


Property listings come in and out daily. To keep up with this fast-paced property market, you need a reliable source of available properties in the area that can collect the data automatically. This is where a real estate web scraping tool comes in.
In this tutorial blog, we’ll show you how to build a real estate web scraper, starting from the required tools and how to set them up. But first, let’s discuss the benefits you’ll get from having your own real estate web scraping tool.
Web Scraping Benefits for Real Estate
Real estate agents, home buyers, and home sellers can all benefit from a variety of real estate websites. These websites provide useful information such as rates, photos, location, rooms, and more real estate industry data. These websites can also be used to locate business properties. The best part about these websites is that they provide real-time MLS listings and as a result, you may have access to a variety of real estate listings. Extracting real estate data manually can be a tedious task, so how do you access and use this data efficiently? A real estate web scraper does the trick.
Geotargeting
Some web scrapers such as ScraperAPI include extra beneficial features like geotargeting. This especially comes in handy with real estate web scraping since gathering location intelligence is critical for a real estate agency. These insights are hidden in the raw data of the real estate market, and gathering all of it manually would be difficult. To ensure your real estate web scraping requests come from a particular geographical region, all you have to do is enter some simple piece of code to hone in on specific location data you need.
Analyzing and Comparing Property Values
You want to receive the most precise estimate of the property’s value. Because most realtors rely on a single listing, such as the MLS, you can set yourself apart by using various data sources. Web data extraction can help by allowing you to fetch structured real estate data from any publicly available listing website. If the property is available online, you can use web scraping to get all of the data points about it. You can then utilize this information to support your price or better position your offer. Because online data provides a complete picture, you have a better chance of accurately estimating a property’s value.
Creating Property Lists For Clients
Real estate companies may now use web scraping to develop lists of possible buyers and sellers, automating lead generation and ensuring a consistent flow of property sales throughout the year. It’s particularly helpful to use real estate data API to provide a property list to the client that has accurate information and is catered to their interests.Compiled real estate industry data is hugely useful for creating property lists for clients, which shows the client that you’ve done your research and your real estate agency is highly credible.
Gaining Real Estate Industry Insights
The real estate market is always shifting and cycles. The task at hand is to determine where it is today and where it will be in the future. To properly value property and make investment decisions, it is necessary to understand market direction. The raw data of the real estate market contains this information, but it would be difficult for a single person to manually collect all of the data. That is why web scraping real estate data can be extremely beneficial by providing you with all of the data you require in a timely manner. Mining this data can help you see the market’s direction and reveal trends you wouldn’t have noticed otherwise.
Maintaining a Real Estate Aggregator
Web scraping is heavily used by real estate aggregators to acquire enormous volumes of real-time intelligence from a variety of data sources and show it on their one-stop-shop website for the benefit of consumers. Real estate data mining is a step in which a large volume of collected data is investigated in order to provide meaningful insights. To find patterns and trends, highly specialized tools and algorithms are usually used. This type of examined data can be used to determine the ideal moments to buy or sell, forecast market direction, change pricing tactics, and more once it is completed.
How To Build A Real Estate Web Scraping Tool
There are many tools and techniques you can use to build a real estate web scraper. You can build a JavaScript web scraper using Node.js or build a web scraping script using R and Rvest.
For this example, we’ll be using Python with Requests and Beautifulsoup because of its ease of use and low learning curve.
Requests will be used to send HTTP requests for the HTML of the page you’re interested in, while Beautifulsoup is used to parse and retrieve the necessary information.
If you’re a total beginner in web scraping, we recommend you to check out our tutorials on setting up a web scraper with Python and Beautiful Soup. You’ll learn the basics from installing the necessary tools to building your first web scraping program.
Without further ado, let’s start by installing all necessary dependencies:
1. Install Python, Requests, and Beautiful Soup
This is actually a really straightforward process.
First, go to Python’s official website and download the recommended version. You’ll notice that the site will automatically recognize your operating system, so just click on download and follow the installation instructions.

To verify Python has been installed correctly, open your terminal and type python -v.
As we’re already on the terminal, let’s download Requests and Beautiful Soup:
- Requests:
pip3 install requests. - Beautiful Soup:
pip3 install beautifulsoup4.
It will take a few minutes to download and install the dependencies but after that’s done, you’re ready for the next step.
2. Send an HTTP request using Requests
When you go to a URL, your browser sends a request to the server and then the server responds by sending the HTML and all necessary files for the browser to render the website.
This is exactly the behavior we want to imitate with our scraper because all the data we want to extract from a website is inside the HTML source.
First, create a folder called ‘real-estate-scraper-tutorial’ and open it using whatever editor you prefer (in our case, we’re using VS Code).
Inside the new folder, create a new file called ‘zillow_scraper.py’ and import the Requests library inside.
import requests
Now the fun part begins.
