Go allows developers to create complicated projects with a simpler syntax than C, but with almost the same efficiency and control.
Its simplicity and efficiency is why we decided to add Golang to our web scraping beginners series and show you how to use it to extract data at scale.
Why Use Go Over Python or JavaScript for Web Scraping?
If you’ve followed our series, you’ve seen how easy web scraping is with languages like Python and JavaScript, so why should you give Go a shot?
There are three main reasons for choosing Go over other languages:
- Go is a statically typed language, making it easier to find errors without running your program. Integrated Development Environments (IDEs) will highlight errors immediately and even show you suggestions to fix them.
- IDEs can be more helpful the more they understand the code, and because we declare the data types in Go, there’s less ambiguity in the code. Thus, IDEs can provide better auto-complete features and suggestions than in other languages.
- Unlike Python or JavaScript, Go is a compiled language that outputs machine code directly, making it faster than Python. In an experiment run by Arnesh Agrawal, Python (using the Beautiful Soup library) took almost 40 minutes to scrape 2000 URLs, while Go (using the Goquery package) took less than 20 minutes.
In summary, Go is an excellent option if you need to optimize scraping speed or if you’re looking for a statically typed language to transition to.
Web Scraping with Go
For this project, we’ll scrape the Jack and Jones shoe category page to extract product names, prices, and URLs before exporting the data into a JSON file using Go’s web scraping library Colly.
A consideration: We’ll try to explain every step of the way as detailed as possible, so even if you don’t have experience with Go, you’ll be able to follow along. However, if you still feel lost while reading, here’s a great introduction to Go to watch beforehand.
1. Setting Up Our Project
We first need to head to https://go.dev/dl/ and download the right version of Go based on our operating system. In our case, we’ll pick the ARM64 version as we’re using a MacBook Air M1.

Note: You can also use Homebrew in MacOS or Chocolatey in Windows to install Go.
Once the download is complete, follow the instructions to install it on your machine. With it installed, let’s create a new directory named go-scraper and open it on VScode or your preferred IDE.
Note: Open the terminal and enter the go version command. If everything goes well, it will log the version like this:

For this tutorial, we’ll be using VScode to write our code, so we’ll also download Go’s VScode extension for a better experience.
Next, open the terminal and type the following command to create or initialize the project: go mod init go-scraper.
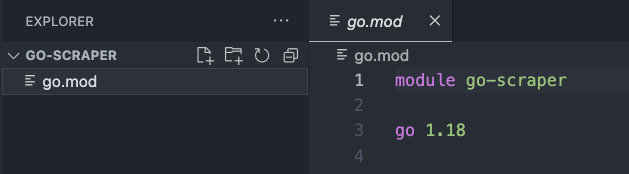
In Go, “a module is a collection of Go packages stored in a file tree with a go.mod file at its root.” The command above – go mod init – tells Go that the directory we’re specifying (go-scraper) is the module’s root.
Without leaving the terminal, let’s create a new jack-scraper.go file using: touch jack-scraper.go and – using the command found on Colly’s documentation – go get -u github.com/gocolly/colly/... to install Colly.
