


Web scraping can get complicated quickly. From JavaScript-heavy websites to CAPTCHAs and IP bans, there are plenty of obstacles that can slow you down or stop you entirely. But with the right tools, collecting clean, reliable data doesn’t have to be a constant struggle.
In this guide, I’ll walk you through some of the best web scraping tools available today. Whether you’re a developer looking for full control or someone who prefers an easy, no-code solution, you’ll find an option that fits your workflow and skill level.
Here’s what to expect:
- A straightforward comparison of each tool’s pricing, features, and ease of use
- Technical insights into how well they handle JavaScript rendering, proxies, and large-scale tasks
- Pros, cons, and who each tool is best suited for
- Tips to help you avoid common scraping issues and make the most of your data
By the end, you’ll have a solid understanding of which tools are worth your time—and which might save you hours of frustration.
Ready? Let’s get into it!
The 14 Best Web Scraping Tools: Quick Comparison
To easily scrape data from any website, you need a reliable web scraping tool. Here are some key factors to consider before choosing the right tool for your project:
- Speed and efficiency: How fast can the tool scrape data?
- Scalability: Can it handle large-scale scraping tasks?
- Pricing: Is it cost-effective for your needs?
- Ease of use: How user-friendly is the interface?
- Error handling: How well does the tool manage failures or interruptions?
- Customer support: Is there responsive support available?
- Customization: Does the tool offer flexibility for specific requirements?
Of course, we’ve considered all of these factors when choosing our top picks for this list so you can confidently choose the right web scraping tool for your project.
For those in a hurry, here’s a quick overview of the web scraping tools on the list:
| Provider | Pricing/Monthly | Key Features | Ease of use | Ratings |
| ScraperAPI | $49+ | Full scraping solution | ⭐⭐⭐⭐⭐ | Trustpilot – 4.7 G2 – 4.27 Capterra – 4.6 |
| ScrapeSimple | $250+ | Custom web scraper service [no-code] | ⭐⭐⭐⭐ | No ratings |
| Octoparse | $119+ | No-code web scraping tool | ⭐⭐⭐⭐ | Trustpilot – 2.7 G2 – 4.8 Capterra – 4.7 |
| ParseHub | $189+ | Click-and-scrape web scraping tool [no-code] | ⭐⭐⭐⭐ | G2 – 4.3 Capterra – 4.5 |
| Decodo | Core: from $0.08 (1,000 requests) Advanced: from $0.95 (1,000 requests) | All-in-one scraping with templates and free tools | ⭐⭐⭐⭐⭐ | Trustpilot – 4.3 G2 – 4.6 |
| Scrapy | Free | Open-source web crawling framework for developers [Python] | ⭐⭐⭐⭐⭐ | Github star – 55.1k |
| Oxylabs | $499+ | AI-powered, all-in-one scraping solution and code generation (OxyCopilot) | ⭐⭐⭐⭐⭐ | G2 – 4.5 Capterra – 4.7 |
| Diffbot | $299+ | AI-powered enterprise data extraction tool | ⭐⭐⭐⭐ | G2 – 4.9 Capterra – 4.5 |
| Cheerio | Free | Lightweight HTML parsing library for Node.js | ⭐⭐⭐⭐ | Github star – 29.4k |
| BeautifulSoup | Free | Python HTML parsing library | ⭐⭐⭐⭐⭐ | G2 – 4.4 |
| Puppeteer | Free | Headless browser automation for Node.js | ⭐⭐⭐⭐⭐ | Github star – 90.6k |
| Mozenda | $99+ | Cloud-based web scraping tool [no-code] | ⭐⭐⭐⭐ | G2 – 4.1 Capterra – 4.4 |
| ScrapeHero Cloud | $5+ | On-click cloud-based scraping [no-code] | ⭐⭐⭐⭐ | Trustpilot – 3.7 G2 – 4.6 Capterra – 4.7 |
| Webscraper.io | $50+ | Free Google Chrome browser extension | ⭐⭐⭐ | Trustpilot – 4.4 G2 – 4.7 |
| Kimura | Free | Ruby-based web scraping framework with multi-browser support | ⭐⭐⭐ | Github star – 1k |
| Goutte | Free | PHP-based web crawling framework for static sites | ⭐⭐⭐ | Github star – 9.3k |
The 14 Best Web Scraping Tools: In-Depth Review
1. ScraperAPI [Full scraping solution for dev teams]
Who this is for: ScraperAPI is a tool for developers building web scrapers. It handles proxies, browsers, and CAPTCHAs so developers can get the raw HTML from any website with a simple API call. ScraperAPI’s automatic proxy management saves time and reduces the risk of IP bans, ensuring uninterrupted data scraping.
Why you should use it: ScraperAPI doesn’t burden you with managing your own proxies. Instead, it manages its internal pool of hundreds of thousands of proxies from a dozen different proxy providers and has smart routing logic that routes requests through different subnets.
It also automatically throttles requests to avoid IP bans and CAPTCHAs – providing excellent reliability. It’s the ultimate web scraping service for developers, with unique pools of premium proxies for ecommerce price scraping, search engine scraping, social media scraping, sneaker scraping, ticket scraping, and more!
Simply put, ScraperAPI helps businesses gain valuable insights at a large scale, ultimately allowing you to focus on decision-making rather than data extraction.
Note: See how saas.group uses ScraperAPI to help identify merger & acquisition opportunities.
Pros
- Full Scraping Solution: ScraperAPI offers a complete web scraping package that automates proxy management, CAPTCHA solving, and request retries, making it easy to extract data from almost any site.
- Advanced Bot Blocker Bypass: It effectively bypasses advanced anti-bot solutions like DataDome and PerimeterX, ensuring higher success rates on difficult-to-scrape websites.
- Structured Endpoints: ScraperAPI’s pre-built endpoints deliver clean, structured data, reducing the time needed for parsing and data cleaning, which enhances productivity.
- Cost-Effective: ScraperAPI’s unique smart IP rotation system uses machine learning and statistical analysis to select the best proxy per request; by only rotating proxies when necessary and using residential and mobile proxies as secondary options for failed requests, it significantly reduces proxy overhead, making it cheaper than many competitors.