Zillow is one of those challenging sites to scrape. One of the reasons is because of the use of CAPTCHAs designed to differentiate between humans and bots.
To get access to the full content of the page through the response, we’ll need to add a few things:
- URL
- Headers
- Params
So let’s start by adding the following code to our scraper:
import requests
url = 'https://www.zillow.com/new-york-ny/fsbo/'
response = requests.get(url, headers=headers, params=params)
Find the Correct Headers and Params
In the code above, we’ve already defined the URL we’re trying to get access to. However, most likely, we’ll get blocked by a CAPTCHA as soon as the request hits the server.
For that, we need the header information to trick the machine.
Open the website on your browser and then open developer tools (we’re using chrome but you can use whichever browser you like). Then, click on the Network tab.
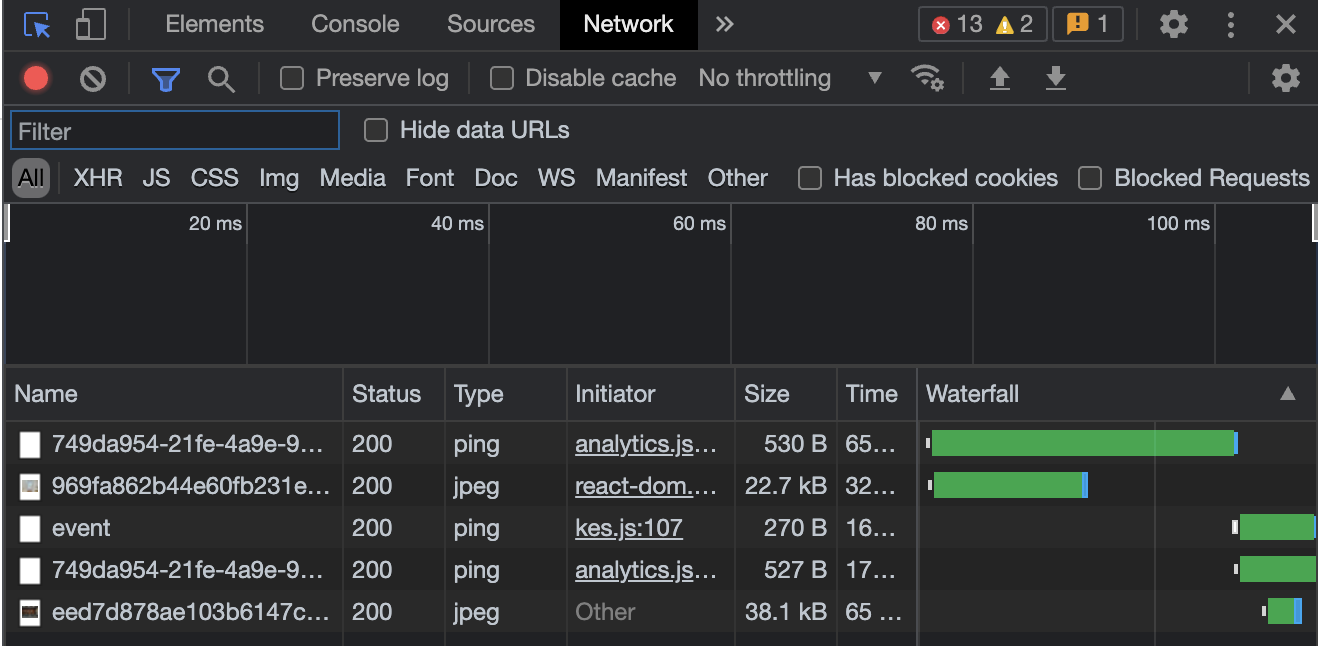
Lastly, clear the console and refresh the page. This time, a lot more information will be logged.
