMeta-rui__sc-67m6bo-0",
)
baths = baths.find("span").text.strip() if baths else "nil"
sqft = listing.find(
"li",
class_="PropertySqftMetastyles__StyledPropertySqftMeta-rui__sc-1gdau7i-0",
)
sqft = (
sqft.find("span", {"data-testid": "screen-reader-value"}).text.strip()
if sqft
else "nil"
)
plot_size = listing.find(
"li",
class_="PropertyLotSizeMetastyles__StyledPropertyLotSizeMeta-rui__sc-1cz4zco-0",
)
plot_size = (
plot_size.find(
"span", {"data-testid": "screen-reader-value"}
).text.strip()
if plot_size
else "nil"
)
property_data = {
"price": price,
"address": address,
"township": township,
"url": property_url,
"beds": beds,
"baths": baths,
"square_footage": sqft,
"plot_size": plot_size,
}
output_data.append(property_data)
This data is stored in a dictionary and appended to the output_data list. Each piece of data is extracted using the .find() method and the appropriate CSS selector.
Step 5: Scrape Data from Multiple Pages
We call the scrape_listing() function to scrape data from the desired number of pages. Feel free to modify the num_pages variable to scrape data from more pages if needed.
num_pages = 5 # Set the desired number of pages
# Scrape data from multiple pages
scrape_listing(num_pages)
Step 6: Write the Output to a JSON File
Before finishing our script, we add the total number of properties scraped to the output_data list.
# our property count
output_data.append({"num_hits": len(output_data)})
Finally, we write the output_data list to a JSON file.
# Write the output to a JSON file
with open("Realtor_data.json", "w") as json_file:
json.dump(output_data, json_file, indent=2)
print("Output written to output.json")
Congratulations, you just scrapped vital data from Realtor.com!
Here is how the end result in the Realtor_data.json file will look like:
{
"price": "$315,000",
"address": "2383 Baker Rd NWAtlanta",
"township": "GA 30318",
"url": "https://www.realtor.com/realestateandhomes-detail/2383-Baker-Rd-NW_Atlanta_GA_30318_M56102-81051?from=srp-list-card",
"beds": "3",
"baths": "2",
"square_footage": "nil",
"plot_size": "8,712 square foot lot"
},
{
"price": "$365,000",
"address": "3150 Woodwalk Dr SE Unit 3408Atlanta",
"township": "GA 30339",
"url": "https://www.realtor.com/realestateandhomes-detail/3150-Woodwalk-Dr-SE-Unit-3408_Atlanta_GA_30339_M51624-69914?from=srp-list-card",
"beds": "2",
"baths": "2",
"square_footage": "nil",
"plot_size": "1,307 square foot lot"
},
...
MORA DATA
...
{
"num_hits": 84
}
How to Turn Realtor Pages into LLM-Ready Data
By now, you’ve seen how to scrape Realtor.com listings using BeautifulSoup and how to loop through pages to collect data like price, beds, square footage, and more. But what if you want to skip all the parsing and send the data straight into a language model for analysis or summary?
That’s where ScraperAPI’s output_format=markdown comes in. Instead of returning raw HTML, it gives you a clean, readable version of the listings page—perfect for large language models like Gemini to work with out of the box.
Step 1: Obtain and Secure Your API Keys
To get started, ensure you have a ScraperAPI key and a Google Gemini API key. If you already have them, you can skip to the next step. You can get your ScraperAPI key from your dashboard or sign up here for a free one with 5,000 API credits.
To get a Gemini API key:
- Go to Google AI Studio
- Sign in with your Google account
- Click on Create API Key
- Follow the prompts to generate your key
Step 2: Scrape Realtor as Markdown
Let’s say you want to analyse listings in Atlanta. Using ScraperAPI, you can pull the page in Markdown format like this:
import requests
API_KEY = "YOUR_SCRAPERAPI_KEY"
url = "https://www.realtor.com/realestateandhomes-search/Atlanta_GA"
payload = {
"api_key": API_KEY,
"url": url,
"ultra_premium": true
"output_format": "markdown"
}
response = requests.get("https://api.scraperapi.com", params=payload)
markdown_data = response.text
print(markdown_data)
Sample Output:
[Property detail for 490 Culberson St SW Atlanta, GA 30310](/realestateandhomes-detail/490-Culberson-St-SW%5FAtlanta%5FGA%5F30310%5FM67500-54827?from=srp-list-card)
House for sale
$134,900
* 2bed
* 2.5bath
* 6,970sqft lot6,970 square foot lot
490 Culberson St SW
Atlanta, GA 30310
Email Agent
Brokered by Atlanta Communities - East Cobb
Step 3: Summarize the Realtor Page with Gemini
Now that you have the Markdown, you can feed it to Google Gemini and extract a clean summary.