- Scalability Tools: Features like DataPipeline for scheduling recurring tasks and Async Scraper for handling large request volumes asynchronously allow users to scale and automate scraping efforts efficiently.
Cons
- Reduced number of structured data endpoints compare to some competitors.
Ratings
The best way to identify a tool that does what it says is by checking reviews and ratings of the tool, and so far, scraperAPI has maintained its position at the top. Here are ratings from major rating platforms.
- Trustpilot rating — 4.7
- G2 rating — 4.27
- Capterra — 4.6
Ease of use
⭐⭐⭐⭐⭐ (5/5)
A good scraping tool should be easy to use, else it defeats the purpose, and ScraperAPI stands out in this case as the reviews don’t lie.
Feel free to check the amazing reviews about how ScraperAPI makes your task easier.
Pricing
ScraperAPI pricing model is easy to understand and affordable as we charge per successful request instead of per GB or bandwidth like other web scraping tools.
The number of credits consumed depends on the domain, the level of protection on the website, and the specific parameters you include in your request.
For example, ScraperAPI charges 5 API credits per successful request to ecommerce domains like Amazon and Walmart, making it simple to calculate the number of pages you can scrape with your plan.
Here is a breakdown of ScraperAPI’s pricing model:
| Plan | Pricing | API Credits |
| Free Trial [7 – days] | Free | 5000 |
| Hobby | $49 | 100,000 |
| Startup | $149 | 1,000,000 |
| Business | $299 | 3,000,000 |
| Enterprise | $299 + | 3,000,000 + |
Visit the ScraperAPI Credits and Requests page to see credit usage In detail.
2. ScrapeSimple [web scraping outsourcing]
Who this is for: ScrapeSimple is the perfect service for people who want a custom web scraper tool built for them. It’s as simple as filling out a form with instructions for what kind of data you want.
Why you should use it: ScrapeSimple lives up to its name and takes its place near the top of our list of easy web scraping tools with a fully managed service that builds and maintains custom web scrapers for customers.
Just tell them what information you need from which sites, and they will design a custom web scraper to deliver the information periodically (you can choose between daily, weekly, or monthly) in CSV format directly to your inbox.
This service is perfect for businesses that just want an HTML scraper without needing to write any code themselves. Response times are quick, and the service is incredibly friendly and helpful, making it perfect for people who just want the full data extraction process taken care of.
Pros
- Fast 1 – 2 days turnaround time for small projects
- Outsource services for companies looking only for data
- It doesn’t require technical expertise for the data collection process
Cons
- It’s more expensive than a DIY approach
- Your team still needs technical expertise to work with and analyse the data
Ratings
As they are a web scraping service, there are no related G2 or Trustpilot reviews to mention.
Ease of use
⭐⭐⭐⭐(4/5)
Pricing
ScrapeSimple does not have a fixed price. Instead, they ask for a minimum $250/month budget per project.
3. Octoparse [no-code browser scraping tool]
Who this is for: Octoparse is a fantastic scraper tool for people who want to extract data from websites without having to code while still having control over the whole process with their easy-to-use user interface.
Why you should use it: Octoparse is one of the best screen scraping tools for people who want to scrape websites without learning to code. It features a point-and-click screen scraper, allowing users to scrape behind login forms, fill in forms, input search terms, scroll through infinite scroll, render JavaScript, and more.
It also includes a site parser and a hosted solution for users who want to run their scrapers in the cloud. Best of all, it comes with a generous free tier, allowing users to build up to 10 crawlers for free. For enterprise-level customers, they also offer fully customized crawlers and managed solutions where they run everything for you and just deliver the data to you directly.
Pros
- Ease of Use: Octoparse is highly praised for its user-friendly interface, especially with the Smart Mode and Wizard Mode, making it accessible to anyone with limited technical skills.
- Advanced Mode for Precision: The Advanced Mode is well-regarded for enabling precise and accurate data extraction, allowing more technical individuals to refine their scraping tasks.
- XPath Support: Octoparse XPath support is clear and easy to use, helping you extract specific elements from web pages efficiently.
- Speed and Automation: Octoparse excels in speed and is particularly valued for automating the extraction of large datasets, which is useful for tasks like gathering email IDs or scraping product data.
- No Coding Required: Octoparse simplifies the data extraction process, allowing you to scrape websites without any programming or complex rule-setting.
Cons
- Learning Curve for Advanced Features: While the basic features are user-friendly, some users might find the Advanced Mode or XPath customization challenging without prior knowledge.
Ratings
- Trustpilot rating — 2.7
- G2 rating — 4.8
- Capterra — 4.7
Ease of use
⭐⭐⭐⭐(4/5)
Pricing
Octoparse pricing models are relatively fair as they charge per task, so your subscription determines the number of tasks you can perform.
| Plan | Pricing | Task |
| Free Trial | Free | 10 |
| Standard | $119 | 100 |
| Premium | $299 | 250 |
Despite Octoparse’s fair prices, it is still not cost-effective for medium and large-scale projects compared to ScraperAPI. ScraperAPI’s free plan offers 5000 API credits, allowing you to scrape up to 5k URLs without heavy anti-bots.
ScraperAPI’s lowest plan offers US & EU geo-targeting features for location-based tasks to help you extract data from specific locations.
4. ParseHub [low-code web scraping automation tool]
Who this is for: ParseHub is a potent tool for building web scrapers without coding—analysts, journalists, data scientists, and everyone in between use it.
Why you should use it: ParseHub is exceedingly simple to use. Its automatic IP rotation ensures that your scraping activities remain undetected, providing you with reliable access to the data you need, even from sites with strict access controls. You can build web scrapers simply by clicking on your desired data. ParseHub then exports the data in JSON or Excel format. It has many handy features, such as automatic IP rotation, allowing web page scraping behind login walls, going through dropdowns and tabs, getting data from tables and maps, and much more.
In addition, it has a generous free tier, allowing users to scrape up to 200 pages of data in just 40 minutes! ParseHub is also nice because it provides desktop clients for Windows, Mac OS, and Linux, so you can use them from your computer no matter what system you’re running.