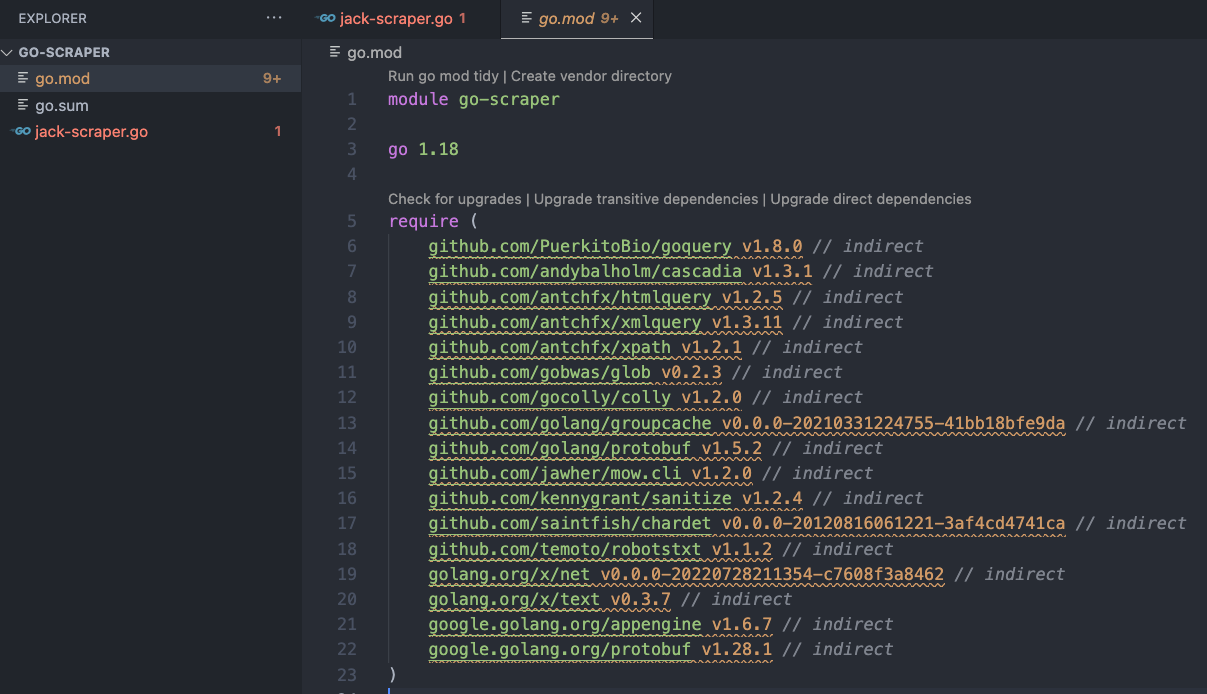
All the dependencies downloaded were added to the go.mod file and a new go.sum file – which may contain hashes for multiple versions of a module- was created.
Now we can consider our environment set!
2. Sending HTTP Requests with Colly
At the top of our jack-scraper.go file, we’ll add our package’s name, which as a convention, we’ll name main:
</p>
package main
<p>And then import the dependencies to the project:
</p>
import (
"github.com/gocolly/colly"
)
<p>Note: Due to Go’s typed nature, VScode will tell us there’s an error with your import. Basically, it’s telling us that we imported a dependency, but we’re not using it. This is one of the advantages of using Go, as we don’t need to run our code to find errors.
Something particular to Go is that we need to provide a starting point for the code to run. So we’ll create the main function, and all our logic will be inside it. For now, we’ll print “Function is working.”
</p>
func main() {
fmt.Println("Function is working")
}
<p>If everything went well it should return this:

You might have also noticed that a new package was imported. That’s because Go can tell we’re trying to use the .Println() function from the fmt package, so it automatically imported it. Handy, right?
To handle our request and deal with all callbacks necessary to extract the data, Colly uses a collector object. Initializing the collector is as simple as calling the .NewCollector() method from Colly and passing the domains we want to allow Colly to visit:
</p>
c := colly.NewCollector(
colly.AllowedDomains("www.jackjones.com"),
)
<p>On our new c instance, we can now call the .Visit() method to make colly send our request.
</p>
c.Visit("https://www.jackjones.com/nl/en/jj/shoes/"
<p>However, there are a few more things we need to add to our code before sending our collector out into the world. Let’s see what’s happening behind the scenes.
First, we’ll create a callback to print out the URL Colly is navigating to – this will become more useful as we scale our scraper from one page to multiple pages.
</p>
c.OnRequest(func(r *colly.Request) {
fmt.Println("Scraping:", r.URL)
})
<p>And then a callback to print out the status of the request.
</p>
c.OnResponse(func(r *colly.Response) {
fmt.Println("Status:", r.StatusCode)
})
<p>As we said before, the collector object is responsible for the callbacks attached to a collector job. So each of these functions will be called at various stages in the collector job cycle.
In our example, the .OnRequest() function is called right before the collector makes the HTTP request, while the .OnRespond() function will be called after a response is received.
Just for good measure, let’s also create an error handler before running the scraper.
</p>
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "nError:", err)
})
<p>To run our code, open a terminal and use the go run jack-scraper.go command.

Awesome, we got a beautiful 200 (successful) status code! We’re ready for phase 2, the extraction.