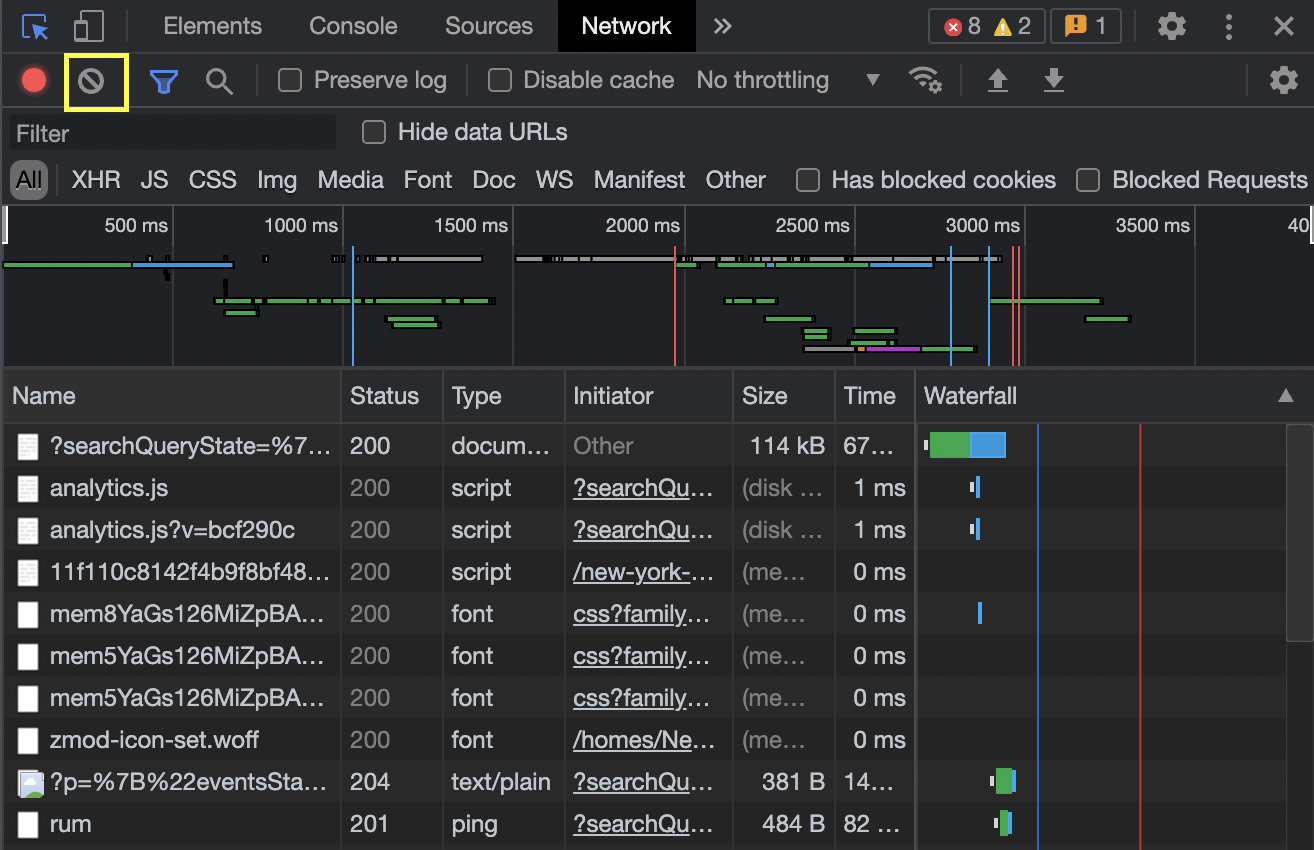
To get the headers, you need to find and click on the ‘?searchQueryState’ element. It will open the preview by default, so just click on the headers tab to access the right information.

Now, create a new variable called headers and add the headers from your browser:
For the Params, just scroll to the bottom and you’ll find the ‘Query String Parameters’ toggle. Copy the full searchQueryState and add it to a new variable called ‘params’.
params = {
'searchQueryState': '{"pagination":{},"mapBounds":{"west":-74.45174190039063,"east":-73.50417109960938,"south":40.364611350639585,"north":41.045454918005234},"regionSelection":[{"regionId":6181,"regionType":6}],"isMapVisible":false,"filterState":{"sort":{"value":"globalrelevanceex"},"fsba":{"value":false},"nc":{"value":false},"fore":{"value":false},"cmsn":{"value":false},"auc":{"value":false},"pmf":{"value":false},"pf":{"value":false},"ah":{"value":true}},"isListVisible":true}'
}
3. Test the Request to Make Sure it Works
All we want to know in this step is whether or not we’re receiving a 200 success status code from the server.
For that, we’ll print() our response variable:
print(response)
After running the script, you should see something like this on your terminal:

4. Structure the Scraper Into a Class and Define the Main Methods
Because we know it’s working, let’s give our scraper a better structure.