Pros
- Ease of use for simple tasks: ParseHub has a user-friendly interface, allowing easy web scraping without requiring much technical expertise.
- Automation features: ParseHub has useful automation capabilities, such as scheduling and dynamic page scraping, which allow users to scrape complex sites with multiple layers of data
- Free version: It offers a robust free version, making it accessible for those who want to try its features before committing to a paid plan. This includes up to 200 pages per run and 5 public projects.
- Cost-effective scalability: It offers several pricing tiers, including the $189/month Standard plan, which allows up to 10,000 pages per run, and a Professional plan with enhanced features like faster scraping and priority support.
Cons
- Support limitations: There have been complaints about customer support being more sales-oriented and less focused on resolving issues, especially for users on free trials.
- Needs to be Installed: Having the scrapers running locally on your machine means you’ll need a larger investment in equipment to grow your operations.
- Customization Limits: Being a low-code platform, it is more restrictive than dedicated scraping APIs.
Ratings
- G2 rating — 4.3
- Capterra — 4.5
Ease of use
⭐⭐⭐⭐ (4/5)
Pricing
ParseHub pricing is based on speed and pages. The higher your subscription, the more pages you can scrape.
| Plan | Pricing | Pages |
| Free Trial | Free | 200 pages per run in 40 minutes |
| Standard | $189 | 10,000 pages per run (200 pages in 10 minutes) |
| Professional | $599 | Unlimited in less than 2 minutes |
| ParseHub Plus | Custom | Custom |
Based on the number of pages, scraperAPI is more economical because its lowest plan, with 100,000 API credits – $49/month – can easily get you over 10,000 pages.
Related: Explore some of the best Parsehub alternatives.
5. Decodo [web scraping with integrated proxies]
Who is this for: Decodo is designed for businesses and technical users who need reliable, large-scale web scraping with integrated proxies. It’s particularly useful for teams working on data-driven projects such as market research, ad verification, social media monitoring, SEO tracking, and price aggregation.
Why you should use it: The platform offers access to over 125 million IPs across more than 195 locations, covering residential, mobile, static residential (ISP), and datacenter proxies. Its Web Scraping API supports geo-targeting, JavaScript rendering, and bypasses many anti-bot and CAPTCHA systems. Good performance, strong uptime, and very responsive support are often cited by users. Its dashboard is user friendly, and for many projects, you get fine-grained control (session persistence, IP rotation, etc.) as well as usage statistics.
Pros
- Flexible payment options with a Core plan for smaller projects and an Advanced plan for higher-volume needs
- Strong uptime and reliability
- 24/7 tech support
Cons
- Can be expensive for low-volume users or small one-off scraping tasks
Ratings
- Trustpilot – 4.3
- G2 – 4.6
Ease of use
⭐⭐⭐⭐⭐ (5/5)
Pricing
Decodo’s pricing is based on the number of successful API requests. The Web Scraping API offers a 7-day free trial with 1,000 requests included, and paid plans scale based on request volume.
If you buy the Advanced plan, you’ll be able to spend less and get a better price per 1,000 requests.
Decodo also offers custom solutions to enterprise clients.
| Plan | Pricing | Requests |
| Free Trial (7 days) | Free | 1,000 |
| Core | From $0.08 | 1,000 |
| Advanced | From $0.95 | 4.2M |
Refund policy: 14-day money-back, which doesn’t apply if you used a free trial.
Related: Explore some of the best Decodo alternatives.
6. Scrapy [crawling and scraping Python library]
Who this is for: Scrapy is an open-source web scraping library for Python developers looking to build scalable web crawlers. It’s a comprehensive framework that handles all plumbing (queueing requests, proxy middleware, etc.) that makes building web crawlers difficult.
Why you should use it: As an open-source tool, Scrapy is entirely free. It is battle-tested and has been one of the most popular Python libraries for years. It’s lauded as the best Python web scraping tool for new applications. There is a learning curve, but it’s well-documented, and numerous tutorials are available to help you get started.
In addition, deploying the crawlers is very simple and reliable. Once they are set up, the processes can run themselves. As a fully featured web scraping framework, many middleware modules are available to integrate various tools and handle various use cases (handling cookies, user agents, etc.)
Pros
- High-Speed Crawling and Scraping: Scrapy is known for its speed in handling large-scale web scraping projects. It’s designed with asynchronous networking support, which means it can send multiple requests concurrently, reducing idle times. This makes it highly efficient in extracting large volumes of data from websites in a short period of time.
- Capable of Large-Scale Data Extraction: With Scrapy, you can scrape massive amounts of data. Its ability to handle distributed crawlers means you can scale your projects by running multiple spiders simultaneously. This makes Scrapy ideal for enterprise-level scraping projects where thousands of pages must be crawled daily.
- Memory-Efficient Processes: Scrapy uses efficient memory handling to manage large-scale web scraping tasks with minimal resource consumption. Unlike browser-based scrapers, Scrapy doesn’t load full HTML pages or render JavaScript, keeping its memory usage low and allowing it to handle a large number of requests without performance degradation.
- Highly Customizable and Extensible: Scrapy’s modular architecture allows developers to easily tailor their scraping projects. You can modify or extend Scrapy’s core functionalities, integrate third-party libraries, or even create custom middleware and pipelines to suit specific project requirements. This flexibility makes it ideal for users who want fine control over their scraping operations.
Cons
- Doesn’t Support Dynamic Content Rendering: Scrapy struggles with websites that use JavaScript to render dynamic content. Since it’s an HTML parser rather than a full browser, Scrapy cannot interact with JavaScript-driven elements.
- Steep Learning Curve: Scrapy is designed with developers in mind, which can make it challenging for beginners. It requires a solid understanding of Python, web scraping techniques, and asynchronous programming. For those new to web scraping or without strong technical skills, mastering Scrapy can take significant time and effort.
Rating
- Per Github star — 55.1k
Ease of use
⭐⭐⭐⭐⭐ (5/5)
Pricing
Free
Related: How to scrape websites with Scrapy and ScraperAPI.