3. Inspecting the Target Website
To extract data from an HTML file, we need more than just access to the site. Each website has its own structure and we must understand it in order to scrape specific elements without adding noise to our dataset.
The good news is that we can quickly look at the site’s HTML structure by right-clicking on the page and selecting Inspect from the menu. It’ll open the Inspector tools, and we can start hovering on elements to see their positions in the HTML and attributes.
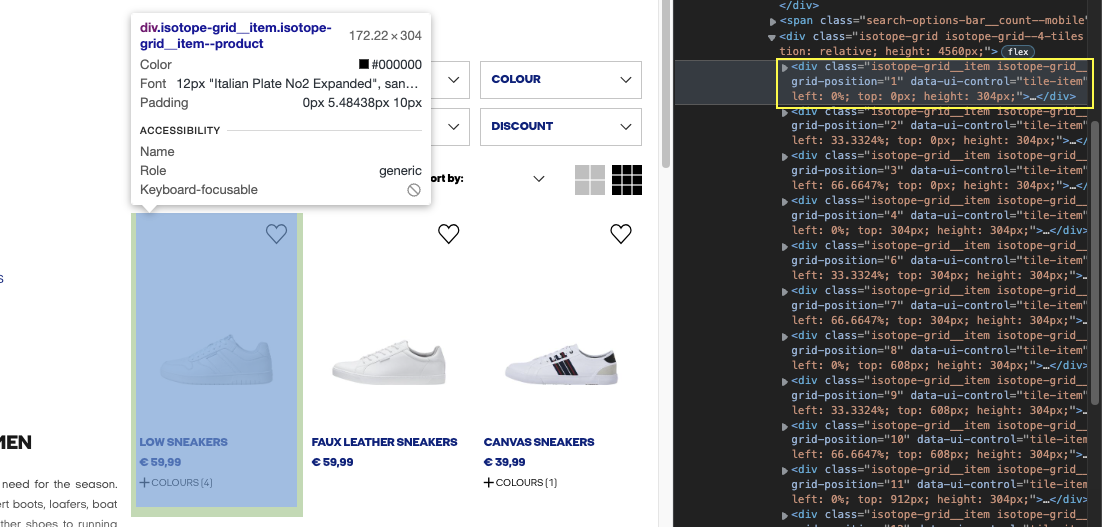
We use CSS selectors in web scraping (classes, IDs, etc.) to tell our scrapers where to locate the elements we want them to extract for us. Fortunately for us, Colly is based on the Goquery package, which provides Colly with a JQuery-like syntax to target these selectors.
Let’s try to grab the first shoe’s product name using the DevTools console to test the ground.
4. Using DevTools to Test Our CSS Selectors
If we inspect the element further, we can see that the name of the product is in a <a> tag with the class “product-tile__name__link”, wrapped between <header> tags.
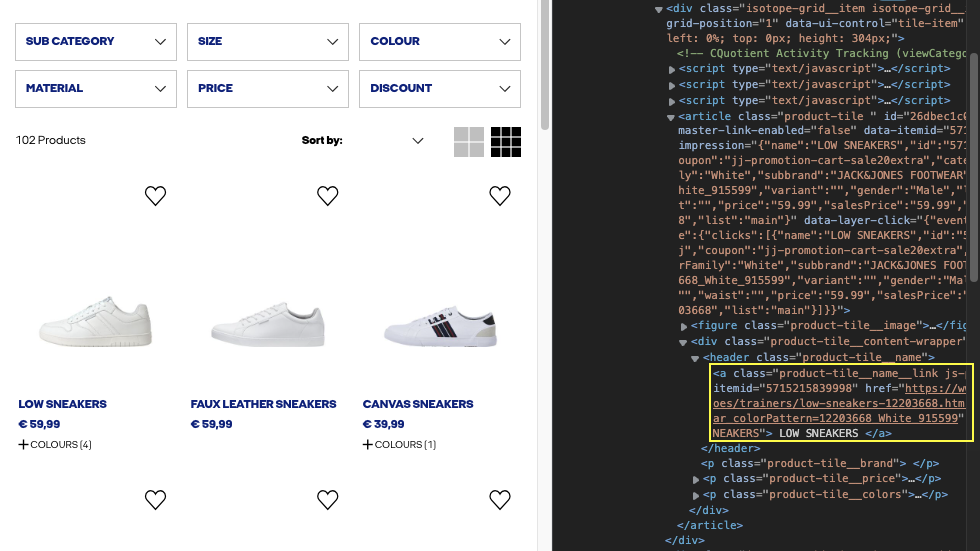
On our browser’s console, let’s use the document.querySelectorAll() method to find the that element.