Create a class called EstateScraper and add the headers inside:
class EstateScraper():
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9,es;q=0.8',
'cache-control': 'max-age=0',
'cookie': 'zguid=23|%24749da954-21fe-4a9e-9d76-e519a78ba0c9; _ga=GA1.2.1600763508.1625590071; zjs_user_id=null; zjs_anonymous_id=%22749da954-21fe-4a9e-9d76-e519a78ba0c9%22; _pxvid=e6e22d59-de79-11eb-99fe-0242ac120008; _gcl_au=1.1.771124946.1625590072; __pdst=9ea7da3100ba4be5b11e3b1439647467; _fbp=fb.1.1625590072673.1861311414; _pin_unauth=dWlkPU1EZ3haV0ZtWldZdE5qZGtZaTAwTW1ZMUxXRmhZMkl0TkRrNU16VXdZbVppT0dRMA; FSsampler=377337126; zgsession=1|78736779-0639-4f0d-958f-454215385742; DoubleClickSession=true; g_state={"i_p":1627666314547,"i_l":3}; _gid=GA1.2.790590851.1627322052; KruxPixel=true; utag_main=v_id:017a7cb803fe006d9eafa8b9088802079001707100942$_sn:4$_se:1$_ss:1$_st:1627323853684$dc_visit:3$ses_id:1627322053684%3Bexp-session$_pn:1%3Bexp-session$dcsyncran:1%3Bexp-session$tdsyncran:1%3Bexp-session$dc_event:1%3Bexp-session$dc_region:us-east-1%3Bexp-session; KruxAddition=true; JSESSIONID=6BF35449AA3EB26BA2145DBBC2682D3B; _px3=f3ca1d08b30ece1cf0653f24bb91ac6f0a84c04af722dd9ae649dc27099763d1:PZxIxKTPRTGCUE99clC1hQa0g5WwvYCc/gMdeuMB1ygu+Ea08QO6Cg/dN8Fe41YcVeOee/pw+Sg78Gv2Qjqsug==:1000:Jlpok2s5u9PyWKRfj63CdEWDDQsjPAFfoPXnEv55JCamXF2zhfWLyh6wteDIGBjKPy6HkAmJBY6jRmgk2ROhq+qZ+SItOJ0Jc68WzlHr0O82i49GiMIfbqafTnsLIuSQBZv/ruFqk5ThTxh1r/Gzrf1NdfINYNsaH7m7DQ6V+pIi84TE6aTzl8rWiQyHguWM/9wynjgR9JLd/G44Vr5DYQ==; _uetsid=7cfdec40ee3a11eba052b7e44eba3808; _uetvid=e7a59800de7911ebaf025dd320c394a8; AWSALB=QBa76k4FjGb+xHkALAYIFKaZxi3riUccngDpBj07JjeFARwZikwRZWHziNRg9K3oG1JgF0/1EMNzBTTgjnZizipqHBClNoF6lpxIpL4kg+sY+6+EnvKMxkY4y5HC; AWSALBCORS=QBa76k4FjGb+xHkALAYIFKaZxi3riUccngDpBj07JjeFARwZikwRZWHziNRg9K3oG1JgF0/1EMNzBTTgjnZizipqHBClNoF6lpxIpL4kg+sY+6+EnvKMxkY4y5HC; search=6|1629931657362%7Crect%3D41.38326361172051%252C-73.08669063085938%252C40.02158272425184%252C-74.86922236914063%26rid%3D6181%26disp%3Dmap%26mdm%3Dauto%26p%3D1%26sort%3Ddays%26z%3D1%26pt%3Dpmf%252Cpf%26fs%3D1%26fr%3D0%26mmm%3D1%26rs%3D0%26ah%3D0%26singlestory%3D0%26housing-connector%3D0%26abo%3D0%26garage%3D0%26pool%3D0%26ac%3D0%26waterfront%3D0%26finished%3D0%26unfinished%3D0%26cityview%3D0%26mountainview%3D0%26parkview%3D0%26waterview%3D0%26hoadata%3D1%26zillow-owned%3D0%263dhome%3D0%26featuredMultiFamilyBuilding%3D0%09%096181%09%09%09%09%09%09',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
Now, we’ll define a fetch() method, paste our request in it, and return a response.
def fetch(self, url, params):
response = requests.get(url, headers=self.headers, params=params)
print(response)
return response
Note: We specified the variables url and params to the method. This will be important as we define the next method.
Lastly, we’ll define a run() method and add the URL and params under it while adding a new variable to the method:
def run(self):
url = 'https://www.zillow.com/homes/New-York,-NY_rb/'
params = {
'searchQueryState': '{"pagination":{},"mapBounds":{"west":-74.45174190039063,"east":-73.50417109960938,"south":40.364611350639585,"north":41.045454918005234},"regionSelection":[{"regionId":6181,"regionType":6}],"isMapVisible":false,"filterState":{"sort":{"value":"globalrelevanceex"},"fsba":{"value":false},"nc":{"value":false},"fore":{"value":false},"cmsn":{"value":false},"auc":{"value":false},"pmf":{"value":false},"pf":{"value":false},"ah":{"value":true}},"isListVisible":true}'
}
res = self.fetch(url, params)
To finish our setup, we’ll add this last piece of code to get our scraper to run properly:
if __name__ == '__main__':
scraper = EstateScraper()
scraper.run()
If everything is set correctly, then we’ll receive a 200 status code again.
Note: It’s important to create the methods inside the EstateScraper class or you’ll receive an error message.
5. Define the Parse Method
Inside the parse() method we’ll call Beautiful Soup to parse the HTML and find the elements we’re interested in.
Open the target URL on the browser and inspect the page. We’re looking for a parent element that contains all of the cards.