7. Oxylabs Web Scraper API [AI-powered all-in-one scraping solution]

Who this is for: Oxylabs’ Web Scraper API is aimed at developers and data teams who need to collect large volumes of web data from complex websites. It consolidates multiple scraping tasks, including proxy management, CAPTCHA handling, JavaScript rendering, and data parsing into a single platform, reducing the need to maintain custom-built scrapers.
Why you should use it: Oxylabs’ Web Scraper API is an all-in-one web data collection solution that covers every stage of web scraping. It runs on a large infrastructure of 177M+ proxies across 195 countries and includes AI-powered features like OxyCopilot, which can generate scraping code and parsing instructions from plain English requests.
The API can reliably handle complex targets, including JavaScript-heavy websites with strong anti-bot protections. Data can be returned as structured JSON or raw HTML, and there are dedicated scrapers for commonly targeted websites.
Pros
- Complete All-in-One Platform: Eliminates task juggling by combining proxy management, CAPTCHA bypassing , JavaScript rendering, and data parsing in one integrated solution.
- OxyCopilot AI Assistant: Generates code and parsing instructions from plain English descriptions, making complex scraping accessible even to beginners.
- Highly Scalable: With 177M+ proxies spanning 195 countries, Oxylabs offers exceptional global coverage and precise geo-targeting capabilities.
- Advanced Bypassing: Oxylabs uses ML-driven proxy selection, AI-powered fingerprinting, and unique HTTP headers to bypass advanced anti-bot measures.
- Pay-Per-Success Model: This service charges only for successfully delivered results, making it cost-effective and predictable for budget planning.
Cons
- Premium Pricing: Oxylabs is a premium solution that may be expensive for small businesses or occasional use, unless you take a 7-day free trial.
Ratings
- G2 rating – 4.5
- Capterra – 4.7
Ease of use
⭐⭐⭐⭐⭐ (5/5)
Pricing
Oxylabs offers a free trial of the Web Scraper API, no credit card required. Once you decide to go premium, you can choose from flexible pricing plans based on successful results rather than bandwidth, making it easy to predict costs:
| Plan | Pricing | Results | Rate limit | Cost per 1K results (without JS rendering) | Cost per 1K results (with JS rendering) |
| Micro | $49 | Up to 98,000 | 50 requests/s | Amazon: $0.50 Google: $1.00 Other: $1.15 | $1.35 |
| Starter | $99 | Up to 220,000 | 50 requests/s | Amazon: $0.45 Google: $0.90 Other: $1.10 | $1.30 |
| Advanced | $249 | Up to 622,500 | 50 requests/s | Amazon: $0.40 Google: $0.80 Other: $0.95 | $1.25 |
Enterprise plans range from $499 (Venture) to $10,000+ (Custom) for high-volume operations with Dedicated Account Managers.
Related: Explore some of the best Oxylabs alternatives.
8. Diffbot [computer vision-based scraping tool]
Who this is for: Diffbot is an enterprise-level solution for companies with highly specified data crawling and screen scraping needs, particularly those who scrape websites that often change their HTML structure.
Why you should use it: Diffbot is different from most web page scraping tools in that it uses computer vision (instead of HTML parsing) to identify relevant information on a page. This means that even if a page’s HTML structure changes, your web scrapers will not break as long as the page looks the same visually. This is an incredible feature for long-running mission-critical web scraping jobs.
Diffbot is pricey (the cheapest plan is $299/month), but they do a great job offering a premium service that may make it worth it for large customers.
Pros
- Automated Data Extraction with AI: Diffbot uses AI to analyze and extract structured data from unstructured web pages, eliminating the need for manual coding. It can automatically detect and extract specific content types such as articles, products, images, etc. This makes it highly efficient for large-scale data extraction projects without needing to design custom scrapers.
- Supports Dynamic Content: Unlike some web scraping tools, Diffbot is capable of handling dynamic content generated by JavaScript. This is particularly useful for websites that load content dynamically or rely on client-side rendering.
- Rich API Support: Diffbot offers multiple APIs for different data extraction needs, including its Knowledge Graph API, which allows users to query and retrieve structured data across a variety of domains. It also offers Article, Product, and Image APIs, making it versatile for scraping different content types from websites.
Cons
- High Cost: Diffbot’s advanced capabilities and enterprise focus come at a premium price. For small-scale operations or individual users, the cost can be prohibitive. Its pricing model is usage-based, meaning higher volumes of requests can lead to significant costs, making it less suitable for low-budget or small projects.