document.querySelectorAll("a.product-tile__name__link.js-product-tile-link")
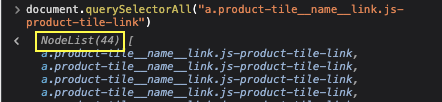
Yes! It returns 44 elements that match perfectly with the number of elements on the page.
The product’s URL is inside the same element, so we can use the same selector for it. On the other hand, after some testing, we can use “em.value__price” to pick the price.
5. Scraping All Product Names on the Page
If you’ve read some of our previous articles, you know we love testing. So, before extracting all our target elements, we’re first going to test our scraper by extracting all product names from the page.
To do so, Colly has a .OnHTML() function to handle the HTML from the response (there’s also an .OnXML() function you can use if you’re not sure if the response will be HTML or XML content).
</p>
c.OnHTML("a.product-tile__name__link.js-product-tile-link", func(h *colly.HTMLElement) {
fmt.Println(h.Text)
})
<p>Here’s a breakdown of what’s happening:
- We pass the main element we want to work with
a.product-tile__name__link.js-product-tile-linkas the first argument of theOnHTML()function. - The second argument is a function that will run when Colly finds the element we specified.
Inside that function, we told Colly what to do with the h object. In our case, it’s printing the text of the element.
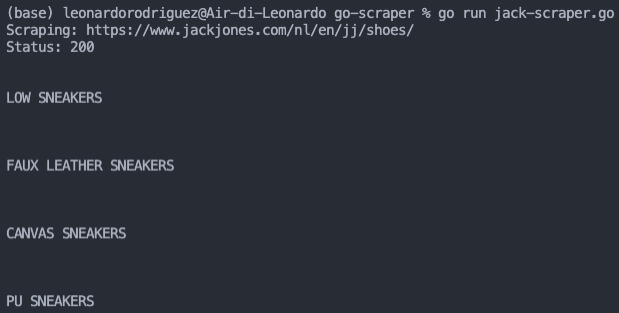
And yes, it’s working great so far. However, there’s a lot of empty space around our text, adding noise to the data.
To solve this problem, let’s get even more specific by adding the <header> element as our main selector and then looking for the text using the .ChildText() function.
</p>
c.OnHTML("header.product-tile__name", func(h *colly.HTMLElement) {
fmt.Println(h.ChildText("a.product-tile__name__link.js-product-tile-link"))
})
<p>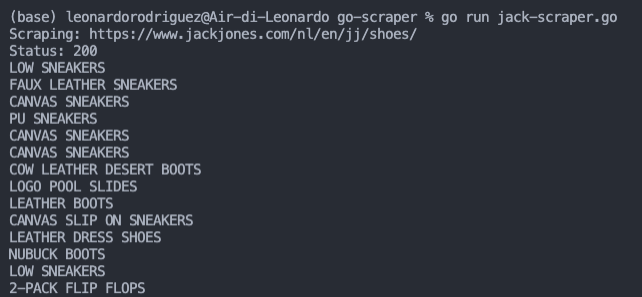
6. Extracting All HTML Elements
By now, we have a good grasp of the logic behind the OnHTML() function, so let’s scale it a little bit more and extract the rest of the data.
We begin by changing the main selector to the one that contains all the data we want:

Then, we go down the hierarchy to extract the name, price, and URL of each product:

Here’s how it translates to code:
</p>
c.OnHTML("div.product-tile__content-wrapper", func(h *colly.HTMLElement) {
name := h.ChildText("a.product-tile__name__link.js-product-tile-link")
price := h.ChildText("em.value__price")
url := h.ChildAttr("a.product-tile__name__link.js-product-tile-link", "href")
fmt.Println(name, price, url)
})
<p>For this function, we’re storing each element inside a variable to make it easier to work with later. For example, printing all the elements scraped to the console.