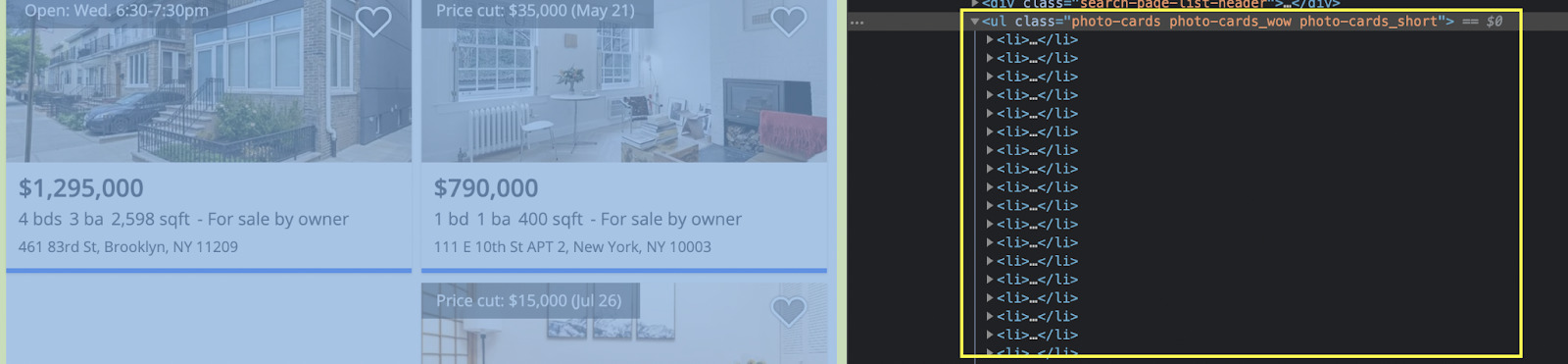
It seems like each card is represented by a <li> tag and wrapped between a <ul> tag with the class “photo-cards photo-cards_wow photo-cards_short”.
With this information we can construct the first part of our parser:
def parse(self, response):
content = BeautifulSoup(response)
deck = content.find('ul', {'class': 'photo-cards photo-cards_wow photo-cards_short'})
Note: We also have to add a parser inside our run() method by adding self.parse(res.text) after the res variable.
Before moving to the next step, let’s print(deck.prettify()) and see what it returns:
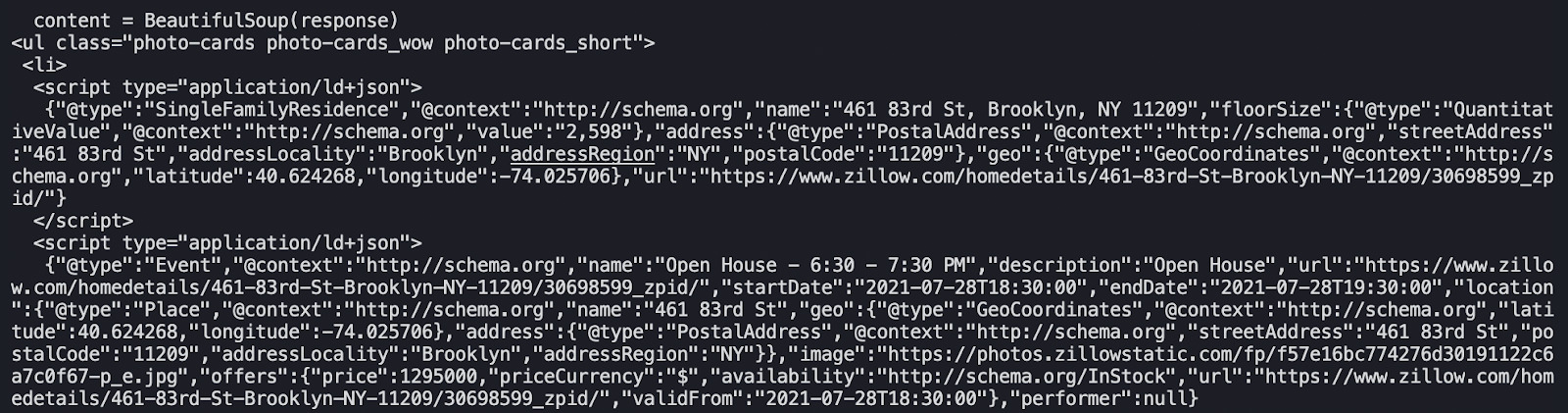
We used .prettify() to make the code easier to read.
6. Access the Script Tag
By inspecting the <il> elements, we can see that most of the information we’re looking for is inside a <script> tag as JSON data.
First, we’ll extract all the child elements from deck, and then select the <script> tag.
for card in deck.contents:
script = card.find('script', {'type': 'application/ld+json'})
if script:
print(script.prettify)
Also, delete the rest of the previous print() statements as we want to test our script selector.