Start by installing the Gemini SDK if you haven’t already:
pip install google-generativeai
Then, request a summary from Gemini using a custom prompt:
import google.generativeai as genai
genai.configure(api_key="YOUR_GEMINI_API_KEY")
model = genai.GenerativeModel(model_name="gemini-2.0-pro")
prompt = f"""
You are a housing market analyst. Based on the listings below, provide:
- A brief summary of the properties listed
- Any pricing or size trends you notice
- The most appealing or unique listing features
Here are the listings:
{markdown_data}
"""
response = model.generate_content(prompt)
print(response.text)
Gemini’s response might look like this:
Okay, here's an analysis based on the provided Realtor.com listings in Atlanta, GA:
**Brief Summary of Listings**
The provided snippet shows a mix of property types for sale in Atlanta, GA, including single-family homes, a multi-family home, and condos. The prices range drastically from $85,000 to $37,800,000, and the size ranges from 1,118 sqft to 3,147 sqft. There are also some advertisements and coming-soon placeholders in the listing results.
**Pricing and Size Trends**
* **Wide Price Range:** Atlanta's market seems to cater to diverse budgets, from affordable condos to ultra-high-end luxury estates.
* **Price per Square Foot Varies:** Without knowing exact features, price per square foot likely reflects location, condition, and amenities.
* **Size Not Always Correlated with Price:** The most expensive property has a massive lot size of 18.55 acres, which drives the price up immensely compared to other properties.
**Most Appealing or Unique Listing Features**
* **Virtual Tours Available:** Many listings advertise virtual tours, which is a big draw for buyers who may be out-of-state or prefer to view properties remotely first.
* **New Construction:** The "Popular filters" section indicates that new construction is a sought-after feature.
* **Open House:** The listing for "707 Pine Tree Trl B10" highlights an upcoming open house, which can attract a lot of potential buyers.
* **"New" Badge:** The condo listed at 1213 Camelot Dr displays a "new" badge, indicating a recent listing which may attract buyers looking for fresh opportunities.
**Overall Impression**
The Atlanta housing market, based on this limited data, is active with diverse offerings. Online features like virtual tours are prominently displayed. The market seems to have options for a wide range of budgets and preferences.
With just a few lines of code, you get a clear view of what’s happening in the local housing market—no need to scroll through endless listings. Whether you’re trying to compare prices, spot standout features, or find homes that fit a specific need, this setup makes it simple.
And since you can adjust the prompt however you like, it works for all use cases—from tracking renovation trends to highlighting good value properties. It’s a straightforward way to turn raw listing pages into real insight.
Wrapping Up
In this tutorial we’ve built a Realtor.com scraper that:
- Navigates to a specific page from Realtor.com to collect property data
- Sends all requests through ScraperAPI servers to avoid getting blocked by anti-scraping mechanisms
- Navigates through the pagination to scrape multiple pages
- Writes all scraped data into a JSON file
Now, change the URL from the base_url variable (or create a list of URLs) and start collecting Realtor property data at scale!
Need more than 3M API credits? Contact our sales team and let them help you build a custom solution that fits your needs.
Frequently Asked Questions
From Realtor.com you can get data like:
– Property Selling Price
– Property Address
– Property Listing URL
– Number of Beds and baths
– Property Square footage
– Plot size
All of this information can then be transformed into JSON or a CSV file for analysis.
You can use Realtor.com’s data to know the price and qualities of property in a location, spot pricing and demand trends in specific areas, improve your listings based on your competitors, create property alerts when prices are down, and much more.
Yes, it does. This is the reason it is vital to use formidable scraping tools such as ScraperAPI.