Note: When using the .ChildAttr() callback function, we need to pass the selectors of the element as a first argument (a.product-tile__name__link.js-product-tile-link) and the name of the attribute as the second (href).

We got a beautiful list of elements printed on the console but not quite the best format for analysis. Let’s solve that!
7. Export Data to a JSON File in Colly
Saving our data to a JSON file will be more useful than having everything on the terminal, and it’s not that hard to do, thanks to Go’s built-in JSON modules.
Creating a Structure
Outside the main function, we need to create a structure (struct) to group every data set (name, price, URL) into a single type.
</p>
type products struct {
Name string
Price string
URL string
}
<p>Structures let you combine different data types, so we have to define the data type for each element. We could also define the JSON field if we want, but it’s not mandatory, as in some cases we don’t know what these will be.
</p>
type products struct {
Name string 'json:"name"'
Price string 'json:"price"'
URL string 'json:"url"'
}
<p>TIP: for a cleaner look, we can group all fields sharing the same type in a single line of code like:
</p>
type products struct {
Name, Price, URL string
}
<p>Of course, there’s going to be an “unused” error message on our code because we haven’t, well, used the products struct anywhere. So, we’ll assign each scraped element to one of our fields in the struct.
</p>
c.OnHTML("div.product-tile__content-wrapper", func(h *colly.HTMLElement) {
products := products{
Name: h.ChildText("a.product-tile__name__link.js-product-tile-link"),
Price: h.ChildText("em.value__price"),
URL: h.ChildAttr("a.product-tile__name__link.js-product-tile-link", "href"),
}
fmt.Println(products)
})
<p>If we run our application, our data is now grouped, making it possible to pass each element as an individual “item” to the empty list we’ll later turn into a JSON file.

Adding Scraped Elements to a Slice
With our structure holding the product data, we’ll next send all of them to an empty Slice (instead of an Array like we would in other languages) to create a list of items we’ll export to the JSON file.
To collect the empty slice, add this code after the collector initiation code:
</p>
var allProducts []products
<p>Inside the .OnHTML() function, instead of printing our structure, let’s instead append all the items inside products to the Slice.
</p>
allProducts = append(allProducts, products)
<p>If we print the Slice out now, here’s the result:

You can see that each product information set is inside curly braces ({…}), and the entire Slice is inside brackets ([…]).
Writing the Slice into a JSON File
We already did all the heavy lifting we needed to do. From here on, Go has a very easy-to-use JSON module that’ll handle the writing for us:
</p>
//We pass the data to Marshal
content, err := json.Marshal(allProducts)
//We need to handle someone the potential error
if err != nil {
fmt.Println(err.Error())
}
//We write a new file passing the file name, data, and permission
os.WriteFile("jack-shoes.json", content, 0644)
}
<p>Save it, and the necessary dependencies will update:
</p>
import (
"encoding/json"
"fmt"
"os"
"github.com/gocolly/colly"
)
<p>Let’s run our code and see what it returns:
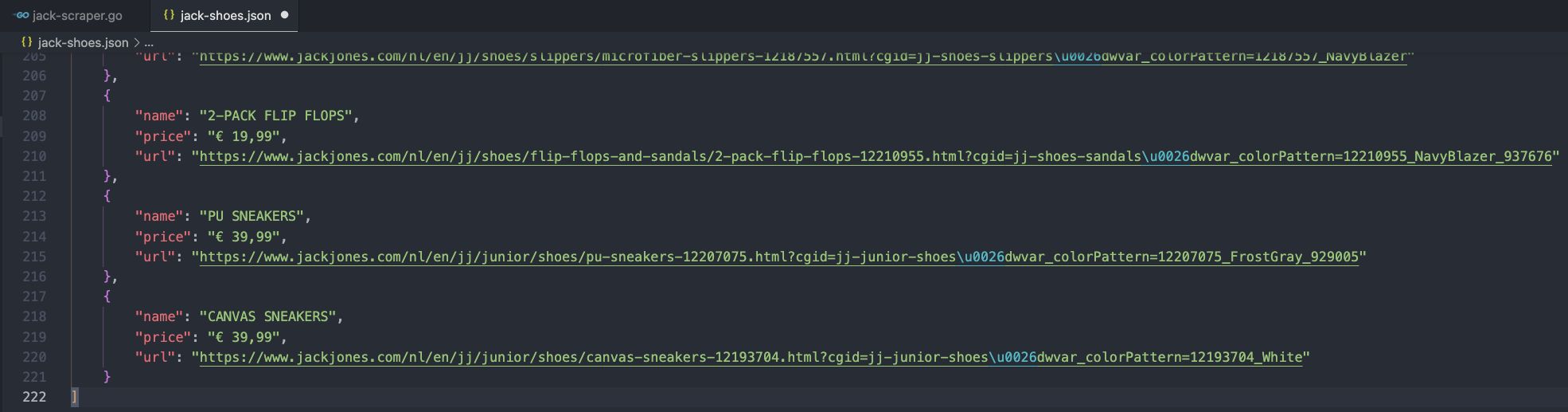
Note: When you open your file, it has all the data in a single line. To display your document as the image above, right-click on the window and select format document.