Great. It’s working!
We’re getting closer to our goal. However, we haven’t handled all the challenges when scraping Zillow.
If we check Beautiful Soup documentation, we’ll find this paragraph:
“As of Beautiful Soup version 4.9.0, when lxml or html.parser are in use, the contents of <script>, <style>, and <template> tags are generally not considered to be ‘text’, since those tags are not part of the human-visible content of the page.”
Meaning that we can’t use script.text() to extract the text out of the tag. So here’s a solution we found on this:
- Add import json to our dependencies at the top of the file
- Then add this to or if script statement:
script_json = json.loads(script.contents[0])
If you update your script correctly, this is how the parser should look like:
def parse(self, response):
content = BeautifulSoup(response)
deck = content.find('ul', {'class': 'photo-cards photo-cards_wow photo-cards_short'})
for card in deck.contents:
script = card.find('script', {'type': 'application/ld+json'})
if script:
script_json = json.loads(script.contents[0])
Now, let’s make our scraper extract the name, GPS coordinates, floor size and the URL.
- Extract the Desirable Data
Above pour headers variable we’ll create a new results = [] variable to store the data we’ll be extracting.
Using this variable, we can now add a new step to our parser to select the elements from the <script> tag using the following logic:
- For name:
'name': script_json['name'] - For latitude:
'latitude': script_json['geo']['latitude'] - For longitude:
'longitude': script_json['geo']['longitude'] - For floor size:
'floorSize': script_json['floorSize']['value'] - For the URL:
'url': script_json['url']
But it won’t work to find the price because that piece of information is not inside the <script> tag, so we’ll need to check the page again and find how to select it.
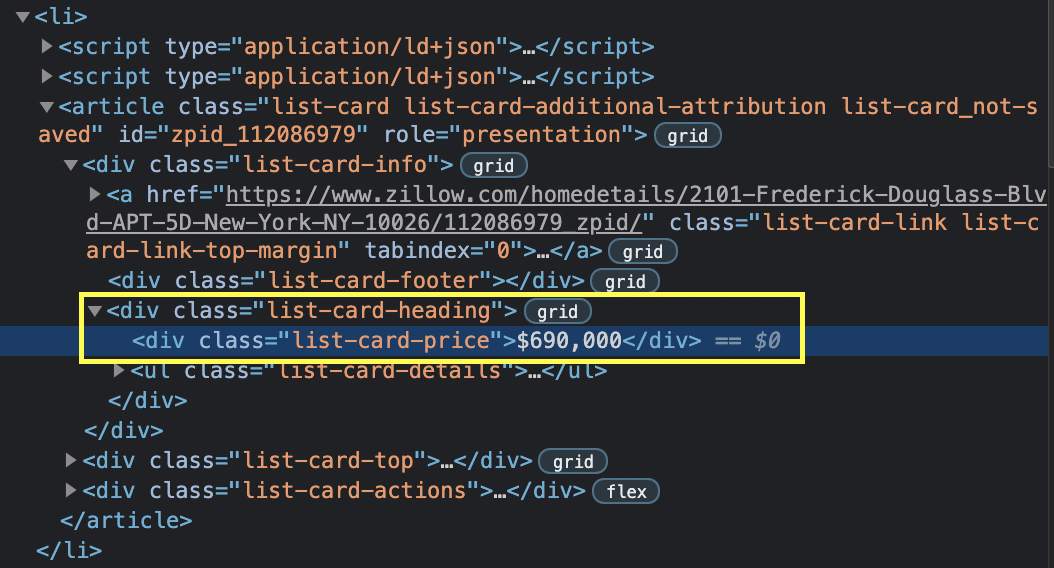
For the price we’ll use a CSS selector: 'price': card.find('div', {'class': 'list-card-price'}).text.
Let’s update our parser with the new information:
def parse(self, response):
content = BeautifulSoup(response)
deck = content.find('ul', {'class': 'photo-cards photo-cards_wow photo-cards_short'})
for card in deck.contents:
script = card.find('script', {'type': 'application/ld+json'})
if script:
script_json = json.loads(script.contents[0])
self.results.append({
'name': script_json['name'],
'latitude': script_json['geo']['latitude'],
'longitude': script_json['geo']['longitude'],
'floorSize': script_json['floorSize']['value'],
'url': script_json['url'],
'price': card.find('div', {'class': 'list-card-price'}).text
})
7. Navigating the Pagination
Without getting into much detail, we’ll specify a range to our run(self) method and do a little tweak to our params variable.
def run(self):
url = 'https://www.zillow.com/homes/New-York,-NY_rb/'
for page in range(1, 3):
params = {
'searchQueryState': '{"pagination":{"Current page": %s},"mapBounds":{"west":-74.45174190039063,"east":-73.50417109960938,"south":40.364611350639585,"north":41.045454918005234},"regionSelection":[{"regionId":6181,"regionType":6}],"isMapVisible":false,"filterState":{"sort":{"value":"globalrelevanceex"},"fsba":{"value":false},"nc":{"value":false},"fore":{"value":false},"cmsn":{"value":false},"auc":{"value":false},"pmf":{"value":false},"pf":{"value":false},"ah":{"value":true}},"isListVisible":true}' %page
}
res = self.fetch(url, params)
self.parse(res.text)
Note: At this stage, we can now delete the print(self.results) statement from our parser() method.