Rating
- G2 rating — 4.9
- Capterra — 4.5
Ease of use
⭐⭐⭐⭐ (4/5)
Pricing
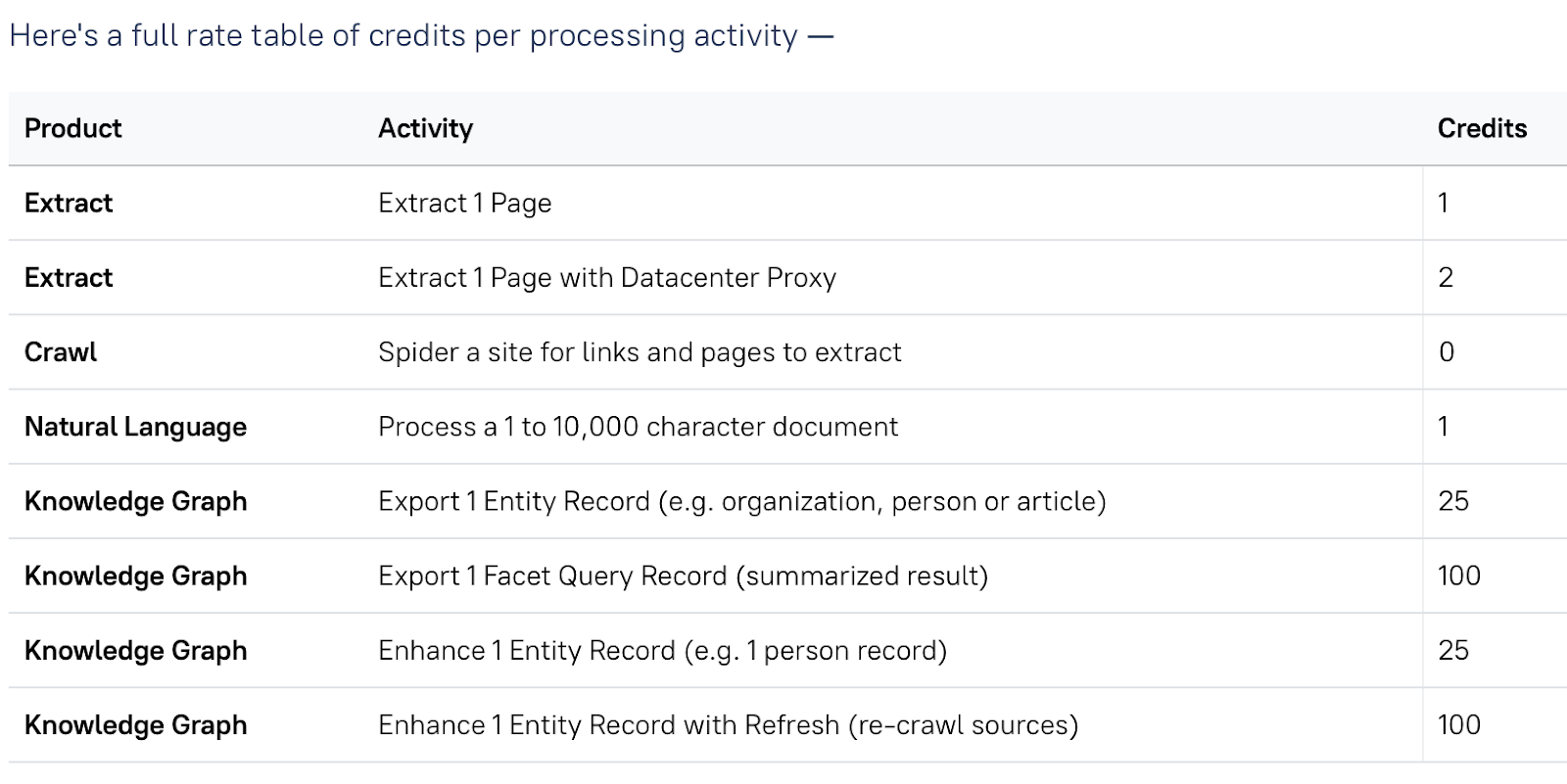
Diffbot’s pricing is similar to that of ScraperAPI as they are credit-based but Diffbot doesn’t bill per successful request.
As you can see in the table and image below, Diffbot costs $299 for 250,000 credits, which is equivalent to 250,000 pages [successful or not] at 1 credit per page.
On the other hand, ScraperAPI offers 1M API credits for as little as $149, giving you access to 1M successful requests/pages.
| Plan | Pricing | Credit |
| Free | Free | 10,000 Credits ($0 per credit) |
| Startup | $299 | 250,000 Credits ($0.001 per Credit) |
| Plus | $899 | 1,000,000 Credits ($0.0009 per Credit) |
| Enterprise | Custom | Custom |
Related: Explore some of the best Diffbot alternatives.
9. Cheerio [HTML parser for Node.js]
Who this is for: NodeJS developers who want a straightforward way to parse HTML. Those familiar with jQuery will immediately appreciate the best JavaScript web scraping syntax available.
Why you should use it: Cheerio offers an API similar to jQuery, so developers familiar with jQuery will immediately feel at home using Cheerio to parse HTML. It is blazing fast and offers many helpful methods for extracting text, HTML, classes, IDs, etc.
It is by far the most popular HTML parsing library written in NodeJS and probably the best NodeJS or JavaScript web scraping tool for new projects.
Pros
- Lightweight and Fast: Cheerio is a fast and efficient library for parsing and manipulating HTML and XML. Since it doesn’t render JavaScript or simulate a browser, it operates with minimal overhead, making it ideal for tasks that only involve static HTML content.
- jQuery-like Syntax: One of Cheerio’s standout features is its jQuery-like syntax, which makes it easy for developers familiar with jQuery to start using Cheerio quickly. The jQuery-style manipulation of DOM elements makes scraping and extracting data straightforward and intuitive.
- Flexible and Extensible: You can easily integrate Cheerio with other tools and APIs. Its modular nature allows it to fit into custom scraping pipelines, making it adaptable for a variety of web scraping needs.
Cons
- Need for Additional Tools for More Complex Scraping: While Cheerio is lightweight and efficient for basic scraping tasks, handling more complex scenarios like interacting with dynamic elements or bypassing anti-scraping measures requires combining it with more advanced tools. This adds complexity to the scraping setup and workflow.
- Limited Support for JavaScript-Heavy Websites: Cheerio does not execute JavaScript, so any content that depends on client-side JavaScript execution will not be captured. This limitation requires integrating it with additional tools like Puppeteer or Selenium, which can simulate a real browser environment.
Ease of use
⭐⭐⭐⭐ (4/5)
Rating
- Github star — 29.4k
Pricing
Free
Related: How to scrape HTML tables using Axios and Cheerio.
10. BeautifulSoup [HTML parser for Python]

Who this is for: Python developers who just want an easy interface to parse HTML and don’t necessarily need the power and complexity that comes with Scrapy.
Why you should use it: Like Cheerio for NodeJS developers, BeautifulSoup is the most popular HTML parser for Python developers. It’s been around for over a decade now and is extremely well documented, with many web parsing tutorials teaching developers to use it to scrape various websites in both Python 2 and Python 3. If you are looking for a Python HTML parsing library, this is what you want.
Pros
- Easy to Use and Learn: BeautifulSoup has a simple and intuitive API, making it accessible to both beginners and experienced developers. It allows you to easily parse HTML and XML documents and extract data with minimal code.
- Flexible with Parsers: BeautifulSoup is compatible with multiple parsers, such as Python’s built-in HTML parser, lxml, and html5lib. This flexibility allows you to choose the parser that best suits their needs, whether it’s for speed or completeness in handling poorly formatted HTML.