We could also print the length allProducts after creating the JSON file for testing purposes:
</p>
fmt.Println(len(allProducts))
<p>But we should be getting everything we want.
That said, a single page isn’t enough for most projects. In fact, in almost all projects like this, we’ll need to scrape multiple pages to gather as much information as possible. Luckily, we can scale our project with just a few lines of code.
8. Scraping Multiple Pages
If we scroll down to the bottom of the product list, we can see that J&J is using a numbered pagination on their category page.
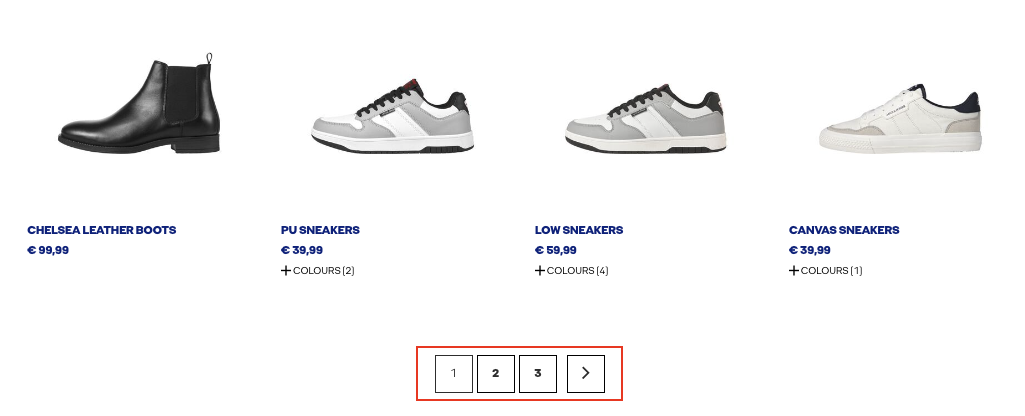
We could try to figure out how they construct their URLs and see if we can mimic it with a loop, but Colly has a more elegant solution, similar to how Scrapy navigates paginations.
</p>
c.OnHTML("a.paging-controls__next.js-page-control", func(p *colly.HTMLElement) {
nextPage := p.Request.AbsoluteURL(p.Attr("data-href"))
c.Visit(nextPage)
})
<p>In a new OnHTML() function, we’re targeting the next button on the menu.

On the internal function, we’re grabbing the value inside data-href (which contains the URL), storing it into a new variable (nextPage), and then telling our scraper to visit the page.
Running the code now, we’ll bring all product data from every page in the pagination.
As you can see, our Slice now contains 102 items.
9. Avoid Getting Your Colly Scraper Blocked
One thing we always have to consider when scraping the web is that most sites don’t like web scrapers because many developers have no regard for the websites they extract data from.
Imagine that you want to scrape thousands of pages from a site. Every request you send takes resources away from the real users, creating more expenses for the site’s owner and possibly hurting the user experience with slow load times.
That’s why we should always use web scraping best practices to ensure we’re not hurting our target sites.
However, there’s another side of the story. To prevent scrapers from accessing the site, more and more websites implement anti-scraping systems designed to identify and block scrapers.
Although scraping a few pages won’t raise any flags – in most cases – scraping multiple pages will definitely put your IP and scraper at risk.
To avoid these measures, we would have to create a function that changes our IP address, have access to a pool of IP addresses for our script to rotate between, create some way to deal with CAPTCHAs, and handle javascript pages – which are becoming more common.