To set the range, all we need to do is to find out which is the last page of the navigation. In our case there are only two result pages to scrape.
With that, our scraper can now iterate through each page and find the information.
For debugging, we’ll print the status code of each request. This is super helpful for larger projects because your scraper will take some time to extract and return all the data.
In those cases, you’ll thank a status code telling you whether everything is going well or if your scraper crashed and burned.
8. Add Scraped Data in a CSV File
To add the data into a CSV file, we’ll import csv at the top of our Python file and define our to_csv() method:
def to_csv(self):
with open('estate.csv', 'w') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=self.results[0].keys())
writer.writeheader()
for row in self.results:
writer.writerow(row)
Then, in our run() method we’ll write self.to_csv().
Here’s the finished real estate scraper code:
import requests
from bs4 import BeautifulSoup
import json
import csv
class EstateScraper():
results = []
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9,es;q=0.8',
'cache-control': 'max-age=0',
'cookie': 'zguid=23|%24749da954-21fe-4a9e-9d76-e519a78ba0c9; _ga=GA1.2.1600763508.1625590071; zjs_user_id=null; zjs_anonymous_id=%22749da954-21fe-4a9e-9d76-e519a78ba0c9%22; _pxvid=e6e22d59-de79-11eb-99fe-0242ac120008; _gcl_au=1.1.771124946.1625590072; __pdst=9ea7da3100ba4be5b11e3b1439647467; _fbp=fb.1.1625590072673.1861311414; _pin_unauth=dWlkPU1EZ3haV0ZtWldZdE5qZGtZaTAwTW1ZMUxXRmhZMkl0TkRrNU16VXdZbVppT0dRMA; FSsampler=377337126; zgsession=1|78736779-0639-4f0d-958f-454215385742; DoubleClickSession=true; g_state={"i_p":1627666314547,"i_l":3}; _gid=GA1.2.790590851.1627322052; KruxPixel=true; utag_main=v_id:017a7cb803fe006d9eafa8b9088802079001707100942$_sn:4$_se:1$_ss:1$_st:1627323853684$dc_visit:3$ses_id:1627322053684%3Bexp-session$_pn:1%3Bexp-session$dcsyncran:1%3Bexp-session$tdsyncran:1%3Bexp-session$dc_event:1%3Bexp-session$dc_region:us-east-1%3Bexp-session; KruxAddition=true; JSESSIONID=6BF35449AA3EB26BA2145DBBC2682D3B; _px3=f3ca1d08b30ece1cf0653f24bb91ac6f0a84c04af722dd9ae649dc27099763d1:PZxIxKTPRTGCUE99clC1hQa0g5WwvYCc/gMdeuMB1ygu+Ea08QO6Cg/dN8Fe41YcVeOee/pw+Sg78Gv2Qjqsug==:1000:Jlpok2s5u9PyWKRfj63CdEWDDQsjPAFfoPXnEv55JCamXF2zhfWLyh6wteDIGBjKPy6HkAmJBY6jRmgk2ROhq+qZ+SItOJ0Jc68WzlHr0O82i49GiMIfbqafTnsLIuSQBZv/ruFqk5ThTxh1r/Gzrf1NdfINYNsaH7m7DQ6V+pIi84TE6aTzl8rWiQyHguWM/9wynjgR9JLd/G44Vr5DYQ==; _uetsid=7cfdec40ee3a11eba052b7e44eba3808; _uetvid=e7a59800de7911ebaf025dd320c394a8; AWSALB=QBa76k4FjGb+xHkALAYIFKaZxi3riUccngDpBj07JjeFARwZikwRZWHziNRg9K3oG1JgF0/1EMNzBTTgjnZizipqHBClNoF6lpxIpL4kg+sY+6+EnvKMxkY4y5HC; AWSALBCORS=QBa76k4FjGb+xHkALAYIFKaZxi3riUccngDpBj07JjeFARwZikwRZWHziNRg9K3oG1JgF0/1EMNzBTTgjnZizipqHBClNoF6lpxIpL4kg+sY+6+EnvKMxkY4y5HC; search=6|1629931657362%7Crect%3D41.38326361172051%252C-73.08669063085938%252C40.02158272425184%252C-74.86922236914063%26rid%3D6181%26disp%3Dmap%26mdm%3Dauto%26p%3D1%26sort%3Ddays%26z%3D1%26pt%3Dpmf%252Cpf%26fs%3D1%26fr%3D0%26mmm%3D1%26rs%3D0%26ah%3D0%26singlestory%3D0%26housing-connector%3D0%26abo%3D0%26garage%3D0%26pool%3D0%26ac%3D0%26waterfront%3D0%26finished%3D0%26unfinished%3D0%26cityview%3D0%26mountainview%3D0%26parkview%3D0%26waterview%3D0%26hoadata%3D1%26zillow-owned%3D0%263dhome%3D0%26featuredMultiFamilyBuilding%3D0%09%096181%09%09%09%09%09%09',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36'
}
def fetch(self, url, params):
response = requests.get(url, headers=self.headers, params=params)
print(response.status_code)
return response
def parse(self, response):
content = BeautifulSoup(response, 'lxml')
deck = content.find('ul', {'class': 'photo-cards photo-cards_wow photo-cards_short'})
for card in deck.contents:
script = card.find('script', {'type': 'application/ld+json'})
if script:
script_json = json.loads(script.contents[0])
self.results.append({
'name': script_json['name'],