- Integration with Other Libraries: BeautifulSoup integrates well with other Python libraries, such as requests and lxml, making it easy to set up comprehensive scraping pipelines for retrieving and processing data from websites.
- Handles Imperfect HTML: BeautifulSoup is known for its robustness in handling poorly structured or broken HTML. It automatically corrects errors in HTML documents, making it easier to scrape websites with inconsistent markup.
Cons
- No JavaScript Support: BeautifulSoup cannot handle websites that rely heavily on JavaScript to load content. Since it works on static HTML, dynamic JavaScript-generated content will be inaccessible without integrating additional tools like Selenium.
- Manual Effort Required for Complex Tasks: BeautifulSoup works well for simple HTML parsing tasks but requires more manual coding to handle complex tasks like pagination, managing proxies, or bypassing anti-scraping measures.
Ease of use
⭐⭐⭐⭐⭐ (5/5)
Rating
- G2 rating — 4.4
Pricing
Free
Related: Scraping HTML websites with BeautifulSoup and ScraperAPI.
11. Puppeteer [Headless Chrome API for Node.js]
Who this is for: Puppeteer is a headless Chrome API for NodeJS developers who want granular control over their scraping activity.
Why you should use it: Puppeteer is an open-source tool that is completely free. It is well-supported, actively developed, and backed by the Google Chrome team. It quickly replaces Selenium and PhantomJS as the default headless browser automation tool.
It has a well-considered API and automatically installs a compatible Chromium binary as part of its setup process, so you don’t have to keep track of browser versions yourself.
While it’s much more than just a web crawling library, it’s often used to scrape website data from sites that require JavaScript to display information.
It handles scripts, stylesheets, and fonts just like a real browser. While it is an excellent solution for sites that require JavaScript to display data, it is also very CPU- and memory-intensive. So, using it for sites where a full-blown browser is unnecessary is not a great idea. Most of the time, a simple GET request should do the trick!
Pros
- Headless Browser Automation: Puppeteer allows you to control Chrome or Chromium in a headless mode, making it ideal for automation tasks like web scraping, UI testing, and generating PDFs from web pages.
- Cross-Platform: Puppeteer works on multiple platforms (Linux, macOS, Windows) and supports both headless and non-headless modes, making it versatile for a range of use cases, from local development to deployment in cloud environments.
Cons
- Resource Intensive: Running headless Chrome instances can be resource-heavy, especially when scaling up scraping jobs or automation tasks. It requires more CPU and memory compared to lightweight tools like Cheerio or non-browser-based scrapers.
- Manual Setup for Advanced Use Cases: Puppeteer doesn’t have built-in scheduling, data extraction templates, or data storage functionalities. You need to build these processes manually, which can increase the complexity of using the tool for extensive projects.
- Lacks Built-In Scraping Features: Puppeteer is a general-purpose browser automation tool and lacks specific web scraping optimizations (e.g., handling CAPTCHAs or IP rotation). For scraping large, protected websites, you’ll need additional tools or services for anti-scraping bypass techniques like ScraperAPI.
Rating
- Github star — 90.6k
Ease of use
⭐⭐⭐⭐⭐ (5/5)
Pricing
Free
Related: Scraping Amazon with Puppeteer and ScraperAPI.
12. Mozenda
Who this is for: Enterprises looking for a cloud-based, self-serve web page scraping platform need look no further. With over 7 billion pages scraped, Mozenda has experience serving enterprise customers worldwide.
Why you should use it: Mozenda sets itself apart with its customer service (providing both phone and email support to all paying customers). The platform is highly scalable and will allow for on-premise hosting as well. Like Diffbot, it is a bit pricey, with its lowest plan starting at $250/month.
Pros
- User-Friendly Interface: Mozenda is designed for non-technical users, featuring an intuitive point-and-click interface that simplifies the process of setting up and running scraping jobs without the need for coding.
- Automation and Scheduling: Mozenda supports scheduling and automating scraping tasks, which allows you to set recurring jobs and scrape data periodically without manual intervention.
- Data Export Flexibility: Mozenda offers a wide range of data export options, allowing you to export scraped data into multiple formats such as CSV, Excel, XML, or directly to a database. It also integrates with other data services.
Cons
- Pricing: Mozenda’s pricing is higher than some other scraping tools, which can be a drawback for small businesses or individuals with limited budgets. The cost increases with the number of pages scraped or the level of data complexity.
Rating
- G2 rating — 4.1
- Capterra — 4.4
Ease of use
⭐⭐⭐⭐ (4/5)
Pricing
Mozenda’s pricing is not clearly stated on their website, but as of a pricing model document released in 2018, which can also be seen below, Mozenda’s pricing is credit-based and quite expensive compared to competitors like ScraperAPI.
| Plan | Pricing | Credits | Storage |
| Basic | $99/month | < 20,000 | <1GB |
| Project | $300/month | 20,000 | 1GB |
| Professional | $400/month | 35,000 | 5GB |
| Enterprise | $450/month[billed annually] | 1,000,000+ annually | 50GB |
| High Capacity | $40K/year | Custom | Custom |
| On-Premise | Custom | Custom | Custom |
13. ScrapeHero Cloud [cloud-based online web scraper and done-for-you scraping services]
Who this is for: ScrapeHero is cloud-based and user-friendly, which makes it ideal if you’re not a programmer. You just need to provide the inputs and click ‘gather data.’ You’ve got actionable data in JSON, CSV, or Excel formats.
Why you should use it: ScrapeHero has created a browser-based, automated scraping tool that lets you download anything you want on the Internet into spreadsheets with just a few clicks. It’s more affordable than their full services, and there’s a free trial. It uses pre-built crawlers with auto-rotating proxies. Real-time APIs scrape data from some of the largest online retailers and services, including maps, product pricing, the latest news, and more. This data-as-a-service tool is perfect for businesses, especially those interested in AI.