Or we could just send our HTTP request through ScraperAPI’s server and let them handle everything automatically:
- First, we’ll only need to create a free ScraperAPI account to redeem 5000 free API credits and get access to our API key from the dashboard.
- For simplicity, we’ll delete the
colly.AllowedDomains("www.jackjones.com")setting from thecollector. - We’ll add the ScraperAPI endpoint to our initial
.Visit()function like this:<br> c.Visit("http://api.scraperapi.com?api_key={yourApiKey}&url=https://www.jackjones.com/nl/en/jj/shoes/") <p> - And make a similar change for how we visit the next page:
<br> c.Visit("http://api.scraperapi.com?api_key={yourApiKey}&url=" + nextPage) <p> - For it to work properly and avoid errors, we’ll need to change Colly’s 10 second default timeout to at least 60 seconds to give our scraper enough time to handle any headers, CAPTCHAs, etc. We’ll use the sample code from Colly’s documentation – but change the timeout from 30 to 60:
<br> c.WithTransport(&http.Transport{ DialContext: (&net.Dialer{ Timeout: 60 * time.Second, KeepAlive: 30 * time.Second, DualStack: true, }).DialContext, MaxIdleConns: 100, IdleConnTimeout: 90 * time.Second, TLSHandshakeTimeout: 10 * time.Second, ExpectContinueTimeout: 1 * time.Second, }) <p>
Add this code after creating the collector.
Running our code will bring back the same data as before. With the difference being that ScraperAPI will rotate our IP address for each request sent, look for the best “proxy + headers” combination to ensure a successful request, and handle any other complexities our scraper could encounter.

Colly will save all the data into a formatted JSON file that we can use in other applications or projects.
With just a few small changes to the code, you can scrape any website you need, as long as the information is live in the HTML file.
However, we can also configure our ScraperAPI endpoint to render JavaScript content before returning the HTML document. So unless the content is behind an event (like clicking a button), you should also be able to grab dynamic content without a problem.
Wrapping Up: Full Colly Web Scraper Code
Congratulations, you created your first Colly web scraper! If you’ve followed along, here’s how your codebase should look:
</p>
package main
import (
"encoding/json"
"fmt"
"net"
"net/http"
"os"
"time"
"github.com/gocolly/colly"
)
type products struct {
Name string 'json:"name"'
Price string 'json:"price"'
URL string 'json:"url"'
}
func main() {
c := colly.NewCollector()
c.WithTransport(&http.Transport{
DialContext: (&net.Dialer{
Timeout: 60 * time.Second,
KeepAlive: 30 * time.Second,
DualStack: true,
}).DialContext,
MaxIdleConns: 100,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
})
var allProducts []products
c.OnRequest(func(r *colly.Request) {
fmt.Println("Scraping:", r.URL)
})
c.OnResponse(func(r *colly.Response) {
fmt.Println("Status:", r.StatusCode)
})
c.OnHTML("div.product-tile__content-wrapper", func(h *colly.HTMLElement) {
products := products{
Name: h.ChildText("a.product-tile__name__link.js-product-tile-link"),
Price: h.ChildText("em.value__price"),
URL: h.ChildAttr("a.product-tile__name__link.js-product-tile-link", "href"),
}
allProducts = append(allProducts, products)
})
c.OnHTML("a.paging-controls__next.js-page-control", func(p *colly.HTMLElement) {
nextPage := p.Request.AbsoluteURL(p.Attr("data-href"))
c.Visit("http://api.scraperapi.com?api_key={yourApiKey}&url=" + nextPage)
})
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "nError:", err)
})
c.Visit("http://api.scraperapi.com?api_key={yourApiKey}&url=https://www.jackjones.com/nl/en/jj/shoes/")
content, err := json.Marshal(allProducts)
if err != nil {
fmt.Println(err.Error())
}
os.WriteFile("jack-shoes.json", content, 0644)
fmt.Println("Total products: ", len(allProducts))
}
<p>Web scraping is one of the most powerful tools to have in your data collection arsenal. However, remember that every website is built somewhat differently. Focus on the fundamentals of website structure, and you’ll be able to solve any problem that comes your way.
Until next time, happy scraping!