'latitude': script_json['geo']['latitude'],
'longitude': script_json['geo']['longitude'],
'floorSize': script_json['floorSize']['value'],
'url': script_json['url'],
'price': card.find('div', {'class': 'list-card-price'}).text
})
def to_csv(self):
with open('estate.csv', 'w') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=self.results[0].keys())
writer.writeheader()
for row in self.results:
writer.writerow(row)
def run(self):
url = 'https://www.zillow.com/new-york-ny/fsbo/'
for page in range(1, 3):
params = {
'searchQueryState': '{"pagination":{"Current page": %s},"mapBounds":{"west":-74.45174190039063,"east":-73.50417109960938,"south":40.364611350639585,"north":41.045454918005234},"regionSelection":[{"regionId":6181,"regionType":6}],"isMapVisible":false,"filterState":{"sort":{"value":"globalrelevanceex"},"fsba":{"value":false},"nc":{"value":false},"fore":{"value":false},"cmsn":{"value":false},"auc":{"value":false},"pmf":{"value":false},"pf":{"value":false},"ah":{"value":true}},"isListVisible":true}' %page
}
res = self.fetch(url, params)
self.parse(res.text)
self.to_csv()
if __name__ == '__main__':
scraper = EstateScraper()
scraper.run()
If we run this code, our scraper will create a new CSV file named ‘ estate.csv’ inside our root directory, and append the data stored in the results variable.

Integrating ScraperAPI into Your Real Estate Web Scraper
Dealing with IP restrictions and CAPTCHAs is one of the most aggravating aspects of automated site scraping. To eliminate this issue, you now have to add Captcha solver and proxy support.
Although in this project we only scraped two pages, with larger projects you’ll be sending several requests to servers that, in most cases, will blacklist your IP and stop your scraper from accessing the domain.
ScraperAPI is a sophisticated system that employs third-party proxies, machine learning, massive browser farms, and years of statistical data to ensure that you are never stopped by bot-security tactics used by real estate websites like Zillow.
With over 20 million home IPs spread over 12 countries and software capable of rendering JavaScript and solving CAPTCHAs, you can perform huge scraping operations rapidly and without fear of being blocked by any servers.
A clear example is that by using ScraperAPI we don’t need to add headers. Once the request is sent to ScraperAPI servers, our tool will automatically decide which are the best headers to use so the request is successful.
This is a huge time saver, makes our script faster and takes a lot of the pressure from us. So we can focus on what’s really important: data!
Here’s the complete guide on how to integrate ScraperAPI with Requests and Beutiful Soup.
Other Real Estate Web Scraping Guide
Congratulations! You’ve just built a fully working real estate web scraper! Expect to get more hot property deals to grow your business.
If you’re interested in learning more about web scraping for real estate and how to build a web scraper for specific real estate websites, we highly recommend checking out these pages:
- How to Scrape Idealista.com with Python
- How to Scrape Zoopla Property Listings
- How to Scrape Homes.com Property Listing
- How to Scrape Redfin Property Data with Node.js
- How to Web Scrape Zillow
Collect Property Data with A Web Scraping Real Estate Tool
You now know how to scrape a real estate website like Zillow to build a list of listings, identify homes to buy, and improve the efficiency of a real estate business.
This list can be used to compare prices, provide to clients, learn more about the sector, and build more value assets.
You have all this data from a real estate scraper at your fingertips in a couple of seconds; how you use it is entirely up to you.
You can also check out our ScraperAPI cheat sheet to learn more about web scraping in more depth or learn about some of the best web scraping courses that can specifically help in the real estate industry.