Pros
- Customizable Solutions: ScrapeHero has fully customizable web scraping solutions tailored to the specific needs of businesses. This allows you to gather precisely the data they need, regardless of website complexity or scale.
- No Coding Required: ScrapeHero is user-friendly and doesn’t require technical skills. Businesses can extract custom data without needing in-house developers or technical expertise.
Cons
- Higher Cost for Custom Solutions: While ScrapeHero offers a range of pricing plans, its custom data scraping services can be expensive compared to DIY tools or platforms, particularly for businesses with smaller budgets or limited scraping needs.
- Limited Self-Service Features: If you are looking for a self-service tool to set up and run scraping jobs manually, ScrapeHero might not be ideal. It’s designed more for managed services, which can limit flexibility for those wanting full control over their scraping processes.
Rating
- Trustpilot rating — 3.7
- G2 rating — 4.6
- Capterra — 4.7
Ease of use
⭐⭐⭐⭐ (4/5)
Pricing

From the image above, you can see that the ScrapeHero pricing model is based on the number of pages you want to scrape. This makes it cost-effective when you want to scrape a smaller number of pages. On the other hand, ScraperAPI offers more API requests at a lower starting price, making it a better option for large scraping projects.
14. Webscraper.io [Point-and-click Chrome extension for web scraping]
Who this is for: Another user-friendly option for non-developers, WebScraper.io, is a simple Google Chrome browser extension. It’s not as full-featured as the other web scraping tools on this list, but it’s an ideal option for those who work with smaller amounts of data and don’t need a lot of automation.
Why you should use it: WebScraper.io helps users set up a sitemap to navigate a given website and precisely what information it will scrape. The additional plugin can handle multiple JS and Ajax pages at a time, and developers can build their scrapers to extract data directly into CVS from the browser or to CVS, XLSX, and JSON from Web Scraper’s cloud. You can also schedule regular scrapes with regular IP rotation. The browser extension is free, but you can try their paid services with a free trial.
Pros
-
- Cloud-Based Scraping: Webscraper.io is a browser-based data scraping tool that enables you to run scraping tasks in the background without tying up local resources. This also allows you to scrape large amounts of data efficiently.
- Affordable Pricing: Webscraper.io has various pricing plans, including a free plan, making it accessible for users with different needs and budgets. This allows you to use the platform without significant upfront costs.
Cons
- Limited to Chrome Extension: Webscraper.io is only available as a Chrome extension, limiting its usability. It also lacks a dedicated desktop or standalone application, which could be a drawback if you don’t use Chrome.
- Free Plan Limitations: While the free plan is useful, it significantly restricts the number of pages and data scraped. For large-scale projects, you need to opt for one of the paid plans.
Rating
- Trustpilot rating — 4.4
- G2 — 4.7
Ease of use
⭐⭐⭐(3/5)
Pricing
Webscraper.io is one of the most affordable web scraping tools out there. It has a free plan a starting price of $50. This pricing is based on cloud credit, where 1 cloud credit = 1 page.
| Plan | Price | Cloud Credit |
| Browser Extension | Free | Nill (local use only) |
| Project | $50 | 5,000 |
| Professional | $100 | 20,000 |
| Business | $200 | 50,000 |
| Scale | $200+ | Unlimited |
15. Kimura
Who this is for: Kimura is an open-source web scraping framework written in Ruby. It makes getting a Ruby web scraper up and running incredibly easy.
Why you should use it: Kimura is quickly becoming recognized as the best Ruby web scraping library. It’s designed to work with headless Chrome/Firefox, PhantomJS, and normal GET requests out-of-the-box. Its syntax is similar to Scrapy, and developers writing Ruby web scrapers will love the nice configuration options to set a delay, rotate user agents, and set default headers.
Pros
- Ruby-Based: Kimurai is built in Ruby, which is advantageous for developers familiar with the Ruby programming language. It provides a framework for writing web scrapers in Ruby, making it easy for Ruby developers to integrate scraping into their projects.
- Multi-Browser Support: Kimurai supports multiple browsers, including headless browsers like Puppeteer and Selenium. This flexibility allows users to scrape both static and dynamic websites effectively.
- Integrated Web Scraping Tools: Kimurai has built-in scraping tools like session management, automatic retries, request delays, and proxy support. This reduces the need to manually integrate additional tools or libraries, simplifying the scraping process.
- Open Source: Being open-source, Kimurai is free to use, and its source code is accessible for modification, making it a cost-effective solution for developers looking to create web scraping applications.
Cons
- Ruby Ecosystem Limitation: Kimurai is built in Ruby, a less commonly used language for web scraping compared to Python. This limits its community support and available resources, especially compared to widely used scraping frameworks like BeautifulSoup in Python.
- Limited Documentation: Although Kimurai is a powerful tool, its documentation is not as extensive as other popular frameworks, making it harder for newcomers to get started.
Rating
- Github star — 1k
Ease of use
⭐⭐⭐⭐ (3/5)
Pricing
Free
16. Goutte
Who this is for: Goutte is an open-source web crawling framework written in PHP, which makes it super useful for developers who want to extract data from HTML/XML responses using PHP.
Why you should use it: Goutte is a very straightforward, no-frills framework that many consider the best PHP web scraping library. It’s designed for simplicity, handling most HTML/XML use cases without too much additional cruft.
It also seamlessly integrates with the excellent Guzzle requests library, which allows you to customize the framework for more advanced use cases.
Pros
- PHP Integration: As a PHP-based tool, Goutte is a great option for developers already familiar with the PHP ecosystem. It integrates well with PHP applications and can be used within existing frameworks like Laravel or Symfony.
- Headless Scraping: Goutte doesn’t require a browser engine, which makes it much faster and less resource-intensive than browser-based scrapers like Puppeteer or Selenium. It’s efficient for scraping static websites that do not heavily rely on JavaScript.
- Uses Symfony Components: Goutte utilizes powerful Symfony components like DomCrawler and BrowserKit, making it a robust option for navigating and scraping HTML content programmatically. This allows users to easily simulate user actions like form submissions, link clicking, and session management.
- Good for Static Sites: Goutte excels at scraping static content, so for sites that don’t rely on JavaScript to load data dynamically, Goutte performs exceptionally well in terms of speed and efficiency.
Cons
- Limited JavaScript Support: Goutte does not support JavaScript rendering, which means it is ineffective for scraping dynamic websites that use JavaScript for loading content. This limitation makes it unsuitable for scraping modern single-page applications (SPAs) or JavaScript-heavy sites.
- PHP Dependency: Being a PHP-based tool limits its use in PHP environments. This may not be ideal for developers working in other languages or those who prefer a more language-agnostic approach to web scraping, such as using Python with Scrapy or BeautifulSoup.
- Not Ideal for Large-Scale Scraping: While Goutte is efficient for smaller scraping tasks, it is not optimized for handling large-scale projects requiring high concurrency or distributed scraping across multiple machines. More robust frameworks like Scrapy or Puppeteer are better suited for such projects.
Rating
- Github star — 9.3k
Ease of use
⭐⭐⭐⭐ (3/5)
Pricing
Free
Why is Scraping Web Data so Important?
Outdated insights push a company to allocate resources ineffectively or miss emerging opportunities. Imagine relying on FMCG pricing data from the week before a holiday to create your pricing for next month.
Web data can be the key to increasing your sales and/or productivity. The modern-day Internet is extremely noisy – users create a mind-blowing 2.5 quintillion bytes of data daily. Whether you’re just about to launch your dream project or you’ve owned your business for decades, the information in the data helps you draw potential customers away from your competitors and keep them coming back.
Web scraping, or extracting valuable data from the Internet and converting it into a useful format (like a spreadsheet), is crucial to keeping your business or product from falling behind.
Web data can tell you almost everything you need to know about potential consumers, from the average prices they’re paying to the must-have features of the moment. However, the sheer amount of data on potential customers means that you could spend the rest of your life manually extracting data, and you would never catch up. That’s where automated scraping tools come in. The process of finding them can be highly intimidating, however.
Using the best web scraping tools is essential for obtaining quality data, so you want to ensure you get the best tools for the job.
Data scraping challenges
When attempting to extract data, businesses often need help overcoming obstacles that require technical expertise and strategic problem-solving. One of the first hurdles is obtaining the correct page source.
Websites today are often dynamic, with content generated on the fly through JavaScript. This means that simply requesting a page’s HTML isn’t enough. We’ve seen instances where scraping efforts produced data that was either incomplete or incorrect, all due to not handling the JavaScript rendering properly.
Related: Learn how to scrape dynamic content from large sites with Python.
Another significant challenge arises from websites actively trying to prevent scraping. Many sites deploy measures such as CAPTCHA tests, IP blocking, or content that only appears after user interaction, designed to thwart automated data extraction. Developers have had to find ways to mimic human behavior, such as introducing random delays or rotating IP addresses, to get the scraper past these defenses.
Even after overcoming these technical barriers, the work doesn’t end there. Data extracted from different sources often arrives in varying formats, requiring extensive cleaning and normalization before it’s usable. Long-term issues include site layouts changing frequently, breaking scripts that once worked perfectly.
Not all web data is fair game for scraping, and businesses must navigate a complex legal landscape of regulations and site-specific terms of service. The potential for legal repercussions is real, and it’s an area that requires careful attention.
Without constant monitoring, a tool that once provided valuable insights can become obsolete, leaving businesses blind to essential market shifts.
What factors should you consider when selecting web scraping tools?
The selection process must be driven by specific technical and practical criteria when evaluating potential web scrapers to add to your arsenal.
The following factors should be scrutinized:
- Data Extraction Capabilities: A good web scraping tool supports various data formats and can extract content from various web structures, including static HTML pages and dynamic sites using JavaScript.
- Ease of Use: Evaluate the tool’s learning curve, user interface, and available documentation. Those using it should understand the tool’s complexity.
- Scalability: Consider how well the tool handles large-scale data extraction. Scalability in both performance and the ability to adapt to increasing volumes of data or requests is critical.
- Automation Features: Examine the degree of automation available. Look for scheduling capabilities, automated handling of CAPTCHA, and the ability to manage cookies and sessions automatically.
- IP Rotation and Proxy Support: The tool should provide robust IP rotation and proxy management support to avoid being blocked.
- Error Handling and Recovery: Investigate how the tool manages errors, such as broken connections or unexpected site changes.
- Integration with Other Systems: Determine if the tool integrates seamlessly with other systems and platforms, such as databases, cloud services, or data analysis tools. Compatibility with APIs can also be a significant advantage.
- Data Cleaning and Processing: Look for built-in or easily integrated data cleaning and processing capabilities to streamline the workflow from raw data to usable information.
Data Management Post-Scraping
Post-scraping, managing data is as critical as extraction. Delivering it in usable formats like CSV or JSON is necessary for integration with business systems. At ScraperAPI, we’ve designed dedicated endpoints for popular websites like Amazon, Walmart, and Google to turn raw HTML into ready-to-use data points.
Storage must be scalable and secure, accommodating large datasets with ease. Cleaning is essential to remove errors and irrelevant content, ensuring accuracy.
Related: Data cleaning 101 for web scraping.
Finally, integration with existing systems is key for actionable insights, aligning data formats with the needs of analytical tools or CRM systems. Efficient management turns raw data into a valuable asset, ready to support business strategies.
Final thoughts: What is the best web scraping tool?
The open web is by far the most significant global repository for human knowledge, and there is almost no information that you can’t find through extracting web data. Many tools are available because people of various technical abilities and know-how do web scraping. There are web data scraping tools that service everyone, from people who don’t want to write any code to seasoned developers just looking for the best open-source solution in their language.
There isn’t one best web scraping tool—it all depends on your needs. Hopefully, this list of scraping tools has helped you identify the best web data scraping tools and services for your specific projects or businesses.
Plenty of the above scraping tools offer free or reduced-cost trial periods, so you can ensure they work for your business use case. Some of them will be more reliable and effective than others. If you’re looking for a tool that can handle data requests at scale and at a good price, reach out to a sales rep to ensure they’ll be able to deliver – before signing any contracts.
